 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-Domain Sentiment Classification with Contrastive Learning and Mutual Information Maximization
Nov 12, 2020
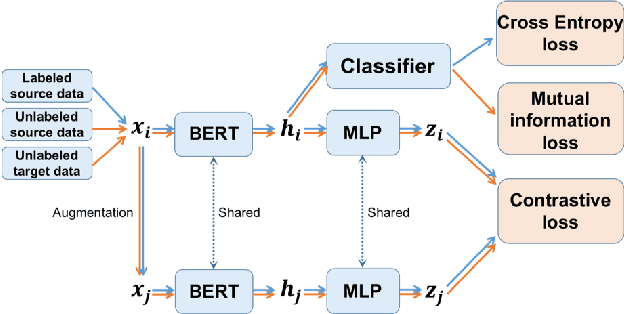
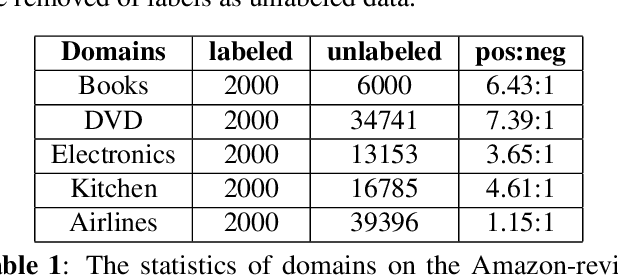
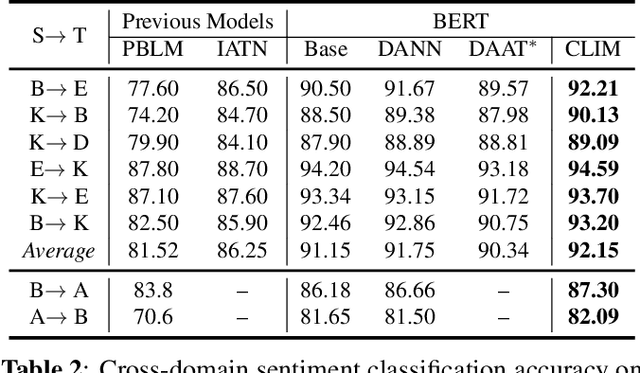

Contrastive learning (CL) has been successful as a powerful representation learning method. In this work we propose CLIM: Contrastive Learning with mutual Information Maximization, to explore the potential of CL on cross-domain sentiment classification. To the best of our knowledge, CLIM is the first to adopt contrastive learning for natural language processing (NLP) tasks across domains. Due to scarcity of labels on the target domain, we introduce mutual information maximization (MIM) apart from CL to exploit the features that best support the final prediction. Furthermore, MIM is able to maintain a relatively balanced distribution of the model's prediction, and enlarges the margin between classes on the target domain. The larger margin increases our model's robustness and enables the same classifier to be optimal across domains. Consequently, we achieve new state-of-the-art results on the Amazon-review dataset as well as the airlines dataset, showing the efficacy of our proposed method CLIM.
