 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tag-Based Attention Guided Bottom-Up Approach for Video Instance Segmentation
Apr 22, 2022
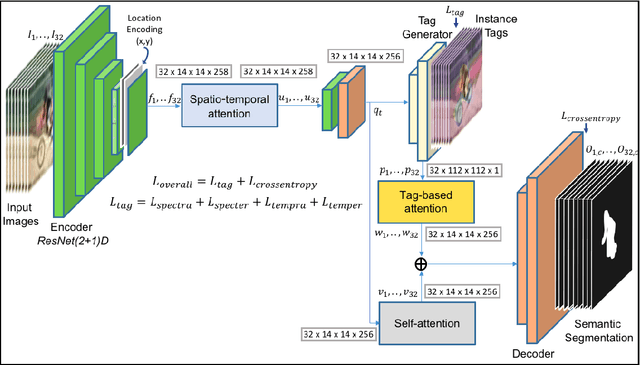
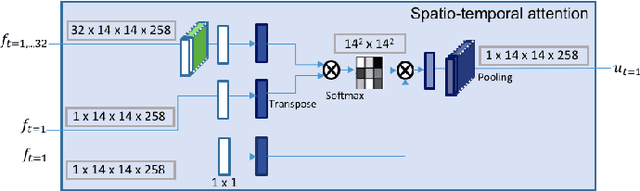
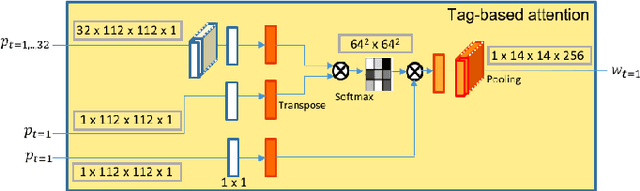
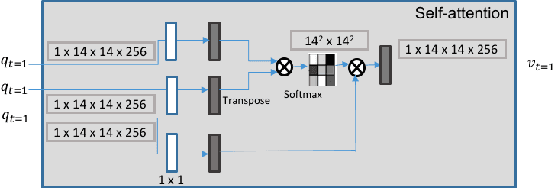
Video Instance Segmentation is a fundamental computer vision task that deals with segmenting and tracking object instances across a video sequence. Most existing methods typically accomplish this task by employing a multi-stage top-down approach that usually involves separate networks to detect and segment objects in each frame, followed by associating these detections in consecutive frames using a learned tracking head. In this work, however, we introduce a simple end-to-end trainable bottom-up approach to achieve instance mask predictions at the pixel-level granularity, instead of the typical region-proposals-based approach. Unlike contemporary frame-based models, our network pipeline processes an input video clip as a single 3D volume to incorporate temporal information. The central idea of our formulation is to solve the video instance segmentation task as a tag assignment problem, such that generating distinct tag values essentially separates individual object instances across the video sequence (here each tag could be any arbitrary value between 0 and 1). To this end, we propose a novel spatio-temporal tagging loss that allows for sufficient separation of different objects as well as necessary identification of different instances of the same object. Furthermore, we present a tag-based attention module that improves instance tags, while concurrently learning instance propagation within a video. Evaluations demonstrate that our method provides competitive results on YouTube-VIS and DAVIS-19 datasets, and has minimum run-time compared to other state-of-the-art performance methods.
