 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Do Transformers Encode a Foundational Ontology? Probing Abstract Classes in Natural Language
Jan 25, 2022
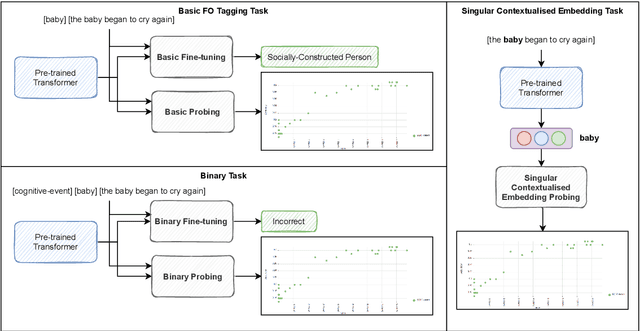
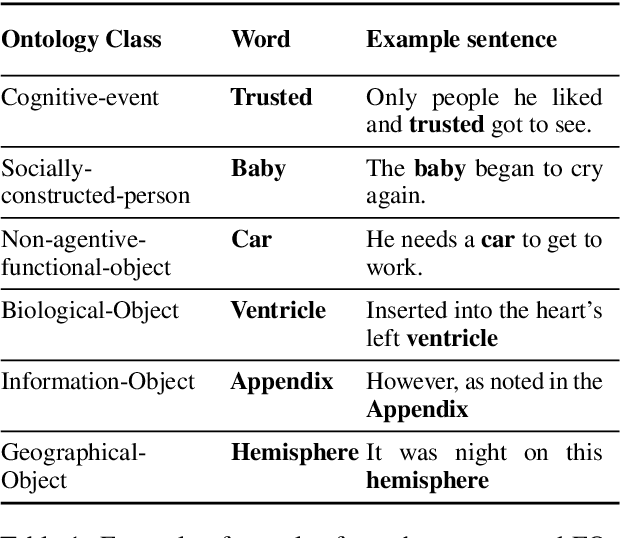

With the methodological support of probing (or diagnostic classification), recent studies have demonstrated that Transformers encode syntactic and semantic information to some extent. Following this line of research, this paper aims at taking semantic probing to an abstraction extreme with the goal of answering the following research question: can contemporary Transformer-based models reflect an underlying Foundational Ontology? To this end, we present a systematic Foundational Ontology (FO) probing methodology to investigate whether Transformers-based models encode abstract semantic information. Following different pre-training and fine-tuning regimes, we present an extensive evaluation of a diverse set of large-scale language models over three distinct and complementary FO tagging experiments. Specifically, we present and discuss the following conclusions: (1) The probing results indicate that Transformer-based models incidentally encode information related to Foundational Ontologies during the pre-training pro-cess; (2) Robust FO taggers (accuracy of 90 percent)can be efficiently built leveraging on this knowledge.
Decision-Dependent Risk Minimization in Geometrically Decaying Dynamic Environments
Apr 08, 2022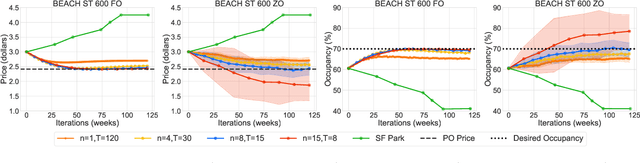

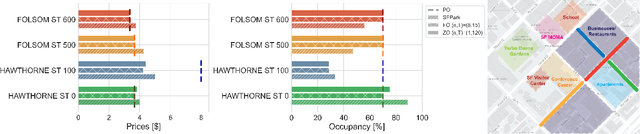
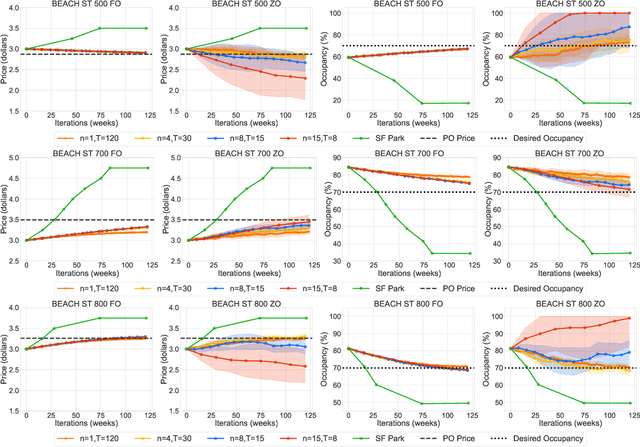
This paper studies the problem of expected loss minimization given a data distribution that is dependent on the decision-maker's action and evolves dynamically in time according to a geometric decay process. Novel algorithms for both the information setting in which the decision-maker has a first order gradient oracle and the setting in which they have simply a loss function oracle are introduced. The algorithms operate on the same underlying principle: the decision-maker repeatedly deploys a fixed decision over the length of an epoch, thereby allowing the dynamically changing environment to sufficiently mix before updating the decision. The iteration complexity in each of the settings is shown to match existing rates for first and zero order stochastic gradient methods up to logarithmic factors. The algorithms are evaluated on a "semi-synthetic" example using real world data from the SFpark dynamic pricing pilot study; it is shown that the announced prices result in an improvement for the institution's objective (target occupancy), while achieving an overall reduction in parking rates.