Secure Rate-Splitting for the MIMO Broadcast Channel with Imperfect CSIT and a Jammer
Jan 23, 2022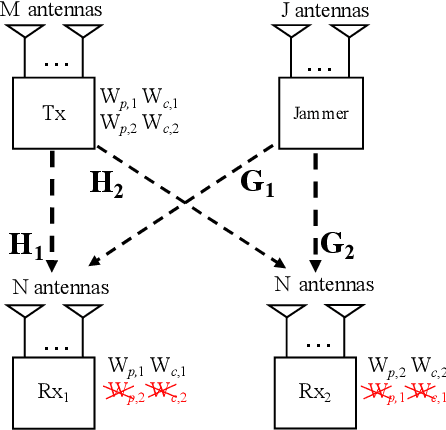
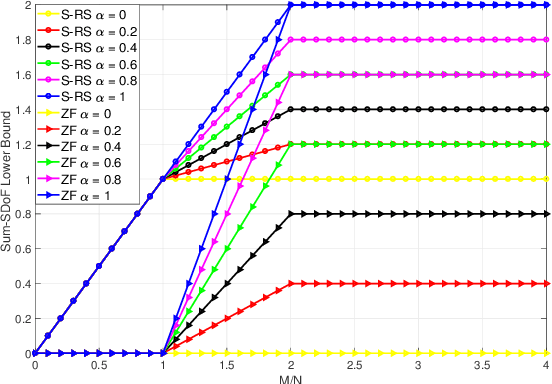
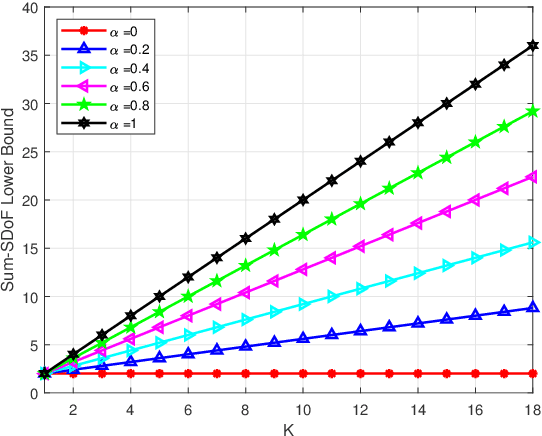
In this paper, we investigate the secure rate-splitting for the two-user multiple-input multiple-output (MIMO) broadcast channel with imperfect channel state information at the transmitter (CSIT) and a multiple-antenna jammer, where each receiver has equal number of antennas and the jammer has perfect channel state information (CSI). Specifically, we design the secure rate-splitting multiple-access in this scenario, where the security of splitted private and common messages is ensured by precoder design with joint nulling and aligning the leakage information, regarding to different antenna configurations. As a result, we show that the sum-secure degrees-of-freedom (SDoF) achieved by secure rate-splitting outperforms that by conventional zero-forcing. Therefore, we validate the superiority of rate-splitting for the secure purpose in the two-user MIMO broadcast channel with imperfect CSIT and a jammer.
One Model to Synthesize Them All: Multi-contrast Multi-scale Transformer for Missing Data Imputation
Apr 28, 2022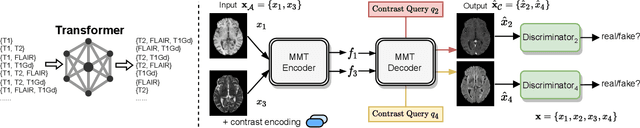
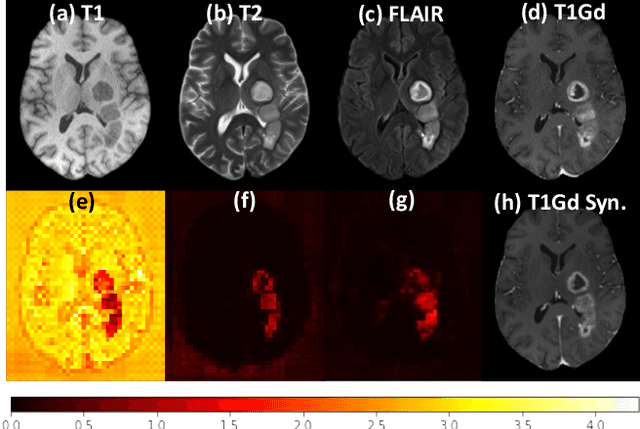
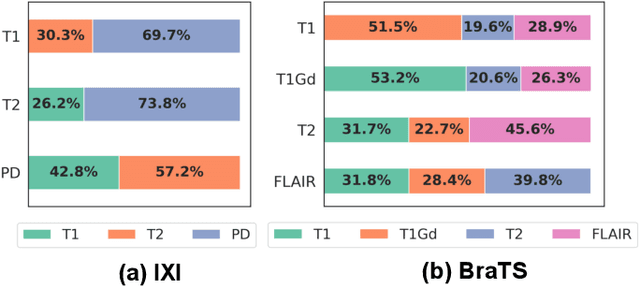
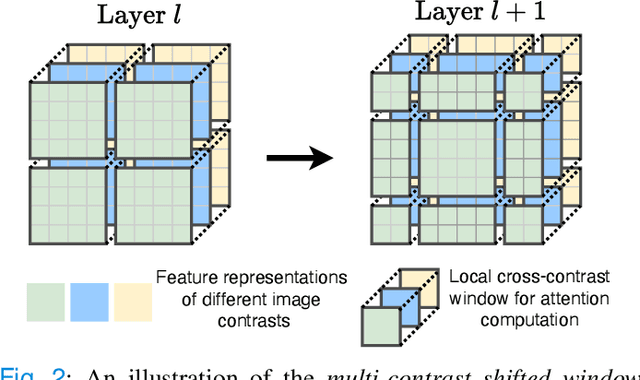
Multi-contrast magnetic resonance imaging (MRI) is widely used in clinical practice as each contrast provides complementary information. However, the availability of each contrast may vary amongst patients in reality. This poses challenges to both radiologists and automated image analysis algorithms. A general approach for tackling this problem is missing data imputation, which aims to synthesize the missing contrasts from existing ones. While several convolutional neural network (CNN) based algorithms have been proposed, they suffer from the fundamental limitations of CNN models, such as requirement for fixed numbers of input and output channels, inability to capture long-range dependencies, and lack of