Wind speed forecast using random forest learning method
Mar 23, 2022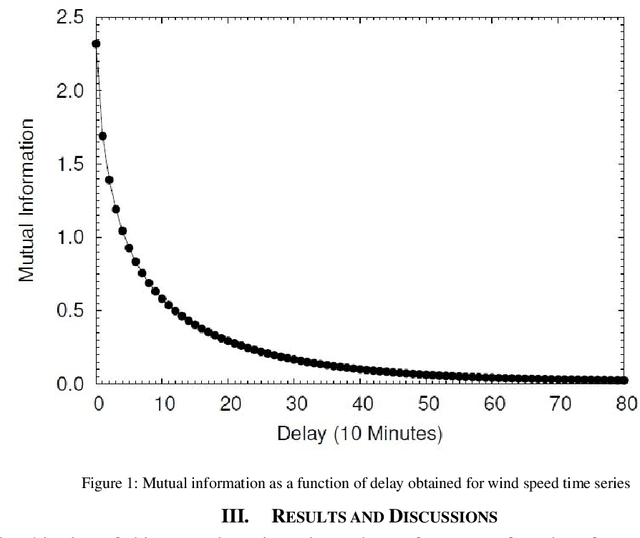
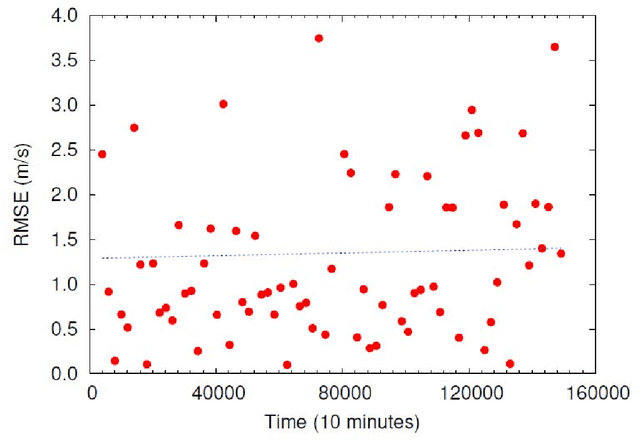
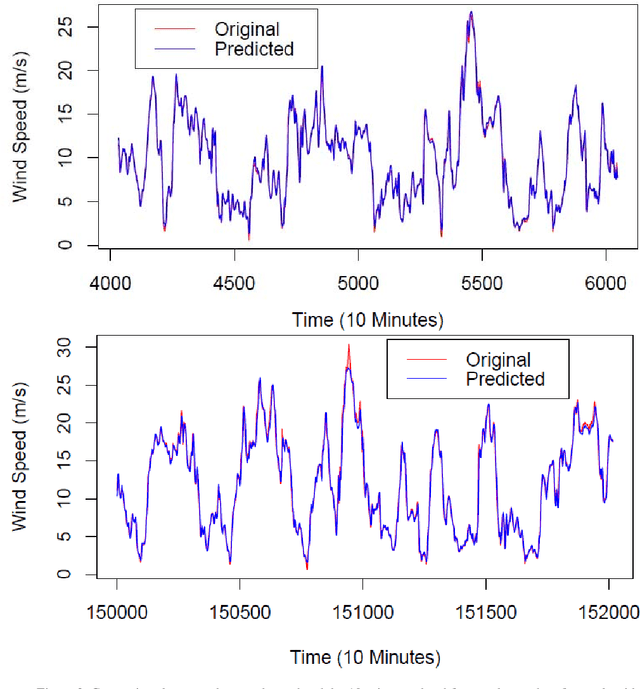
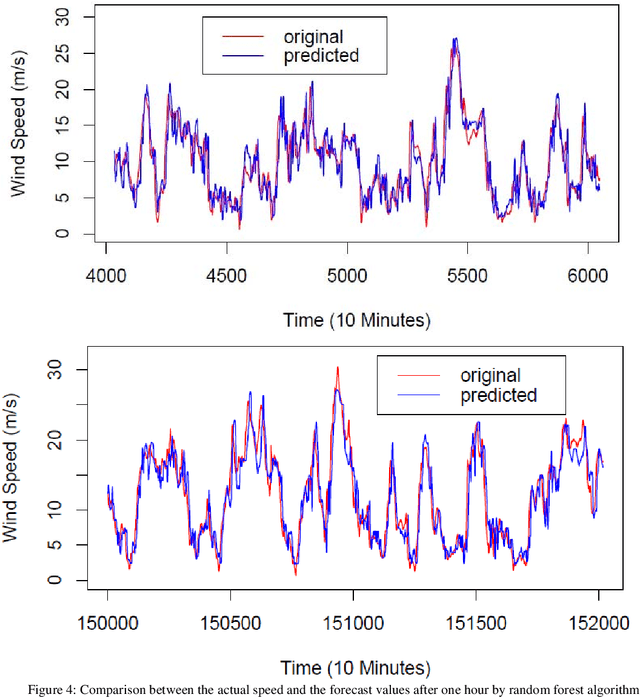
Wind speed forecasting models and their application to wind farm operations are attaining remarkable attention in the literature because of its benefits as a clean energy source. In this paper, we suggested the time series machine learning approach called random forest regression for predicting wind speed variations. The computed values of mutual information and auto-correlation shows that wind speed values depend on the past data up to 12 hours. The random forest model was trained using ensemble from two weeks data with previous 12 hours values as input for every value. The computed root mean square error shows that model trained with two weeks data can be employed to make reliable short-term predictions up to three years ahead.
