 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VesNet-RL: Simulation-based Reinforcement Learning for Real-World US Probe Navigation
May 10, 2022
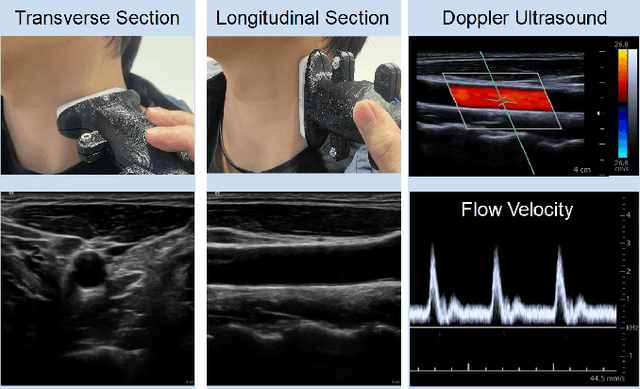
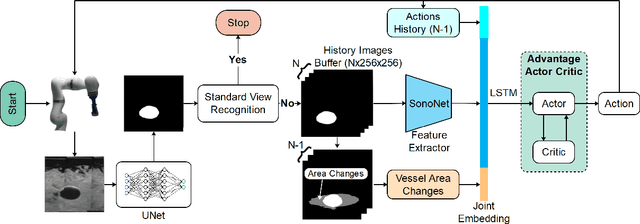
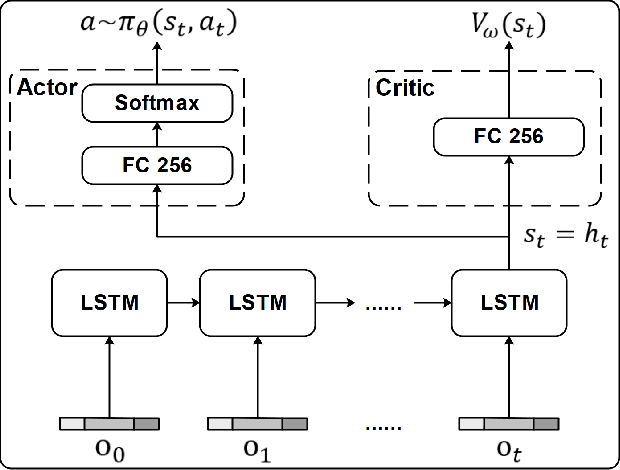
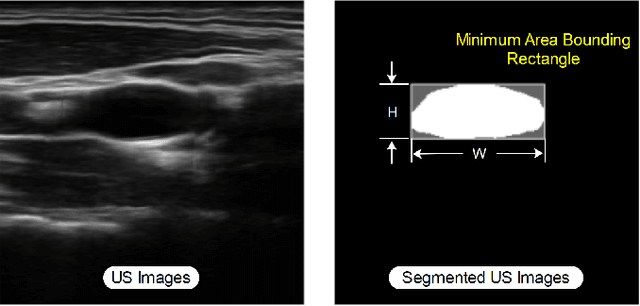
Ultrasound (US) is one of the most common medical imaging modalities since it is radiation-free, low-cost, and real-time. In freehand US examinations, sonographers often navigate a US probe to visualize standard examination planes with rich diagnostic information. However, reproducibility and stability of the resulting images often suffer from intra- and inter-operator variation. Reinforcement learning (RL), as an interaction-based learning method, has demonstrated its effectiveness in visual navigating tasks; however, RL is limited in terms of generalization. To address this challenge, we propose a simulation-based RL framework for real-world navigation of US probes towards the standard longitudinal views of vessels. A UNet is used to provide binary masks from US images; thereby, the RL agent trained on simulated binary vessel images can be applied in real scenarios without further training. To accurately characterize actual states, a multi-modality state representation structure is introduced to facilitate the understanding of environments. Moreover, considering the characteristics of vessels, a novel standard view recognition approach based on the minimum bounding rectangle is proposed to terminate the searching process. To evaluate the effectiveness of the proposed method, the trained policy is validated virtually on 3D volumes of a volunteer's in-vivo carotid artery, and physically on custom-designed gel phantoms using robotic US. The results demonstrate that proposed approach can effectively and accurately navigate the probe towards the longitudinal view of vessels.
