 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Seeded graph matching for the correlated Wigner model via the projected power method
Apr 08, 2022
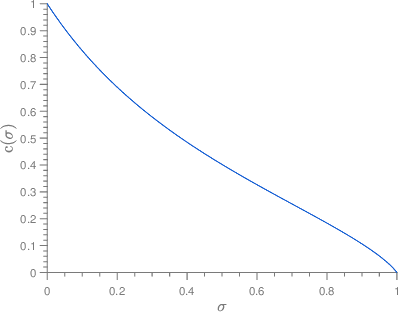
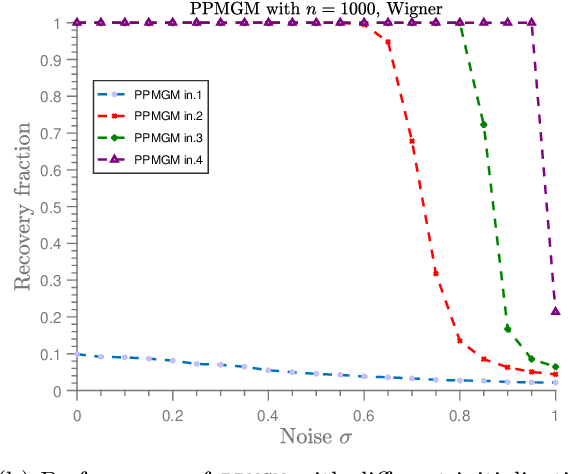
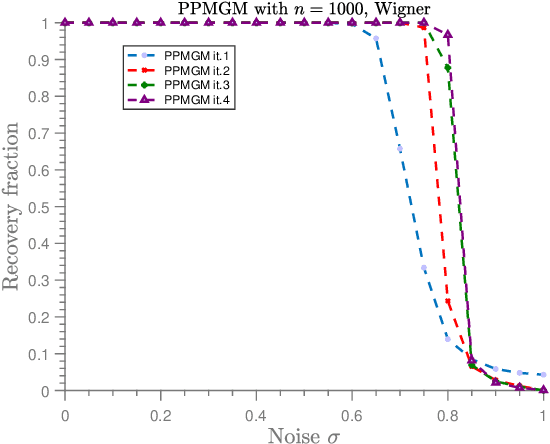
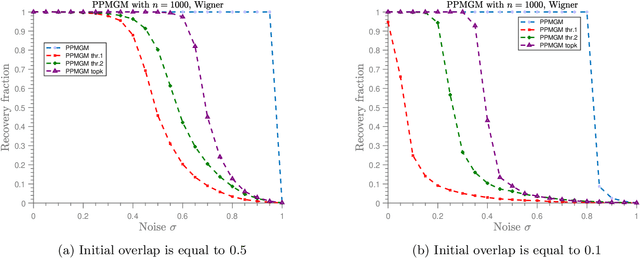
In the graph matching problem we observe two graphs $G,H$ and the goal is to find an assignment (or matching) between their vertices such that some measure of edge agreement is maximized. We assume in this work that the observed pair $G,H$ has been drawn from the correlated Wigner model -- a popular model for correlated weighted graphs -- where the entries of the adjacency matrices of $G$ and $H$ are independent Gaussians and each edge of $G$ is correlated with one edge of $H$ (determined by the unknown matching) with the edge correlation described by a parameter $\sigma\in [0,1)$. In this paper, we analyse the performance of the projected power method (PPM) as a seeded graph matching algorithm where we are given an initial partially correct matching (called the seed) as side information. We prove that if the seed is close enough to the ground-truth matching, then with high probability, PPM iteratively improves the seed and recovers the ground-truth matching (either partially or exactly) in $\mathcal{O}(\log n)$ iterations. Our results prove that PPM works even in regimes of constant $\sigma$, thus extending the analysis in (Mao et al.,2021) for the sparse Erd\"os-Renyi model to the (dense) Wigner model. As a byproduct of our analysis, we see that the PPM framework generalizes some of the state-of-art algorithms for seeded graph matching. We support and complement our theoretical findings with numerical experiments on synthetic data.