MAT: Mask-Aware Transformer for Large Hole Image Inpainting
Mar 30, 2022



Recent studies have shown the importance of modeling long-range interactions in the inpainting problem. To achieve this goal, existing approaches exploit either standalone attention techniques or transformers, but usually under a low resolution in consideration of computational cost. In this paper, we present a novel transformer-based model for large hole inpainting, which unifies the merits of transformers and convolutions to efficiently process high-resolution images. We carefully design each component of our framework to guarantee the high fidelity and diversity of recovered images. Specifically, we customize an inpainting-oriented transformer block, where the attention module aggregates non-local information only from partial valid tokens, indicated by a dynamic mask. Extensive experiments demonstrate the state-of-the-art performance of the new model on multiple benchmark datasets. Code is released at https://github.com/fenglinglwb/MAT.
Progressive Subsampling for Oversampled Data -- Application to Quantitative MRI
Apr 08, 2022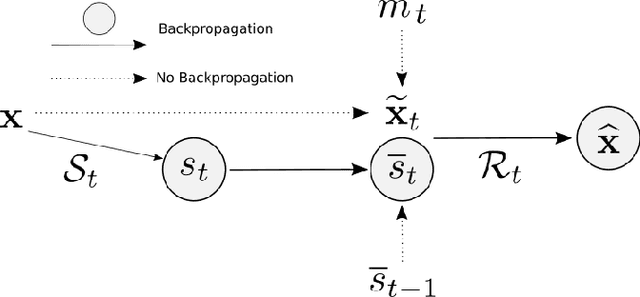
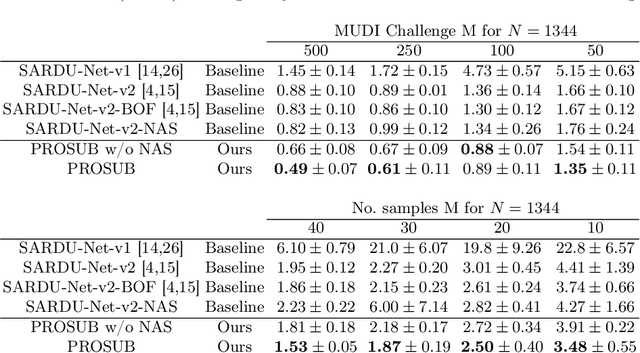
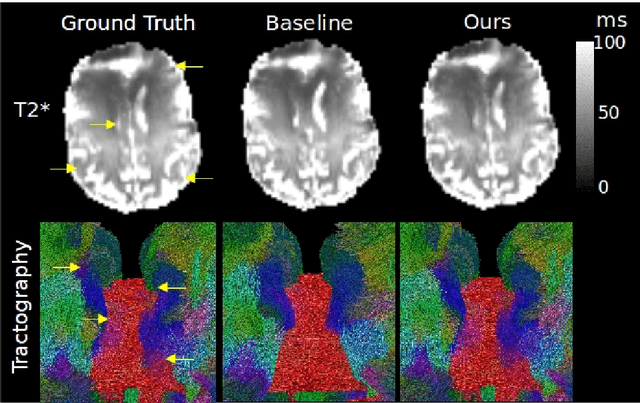
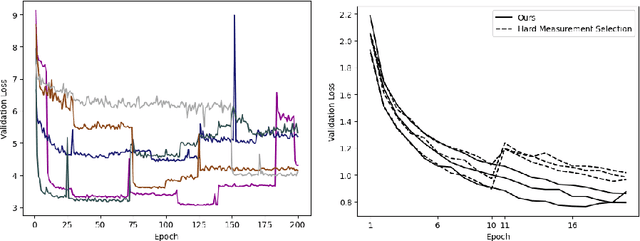
We present PROSUB: PROgressive SUBsampling, a deep learning based, automated methodology that subsamples an oversampled data set (e.g. multi-channeled 3D images) with minimal loss of information. We build upon a recent dual-network approach that won the MICCAI MUlti-DIffusion (MUDI) quantitative MRI measurement sampling-reconstruction challenge, but suffers from deep learning training instability, by subsampling with a hard decision boundary. PROSUB uses the paradigm of recursive feature elimination (RFE) and progressively subsamples measurements during deep learning training, improving