interpretability. In this paper, we formulate missing data imputation as a sequence-to-sequence learning problem and propose a multi-contrast multi-scale Transformer (MMT), which can take any subset of input contrasts and synthesize those that are missing. MMT consists of a multi-scale Transformer encoder that builds hierarchical representations of inputs combined with a multi-scale Transformer decoder that generates the outputs in a coarse-to-fine fashion. Thanks to the proposed multi-contrast Swin Transformer blocks, it can efficiently capture intra- and inter-contrast dependencies for accurate image synthesis. Moreover, MMT is inherently interpretable. It allows us to understand the importance of each input contrast in different regions by analyzing the in-built attention maps of Transformer blocks in the decoder. Extensive experiments on two large-scale multi-contrast MRI datasets demonstrate that MMT outperforms the state-of-the-art methods quantitatively and qualitatively.
Articulated Objects in Free-form Hand Interaction
Apr 28, 2022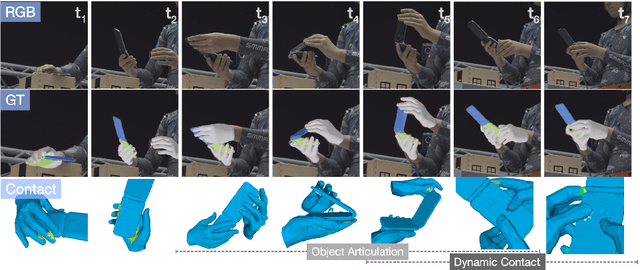

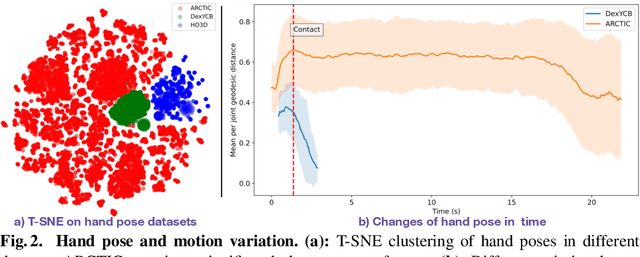
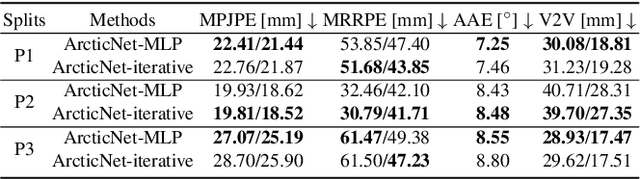
We use our hands to interact with and to manipulate objects. Articulated objects are especially interesting since they often require the full dexterity of human hands to manipulate them. To understand, model, and synthesize such interactions, automatic and robust methods that reconstruct hands and articulated objects in 3D from a color image are needed. Existing methods for estimating 3D hand and object pose from images focus on rigid objects. In part, because such methods rely on training data and no dataset of articulated object manipulation exists. Consequently, we introduce ARCTIC - the first dataset of free-form interactions of hands and articulated objects. ARCTIC has 1.2M images paired with accurate 3D meshes for both hands and for objects that move and deform over time. The dataset also provides hand-object contact information. To show the value of our dataset, we perform two novel tasks on ARCTIC: (1) 3D reconstruction of two hands and