 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deformable Video Transformer
Mar 31, 2022
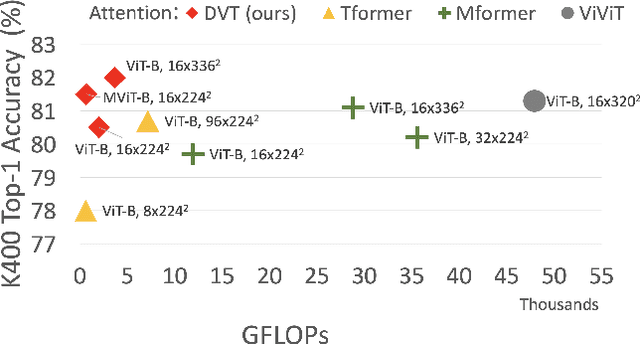

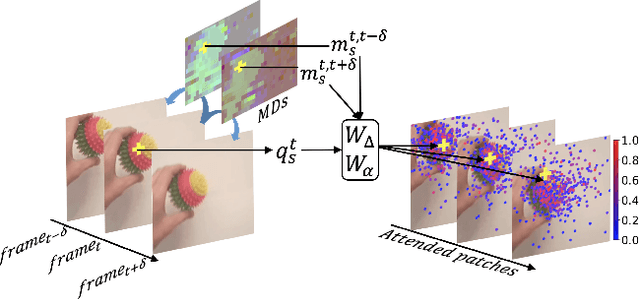
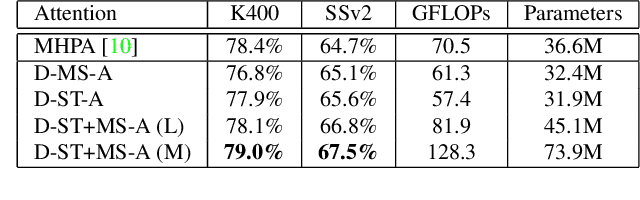
Video transformers have recently emerged as an effective alternative to convolutional networks for action classification. However, most prior video transformers adopt either global space-time attention or hand-defined strategies to compare patches within and across frames. These fixed attention schemes not only have high computational cost but, by comparing patches at predetermined locations, they neglect the motion dynamics in the video. In this paper, we introduce the Deformable Video Transformer (DVT), which dynamically predicts a small subset of video patches to attend for each query location based on motion information, thus allowing the model to decide where to look in the video based on correspondences across frames. Crucially, these motion-based correspondences are obtained at zero-cost from information stored in the compressed format of the video. Our deformable attention mechanism is optimised directly with respect to classification performance, thus eliminating the need for suboptimal hand-design of attention strategies. Experiments on four large-scale video benchmarks (Kinetics-400, Something-Something-V2, EPIC-KITCHENS and Diving-48) demonstrate that, compared to existing video transformers, our model achieves higher accuracy at the same or lower computational cost, and it attains state-of-the-art results on these four datasets.
GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech Synthesis
May 15, 2022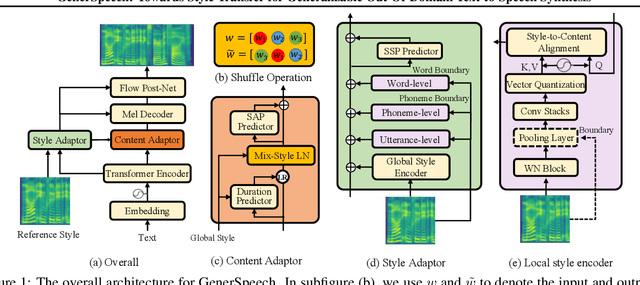
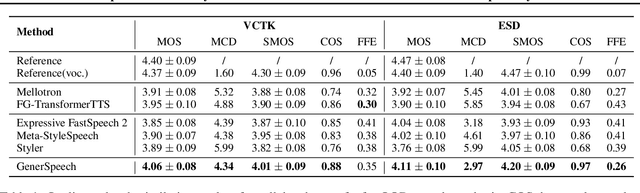
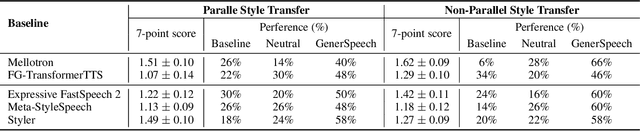
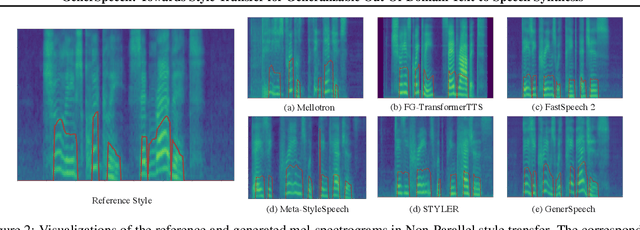
Style transfer for out-of-domain (OOD) speech synthesis aims to generate speech samples with unseen style (e.g., speaker identity, emotion, and prosody) derived from an acoustic reference, while facing the following challenges: 1) The highly dynamic style features in expressive voice are difficult to model and transfer; and 2) the TTS models should be robust enough to handle diverse OOD conditions that differ from the source data. This paper proposes