 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Learning via Meta-Regularization
Apr 01, 2024



Pre-trained vision-language models have shown impressive success on various computer vision tasks with their zero-shot generalizability. Recently, prompt learning approaches have been explored to efficiently and effectively adapt the vision-language models to a variety of downstream tasks. However, most existing prompt learning methods suffer from task overfitting since the general knowledge of the pre-trained vision language models is forgotten while the prompts are finetuned on a small data set from a specific target task. To address this issue, we propose a Prompt Meta-Regularization (ProMetaR) to improve the generalizability of prompt learning for vision-language models. Specifically, ProMetaR meta-learns both the regularizer and the soft prompts to harness the task-specific knowledge from the downstream tasks and task-agnostic general knowledge from the vision-language models. Further, ProMetaR augments the task to generate multiple virtual tasks to alleviate the meta-overfitting. In addition, we provide the analysis to comprehend how ProMetaR improves the generalizability of prompt tuning in the perspective of the gradient alignment. Our extensive experiments demonstrate that our ProMetaR improves the generalizability of conventional prompt learning methods under base-to-base/base-to-new and domain generalization settings. The code of ProMetaR is available at https://github.com/mlvlab/ProMetaR.
Stochastic Conditional Diffusion Models for Semantic Image Synthesis
Feb 27, 2024



Semantic image synthesis (SIS) is a task to generate realistic images corresponding to semantic maps (labels). It can be applied to diverse real-world practices such as photo editing or content creation. However, in real-world applications, SIS often encounters noisy user inputs. To address this, we propose Stochastic Conditional Diffusion Model (SCDM), which is a robust conditional diffusion model that features novel forward and generation processes tailored for SIS with noisy labels. It enhances robustness by stochastically perturbing the semantic label maps through Label Diffusion, which diffuses the labels with discrete diffusion. Through the diffusion of labels, the noisy and clean semantic maps become similar as the timestep increases, eventually becoming identical at $t=T$. This facilitates the generation of an image close to a clean image, enabling robust generation. Furthermore, we propose a class-wise noise schedule to differentially diffuse the labels depending on the class. We demonstrate that the proposed method generates high-quality samples through extensive experiments and analyses on benchmark datasets, including a novel experimental setup simulating human errors during real-world applications.
Advancing Bayesian Optimization via Learning Correlated Latent Space
Nov 20, 2023



Bayesian optimization is a powerful method for optimizing black-box functions with limited function evaluations. Recent works have shown that optimization in a latent space through deep generative models such as variational autoencoders leads to effective and efficient Bayesian optimization for structured or discrete data. However, as the optimization does not take place in the input space, it leads to an inherent gap that results in potentially suboptimal solutions. To alleviate the discrepancy, we propose Correlated latent space Bayesian Optimization (CoBO), which focuses on learning correlated latent spaces characterized by a strong correlation between the distances in the latent space and the distances within the objective function. Specifically, our method introduces Lipschitz regularization, loss weighting, and trust region recoordination to minimize the inherent gap around the promising areas. We demonstrate the effectiveness of our approach on several optimization tasks in discrete data, such as molecule design and arithmetic expression fitting, and achieve high performance within a small budget.
Semantic-Aware Implicit Template Learning via Part Deformation Consistency
Aug 23, 2023



Learning implicit templates as neural fields has recently shown impressive performance in unsupervised shape correspondence. Despite the success, we observe current approaches, which solely rely on geometric information, often learn suboptimal deformation across generic object shapes, which have high structural variability. In this paper, we highlight the importance of part deformation consistency and propose a semantic-aware implicit template learning framework to enable semantically plausible deformation. By leveraging semantic prior from a self-supervised feature extractor, we suggest local conditioning with novel semantic-aware deformation code and deformation consistency regularizations regarding part deformation, global deformation, and global scaling. Our extensive experiments demonstrate the superiority of the proposed method over baselines in various tasks: keypoint transfer, part label transfer, and texture transfer. More interestingly, our framework shows a larger performance gain under more challenging settings. We also provide qualitative analyses to validate the effectiveness of semantic-aware deformation. The code is available at https://github.com/mlvlab/PDC.
Relation-aware Language-Graph Transformer for Question Answering
Dec 02, 2022