an articulated object in interaction; (2) an estimation of dense hand-object relative distances, which we call interaction field estimation. For the first task, we present ArcticNet, a baseline method for the task of jointly reconstructing two hands and an articulated object from an RGB image. For interaction field estimation, we predict the relative distances from each hand vertex to the object surface, and vice versa. We introduce InterField, the first method that estimates such distances from a single RGB image. We provide qualitative and quantitative experiments for both tasks, and provide detailed analysis on the data. Code and data will be available at https://arctic.is.tue.mpg.de.
Robotic and Generative Adversarial Attacks in Offline Writer-independent Signature Verification
Apr 14, 2022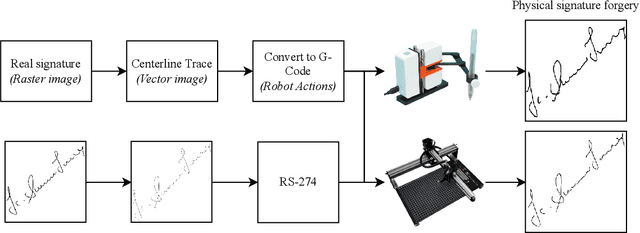
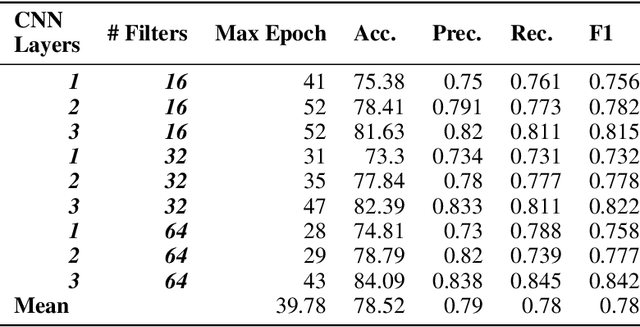

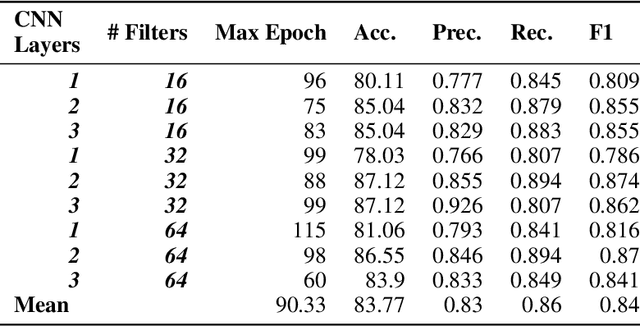
This study explores how robots and generative approaches can be used to mount successful false-acceptance adversarial attacks on signature verification systems. Initially, a convolutional neural network topology and data augmentation strategy are explored and tuned, producing an 87.12% accurate model for the verification of 2,640 human signatures. Two robots are then tasked with forging 50 signatures, where 25 are used for the verification attack, and the remaining 25 are used for tuning of the model to defend against them. Adversarial attacks on the system show that there exists an information security risk; the Line-us robotic arm can fool the system 24% of the time and the iDraw 2.0 robot 32% of the time. A conditional GAN finds similar success, with around 30% forged signatures misclassified as genuine. Following fine-tune transfer learning of robotic and generative data, adversarial attacks are reduced below the model threshold by both robots and the GAN. It is observed that tuning the model reduces the risk of attack by robots to 8% and 12%, and that conditional generative adversarial attacks can be reduced to 4% when 25 images are presented and 5% when 1000 images are presented.