optimization stability. PROSUB also integrates a neural architecture search (NAS) paradigm, allowing the network architecture hyperparameters to respond to the subsampling process. We show PROSUB outperforms the winner of the MUDI MICCAI challenge, producing large improvements >18% MSE on the MUDI challenge sub-tasks and qualitative improvements on downstream processes useful for clinical applications. We also show the benefits of incorporating NAS and analyze the effect of PROSUB's components. As our method generalizes to other problems beyond MRI measurement selection-reconstruction, our code is https://github.com/sbb-gh/PROSUB
Connect, Not Collapse: Explaining Contrastive Learning for Unsupervised Domain Adaptation
Apr 01, 2022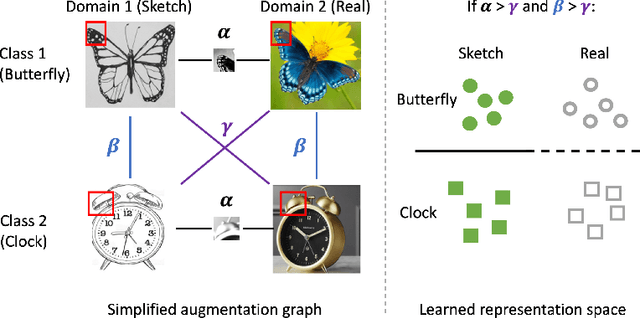
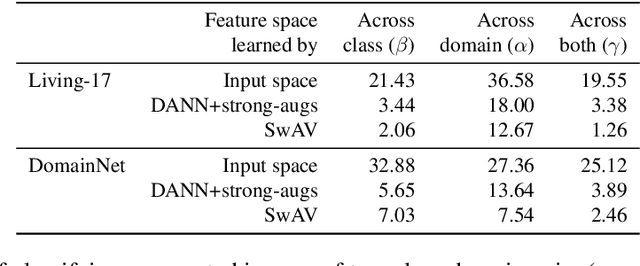
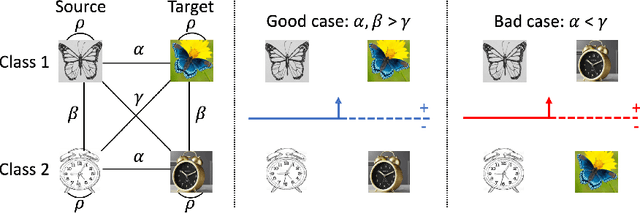

We consider unsupervised domain adaptation (UDA), where labeled data from a source domain (e.g., photographs) and unlabeled data from a target domain (e.g., sketches) are used to learn a classifier for the target domain. Conventional UDA methods (e.g., domain adversarial training) learn domain-invariant features to improve generalization to the target domain. In this paper, we show that contrastive pre-training, which learns features on unlabeled source and target data and then fine-tunes on labeled source data, is competitive with strong UDA methods. However, we find that contrastive pre-training does not learn domain-invariant features, diverging from conventional UDA intuitions. We show theoretically that contrastive pre-training can learn features that vary subtantially across domains but still generalize to the target domain, by disentangling domain and class information. Our results suggest that domain invariance is not necessary for UDA. We empirically validate our theory on benchmark vision datasets.