GelSight Fin Ray: Incorporating Tactile Sensing into a Soft Compliant Robotic Gripper
Apr 14, 2022
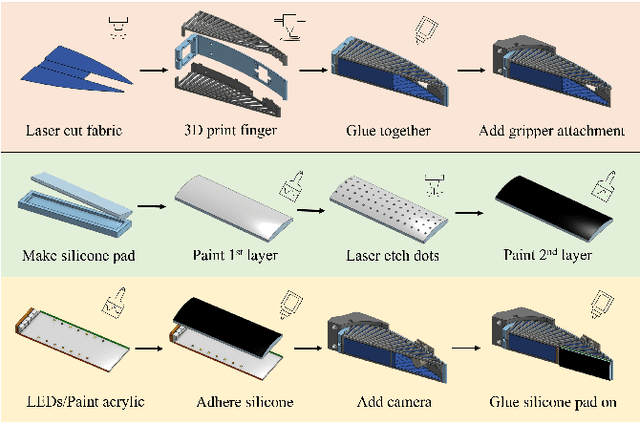
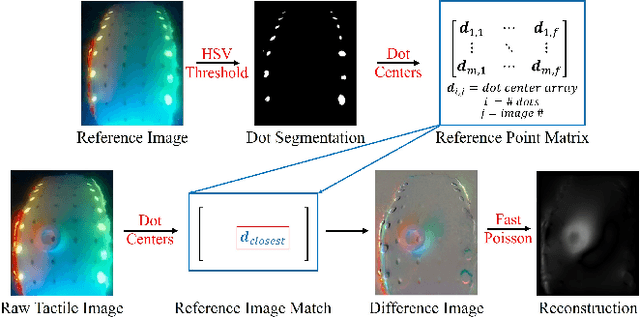

To adapt to constantly changing environments and be safe for human interaction, robots should have compliant and soft characteristics as well as the ability to sense the world around them. Even so, the incorporation of tactile sensing into a soft compliant robot, like the Fin Ray finger, is difficult due to its deformable structure. Not only does the frame need to be modified to allow room for a vision sensor, which enables intricate tactile sensing, the robot must also retain its original mechanically compliant properties. However, adding high-resolution tactile sensors to soft fingers is difficult since many sensorized fingers, such as GelSight-based ones, are rigid and function under the assumption that changes in the sensing region are only from tactile contact and not from finger compliance. A sensorized soft robotic finger needs to be able to separate its overall proprioceptive changes from its tactile information. To this end, this paper introduces the novel design of a GelSight Fin Ray, which embodies both the ability to passively adapt to any object it grasps and the ability to perform high-resolution tactile reconstruction, object orientation estimation, and marker tracking for shear and torsional forces. Having these capabilities allow soft and compliant robots to perform more manipulation tasks that require sensing. One such task the finger is able to perform successfully is a kitchen task: wine glass reorientation and placement, which is difficult to do with external vision sensors but is easy with tactile sensing. The development of this sensing technology could also potentially be applied to other soft compliant grippers, increasing their viability in many different fields.
GraphCoCo: Graph Complementary Contrastive Learning
Mar 24, 2022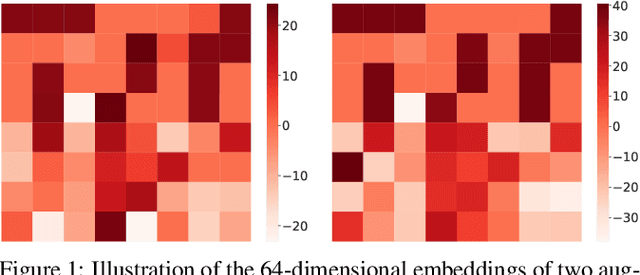
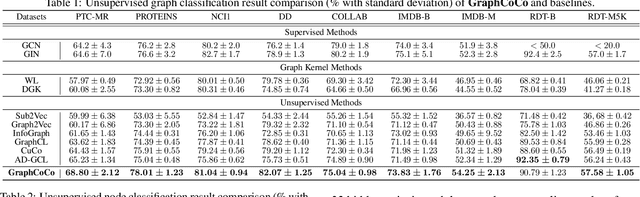
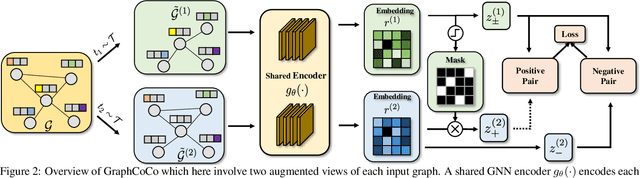
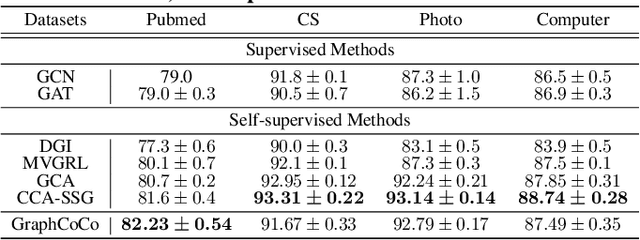
Graph Contrastive Learning (GCL) has shown promising performance in graph representation learning (GRL) without the supervision of manual annotations. GCL can generate graph-level embeddings by maximizing the Mutual Information (MI) between different augmented views of the same graph (positive pairs). However, we identify an obstacle that the optimization of InfoNCE loss only concentrates on a few embeddings dimensions, limiting the distinguishability of embeddings in downstream graph classification tasks. This paper proposes an effective graph complementary contrastive learning approach named GraphCoCo to tackle the above issue. Specifically, we set the embedding of the first augmented view as the anchor embedding to localize "highlighted" dimensions (i.e., the dimensions contribute most in similarity measurement). Then remove these dimensions in the embeddings of the second augmented view to discover neglected complementary representations. Therefore, the combination of anchor and complementary embeddings significantly improves the performance in downstream tasks. Comprehensive experiments on various benchmark datasets are conducted to demonstrate the effectiveness of GraphCoCo, and the results show that our model outperforms the state-of-the-art methods. Source code will be made publicly available.