Simultaneous Communication and Tracking in Arbitrary Trajectories via Beam-Space Processing
Mar 29, 2022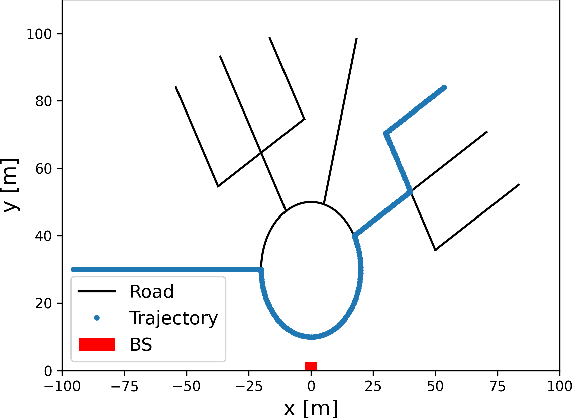
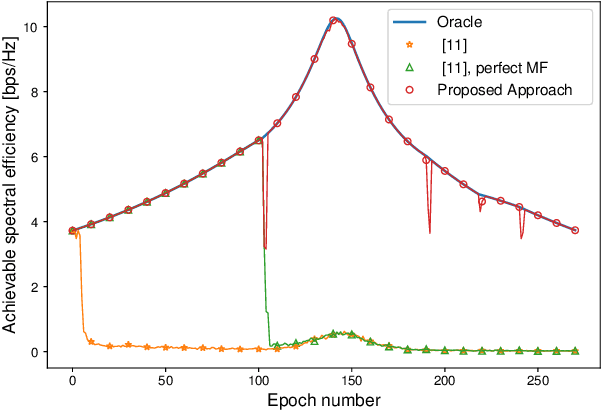
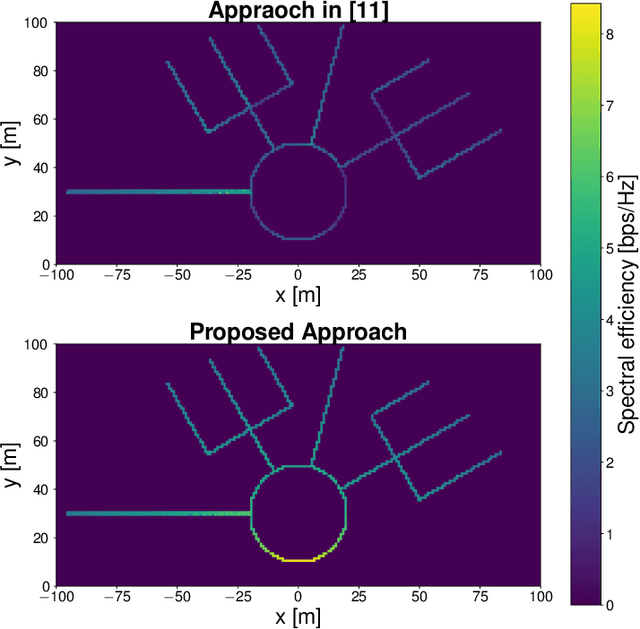
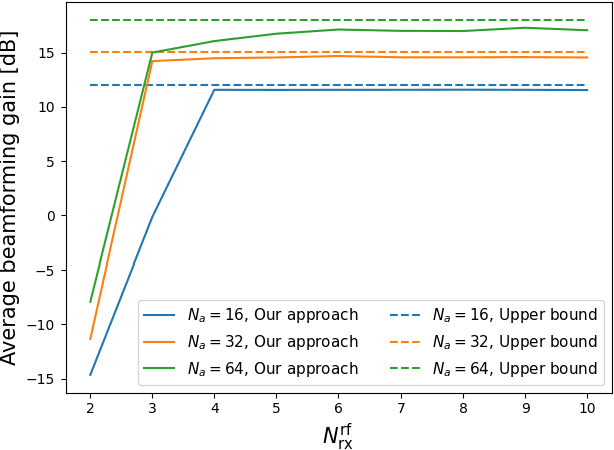
In this paper, we develop a beam tracking scheme for an orthogonal frequency division multiplexing (OFDM) Integrated Sensing and Communication (ISAC) system with a hybrid digital analog (HDA) architecture operating in the millimeter wave (mmWave) band. Our tracking method consists of an estimation step inspired by radar signal processing techniques, and a prediction step based on simple kinematic equations. The hybrid architecture exploits the predicted state information to focus only on the directions of interest, trading off beamforming gain, hardware complexity and multistream processing capabilities. Our extensive simulations in arbitrary trajectories show that the proposed method can outperform state of the art beam tracking methods in terms of prediction accuracy and consequently achievable communication rate, and is fully capable of dealing with highly non-linear dynamic motion patterns.
Zero-shot Entity and Tweet Characterization with Designed Conditional Prompts and Contexts
Apr 18, 2022


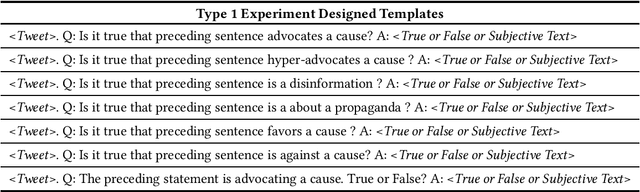
Online news and social media have been the de facto mediums to disseminate information globally from the beginning of the last decade. However, bias in content and purpose of intentions are not regulated, and managing bias is the responsibility of content consumers. In this regard, understanding the stances and biases of news sources towards specific entities becomes important. To address this problem, we use pretrained language models, which have been shown to bring about good results with no task-specific training or few-shot training. In this work, we approach the problem of characterizing Named Entities and Tweets as an open-ended text classification and open-ended fact probing problem.We evaluate the zero-shot language model capabilities of Generative Pretrained Transformer 2 (GPT-2) to characterize Entities and Tweets subjectively with human psychology-inspired and logical conditional prefixes and contexts. First, we fine-tune the GPT-2 model on a sufficiently large news corpus and evaluate subjective characterization of popular entities in the corpus by priming with prefixes. Second, we fine-tune GPT-2 with a Tweets corpus from a few popular hashtags and evaluate characterizing tweets by priming the language model with prefixes, questions, and contextual synopsis prompts. Entity characterization results were positive across measures and human evaluation.