Pilot Aided Channel Estimation for AFDM in Doubly Dispersive Channels
Mar 26, 2022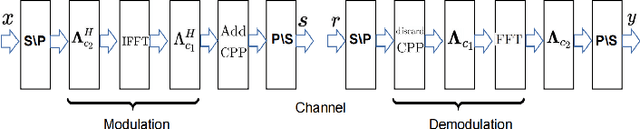
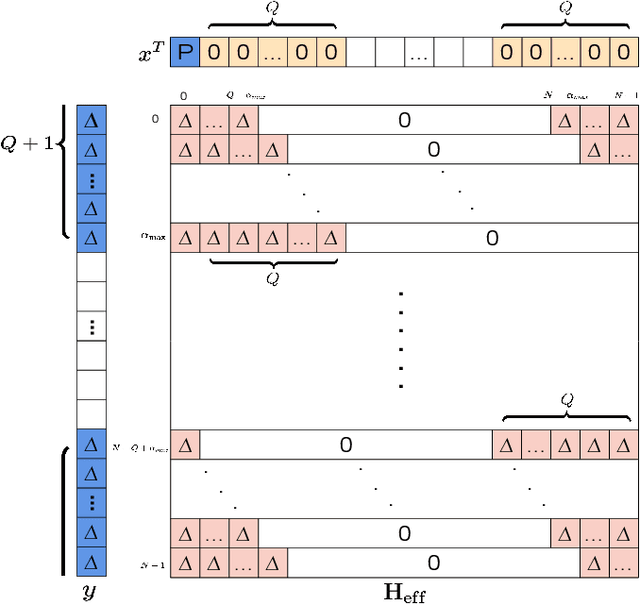
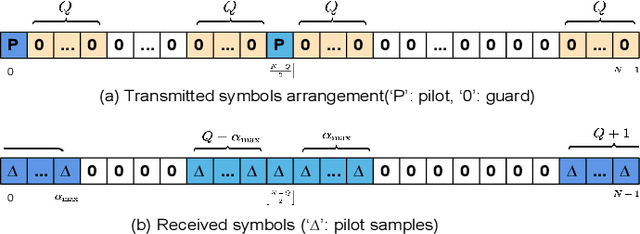
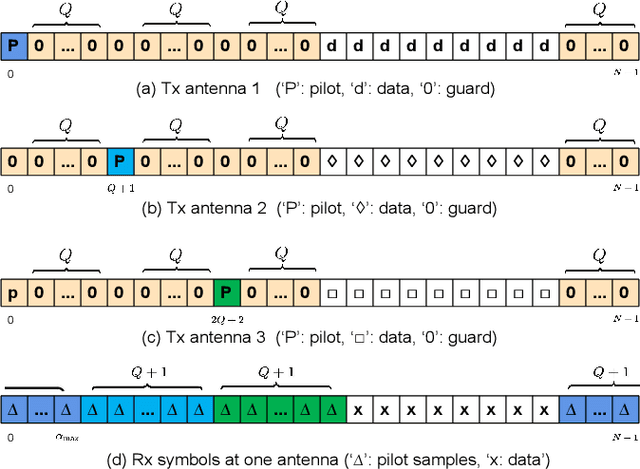
Affine frequency division multiplexing (AFDM) is a multi-chirp waveform and a promising solution for ultra-reliable communication under doubly dispersive channels. In this paper, we propose two pilot aided channel estimation schemes for AFDM, named single pilot aided (SPA) and multiple pilots aided (MPA) respectively. Pilot, guard and data symbols in the discrete affine Fourier transform (DAFT) domain are arranged appropriately at the transmitter. While at the receiver, channel estimation is performed with the aid of an estimation threshold and a mapping table. The bit error performance of AFDM applying the proposed channel estimation schemes shows only marginal loss compared to AFDM with ideally known channel state information. Moreover, extensions of the SPA scheme to multiple-input multiple-output (MIMO) and multi-user uplink/downlink are presented.
