 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PolyU-BPCoMa: A Dataset and Benchmark Towards Mobile Colorized Mapping Using a Backpack Multisensorial System
Jun 15, 2022
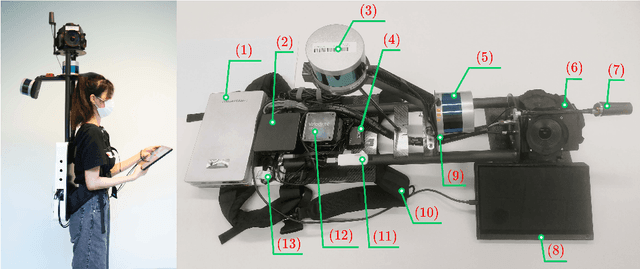
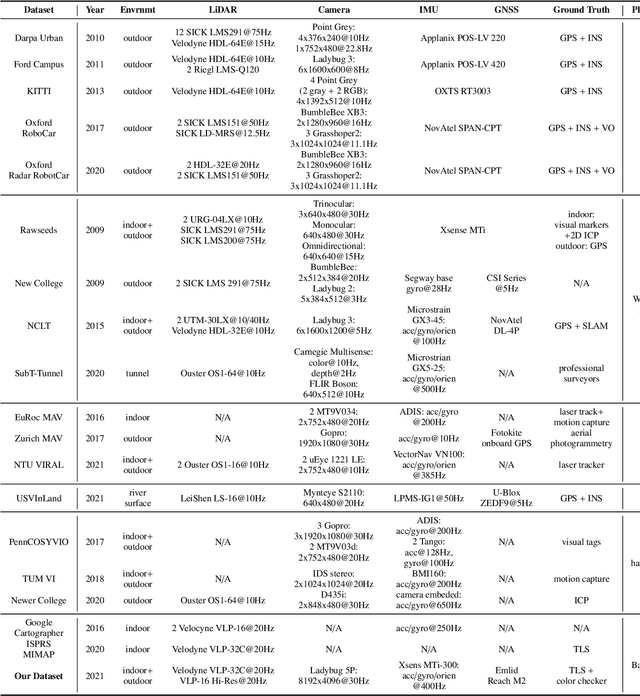


Constructing colorized point clouds from mobile laser scanning and images is a fundamental work in surveying and mapping. It is also an essential prerequisite for building digital twins for smart cities. However, existing public datasets are either in relatively small scales or lack accurate geometrical and color ground truth. This paper documents a multisensorial dataset named PolyU-BPCoMA which is distinctively positioned towards mobile colorized mapping. The dataset incorporates resources of 3D LiDAR, spherical imaging, GNSS and IMU on a backpack platform. Color checker boards are pasted in each surveyed area as targets and ground truth data are collected by an advanced terrestrial laser scanner (TLS). 3D geometrical and color information can be recovered in the colorized point clouds produced by the backpack system and the TLS, respectively. Accordingly, we provide an opportunity to benchmark the mapping and colorization accuracy simultaneously for a mobile multisensorial system. The dataset is approximately 800 GB in size covering both indoor and outdoor environments. The dataset and development kits are available at https://github.com/chenpengxin/PolyU-BPCoMa.git.