GenerSpeech, a text-to-speech model towards high-fidelity zero-shot style transfer of OOD custom voice. GenerSpeech decomposes the speech variation into the style-agnostic and style-specific parts by introducing two components: 1) a multi-level style adaptor to efficiently model a large range of style conditions, including global speaker and emotion characteristics, and the local (utterance, phoneme, and word-level) fine-grained prosodic representations; and 2) a generalizable content adaptor with Mix-Style Layer Normalization to eliminate style information in the linguistic content representation and thus improve model generalization. Our evaluations on zero-shot style transfer demonstrate that GenerSpeech surpasses the state-of-the-art models in terms of audio quality and style similarity. The extension studies to adaptive style transfer further show that GenerSpeech performs robustly in the few-shot data setting. Audio samples are available at \url{https://GenerSpeech.github.io/}
What can we Learn Even From the Weakest? Learning Sketches for Programmatic Strategies
Mar 22, 2022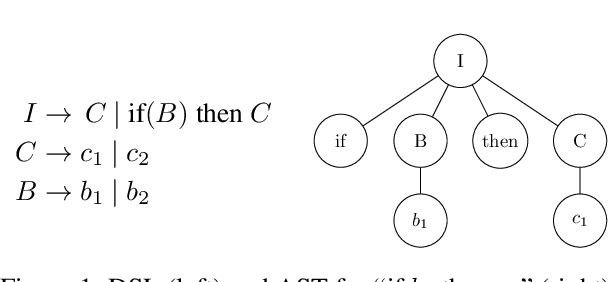

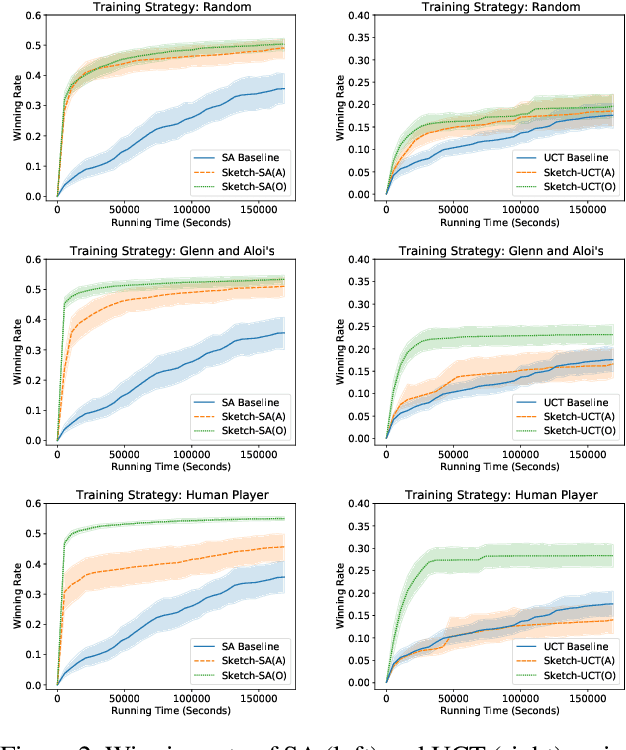
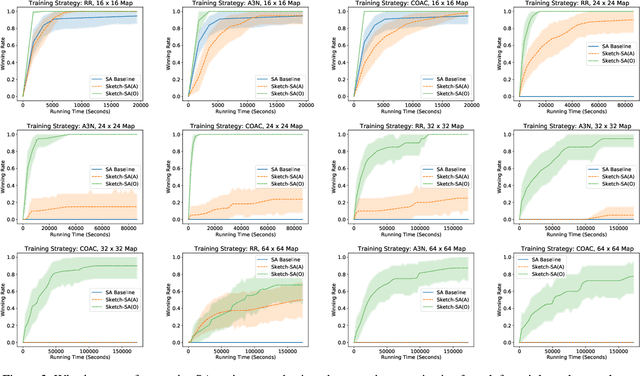
In this paper we show that behavioral cloning can be used to learn effective sketches of programmatic strategies. We show that even the sketches learned by cloning the behavior of weak players can help the synthesis of programmatic strategies. This is because even weak players can provide helpful information, e.g., that a player must choose an action in their turn of the game. If behavioral cloning is not employed, the synthesizer needs to learn even the most basic information by playing the game, which can be computationally expensive. We demonstrate empirically the advantages of our sketch-learning approach with simulated annealing and UCT synthesizers. We evaluate our synthesizers in the games of Can't Stop and MicroRTS. The sketch-based synthesizers are able to learn stronger programmatic strategies than their original counterparts. Our synthesizers generate strategies of Can't Stop that defeat a traditional programmatic strategy for the game. They also synthesize strategies that defeat the best performing method from the latest MicroRTS competition.