Fine-tuning Image Transformers using Learnable Memory
Mar 30, 2022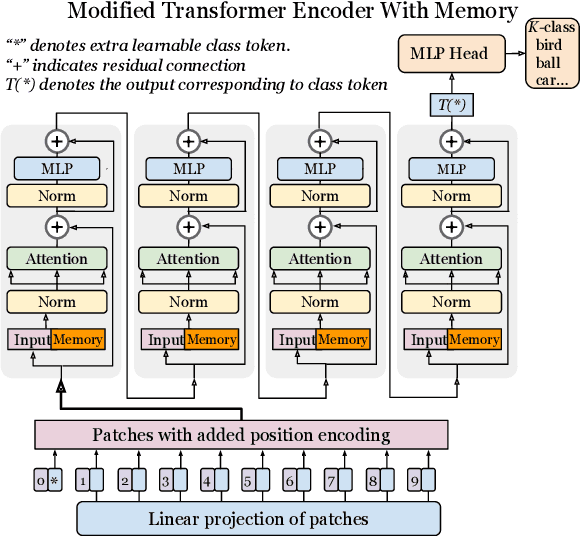
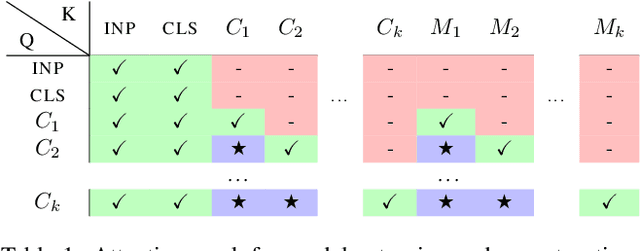
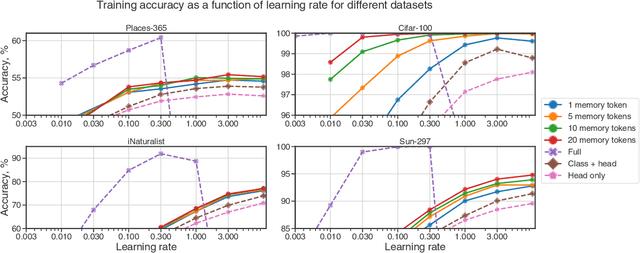
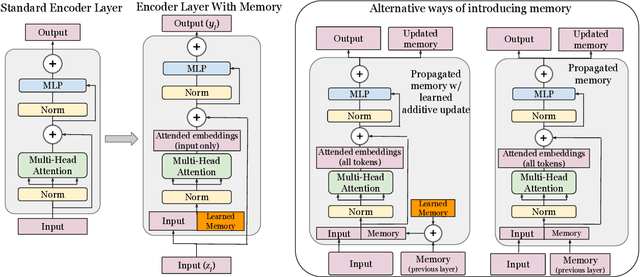
In this paper we propose augmenting Vision Transformer models with learnable memory tokens. Our approach allows the model to adapt to new tasks, using few parameters, while optionally preserving its capabilities on previously learned tasks. At each layer we introduce a set of learnable embedding vectors that provide contextual information useful for specific datasets. We call these "memory tokens". We show that augmenting a model with just a handful of such tokens per layer significantly improves accuracy when compared to conventional head-only fine-tuning, and performs only slightly below the significantly more expensive full fine-tuning. We then propose an attention-masking approach that enables extension to new downstream tasks, with a computation reuse. In this setup in addition to being parameters efficient, models can execute both old and new tasks as a part of single inference at a small incremental cost.