Gaussian Process Self-triggered Policy Search in Weakly Observable Environments
May 07, 2022
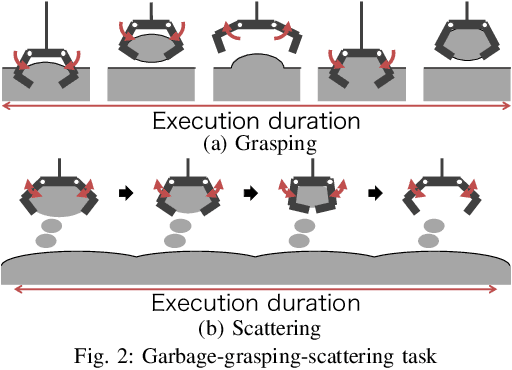
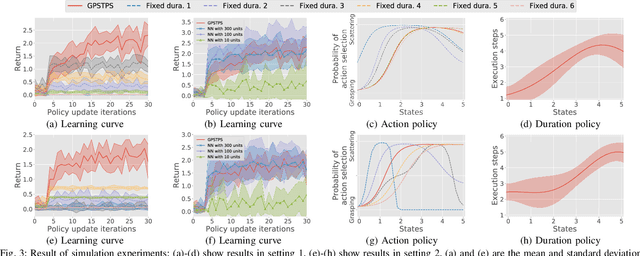

The environments of such large industrial machines as waste cranes in waste incineration plants are often weakly observable, where little information about the environmental state is contained in the observations due to technical difficulty or maintenance cost (e.g., no sensors for observing the state of the garbage to be handled). Based on the findings that skilled operators in such environments choose predetermined control strategies (e.g., grasping and scattering) and their durations based on sensor values, %thereby improving the robustness of their actions, we propose a novel non-parametric policy search algorithm: Gaussian process self-triggered policy search (GPSTPS). GPSTPS has two types of control policies: action and duration. A gating mechanism either maintains the action selected by the action policy for the duration specified by the duration policy or updates the action and duration by passing new observations to the policy; therefore, it is categorized as self-triggered. GPSTPS simultaneously learns both policies by trial and error based on sparse GP priors and variational learning to maximize the return. To verify the performance of our proposed method, we conducted experiments on garbage-grasping-scattering task for a waste crane with weak observations using a simulation and a robotic waste crane system. As experimental results, the proposed method acquired suitable policies to determine the action and duration based on the garbage's characteristics.
DIREG3D: DIrectly REGress 3D Hands from Multiple Cameras
Jan 26, 2022In this paper, we present DIREG3D, a holistic framework for 3D Hand Tracking. The proposed framework is capable of utilizing camera intrinsic parameters, 3D geometry, intermediate 2D cues, and visual information to regress parameters for accurately representing a Hand Mesh model. Our experiments show that information like the size of the 2D hand, its distance from the optical center, and radial distortion is useful for deriving highly reliable 3D poses in camera space from just monocular information. Furthermore, we extend these results to a multi-view camera setup by fusing features from different viewpoints.
