 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Graph Transformer for Multiple Tiny Object Tracking in RGB-T Videos
Dec 14, 2024



Tracking multiple tiny objects is highly challenging due to their weak appearance and limited features. Existing multi-object tracking algorithms generally focus on single-modality scenes, and overlook the complementary characteristics of tiny objects captured by multiple remote sensors. To enhance tracking performance by integrating complementary information from multiple sources, we propose a novel framework called {HGT-Track (Heterogeneous Graph Transformer based Multi-Tiny-Object Tracking)}. Specifically, we first employ a Transformer-based encoder to embed images from different modalities. Subsequently, we utilize Heterogeneous Graph Transformer to aggregate spatial and temporal information from multiple modalities to generate detection and tracking features. Additionally, we introduce a target re-detection module (ReDet) to ensure tracklet continuity by maintaining consistency across different modalities. Furthermore, this paper introduces the first benchmark VT-Tiny-MOT (Visible-Thermal Tiny Multi-Object Tracking) for RGB-T fused multiple tiny object tracking. Extensive experiments are conducted on VT-Tiny-MOT, and the results have demonstrated the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of MOTA (Multiple-Object Tracking Accuracy) and ID-F1 score. The code and dataset will be made available at https://github.com/xuqingyu26/HGTMT.
Visible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines
Jun 20, 2024



Small object detection (SOD) has been a longstanding yet challenging task for decades, with numerous datasets and algorithms being developed. However, they mainly focus on either visible or thermal modality, while visible-thermal (RGBT) bimodality is rarely explored. Although some RGBT datasets have been developed recently, the insufficient quantity, limited category, misaligned images and large target size cannot provide an impartial benchmark to evaluate multi-category visible-thermal small object detection (RGBT SOD) algorithms. In this paper, we build the first large-scale benchmark with high diversity for RGBT SOD (namely RGBT-Tiny), including 115 paired sequences, 93K frames and 1.2M manual annotations. RGBT-Tiny contains abundant targets (7 categories) and high-diversity scenes (8 types that cover different illumination and density variations). Note that, over 81% of targets are smaller than 16x16, and we provide paired bounding box annotations with tracking ID to offer an extremely challenging benchmark with wide-range applications, such as RGBT fusion, detection and tracking. In addition, we propose a scale adaptive fitness (SAFit) measure that exhibits high robustness on both small and large targets. The proposed SAFit can provide reasonable performance evaluation and promote detection performance. Based on the proposed RGBT-Tiny dataset and SAFit measure, extensive evaluations have been conducted, including 23 recent state-of-the-art algorithms that cover four different types (i.e., visible generic detection, visible SOD, thermal SOD and RGBT object detection). Project is available at https://github.com/XinyiYing24/RGBT-Tiny.
Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
Apr 04, 2023



Training a convolutional neural network (CNN) to detect infrared small targets in a fully supervised manner has gained remarkable research interests in recent years, but is highly labor expensive since a large number of per-pixel annotations are required. To handle this problem, in this paper, we make the first attempt to achieve infrared small target detection with point-level supervision. Interestingly, during the training phase supervised by point labels, we discover that CNNs first learn to segment a cluster of pixels near the targets, and then gradually converge to predict groundtruth point labels. Motivated by this "mapping degeneration" phenomenon, we propose a label evolution framework named label evolution with single point supervision (LESPS) to progressively expand the point label by leveraging the intermediate predictions of CNNs. In this way, the network predictions can finally approximate the updated pseudo labels, and a pixel-level target mask can be obtained to train CNNs in an end-to-end manner. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Experimental results show that CNNs equipped with LESPS can well recover the target masks from corresponding point labels, {and can achieve over 70% and 95% of their fully supervised performance in terms of pixel-level intersection over union (IoU) and object-level probability of detection (Pd), respectively. Code is available at https://github.com/XinyiYing/LESPS.