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Mar 31, 2022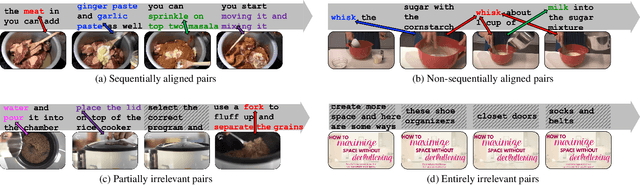
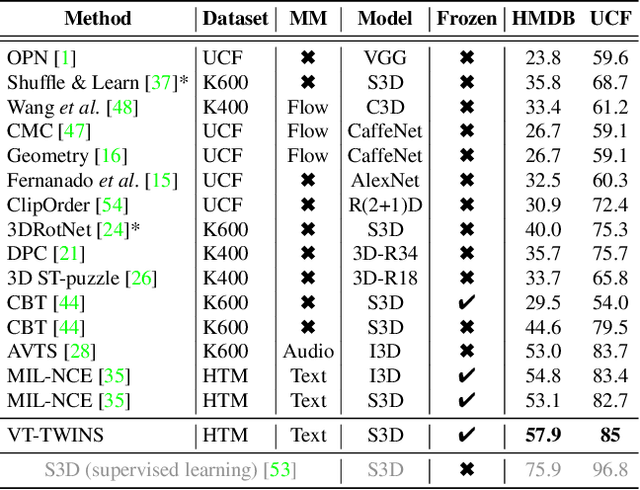
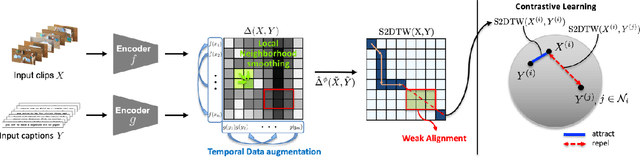
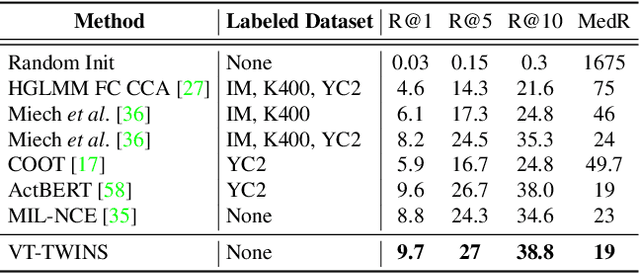
Learning generic joint representations for video and text by a supervised method requires a prohibitively substantial amount of manually annotated video datasets. As a practical alternative, a large-scale but uncurated and narrated video dataset, HowTo100M, has recently been introduced. But it is still challenging to learn joint embeddings of video and text in a self-supervised manner, due to its ambiguity and non-sequential alignment. In this paper, we propose a novel multi-modal self-supervised framework Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS) to capture significant information from noisy and weakly correlated data using a variant of Dynamic Time Warping (DTW). We observe that the standard DTW inherently cannot handle weakly correlated data and only considers the globally optimal alignment path. To address these problems, we develop a differentiable DTW which also reflects local information with weak temporal alignment. Moreover, our proposed model applies a contrastive learning scheme to learn feature representations on weakly correlated data. Our extensive experiments demonstrate that VT-TWINS attains significant improvements in multi-modal representation learning and outperforms various challenging downstream tasks. Code is available at https://github.com/mlvlab/VT-TWINS.