BronchoPose: an analysis of data and model configuration for vision-based bronchoscopy pose estimation
Apr 25, 2022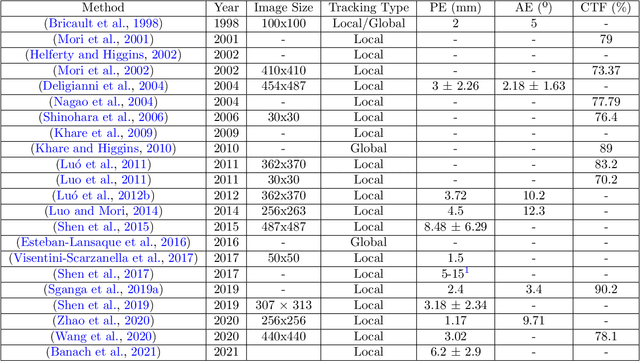
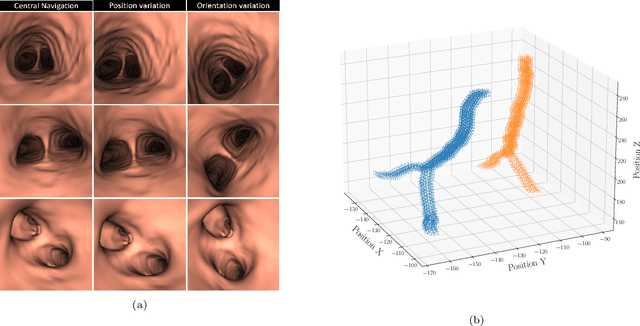
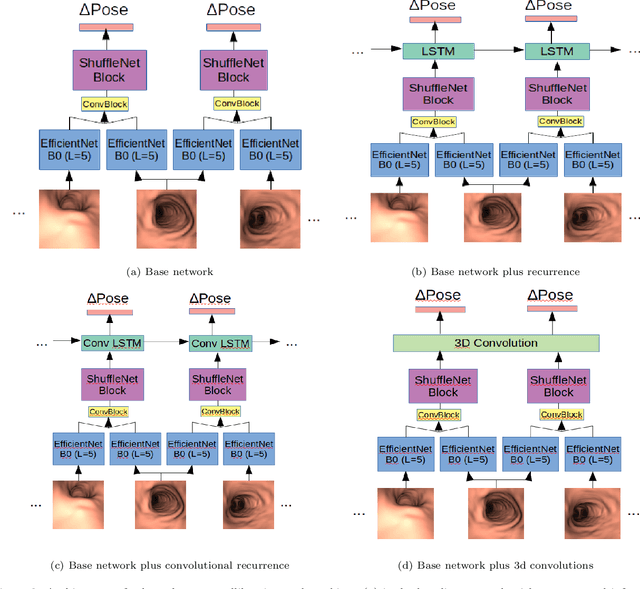
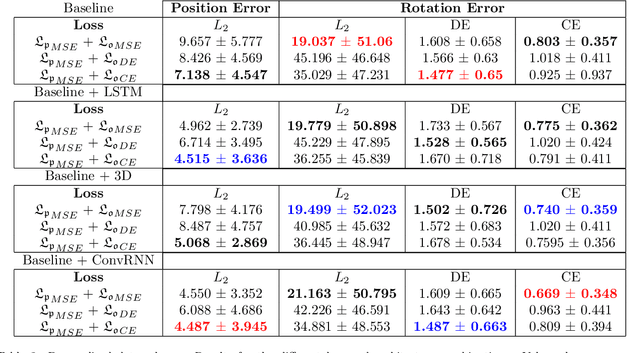
Vision-based bronchoscopy (VB) models require the registration of the virtual lung model with the frames from the video bronchoscopy to provide effective guidance during the biopsy. The registration can be achieved by either tracking the position and orientation of the bronchoscopy camera or by calibrating its deviation from the pose (position and orientation) simulated in the virtual lung model. Recent advances in neural networks and temporal image processing have provided new opportunities for guided bronchoscopy. However, such progress has been hindered by the lack of comparative experimental conditions. In the present paper, we share a novel synthetic dataset allowing for a fair comparison of methods. Moreover, this paper investigates several neural network architectures for the learning of temporal information at different levels of subject personalization. In order to improve orientation measurement, we also present a standardized comparison framework and a novel metric for camera orientation learning. Results on the dataset show that the proposed metric and architectures, as well as the standardized conditions, provide notable improvements to current state-of-the-art camera pose estimation in video bronchoscopy.