MoCoPnet: Exploring Local Motion and Contrast Priors for Infrared Small Target Super-Resolution
Jan 06, 2022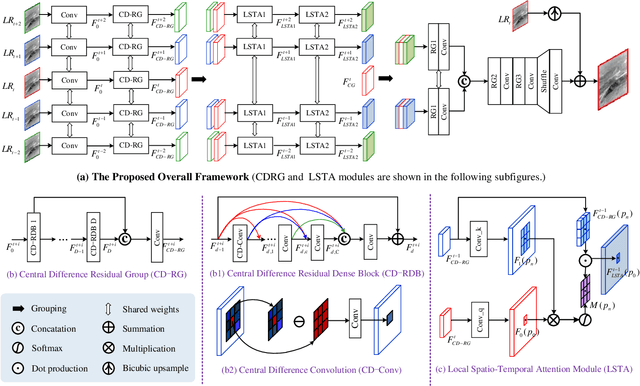
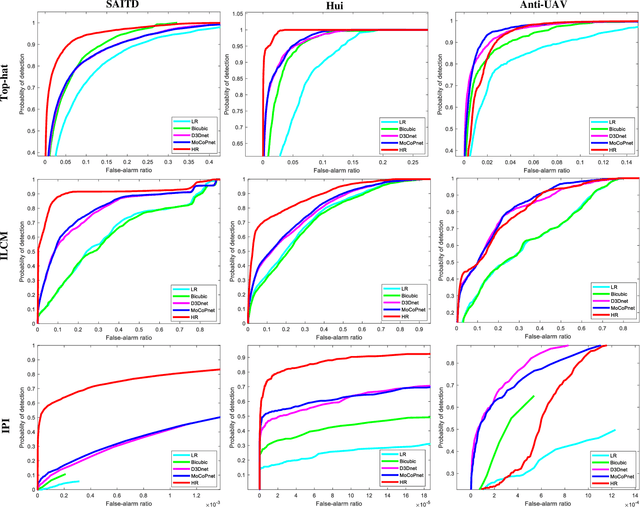

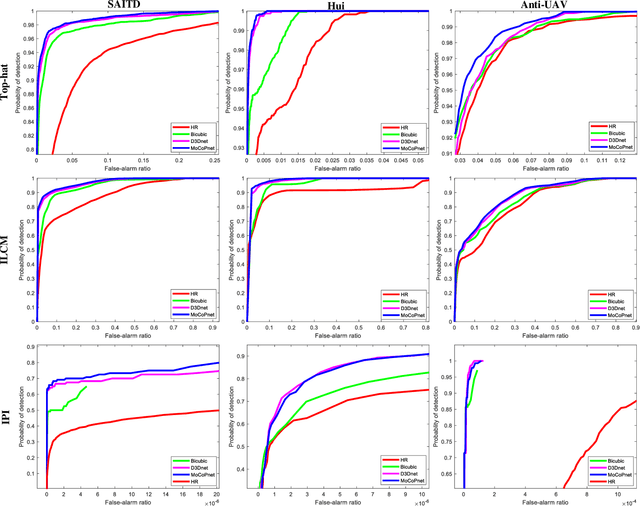
Infrared small target super-resolution (SR) aims to recover reliable and detailed high-resolution image with highcontrast targets from its low-resolution counterparts. Since the infrared small target lacks color and fine structure information, it is significant to exploit the supplementary information among sequence images to enhance the target. In this paper, we propose the first infrared small target SR method named local motion and contrast prior driven deep network (MoCoPnet) to integrate the domain knowledge of infrared small target into deep network, which can mitigate the intrinsic feature scarcity of infrared small targets. Specifically, motivated by the local motion prior in the spatio-temporal dimension, we propose a local spatiotemporal attention module to perform implicit frame alignment and incorporate the local spatio-temporal information to enhance the local features (especially for small targets). Motivated by the local contrast prior in the spatial dimension, we propose a central difference residual group to incorporate the central difference convolution into the feature extraction backbone, which can achieve center-oriented gradient-aware feature extraction to further improve the target contrast. Extensive experiments have demonstrated that our method can recover accurate spatial dependency and improve the target contrast. Comparative results show that MoCoPnet can outperform the state-of-the-art video SR and single image SR methods in terms of both SR performance and target enhancement. Based on the SR results, we further investigate the influence of SR on infrared small target detection and the experimental results demonstrate that MoCoPnet promotes the detection performance. The code is available at https://github.com/XinyiYing/MoCoPnet.