Pilot Aided Channel Estimation for AFDM in Doubly Dispersive Channels
Mar 11, 2022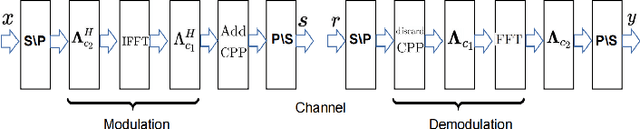
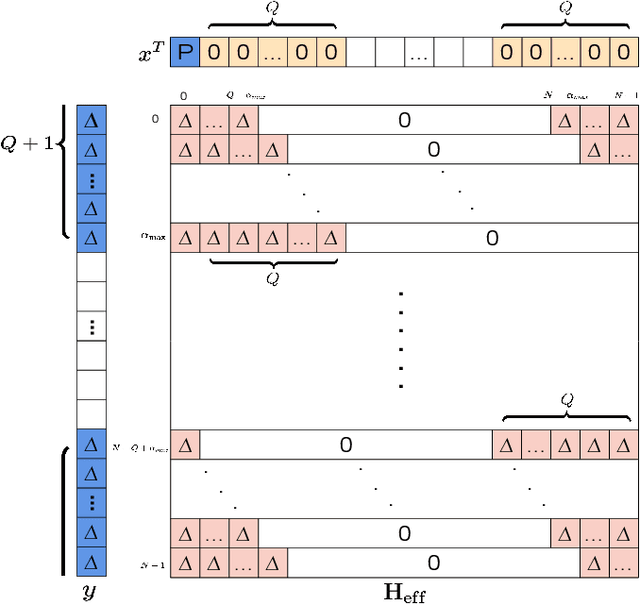
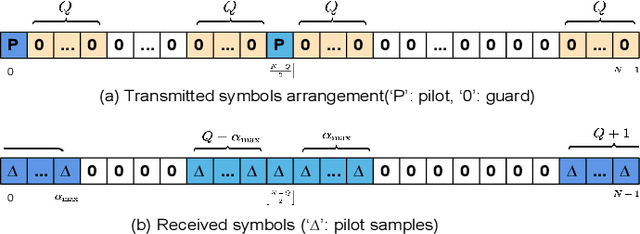
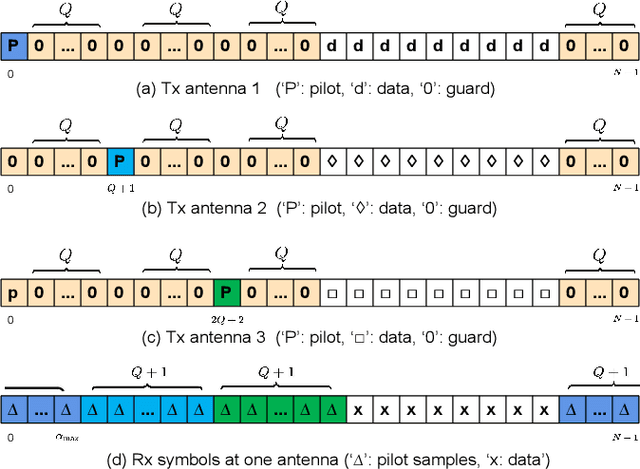
Affine frequency division multiplexing (AFDM) is a multi-chirp waveform and a promising solution for ultra-reliable communication under doubly dispersive channels. In this paper, we propose two pilot aided channel estimation schemes for AFDM, named single pilot aided (SPA) and multiple pilots aided (MPA) respectively. Pilot, guard and data symbols in the discrete affine Fourier transform (DAFT) domain are arranged appropriately at the transmitter. While at the receiver, channel estimation is performed with the aid of an estimation threshold and a mapping table. The bit error performance of AFDM applying the proposed channel estimation schemes shows only marginal loss compared to AFDM with ideally known channel state information. Moreover, extensions of the SPA scheme to multiple-input multiple-output (MIMO) and multi-user uplink/downlink are presented.