Computing Nash Equilibria in Multiplayer DAG-Structured Stochastic Games with Persistent Imperfect Information
Oct 26, 2020
Many important real-world settings contain multiple players interacting over an unknown duration with probabilistic state transitions, and are naturally modeled as stochastic games. Prior research on algorithms for stochastic games has focused on two-player zero-sum games, games with perfect information, and games with imperfect-information that is local and does not extend between game states. We present an algorithm for approximating Nash equilibrium in multiplayer general-sum stochastic games with persistent imperfect information that extends throughout game play. We experiment on a 4-player imperfect-information naval strategic planning scenario. Using a new procedure, we are able to demonstrate that our algorithm computes a strategy that closely approximates Nash equilibrium in this game.
Weakly Supervised Temporal Action Localization via Representative Snippet Knowledge Propagation
Mar 14, 2022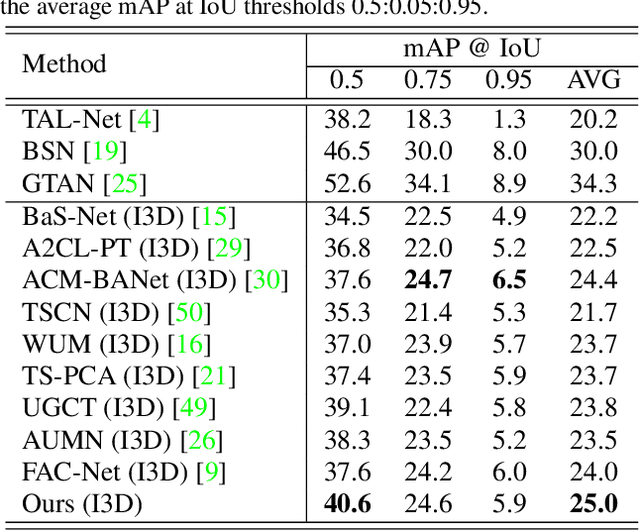
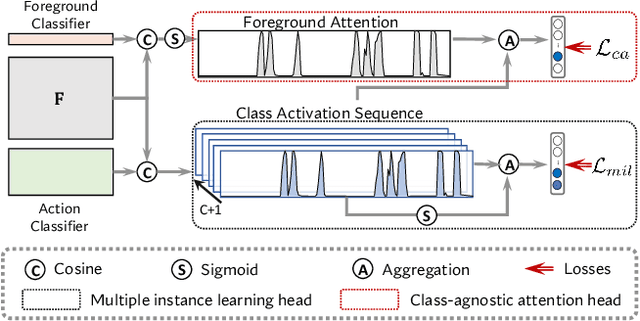
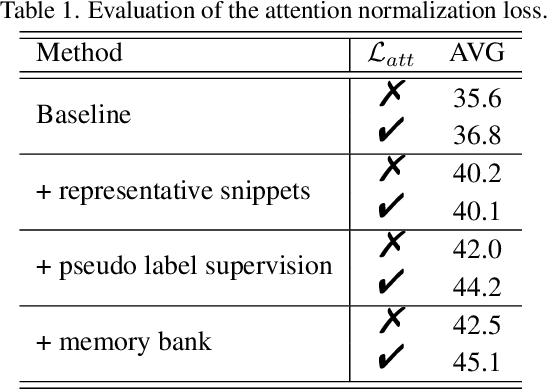
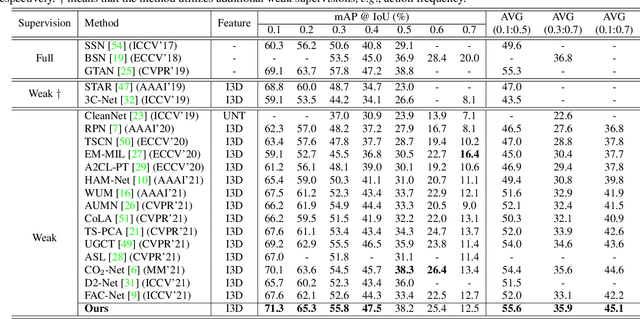
Weakly supervised temporal action localization aims to localize temporal boundaries of actions and simultaneously identify their categories with only video-level category labels. Many existing methods seek to generate pseudo labels for bridging the discrepancy between classification and localization, but usually only make use of limited contextual information for pseudo label generation. To alleviate this problem, we propose a representative snippet summarization and propagation framework. Our method seeks to mine the representative snippets in each video for propagating information between video snippets to generate better pseudo labels. For each video, its own representative snippets and the representative snippets from a memory bank are propagated to update the input features in an intra- and inter-video manner. The pseudo labels are generated from the temporal class activation maps of the updated features to rectify the predictions of the main branch. Our method obtains superior performance in comparison to the existing methods on two benchmarks, THUMOS14 and ActivityNet1.3, achieving gains as high as 1.2% in terms of average mAP on THUMOS14.