Question Answering (QA) is a task that entails reasoning over natural language contexts, and many relevant works augment language models (LMs) with graph neural networks (GNNs) to encode the Knowledge Graph (KG) information. However, most existing GNN-based modules for QA do not take advantage of rich relational information of KGs and depend on limited information interaction between the LM and the KG. To address these issues, we propose Question Answering Transformer (QAT), which is designed to jointly reason over language and graphs with respect to entity relations in a unified manner. Specifically, QAT constructs Meta-Path tokens, which learn relation-centric embeddings based on diverse structural and semantic relations. Then, our Relation-Aware Self-Attention module comprehensively integrates different modalities via the Cross-Modal Relative Position Bias, which guides information exchange between relevant entities of different modalities. We validate the effectiveness of QAT on commonsense question answering datasets like CommonsenseQA and OpenBookQA, and on a medical question answering dataset, MedQA-USMLE. On all the datasets, our method achieves state-of-the-art performance. Our code is available at http://github.com/mlvlab/QAT.
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Mar 31, 2022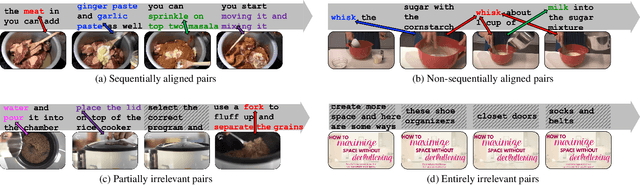
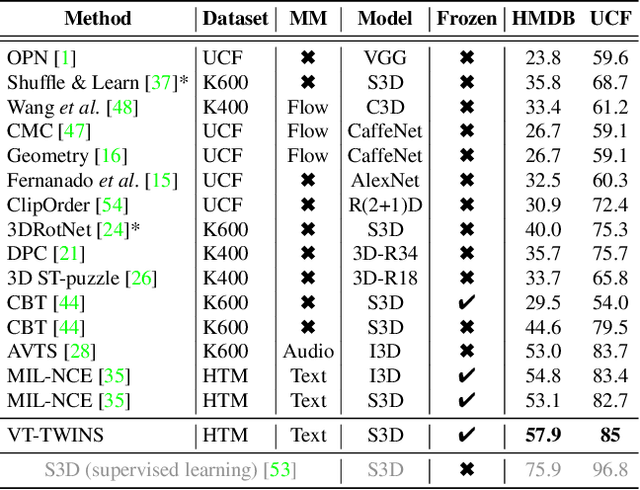
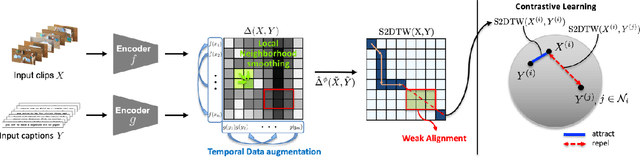
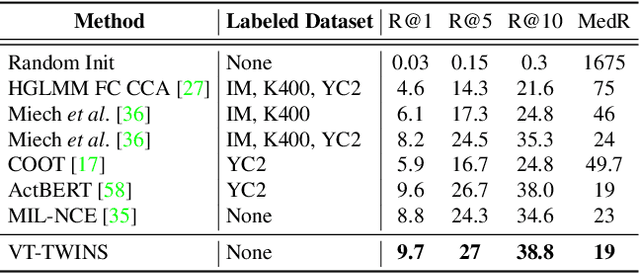
Learning generic joint representations for video and text by a supervised method requires a prohibitively substantial amount of manually annotated video datasets. As a practical alternative, a large-scale but uncurated and narrated video dataset, HowTo100M, has recently been introduced. But it is still challenging to learn joint embeddings of video and text in a self-supervised manner, due to its ambiguity and non-sequential alignment. In this paper, we propose a novel multi-modal self-supervised framework Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS) to capture significant information from noisy and weakly correlated data using a variant of Dynamic Time Warping (DTW). We observe that the standard DTW inherently cannot handle weakly correlated data and only considers the globally optimal alignment path. To address these problems, we develop a differentiable DTW which also reflects local information with weak temporal alignment. Moreover, our proposed model applies a contrastive learning scheme to learn feature representations on weakly correlated data. Our extensive experiments demonstrate that VT-TWINS attains significant improvements in multi-modal representation learning and outperforms various challenging downstream tasks. Code is available at https://github.com/mlvlab/VT-TWINS.