Automatically Learning Fallback Strategies with Model-Free Reinforcement Learning in Safety-Critical Driving Scenarios
Apr 11, 2022
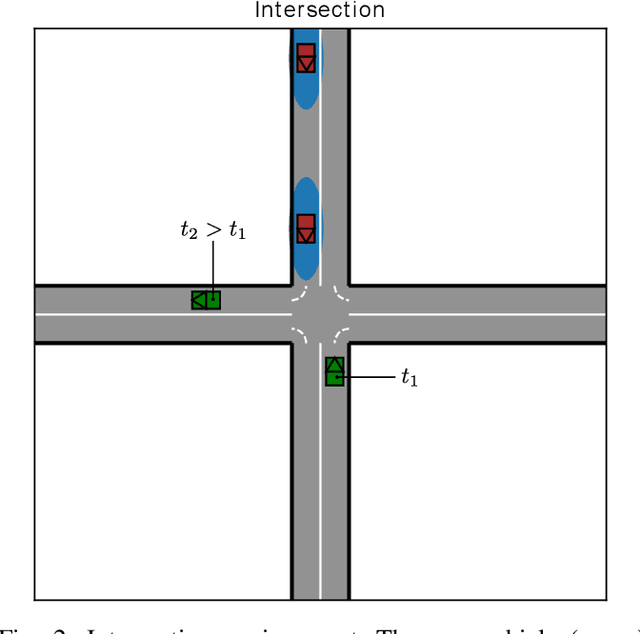
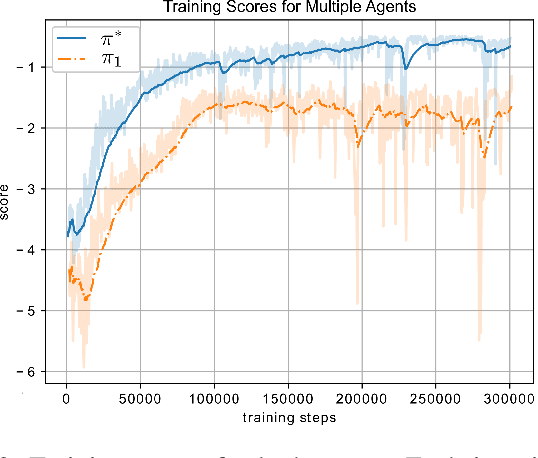
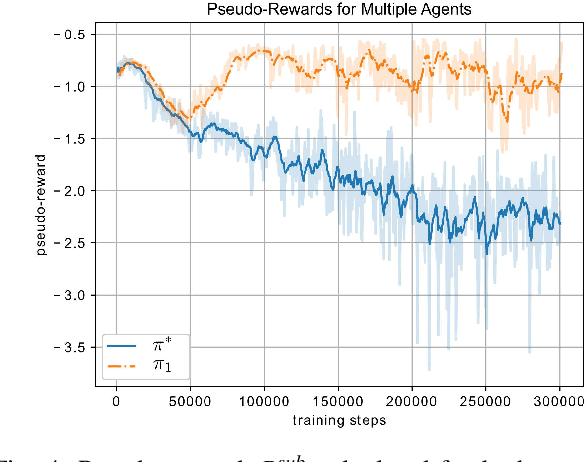
When learning to behave in a stochastic environment where safety is critical, such as driving a vehicle in traffic, it is natural for human drivers to plan fallback strategies as a backup to use if ever there is an unexpected change in the environment. Knowing to expect the unexpected, and planning for such outcomes, increases our capability for being robust to unseen scenarios and may help prevent catastrophic failures. Control of Autonomous Vehicles (AVs) has a particular interest in knowing when and how to use fallback strategies in the interest of safety. Due to imperfect information available to an AV about its environment, it is important to have alternate strategies at the ready which might not have been deduced from the original training data distribution. In this paper we present a principled approach for a model-free Reinforcement Learning (RL) agent to capture multiple modes of behaviour in an environment. We introduce an extra pseudo-reward term to the reward model, to encourage exploration to areas of state-space different from areas privileged by the optimal policy. We base this reward term on a distance metric between the trajectories of agents, in order to force policies to focus on different areas of state-space than the initial exploring agent. Throughout the paper, we refer to this particular training paradigm as learning fallback strategies. We apply this method to an autonomous driving scenario, and show that we are able to learn useful policies that would have otherwise been missed out on during training, and unavailable to use when executing the control algorithm.