Learning to Transfer Prompts for Text Generation
May 03, 2022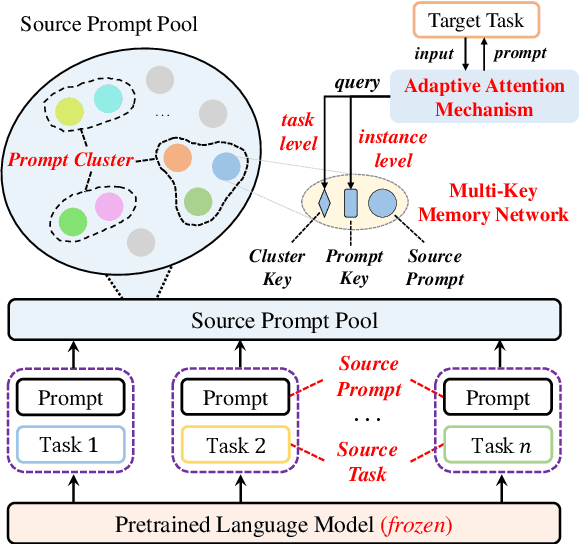
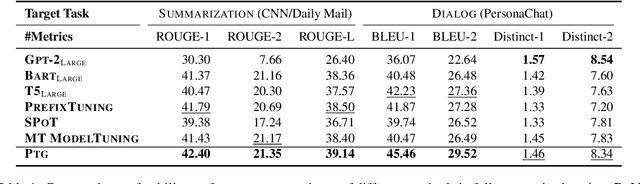
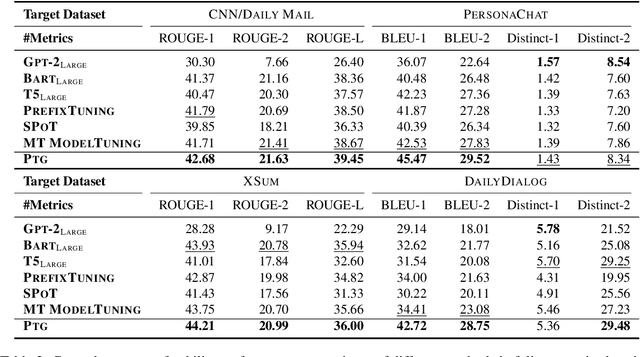
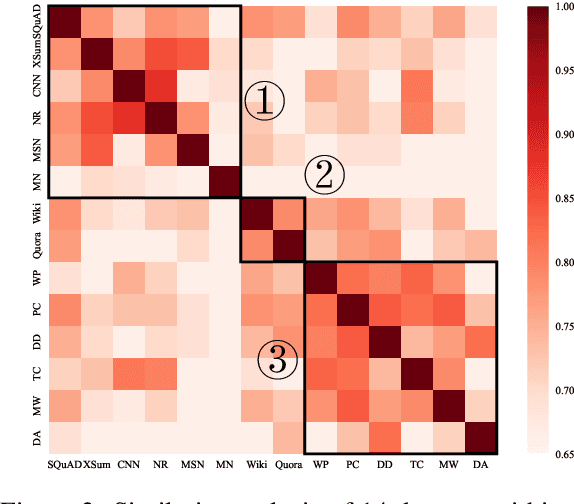
Pretrained language models (PLMs) have made remarkable progress in text generation tasks via fine-tuning. While, it is challenging to fine-tune PLMs in a data-scarce situation. Therefore, it is non-trivial to develop a general and lightweight model that can adapt to various text generation tasks based on PLMs. To fulfill this purpose, the recent prompt-based learning offers a potential solution. In this paper, we improve this technique and propose a novel prompt-based method (PTG) for text generation in a transferable setting. First, PTG learns a set of source prompts for various source generation tasks and then transfers these prompts as target prompts to perform target generation tasks. To consider both task- and instance-level information, we design an adaptive attention mechanism to derive the target prompts. For each data instance, PTG learns a specific target prompt by attending to highly relevant source prompts. In extensive experiments, PTG yields competitive or better results than fine-tuning methods. We release our source prompts as an open resource, where users can add or reuse them to improve new text generation tasks for future research. Code and data can be available at https://github.com/RUCAIBox/Transfer-Prompts-for-Text-Generation.