ProbNVS: Fast Novel View Synthesis with Learned Probability-Guided Sampling
Apr 07, 2022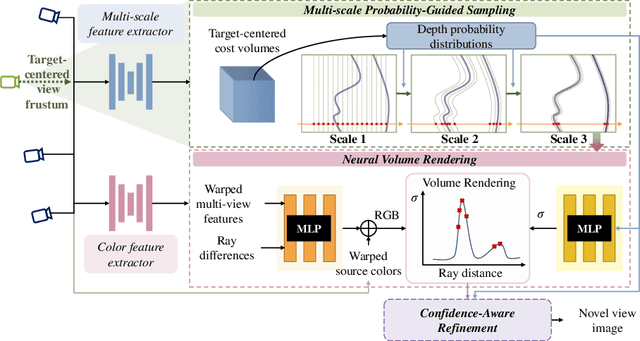
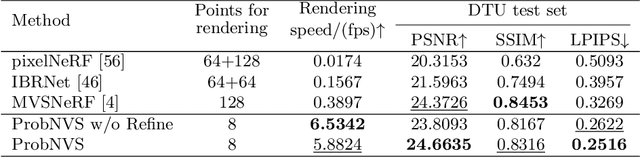
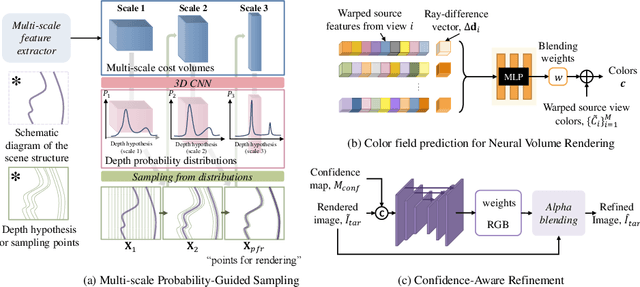
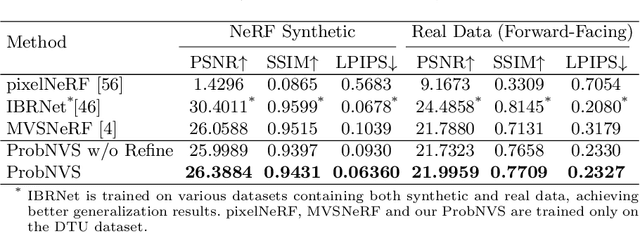
Existing state-of-the-art novel view synthesis methods rely on either fairly accurate 3D geometry estimation or sampling of the entire space for neural volumetric rendering, which limit the overall efficiency. In order to improve the rendering efficiency by reducing sampling points without sacrificing rendering quality, we propose to build a novel view synthesis framework based on learned MVS priors that enables general, fast and photo-realistic view synthesis simultaneously. Specifically, fewer but important points are sampled under the guidance of depth probability distributions extracted from the learned MVS architecture. Based on the learned probability-guided sampling, a neural volume rendering module is elaborately devised to fully aggregate source view information as well as the learned scene structures to synthesize photorealistic target view images. Finally, the rendering results in uncertain, occluded and unreferenced regions can be further improved by incorporating a confidence-aware refinement module. Experiments show that our method achieves 15 to 40 times faster rendering compared to state-of-the-art baselines, with strong generalization capacity and comparable high-quality novel view synthesis performance.