Energy-Efficient Throughput Maximization in mmWave MU-Massive-MIMO-OFDM: Genetic Algorithm based Resource Allocation
Feb 18, 2022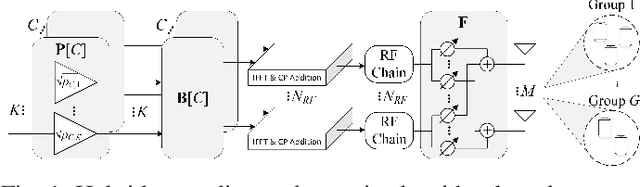
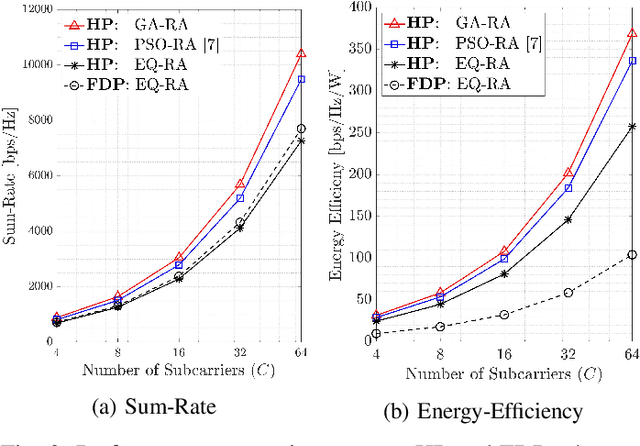
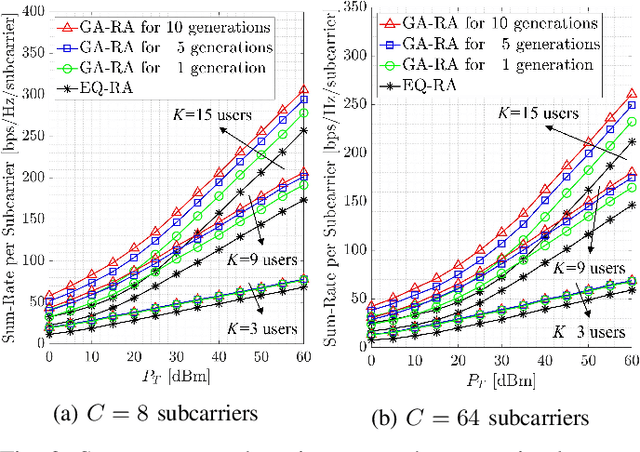
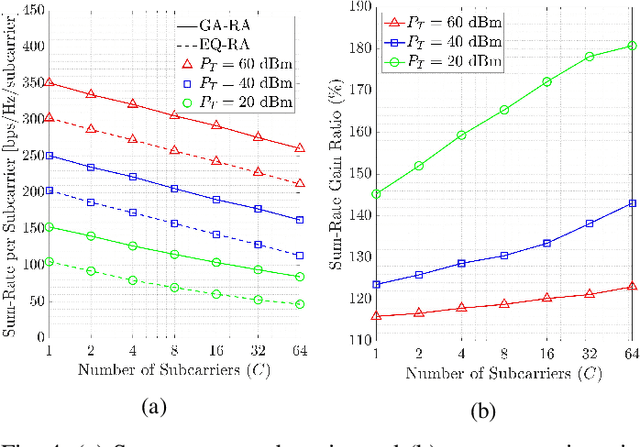
This paper develops a new genetic algorithm based resource allocation (GA-RA) technique for energy-efficient throughout maximization in multi-user massive multiple-input multiple-output (MU-mMIMO) systems using orthogonal frequency division multiplexing (OFDM) based transmission. We employ a hybrid precoding (HP) architecture with three stages: (i) radio frequency (RF) beamformer, (ii) baseband (BB) precoder, (iii) resource allocation (RA) block. First, a single RF beamformer block is built for all subcarriers via the slow time-varying angle-of-departure (AoD) information. For enhancing the energy efficiency, the RF beamformer aims to reduce the hardware cost/complexity and total power consumption via a low number of RF chains. Afterwards, the reduced-size effective channel state information (CSI) is utilized in the design of a distinct BB precoder and RA block for each subcarrier. The BB precoder is developed via regularized zero-forcing technique. Finally, the RA block is built via the proposed GA-RA technique for throughput maximization by allocating the power and subcarrier resources. The illustrative results show that the throughput performance in the MU-mMIMO-OFDM systems is greatly enhanced via the proposed GA-RA technique compared to both equal RA (EQ-RA) and particle swarm optimization based RA (PSO-RA). Moreover, the performance gain ratio increases with the increasing number of subcarriers, particularly for low transmission powers.