Deep Neural Convolutive Matrix Factorization for Articulatory Representation Decomposition
Apr 08, 2022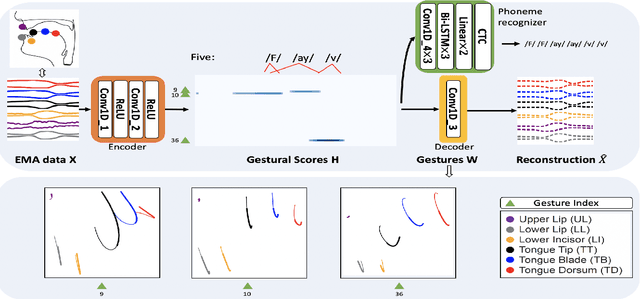
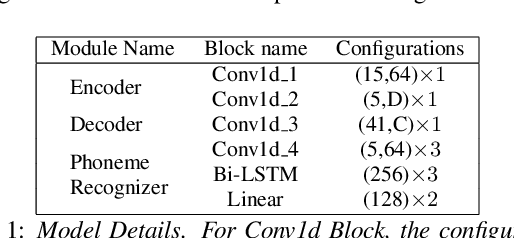
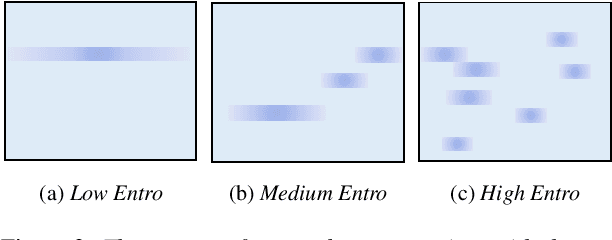
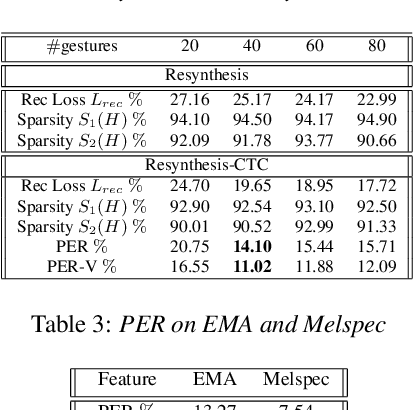
Most of the research on data-driven speech representation learning has focused on raw audios in an end-to-end manner, paying little attention to their internal phonological or gestural structure. This work, investigating the speech representations derived from articulatory kinematics signals, uses a neural implementation of convolutive sparse matrix factorization to decompose the articulatory data into interpretable gestures and gestural scores. By applying sparse constraints, the gestural scores leverage the discrete combinatorial properties of phonological gestures. Phoneme recognition experiments were additionally performed to show that gestural scores indeed code phonological information successfully. The proposed work thus makes a bridge between articulatory phonology and deep neural networks to leverage informative, intelligible, interpretable,and efficient speech representations.