Towards a Deeper Understanding of Skeleton-based Gait Recognition
Apr 16, 2022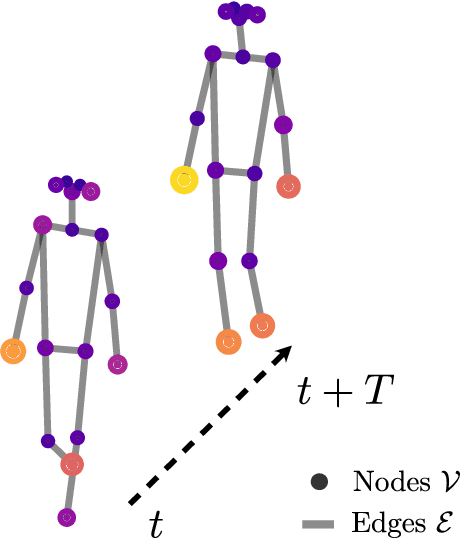
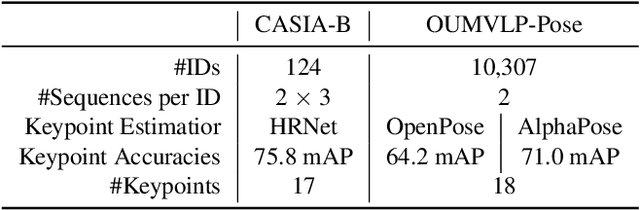
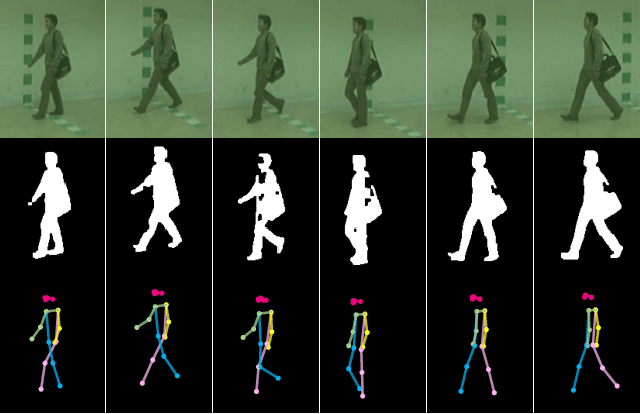
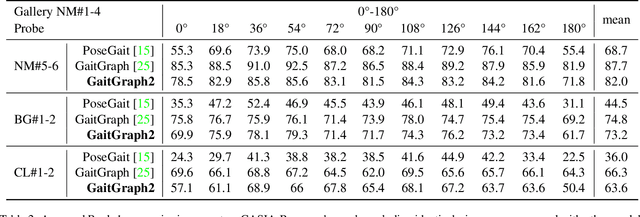
Gait recognition is a promising biometric with unique properties for identifying individuals from a long distance by their walking patterns. In recent years, most gait recognition methods used the person's silhouette to extract the gait features. However, silhouette images can lose fine-grained spatial information, suffer from (self) occlusion, and be challenging to obtain in real-world scenarios. Furthermore, these silhouettes also contain other visual clues that are not actual gait features and can be used for identification, but also to fool the system. Model-based methods do not suffer from these problems and are able to represent the temporal motion of body joints, which are actual gait features. The advances in human pose estimation started a new era for model-based gait recognition with skeleton-based gait recognition. In this work, we propose an approach based on Graph Convolutional Networks (GCNs) that combines higher-order inputs, and residual networks to an efficient architecture for gait recognition. Extensive experiments on the two popular gait datasets, CASIA-B and OUMVLP-Pose, show a massive improvement (3x) of the state-of-the-art (SotA) on the largest gait dataset OUMVLP-Pose and strong temporal modeling capabilities. Finally, we visualize our method to understand skeleton-based gait recognition better and to show that we model real gait features.