Generalizable Person Re-Identification via Self-Supervised Batch Norm Test-Time Adaption
Mar 01, 2022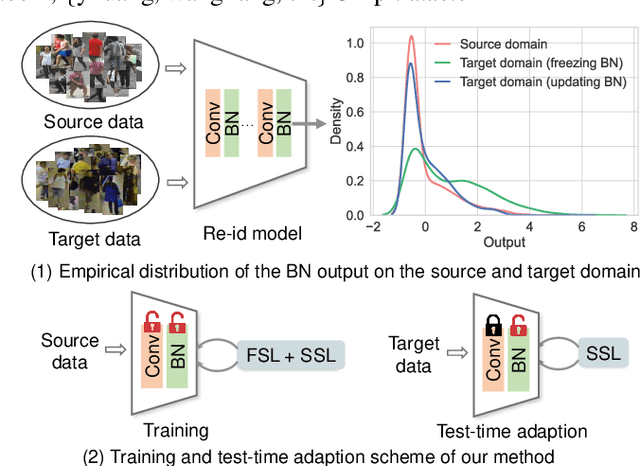
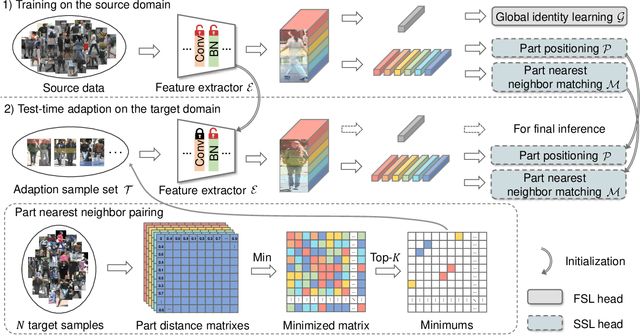
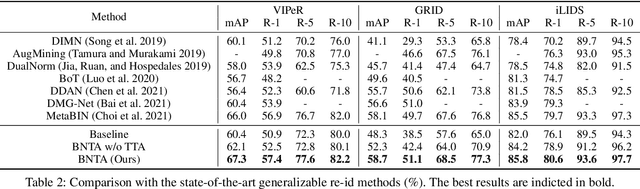
In this paper, we investigate the generalization problem of person re-identification (re-id), whose major challenge is the distribution shift on an unseen domain. As an important tool of regularizing the distribution, batch normalization (BN) has been widely used in existing methods. However, they neglect that BN is severely biased to the training domain and inevitably suffers the performance drop if directly generalized without being updated. To tackle this issue, we propose Batch Norm Test-time Adaption (BNTA), a novel re-id framework that applies the self-supervised strategy to update BN parameters adaptively. Specifically, BNTA quickly explores the domain-aware information within unlabeled target data before inference, and accordingly modulates the feature distribution normalized by BN to adapt to the target domain. This is accomplished by two designed self-supervised auxiliary tasks, namely part positioning and part nearest neighbor matching, which help the model mine the domain-aware information with respect to the structure and identity of body parts, respectively. To demonstrate the effectiveness of our method, we conduct extensive experiments on three re-id datasets and confirm the superior performance to the state-of-the-art methods.
Diverse Melody Generation from Chinese Lyrics via Mutual Information Maximization
Dec 07, 2020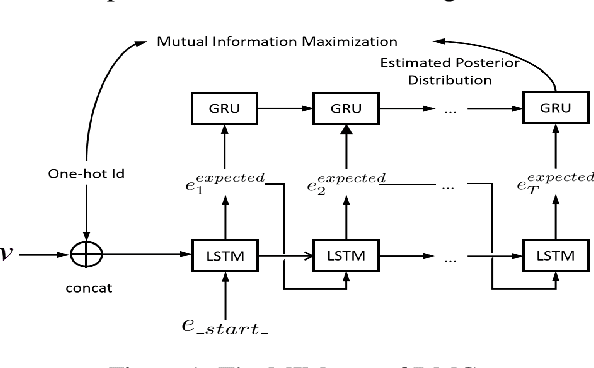
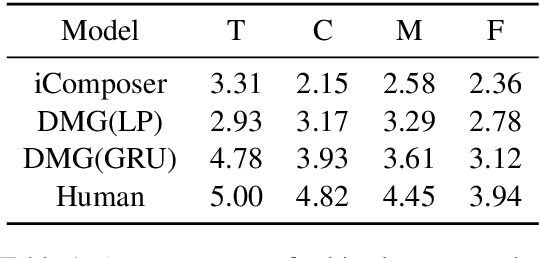
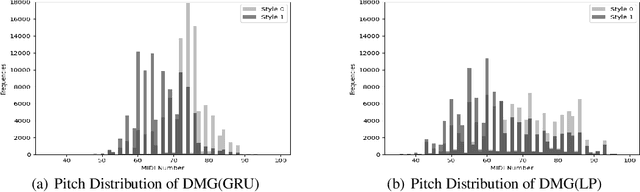

In this paper, we propose to adapt the method of mutual information maximization into the task of Chinese lyrics conditioned melody generation to improve the generation quality and diversity. We employ scheduled sampling and force decoding techniques to improve the alignment between lyrics and melodies. With our method, which we called Diverse Melody Generation (DMG), a sequence-to-sequence model learns to generate diverse melodies heavily depending on the input style ids, while keeping the tonality and improving the alignment. The experimental results of subjective tests show that DMG can generate more pleasing and coherent tunes than baseline methods.