Predicting vacant parking space availability zone-wisely: a graph based spatio-temporal prediction approach
May 03, 2022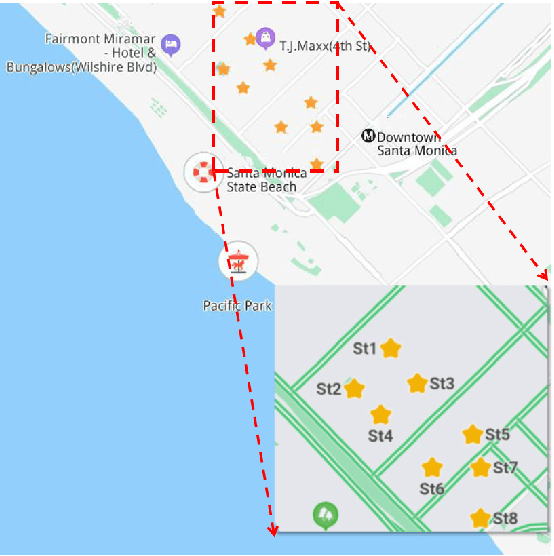
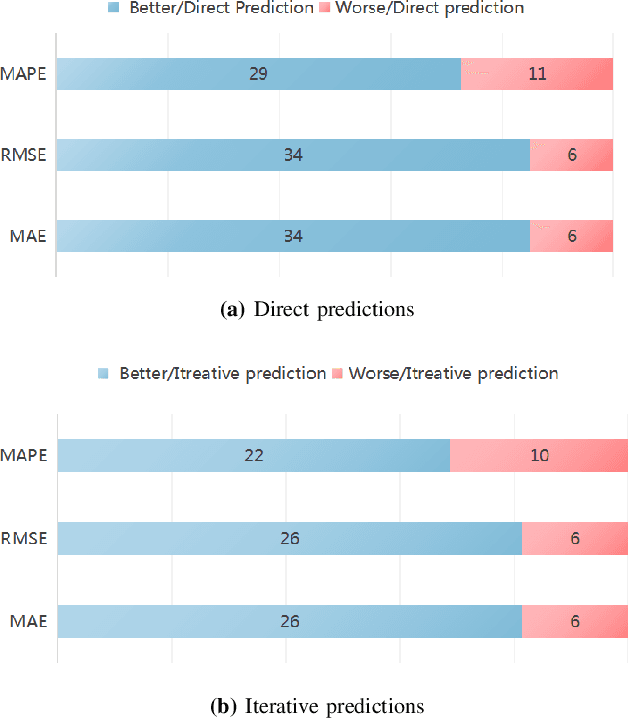
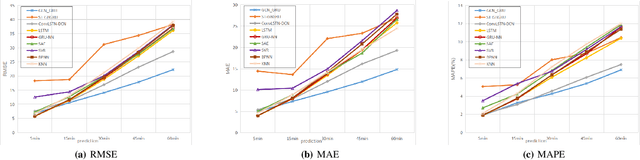
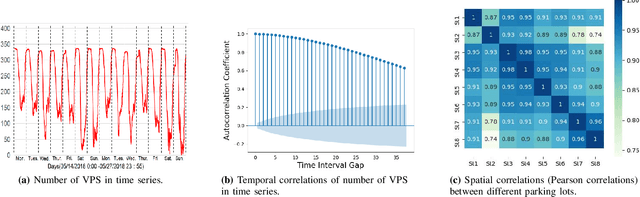
Vacant parking space (VPS) prediction is one of the key issues of intelligent parking guidance systems. Accurately predicting VPS information plays a crucial role in intelligent parking guidance systems, which can help drivers find parking space quickly, reducing unnecessary waste of time and excessive environmental pollution. Through the simple analysis of historical data, we found that there not only exists a obvious temporal correlation in each parking lot, but also a clear spatial correlation between different parking lots. In view of this, this paper proposed a graph data-based model ST-GBGRU (Spatial-Temporal Graph Based Gated Recurrent Unit), the number of VPSs can be predicted both in short-term (i.e., within 30 min) and in long-term (i.e., over 30min). On the one hand, the temporal correlation of historical VPS data is extracted by GRU, on the other hand, the spatial correlation of historical VPS data is extracted by GCN inside GRU. Two prediction methods, namely direct prediction and iterative prediction, are combined with the proposed model. Finally, the prediction model is applied to predict the number VPSs of 8 public parking lots in Santa Monica. The results show that in the short-term and long-term prediction tasks, ST-GBGRU model can achieve high accuracy and have good application prospects.
