 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafer Autonomous Driving in a Stochastic, Partially-Observable Environment by Hierarchical Contingency Planning
Apr 13, 2022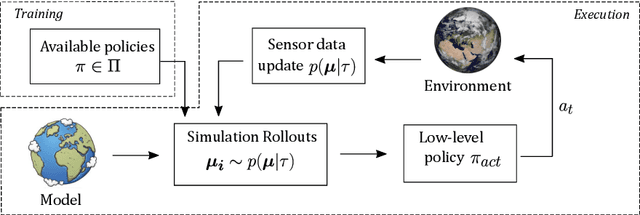


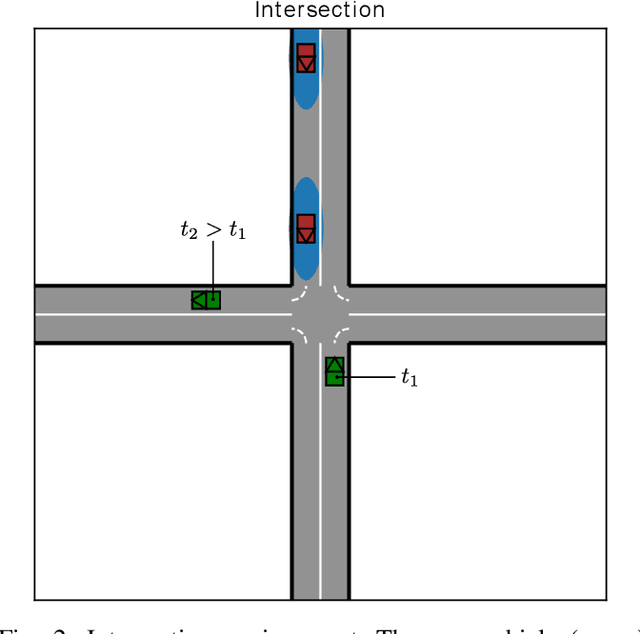
When learning to act in a stochastic, partially observable environment, an intelligent agent should be prepared to anticipate a change in its belief of the environment state, and be capable of adapting its actions on-the-fly to changing conditions. As humans, we are able to form contingency plans when learning a task with the explicit aim of being able to correct errors in the initial control, and hence prove useful if ever there is a sudden change in our perception of the environment which requires immediate corrective action. This is especially the case for autonomous vehicles (AVs) navigating real-world situations where safety is paramount, and a strong ability to react to a changing belief about the environment is truly needed. In this paper we explore an end-to-end approach, from training to execution, for learning robust contingency plans and combining them with a hierarchical planner to obtain a robust agent policy in an autonomous navigation task where other vehicles' behaviours are unknown, and the agent's belief about these behaviours is subject to sudden, last-second change. We show that our approach results in robust, safe behaviour in a partially observable, stochastic environment, generalizing well over environment dynamics not seen during training.
Automatically Learning Fallback Strategies with Model-Free Reinforcement Learning in Safety-Critical Driving Scenarios
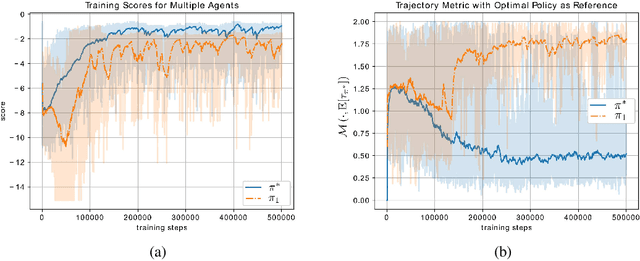
Apr 11, 2022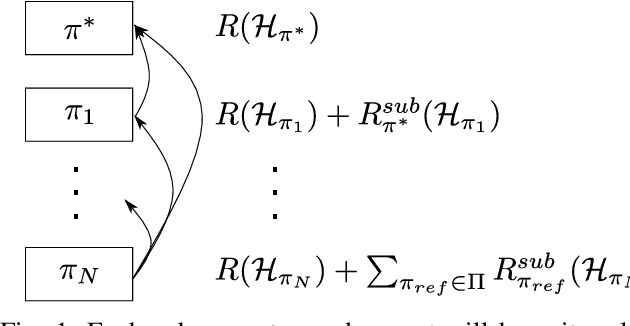
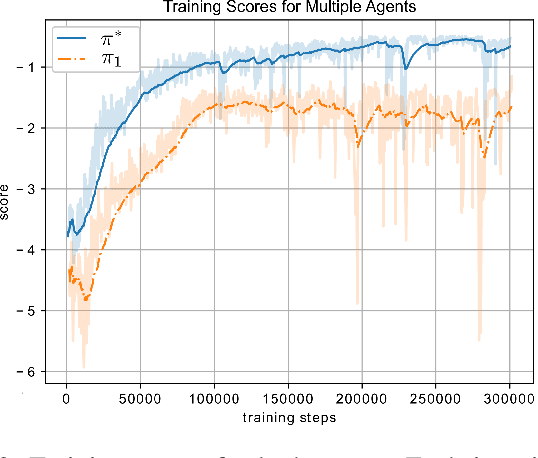
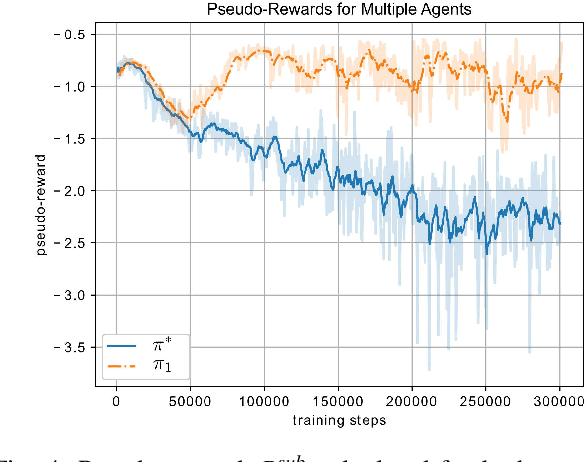
When learning to behave in a stochastic environment where safety is critical, such as driving a vehicle in traffic, it is natural for human drivers to plan fallback strategies as a backup to use if ever there is an unexpected change in the environment. Knowing to expect the unexpected, and planning for such outcomes, increases our capability for being robust to unseen scenarios and may help prevent catastrophic failures. Control of Autonomous Vehicles (AVs) has a particular interest in knowing when and how to use fallback strategies in the interest of safety. Due to imperfect information available to an AV about its environment, it is important to have alternate strategies at the ready which might not have been deduced from the original training data distribution. In this paper we present a principled approach for a model-free Reinforcement Learning (RL) agent to capture multiple modes of behaviour in an environment. We introduce an extra pseudo-reward term to the reward model, to encourage exploration to areas of state-space different from areas privileged by the optimal policy. We base this reward term on a distance metric between the trajectories of agents, in order to force policies to focus on different areas of state-space than the initial exploring agent. Throughout the paper, we refer to this particular training paradigm as learning fallback strategies. We apply this method to an autonomous driving scenario, and show that we are able to learn useful policies that would have otherwise been missed out on during training, and unavailable to use when executing the control algorithm.