On-Device Next-Item Recommendation with Self-Supervised Knowledge Distillation
Apr 23, 2022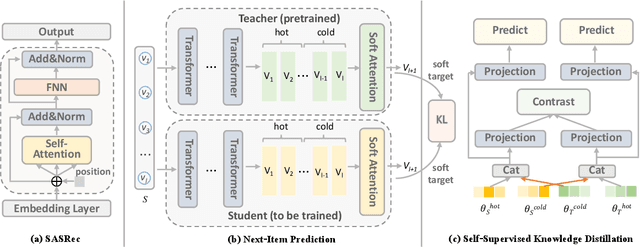
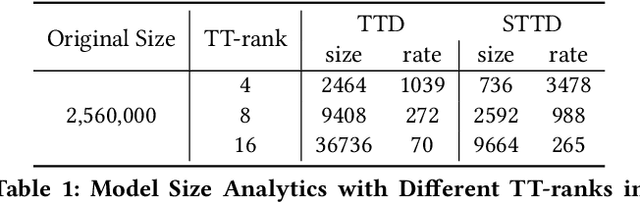
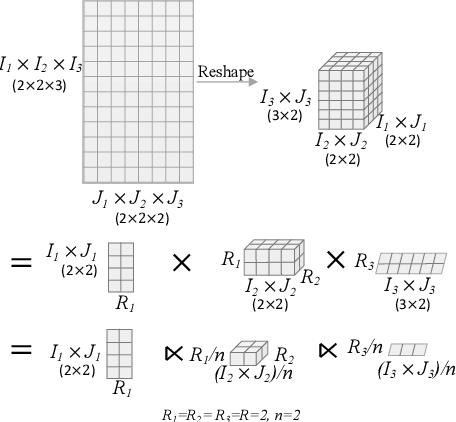

Modern recommender systems operate in a fully server-based fashion. To cater to millions of users, the frequent model maintaining and the high-speed processing for concurrent user requests are required, which comes at the cost of a huge carbon footprint. Meanwhile, users need to upload their behavior data even including the immediate environmental context to the server, raising the public concern about privacy. On-device recommender systems circumvent these two issues with cost-conscious settings and local inference. However, due to the limited memory and computing resources, on-device recommender systems are confronted with two fundamental challenges: (1) how to reduce the size of regular models to fit edge devices? (2) how to retain the original capacity? Previous research mostly adopts tensor decomposition techniques to compress the regular recommendation model with limited compression ratio so as to avoid drastic performance degradation. In this paper, we explore ultra-compact models for next-item recommendation, by loosing the constraint of dimensionality consistency in tensor decomposition. Meanwhile, to compensate for the capacity loss caused by compression, we develop a self-supervised knowledge distillation framework which enables the compressed model (student) to distill the essential information lying in the raw data, and improves the long-tail item recommendation through an embedding-recombination strategy with the original model (teacher). The extensive experiments on two benchmarks demonstrate that, with 30x model size reduction, the compressed model almost comes with no accuracy loss, and even outperforms its uncompressed counterpart in most cases.
Demystifying Deep Learning in Predictive Spatio-Temporal Analytics: An Information-Theoretic Framework
Sep 17, 2020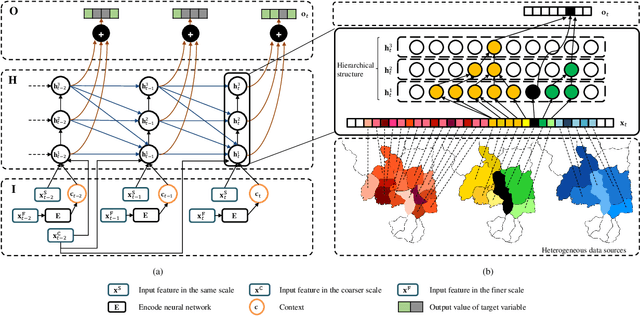