Using Full-text Content of Academic Articles to Build a Methodology Taxonomy of Information Science in China
Jan 20, 2021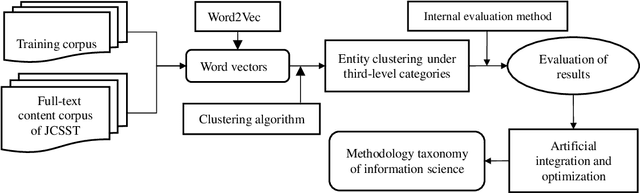
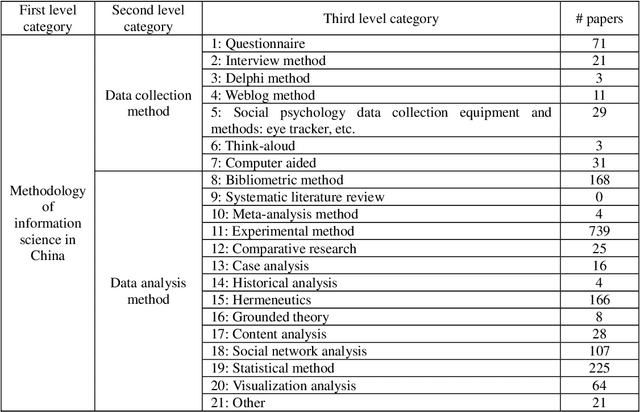
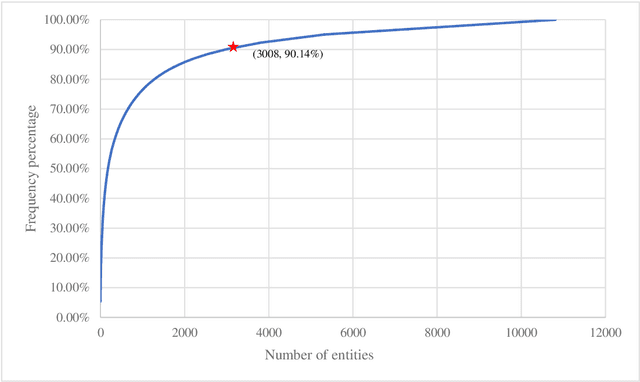

Research on the construction of traditional information science methodology taxonomy is mostly conducted manually. From the limited corpus, researchers have attempted to summarize some of the research methodology entities into several abstract levels (generally three levels); however, they have been unable to provide a more granular hierarchy. Moreover, updating the methodology taxonomy is traditionally a slow process. In this study, we collected full-text academic papers related to information science. First, we constructed a basic methodology taxonomy with three levels by manual annotation. Then, the word vectors of the research methodology entities were trained using the full-text data. Accordingly, the research methodology entities were clustered and the basic methodology taxonomy was expanded using the clustering results to obtain a methodology taxonomy with more levels. This study provides new concepts for constructing a methodology taxonomy of information science. The proposed methodology taxonomy is semi-automated; it is more detailed than conventional schemes and the speed of taxonomy renewal has been enhanced.
CTCNet: A CNN-Transformer Cooperation Network for Face Image Super-Resolution
Apr 19, 2022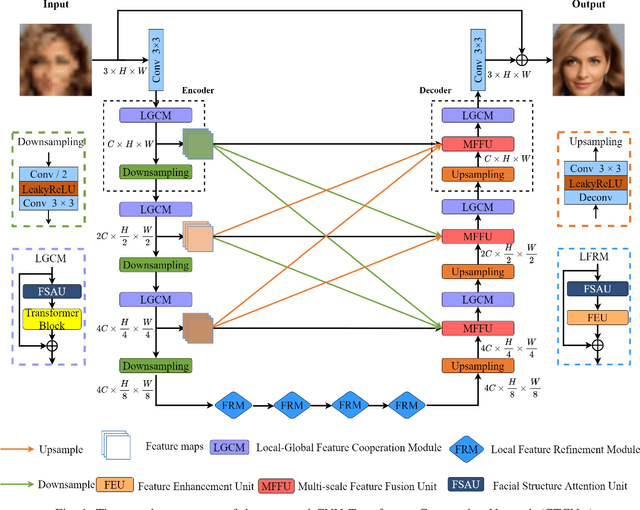

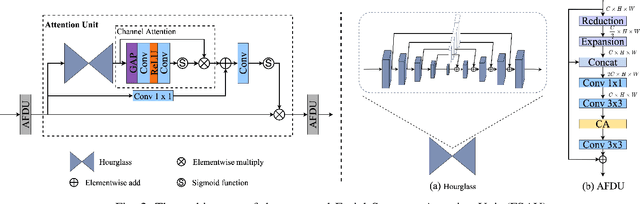
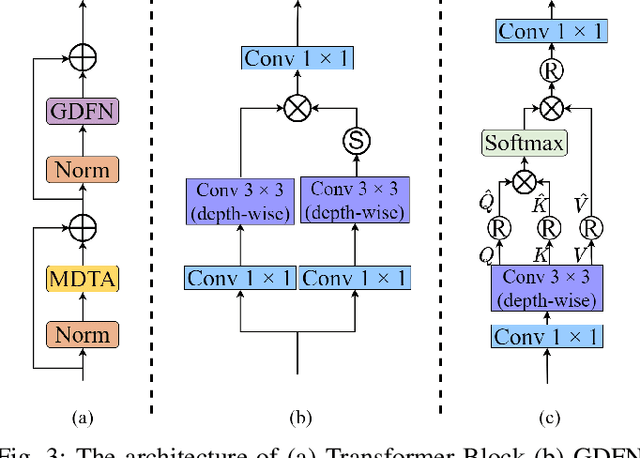
Recently, deep convolution neural networks (CNNs) steered face super-resolution methods have achieved great progress in restoring degraded facial details by jointly training with facial priors. However, these methods have some obvious limitations. On the one hand, multi-task joint learning requires additional marking on the dataset, and the introduced prior network will significantly increase the computational cost of the model. On the other hand, the limited receptive field of CNN will reduce the fidelity and naturalness of the reconstructed facial images, resulting in suboptimal reconstructed images. In this work, we propose an efficient CNN-Transformer Cooperation Network (CTCNet) for face