Disentanglement by Cyclic Reconstruction
Dec 24, 2021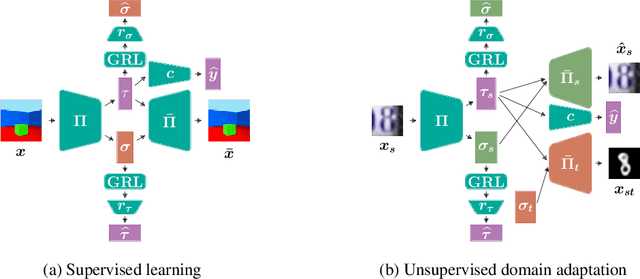

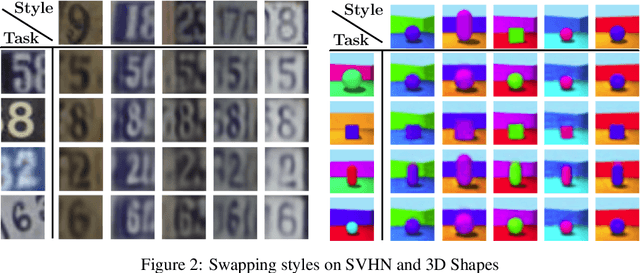
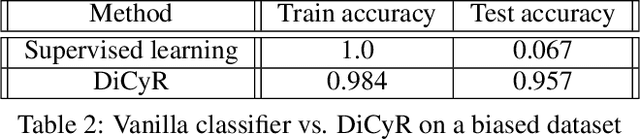
Deep neural networks have demonstrated their ability to automatically extract meaningful features from data. However, in supervised learning, information specific to the dataset used for training, but irrelevant to the task at hand, may remain encoded in the extracted representations. This remaining information introduces a domain-specific bias, weakening the generalization performance. In this work, we propose splitting the information into a task-related representation and its complementary context representation. We propose an original method, combining adversarial feature predictors and cyclic reconstruction, to disentangle these two representations in the single-domain supervised case. We then adapt this method to the unsupervised domain adaptation problem, consisting of training a model capable of performing on both a source and a target domain. In particular, our method promotes disentanglement in the target domain, despite the absence of training labels. This enables the isolation of task-specific information from both domains and a projection into a common representation. The task-specific representation allows efficient transfer of knowledge acquired from the source domain to the target domain. In the single-domain case, we demonstrate the quality of our representations on information retrieval tasks and the generalization benefits induced by sharpened task-specific representations. We then validate the proposed method on several classical domain adaptation benchmarks and illustrate the benefits of disentanglement for domain adaptation.