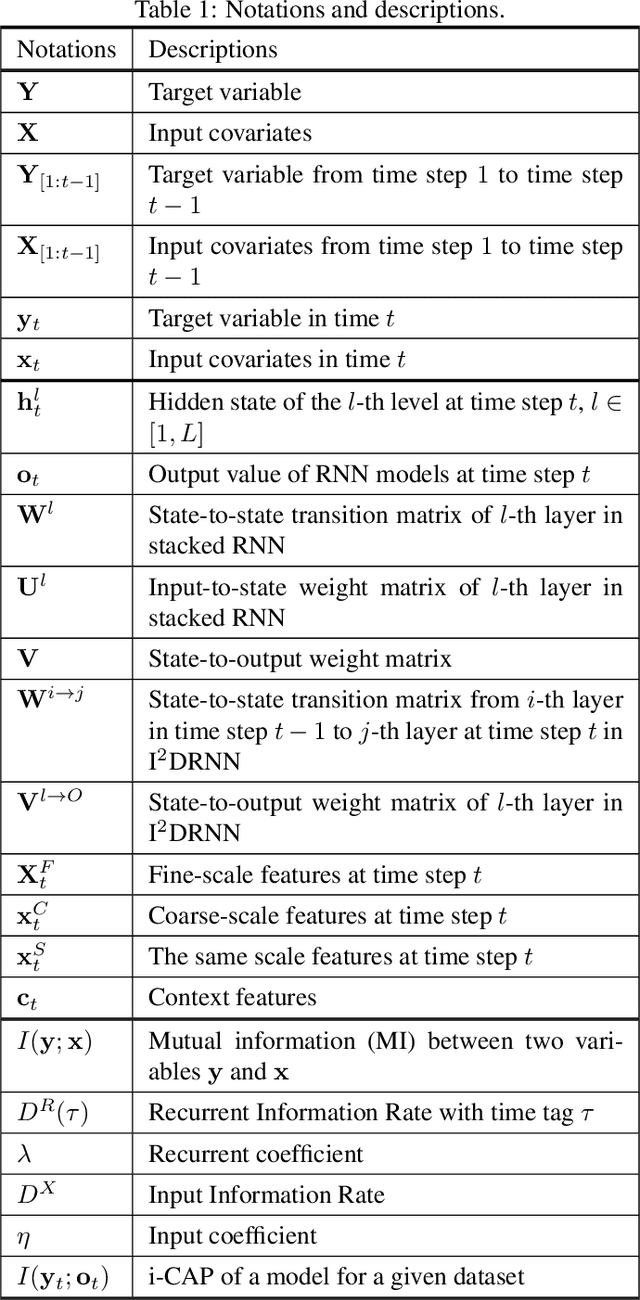
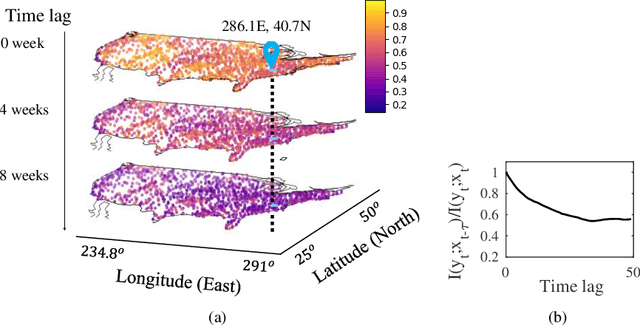
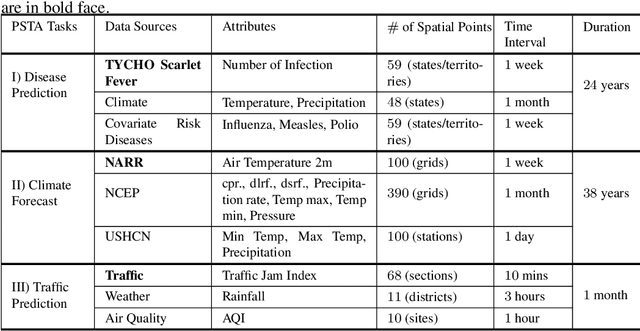
Deep learning has achieved incredible success over the past years, especially in various challenging predictive spatio-temporal analytics (PSTA) tasks, such as disease prediction, climate forecast, and traffic prediction, where intrinsic dependency relationships among data exist and generally manifest at multiple spatio-temporal scales. However, given a specific PSTA task and the corresponding dataset, how to appropriately determine the desired configuration of a deep learning model, theoretically analyze the model's learning behavior, and quantitatively characterize the model's learning capacity remains a mystery. In order to demystify the power of deep learning for PSTA, in this paper, we provide a comprehensive framework for deep learning model design and information-theoretic analysis. First, we develop and demonstrate a novel interactively- and integratively-connected deep recurrent neural network (I$^2$DRNN) model. I$^2$DRNN consists of three modules: an Input module that integrates data from heterogeneous sources; a Hidden module that captures the information at different scales while allowing the information to flow interactively between layers; and an Output module that models the integrative effects of information from various hidden layers to generate the output predictions. Second, to theoretically prove that our designed model can learn multi-scale spatio-temporal dependency in PSTA tasks, we provide an information-theoretic analysis to examine the information-based learning capacity (i-CAP) of the proposed model. Third, to validate the I$^2$DRNN model and confirm its i-CAP, we systematically conduct a series of experiments involving both synthetic datasets and real-world PSTA tasks. The experimental results show that the I$^2$DRNN model outperforms both classical and state-of-the-art models, and is able to capture meaningful multi-scale spatio-temporal dependency.