super-resolution tasks, which uses the multi-scale connected encoder-decoder architecture as the backbone. Specifically, we first devise a novel Local-Global Feature Cooperation Module (LGCM), which is composed of a Facial Structure Attention Unit (FSAU) and a Transformer block, to promote the consistency of local facial detail and global facial structure restoration simultaneously. Then, we design an efficient Local Feature Refinement Module (LFRM) to enhance the local facial structure information. Finally, to further improve the restoration of fine facial details, we present a Multi-scale Feature Fusion Unit (MFFU) to adaptively fuse the features from different stages in the encoder procedure. Comprehensive evaluations on various datasets have assessed that the proposed CTCNet can outperform other state-of-the-art methods significantly.
Imitation and Adaptation Based on Consistency: A Quadruped Robot Imitates Animals from Videos Using Deep Reinforcement Learning
Mar 02, 2022

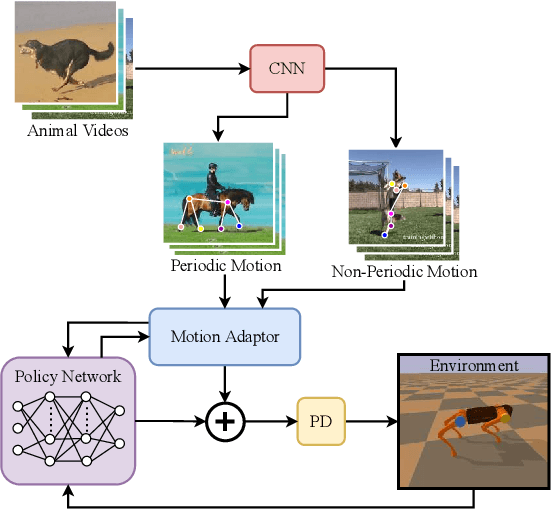
The essence of quadrupeds' movements is the movement of the center of gravity, which has a pattern in the action of quadrupeds. However, the gait motion planning of the quadruped robot is time-consuming. Animals in nature can provide a large amount of gait information for robots to learn and imitate. Common methods learn animal posture with a motion capture system or numerous motion data points. In this paper, we propose a video imitation adaptation network (VIAN) that can imitate the action of animals and adapt it to the robot from a few seconds of video. The deep learning model extracts key points during animal motion from videos. The VIAN eliminates noise and extracts key information of motion with a motion adaptor, and then applies the extracted movements function as the motion pattern into deep reinforcement learning (DRL). To ensure similarity between the learning result and the animal motion in the video, we introduce rewards that are based on the consistency of the motion. DRL explores and learns to maintain balance from movement patterns from videos, imitates the action of animals, and eventually, allows the model to learn the gait or skills from short motion videos of different animals and to transfer the motion pattern to the real robot.