Interaction of Autonomous and Manually-Controlled Vehicles:Implementation of a Road User Communication Service
Apr 28, 2022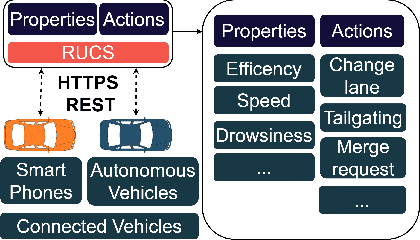
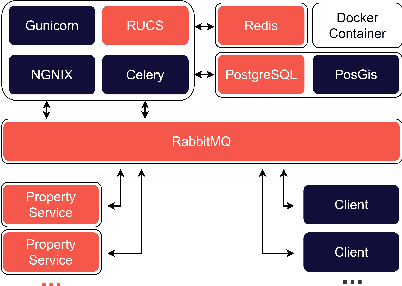
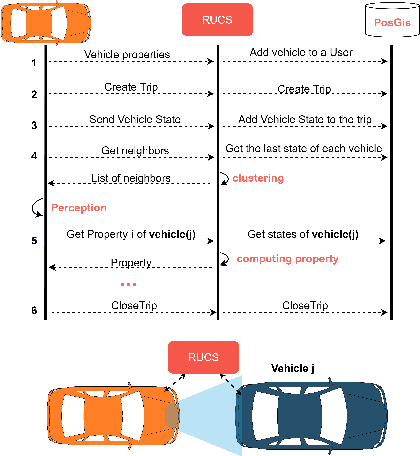
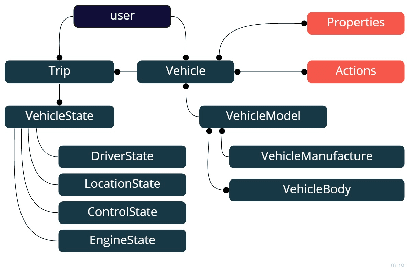
Communication between vehicles with varying degrees of automation is increasingly challenging as highly automated vehicles are unable to interpret the non-verbal signs of other road users. The lack of understanding on roads leads to lower trust in automated vehicles and impairs traffic safety. To address these problems, we propose the Road User Communication Service, a software as a service platform, which provides information exchange and cloud computing services for vehicles with varying degrees of automation. To inspect the operability of the proposed solution, field tests were carried out on a test track, where the autonomous JKU-ITS research vehicle requested the state of a driver in a manually-controlled vehicle through the implemented service. The test results validated the approach showing its feasibility to be used as a communication platform. A link to the source code is available.
D$^\text{2}$UF: Deep Coded Aperture Design and Unrolling Algorithm for Compressive Spectral Image Fusion
May 24, 2022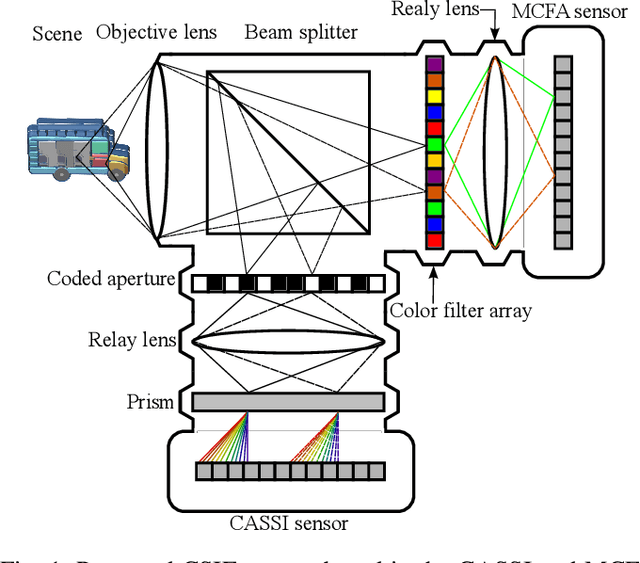
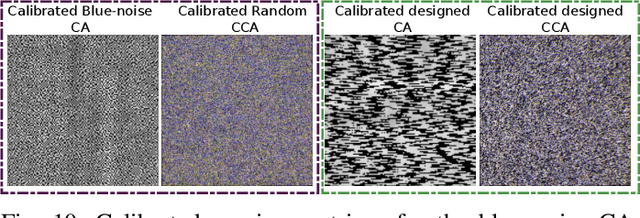
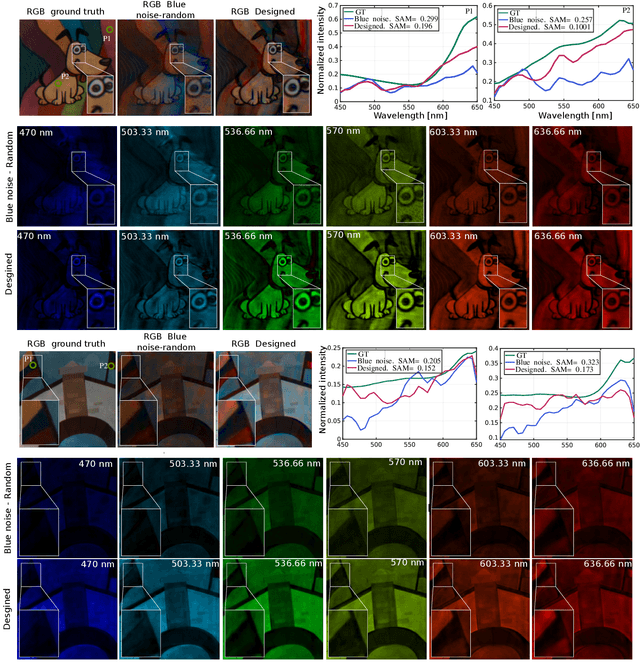
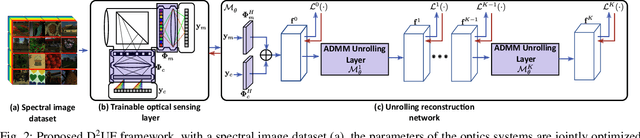