Detecting fake news by enhanced text representation with multi-EDU-structure awareness
May 30, 2022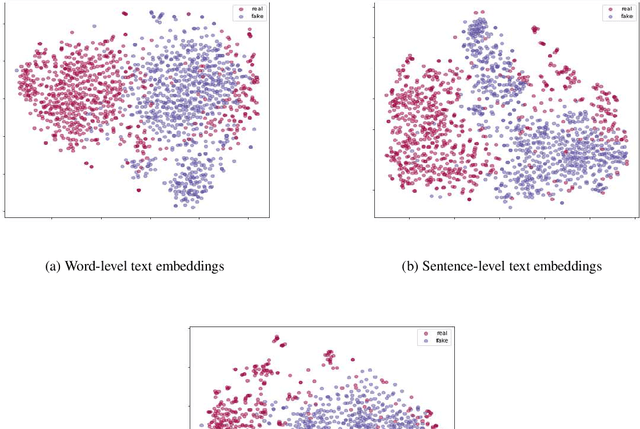


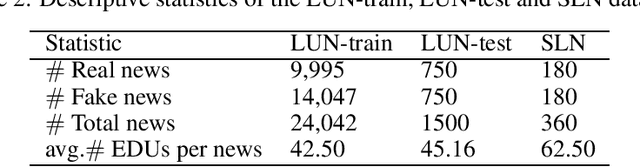
Since fake news poses a serious threat to society and individuals, numerous studies have been brought by considering text, propagation and user profiles. Due to the data collection problem, these methods based on propagation and user profiles are less applicable in the early stages. A good alternative method is to detect news based on text as soon as they are released, and a lot of text-based methods were proposed, which usually utilized words, sentences or paragraphs as basic units. But, word is a too fine-grained unit to express coherent information well, sentence or paragraph is too coarse to show specific information. Which granularity is better and how to utilize it to enhance text representation for fake news detection are two key problems. In this paper, we introduce Elementary Discourse Unit (EDU) whose granularity is between word and sentence, and propose a multi-EDU-structure awareness model to improve text representation for fake news detection, namely EDU4FD. For the multi-EDU-structure awareness, we build the sequence-based EDU representations and the graph-based EDU representations. The former is gotten by modeling the coherence between consecutive EDUs with TextCNN that reflect the semantic coherence. For the latter, we first extract rhetorical relations to build the EDU dependency graph, which can show the global narrative logic and help deliver the main idea truthfully. Then a Relation Graph Attention Network (RGAT) is set to get the graph-based EDU representation. Finally, the two EDU representations are incorporated as the enhanced text representation for fake news detection, using a gated recursive unit combined with a global attention mechanism. Experiments on four cross-source fake news datasets show that our model outperforms the state-of-the-art text-based methods.
Open-domain question classification and completion in conversational information search
Feb 26, 2021Searching for new information requires talking to the system. In this research, an Open-domain Conversational information search system has been developed. This system has been implemented using the TREC CAsT 2019 track, which is one of the first attempts to build a framework in this area. According to the user's previous questions, the system firstly completes the question (using the first and the previous question in each turn) and then classifies it (based on the question words). This system extracts the related answers according to the rules of each question. In this research, a simple yet effective method with high performance has been used, which on average, extracts 20% more relevant results than the baseline.
Stain-free, rapid, and quantitative viral plaque assay using deep learning and holography