Efficient Bayesian Policy Reuse with a Scalable Observation Model in Deep Reinforcement Learning
Apr 19, 2022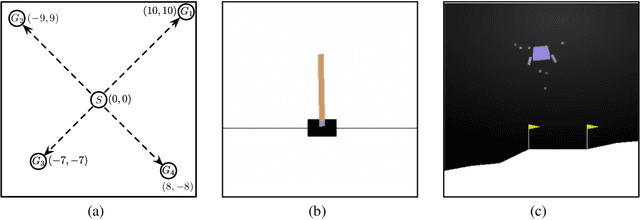

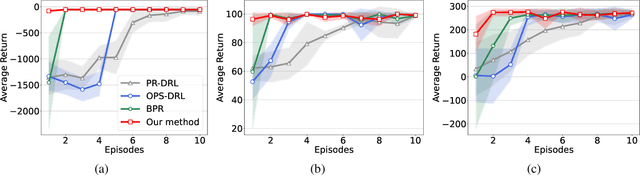

Bayesian policy reuse (BPR) is a general policy transfer framework for selecting a source policy from an offline library by inferring the task belief based on some observation signals and a trained observation model. In this paper, we propose an improved BPR method to achieve more efficient policy transfer in deep reinforcement learning (DRL). First, most BPR algorithms use the episodic return as the observation signal that contains limited information and cannot be obtained until the end of an episode. Instead, we employ the state transition sample, which is informative and instantaneous, as the observation signal for faster and more accurate task inference. Second, BPR algorithms usually require numerous samples to estimate the probability distribution of the tabular-based observation model, which may be expensive and even infeasible to learn and maintain, especially when using the state transition sample as the signal. Hence, we propose a scalable observation model based on fitting state transition functions of source tasks from only a small number of samples, which can generalize to any signals observed in the target task. Moreover, we extend the offline-mode BPR to the continual learning setting by expanding the scalable observation model in a plug-and-play fashion, which can avoid negative transfer when faced with new unknown tasks. Experimental results show that our method can consistently facilitate faster and more efficient policy transfer.
A Comparative Study of Fusion Methods for SASV Challenge 2022
Mar 31, 2022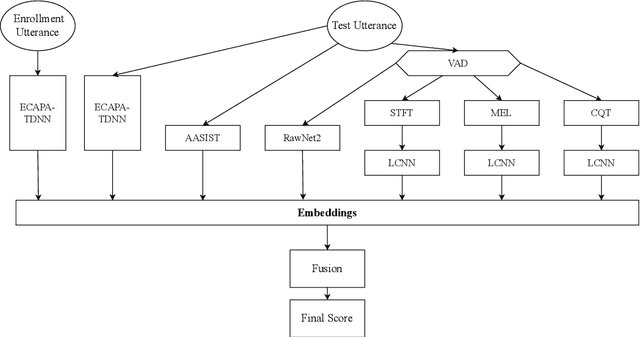
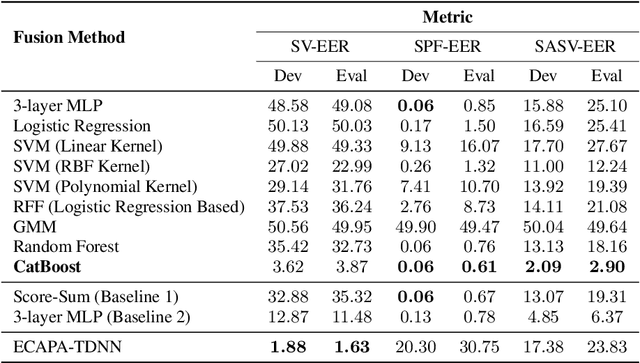
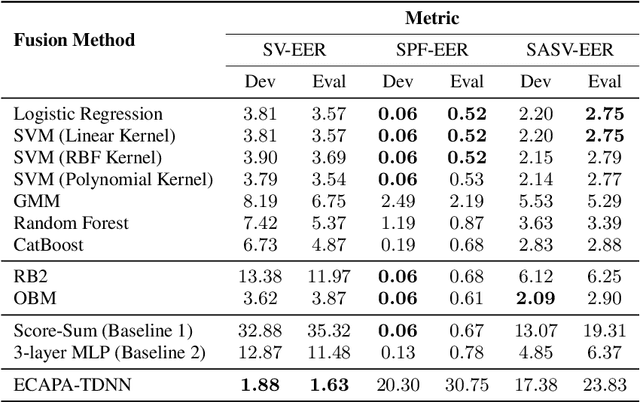
Automatic Speaker Verification (ASV) system is a type of bio-metric authentication. It can be attacked by an intruder, who falsifies data in order to get access to protected information. Countermeasures (CM) are special algorithms that detect these spoofing-attacks. While the ASVspoof Challenge series were focused on the development of CM for fixed ASV system, the new Spoofing Aware Speaker Verification (SASV) Challenge organizers believe that best results can be achieved if CM and ASV systems are optimized jointly. One of the approaches for cooperative optimization is a fusion over embeddings or scores obtained from ASV and CM models. The baselines of SASV Challenge 2022 present two types of fusion: score-sum and back-end ensemble with a 3-layer MLP. This paper describes our research of other fusion methods, including boosting over embeddings, which has not been used in anti-spoofing studies before.