$\textit{latent}$-GLAT: Glancing at Latent Variables for Parallel Text Generation
Apr 05, 2022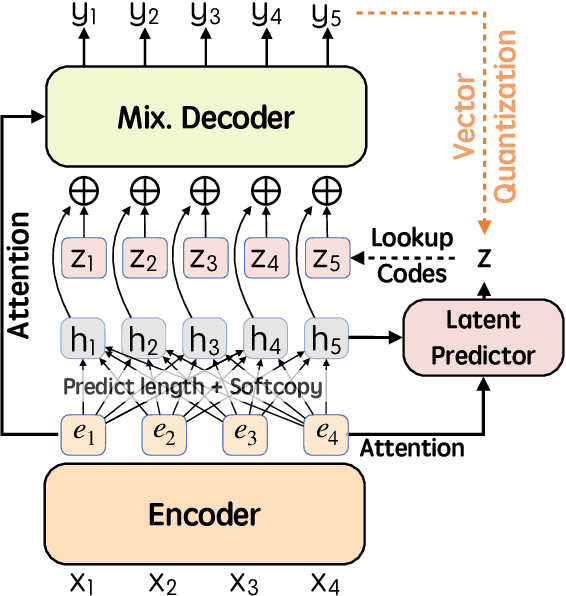
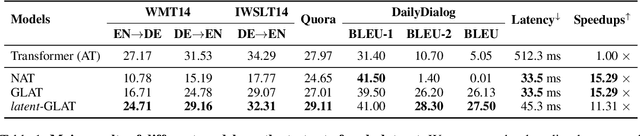
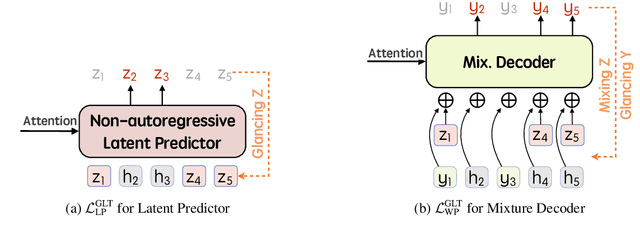
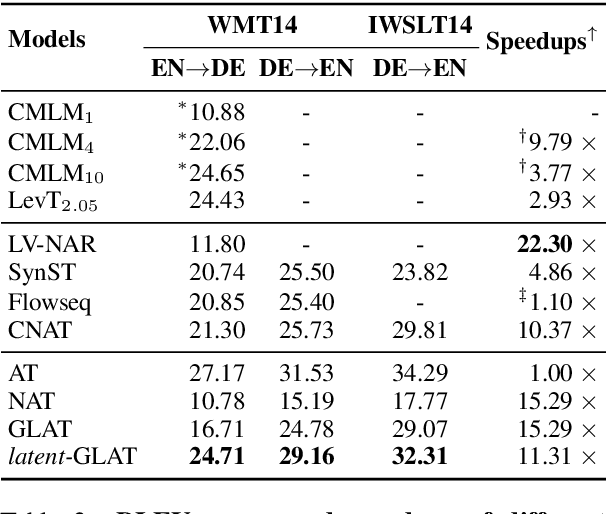
Recently, parallel text generation has received widespread attention due to its success in generation efficiency. Although many advanced techniques are proposed to improve its generation quality, they still need the help of an autoregressive model for training to overcome the one-to-many multi-modal phenomenon in the dataset, limiting their applications. In this paper, we propose $\textit{latent}$-GLAT, which employs the discrete latent variables to capture word categorical information and invoke an advanced curriculum learning technique, alleviating the multi-modality problem. Experiment results show that our method outperforms strong baselines without the help of an autoregressive model, which further broadens the application scenarios of the parallel decoding paradigm.