Jun 30, 2022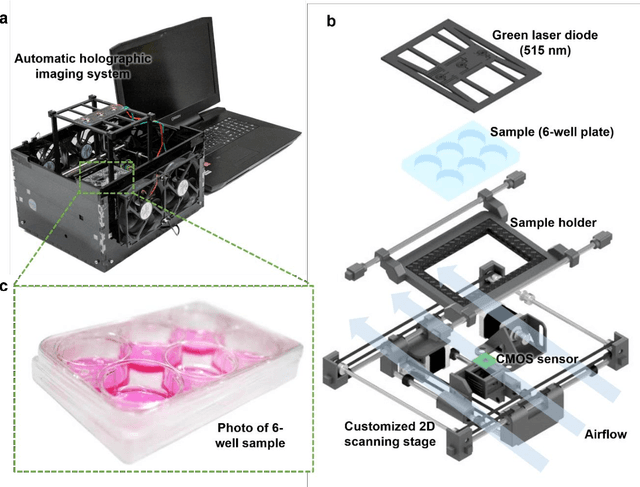
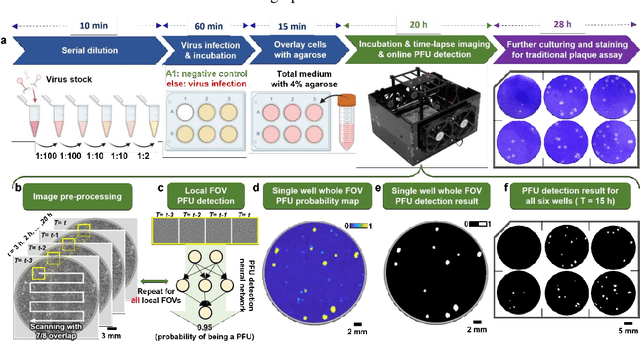
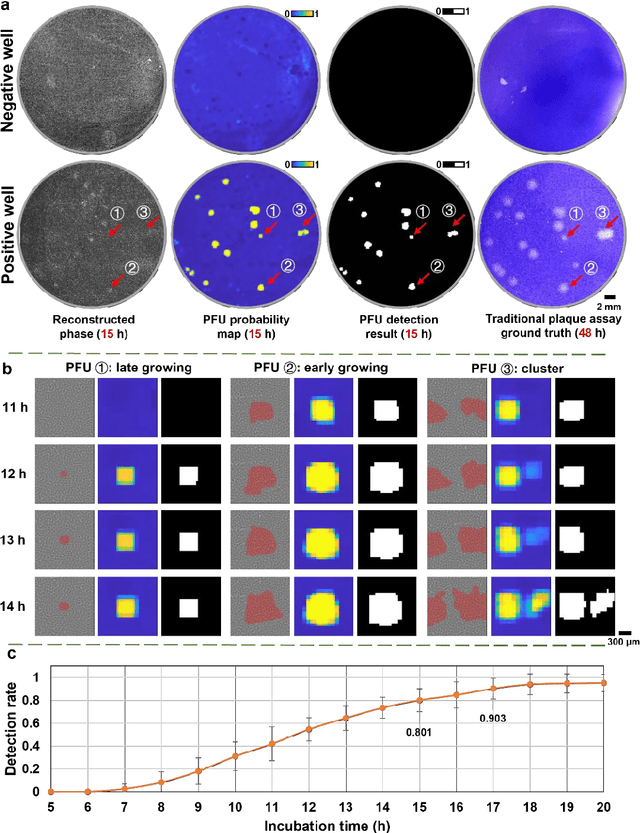

Plaque assay is the gold standard method for quantifying the concentration of replication-competent lytic virions. Expediting and automating viral plaque assays will significantly benefit clinical diagnosis, vaccine development, and the production of recombinant proteins or antiviral agents. Here, we present a rapid and stain-free quantitative viral plaque assay using lensfree holographic imaging and deep learning. This cost-effective, compact, and automated device significantly reduces the incubation time needed for traditional plaque assays while preserving their advantages over other virus quantification methods. This device captures ~0.32 Giga-pixel/hour phase information of the objects per test well, covering an area of ~30x30 mm^2, in a label-free manner, eliminating staining entirely. We demonstrated the success of this computational method using Vero E6 cells and vesicular stomatitis virus. Using a neural network, this stain-free device automatically detected the first cell lysing events due to the viral replication as early as 5 hours after the incubation, and achieved >90% detection rate for the plaque-forming units (PFUs) with 100% specificity in <20 hours, providing major time savings compared to the traditional plaque assays that take ~48 hours or more. This data-driven plaque assay also offers the capability of quantifying the infected area of the cell monolayer, performing automated counting and quantification of PFUs and virus-infected areas over a 10-fold larger dynamic range of virus concentration than standard viral plaque assays. This compact, low-cost, automated PFU quantification device can be broadly used in virology research, vaccine development, and clinical applications
Musical Instrument Recognition by XGBoost Combining Feature Fusion
Jun 02, 2022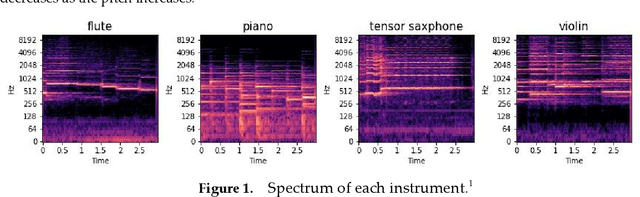

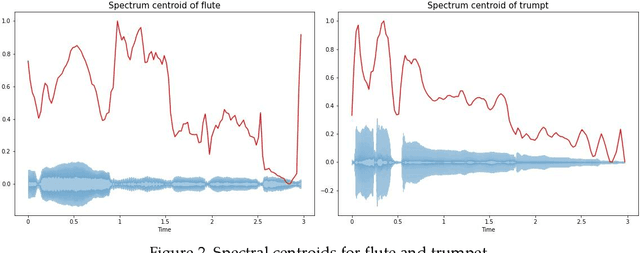
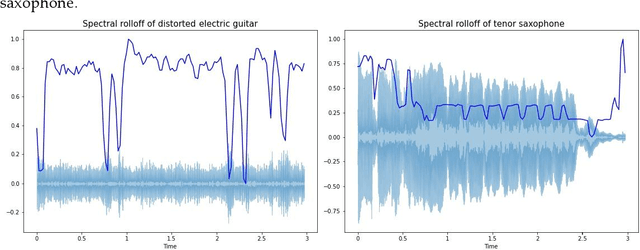
Musical instrument classification is one of the focuses of Music Information Retrieval (MIR). In order to solve the problem of poor performance of current musical instrument classification models, we propose a musical instrument classification algorithm based on multi-channel feature fusion and XGBoost. Based on audio feature extraction and fusion of the dataset, the features are input into the XGBoost model for training; secondly, we verified the superior performance of the algorithm in the musical instrument classification task by com-paring different feature combinations and several classical machine learning models such as Naive Bayes. The algorithm achieves an accuracy of 97.65% on the Medley-solos-DB dataset, outperforming existing models. The experiments provide a reference for feature selection in feature engineering for musical instrument classification.