Deformable 3D Convolution for Video Super-Resolution
Apr 06, 2020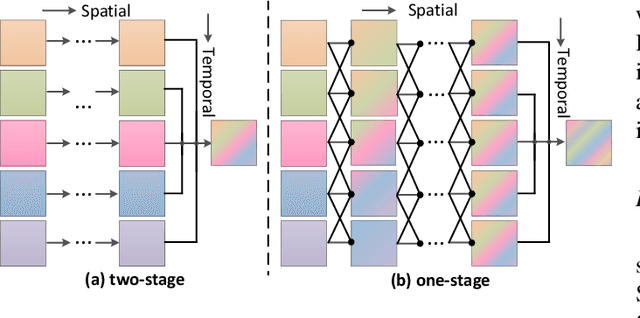
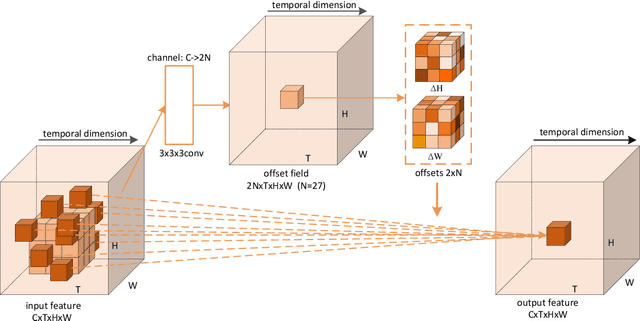
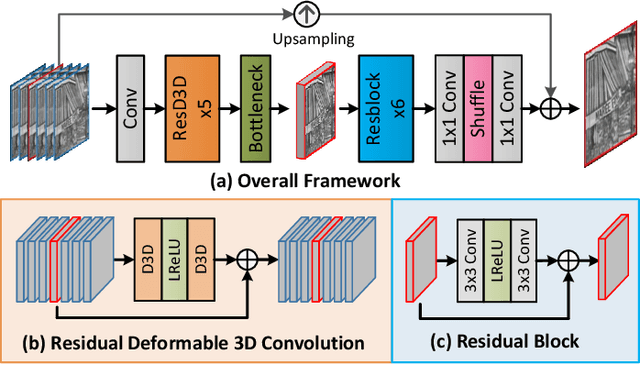
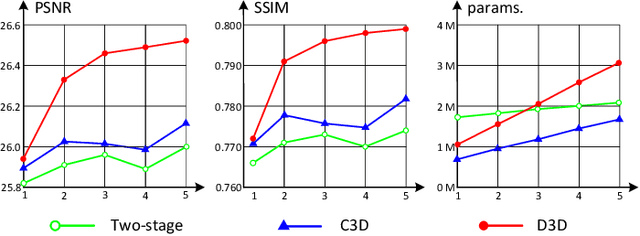
The spatio-temporal information among video sequences is significant for video super-resolution (SR). However, the spatio-temporal information cannot be fully used by existing video SR methods since spatial feature extraction and temporal motion compensation are usually performed sequentially. In this paper, we propose a deformable 3D convolution network (D3Dnet) to incorporate spatio-temporal information from both spatial and temporal dimensions for video SR. Specifically, we introduce deformable 3D convolutions (D3D) to integrate 2D spatial deformable convolutions with 3D convolutions (C3D), obtaining both superior spatio-temporal modeling capability and motion-aware modeling flexibility. Extensive experiments have demonstrated the effectiveness of our proposed D3D in exploiting spatio-temporal information. Comparative results show that our network outperforms the state-of-the-art methods. Code is available at: https://github.com/XinyiYing/D3Dnet.