Compressive spectral imaging (CSI) has attracted significant attention since it employs synthetic apertures to codify spatial and spectral information, sensing only 2D projections of the 3D spectral image. However, these optical architectures suffer from a trade-off between the spatial and spectral resolution of the reconstructed image due to technology limitations. To overcome this issue, compressive spectral image fusion (CSIF) employs the projected measurements of two CSI architectures with different resolutions to estimate a high-spatial high-spectral resolution. This work presents the fusion of the compressive measurements of a low-spatial high-spectral resolution coded aperture snapshot spectral imager (CASSI) architecture and a high-spatial low-spectral resolution multispectral color filter array (MCFA) system. Unlike previous CSIF works, this paper proposes joint optimization of the sensing architectures and a reconstruction network in an end-to-end (E2E) manner. The trainable optical parameters are the coded aperture (CA) in the CASSI and the colored coded aperture in the MCFA system, employing a sigmoid activation function and regularization function to encourage binary values on the trainable variables for an implementation purpose. Additionally, an unrolling-based network inspired by the alternating direction method of multipliers (ADMM) optimization is formulated to address the reconstruction step and the acquisition systems design jointly. Finally, a spatial-spectral inspired loss function is employed at the end of each unrolling layer to increase the convergence of the unrolling network. The proposed method outperforms previous CSIF methods, and experimental results validate the method with real measurements.