Depth-Aware Generative Adversarial Network for Talking Head Video Generation
Mar 13, 2022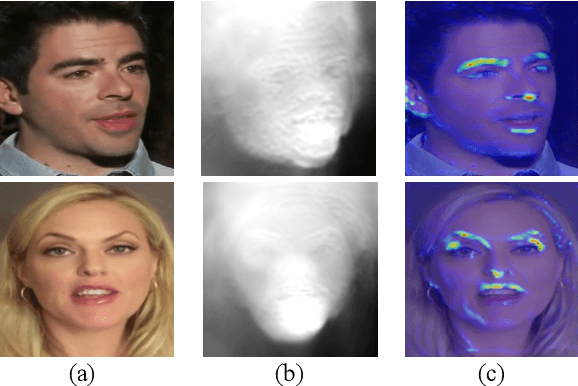
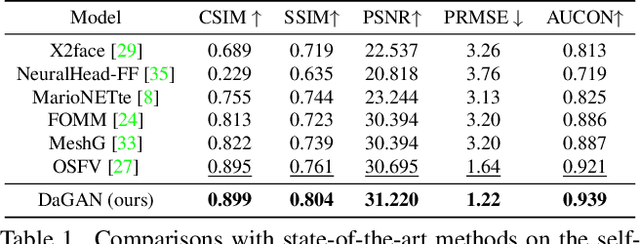
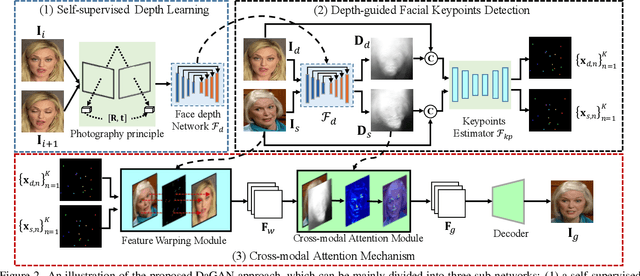
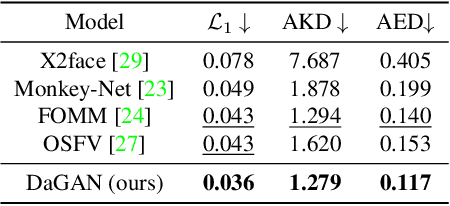
Talking head video generation aims to produce a synthetic human face video that contains the identity and pose information respectively from a given source image and a driving video.Existing works for this task heavily rely on 2D representations (e.g. appearance and motion) learned from the input images. However, dense 3D facial geometry (e.g. pixel-wise depth) is extremely important for this task as it is particularly beneficial for us to essentially generate accurate 3D face structures and distinguish noisy information from the possibly cluttered background. Nevertheless, dense 3D geometry annotations are prohibitively costly for videos and are typically not available for this video generation task. In this paper, we first introduce a self-supervised geometry learning method to automatically recover the dense 3D geometry (i.e.depth) from the face videos without the requirement of any expensive 3D annotation data. Based on the learned dense depth maps, we further propose to leverage them to estimate sparse facial keypoints that capture the critical movement of the human head. In a more dense way, the depth is also utilized to learn 3D-aware cross-modal (i.e. appearance and depth) attention to guide the generation of motion fields for warping source image representations. All these contributions compose a novel depth-aware generative adversarial network (DaGAN) for talking head generation. Extensive experiments conducted demonstrate that our proposed method can generate highly realistic faces, and achieve significant results on the unseen human faces.