MGRR-Net: Multi-level Graph Relational Reasoning Network for Facial Action Units Detection
Apr 08, 2022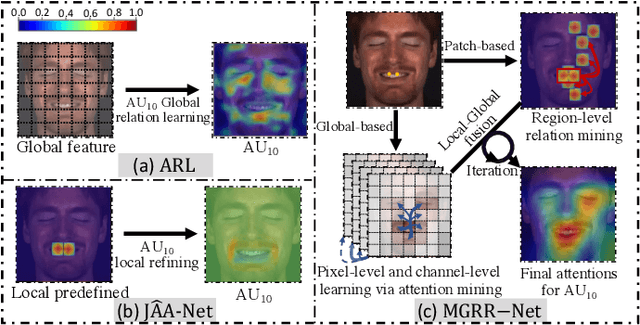
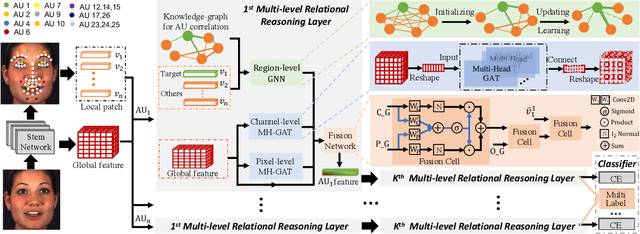
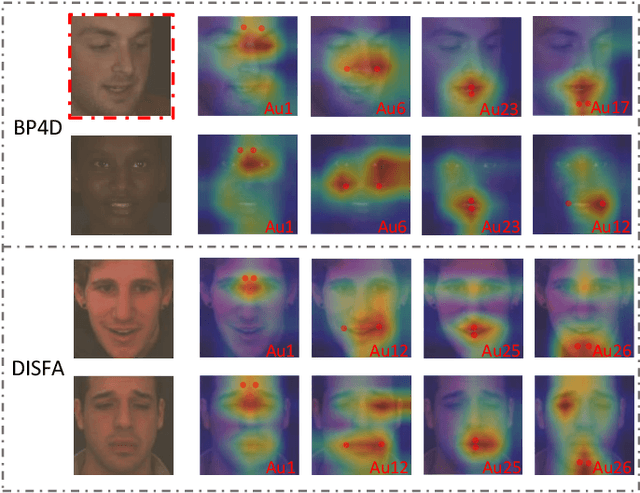
The Facial Action Coding System (FACS) encodes the action units (AUs) in facial images, which has attracted extensive research attention due to its wide use in facial expression analysis. Many methods that perform well on automatic facial action unit (AU) detection primarily focus on modeling various types of AU relations between corresponding local muscle areas, or simply mining global attention-aware facial features, however, neglect the dynamic interactions among local-global features. We argue that encoding AU features just from one perspective may not capture the rich contextual information between regional and global face features, as well as the detailed variability across AUs, because of the diversity in expression and individual characteristics. In this paper, we propose a novel Multi-level Graph Relational Reasoning Network (termed MGRR-Net) for facial AU detection. Each layer of MGRR-Net performs a multi-level (i.e., region-level, pixel-wise and channel-wise level) feature learning. While the region-level feature learning from local face patches features via graph neural network can encode the correlation across different AUs, the pixel-wise and channel-wise feature learning via graph attention network can enhance the discrimination ability of AU features from global face features. The fused features from the three levels lead to improved AU discriminative ability. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance than the state-of-the-art methods.
FisrEbp: Enterprise Bankruptcy Prediction via Fusing its Intra-risk and Spillover-Risk
Feb 01, 2022
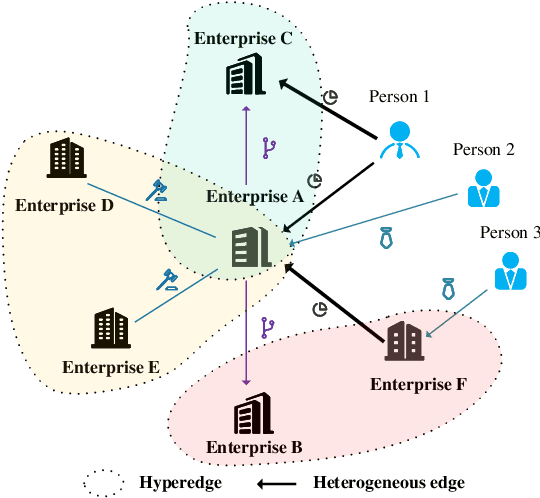
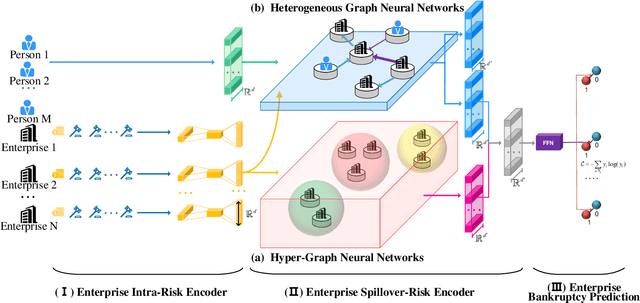
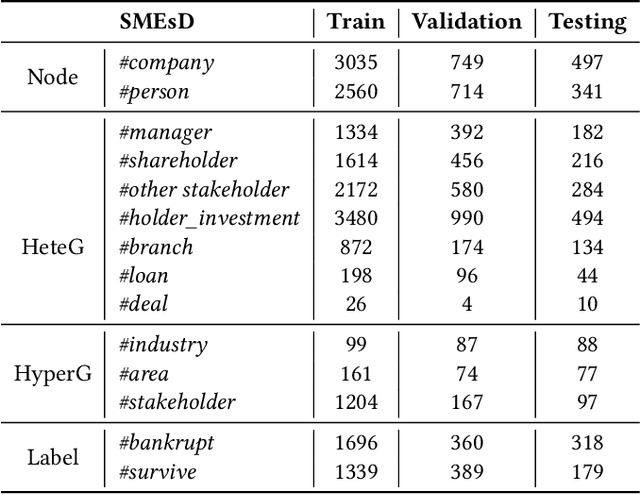
In this paper, we propose to model enterprise bankruptcy risk by fusing its intra-risk and spillover-risk. Under this framework, we propose a novel method that is equipped with an LSTM-based intra-risk encoder and GNNs-based spillover-risk encoder. Specifically, the intra-risk encoder is able to capture enterprise intra-risk using the statistic correlated indicators from the basic business information and litigation information. The spillover-risk encoder consists of hypergraph neural