Towards Unbiased Multi-label Zero-Shot Learning with Pyramid and Semantic Attention
Mar 07, 2022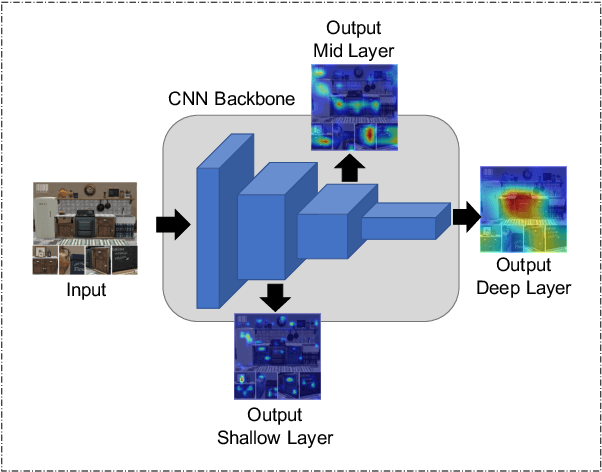
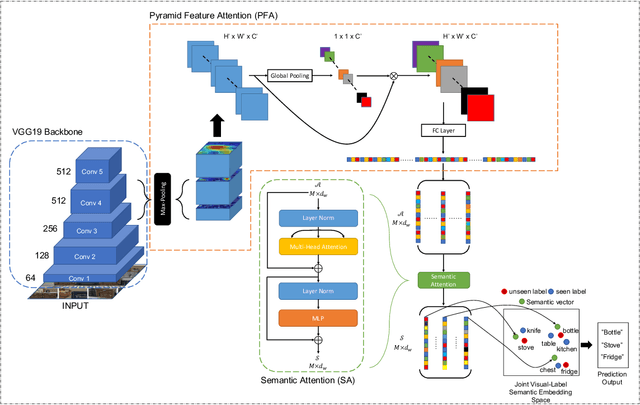
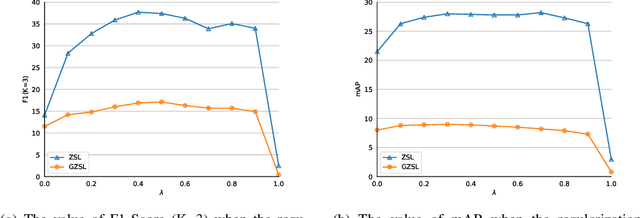

Multi-label zero-shot learning extends conventional single-label zero-shot learning to a more realistic scenario that aims at recognizing multiple unseen labels of classes for each input sample. Existing works usually exploit attention mechanism to generate the correlation among different labels. However, most of them are usually biased on several major classes while neglect most of the minor classes with the same importance in input samples, and may thus result in overly diffused attention maps that cannot sufficiently cover minor classes. We argue that disregarding the connection between major and minor classes, i.e., correspond to the global and local information, respectively, is the cause of the problem. In this paper, we propose a novel framework of unbiased multi-label zero-shot learning, by considering various class-specific regions to calibrate the training process of the classifier. Specifically, Pyramid Feature Attention (PFA) is proposed to build the correlation between global and local information of samples to balance the presence of each class. Meanwhile, for the generated semantic representations of input samples, we propose Semantic Attention (SA) to strengthen the element-wise correlation among these vectors, which can encourage the coordinated representation of them. Extensive experiments on the large-scale multi-label zero-shot benchmarks NUS-WIDE and Open-Image demonstrate that the proposed method surpasses other representative methods by significant margins.