Adversarial Training Reduces Information and Improves Transferability
Jul 22, 2020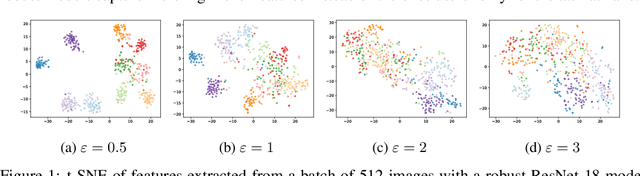
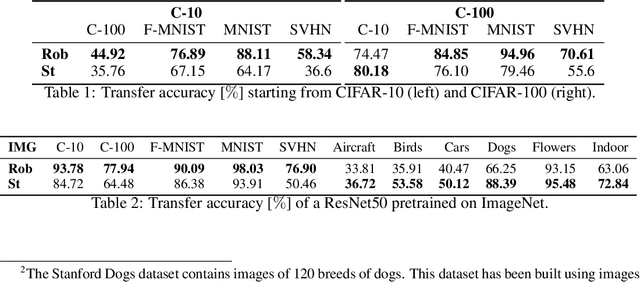
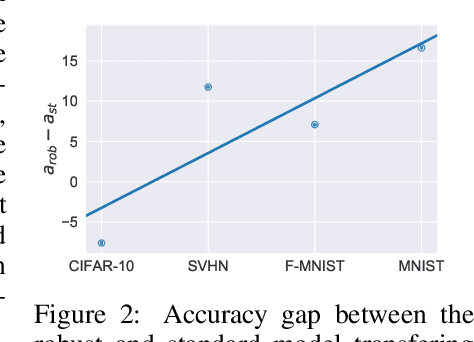
Recent results show that features of adversarially trained networks for classification, in addition to being robust, enable desirable properties such as invertibility. The latter property may seem counter-intuitive as it is widely accepted by the community that classification models should only capture the minimal information (features) required for the task. Motivated by this discrepancy, we investigate the dual relationship between Adversarial Training and Information Theory. We show that the Adversarial Training can improve linear transferability to new tasks, from which arises a new trade-off between transferability of representations and accuracy on the source task. We validate our results employing robust networks trained on CIFAR-10, CIFAR-100 and ImageNet on several datasets. Moreover, we show that Adversarial Training reduces Fisher information of representations about the input and of the weights about the task, and we provide a theoretical argument which explains the invertibility of deterministic networks without violating the principle of minimality. Finally, we leverage our theoretical insights to remarkably improve the quality of reconstructed images through inversion.
A review of ontologies for smart and continuous commissioning
May 11, 2022
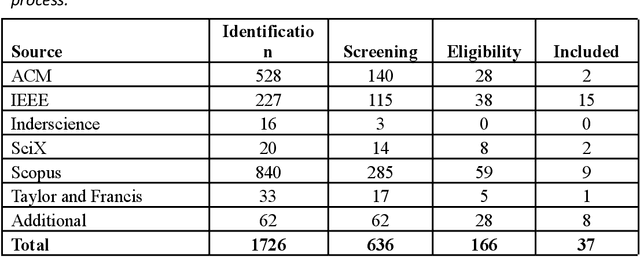
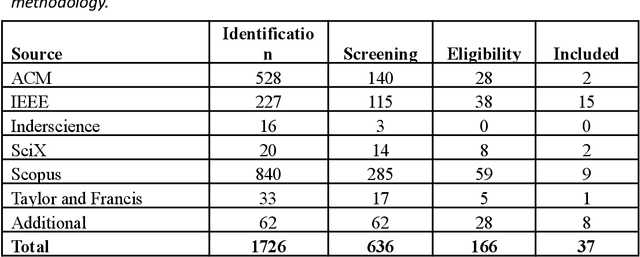
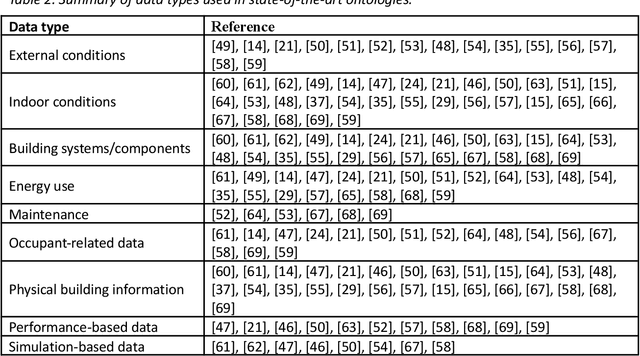
Smart and continuous commissioning (SCCx) of buildings can result in a significant reduction in the gap between design and operational performance. Ontologies play an important role in SCCx as they facilitate data readability and reasoning by machines. A better understanding of ontologies is required in order to develop and incorporate them in SCCx. This paper critically reviews the state-of-the-art research on building data ontologies since 2014 within the SCCx domain through sorting them based on building data types, general approaches, and applications. The data types of two main domains of building information modeling and building management system have been considered in the majority of existing ontologies. Three main applications are evident from a critical analysis of existing ontologies: (1) key performance indicator calculation, (2) building performance improvement, and (3) fault detection and diagnosis. The key gaps found in the literature review are a holistic ontology for SCCx and insight on how such approaches should be evaluated. Based on these findings, this study provides recommendations for future necessary research including: identification of SCCx-related data types, assessment of ontology performance, and creation of open-source approaches.