networks and heterogeneous graph neural networks, which aim to model spillover risk through two aspects, i.e. hyperedge and multiplex heterogeneous relations among enterprise knowledge graph, respectively. To evaluate the proposed model, we collect multi-sources SMEs data and build a new dataset SMEsD, on which the experimental results demonstrate the superiority of the proposed method. The dataset is expected to become a significant benchmark dataset for SMEs bankruptcy prediction and promote the development of financial risk study further.
On Distinctive Image Captioning via Comparing and Reweighting
Apr 08, 2022
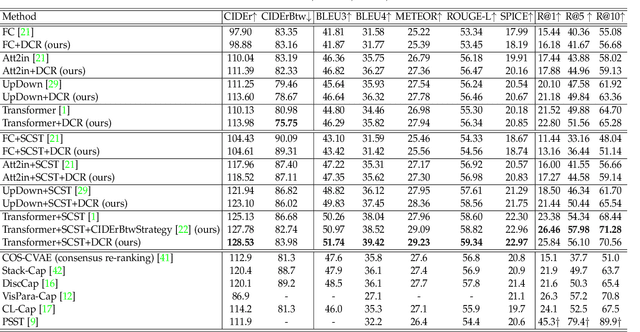
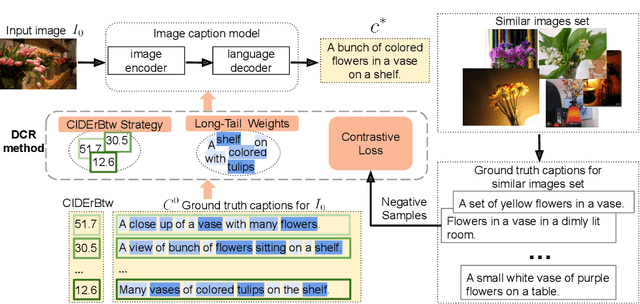
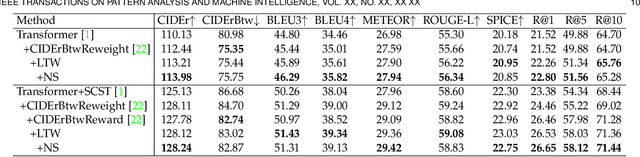
Recent image captioning models are achieving impressive results based on popular metrics, i.e., BLEU, CIDEr, and SPICE. However, focusing on the most popular metrics that only consider the overlap between the generated captions and human annotation could result in using common words and phrases, which lacks distinctiveness, i.e., many similar images have the same caption. In this paper, we aim to improve the distinctiveness of image captions via comparing and reweighting with a set of similar images. First, we propose a distinctiveness metric -- between-set CIDEr (CIDErBtw) to evaluate the distinctiveness of a caption with respect to those of similar images. Our metric reveals that the human annotations of each image in the MSCOCO dataset are not equivalent based on distinctiveness; however, previous works normally treat the human annotations equally during training, which could be a reason for generating less distinctive captions. In contrast, we reweight each ground-truth caption according to its distinctiveness during training. We further integrate a long-tailed weight strategy to highlight the rare words that contain more information, and captions from the similar image set are sampled as negative examples to encourage the generated sentence to be unique. Finally, extensive experiments are conducted, showing that our proposed approach significantly improves both distinctiveness (as measured by CIDErBtw and retrieval metrics) and accuracy (e.g., as measured by CIDEr) for a wide variety of image captioning baselines. These results are further confirmed through a user study.
* 20 pages. arXiv admin note: substantial text overlap with arXiv:2007.06877