Sign and Basis Invariant Networks for Spectral Graph Representation Learning
Apr 11, 2022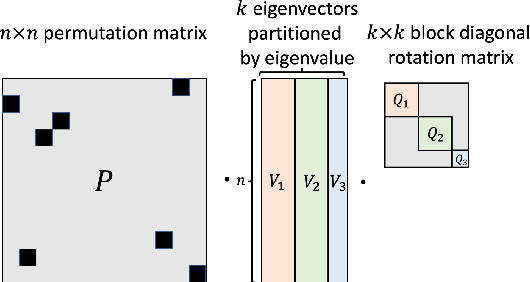
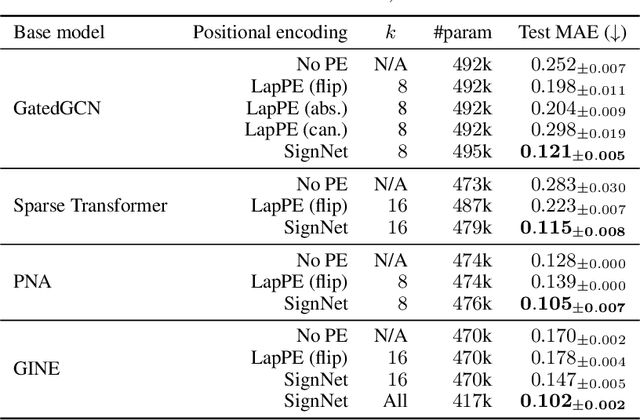

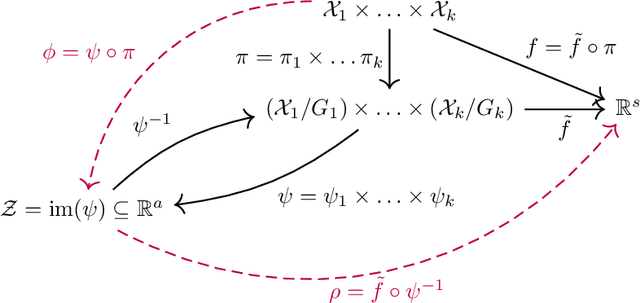
Many machine learning tasks involve processing eigenvectors derived from data. Especially valuable are Laplacian eigenvectors, which capture useful structural information about graphs and other geometric objects. However, ambiguities arise when computing eigenvectors: for each eigenvector $v$, the sign flipped $-v$ is also an eigenvector. More generally, higher dimensional eigenspaces contain infinitely many choices of basis eigenvectors. These ambiguities make it a challenge to process eigenvectors and eigenspaces in a consistent way. In this work we introduce SignNet and BasisNet -- new neural architectures that are invariant to all requisite symmetries and hence process collections of eigenspaces in a principled manner. Our networks are universal, i.e., they can approximate any continuous function of eigenvectors with the proper invariances. They are also theoretically strong for graph representation learning -- they can approximate any spectral graph convolution, can compute spectral invariants that go beyond message passing neural networks, and can provably simulate previously proposed graph positional encodings. Experiments show the strength of our networks for molecular graph regression, learning expressive graph representations, and learning implicit neural representations on triangle meshes. Our code is available at https://github.com/cptq/SignNet-BasisNet .