Hessian Averaging in Stochastic Newton Methods Achieves Superlinear Convergence
Apr 20, 2022
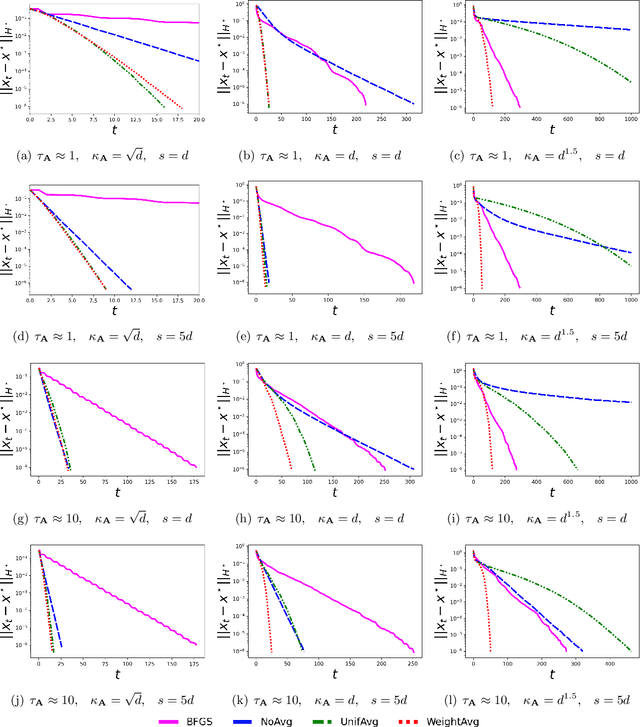
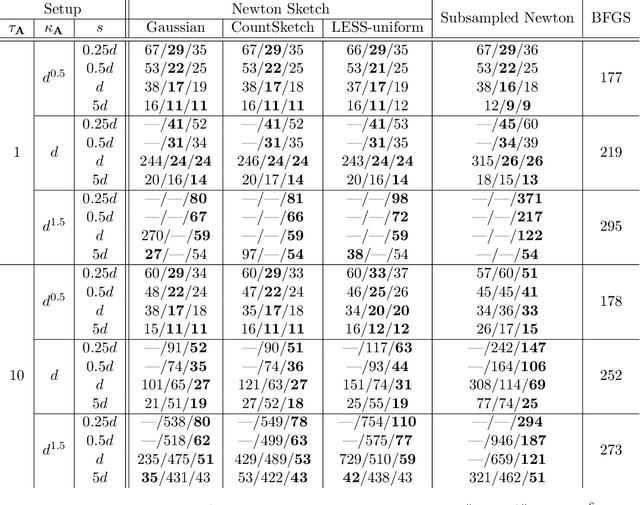
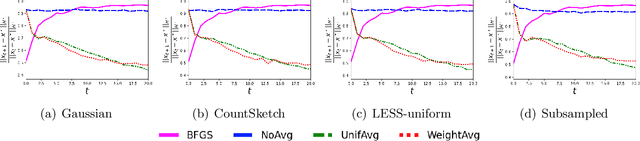
We consider minimizing a smooth and strongly convex objective function using a stochastic Newton method. At each iteration, the algorithm is given an oracle access to a stochastic estimate of the Hessian matrix. The oracle model includes popular algorithms such as the Subsampled Newton and Newton Sketch, which can efficiently construct stochastic Hessian estimates for many tasks. Despite using second-order information, these existing methods do not exhibit superlinear convergence, unless the stochastic noise is gradually reduced to zero during the iteration, which would lead to a computational blow-up in the per-iteration cost. We address this limitation with Hessian averaging: instead of using the most recent Hessian estimate, our algorithm maintains an average of all past estimates. This reduces the stochastic noise while avoiding the computational blow-up. We show that this scheme enjoys local $Q$-superlinear convergence with a non-asymptotic rate of $(\Upsilon\sqrt{\log (t)/t}\,)^{t}$, where $\Upsilon$ is proportional to the level of stochastic noise in the Hessian oracle. A potential drawback of this (uniform averaging) approach is that the averaged estimates contain Hessian information from the global phase of the iteration, i.e., before the iterates converge to a local neighborhood. This leads to a distortion that may substantially delay the superlinear convergence until long after the local neighborhood is reached. To address this drawback, we study a number of weighted averaging schemes that assign larger weights to recent Hessians, so that the superlinear convergence arises sooner, albeit with a slightly slower rate. Remarkably, we show that there exists a universal weighted averaging scheme that transitions to local convergence at an optimal stage, and still enjoys a superlinear convergence~rate nearly (up to a logarithmic factor) matching that of uniform Hessian averaging.
Price Interpretability of Prediction Markets: A Convergence Analysis
May 18, 2022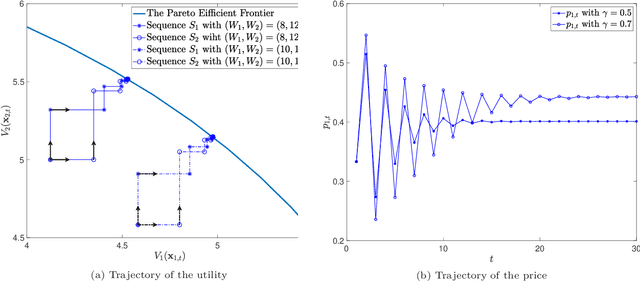
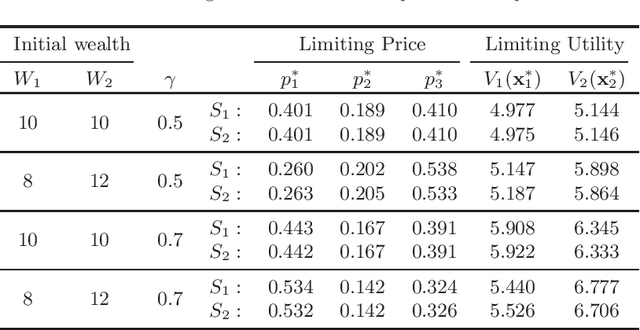
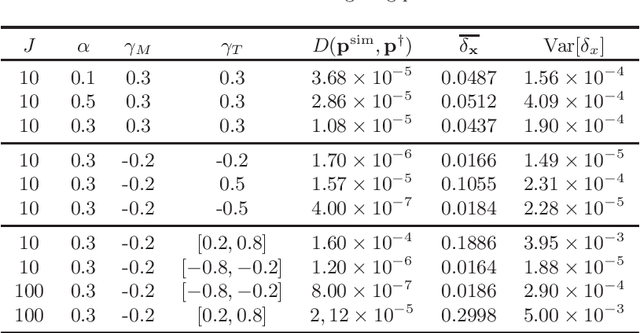
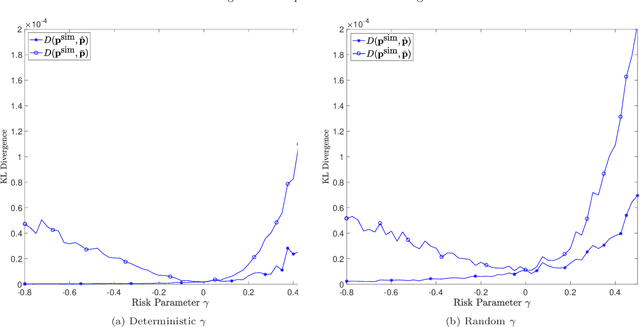
Prediction markets are long known for prediction accuracy. However, there is still a lack of systematic understanding of how prediction markets aggregate information and why they work so well. This work proposes a multivariate utility (MU)-based mechanism that unifies several existing prediction market-making schemes. Based on this mechanism, we derive convergence results for markets with myopic, risk-averse traders who repeatedly interact with the market maker. We show that the resulting limiting wealth distribution lies on the Pareto efficient frontier defined by all market participants' utilities. With the help of this result, we establish both analytical and numerical results for the limiting price for different market models. We show that the limiting price converges to the geometric mean of agents' beliefs for exponential utility-based markets. For risk measure-based markets, we construct a risk measure family that meets the convergence requirements and show that the limiting price can converge to a weighted power mean of agent beliefs. For markets based on hyperbolic absolute risk aversion (HARA) utilities, we show that the limiting price is also a risk-adjusted weighted power mean of agent beliefs, even though the trading order will affect the aggregation weights. We further propose an approximation scheme for the limiting price under the HARA utility family. We show through numerical experiments that our approximation scheme works well in predicting the convergent prices.