Digital-twin-enhanced metal tube bending forming real-time prediction method based on Multi-source-input MTL
Jul 03, 2022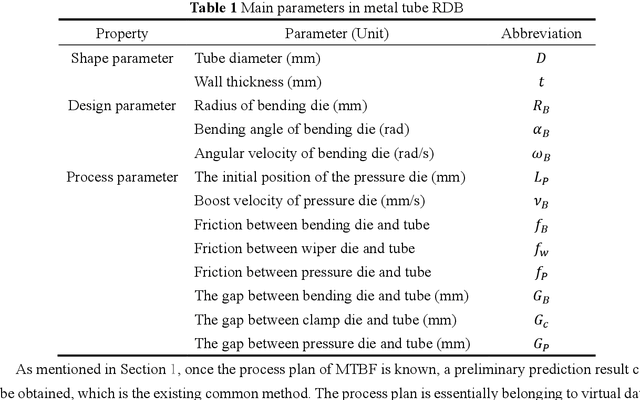
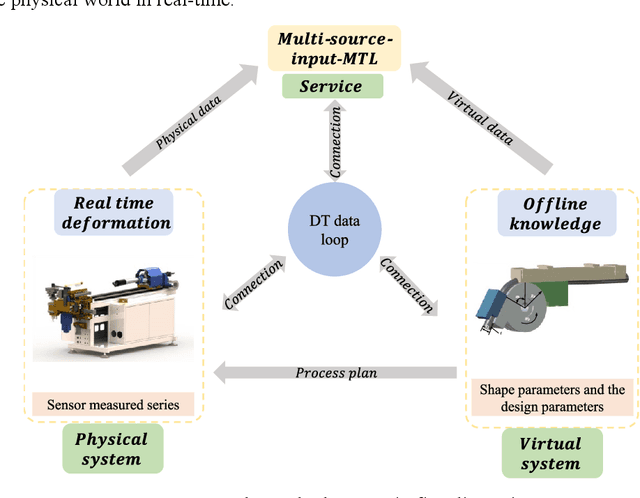

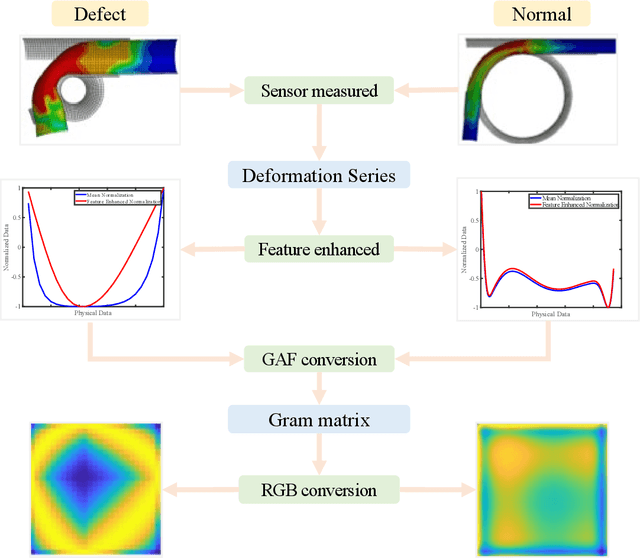
As one of the most widely used metal tube bending methods, the rotary draw bending (RDB) process enables reliable and high-precision metal tube bending forming (MTBF). The forming accuracy is seriously affected by the springback and other potential forming defects, of which the mechanism analysis is difficult to deal with. At the same time, the existing methods are mainly conducted in offline space, ignoring the real-time information in the physical world, which is unreliable and inefficient. To address this issue, a digital-twin-enhanced (DT-enhanced) metal tube bending forming real-time prediction method based on multi-source-input multi-task learning (MTL) is proposed. The new method can achieve comprehensive MTBF real-time prediction. By sharing the common feature of the multi-close domain and adopting group regularization strategy on feature sharing and accepting layers, the accuracy and efficiency of the multi-source-input MTL can be guaranteed. Enhanced by DT, the physical real-time deformation data is aligned in the image dimension by an improved Grammy Angle Field (GAF) conversion, realizing the reflection of the actual processing. Different from the traditional offline prediction methods, the new method integrates the virtual and physical data to achieve a more efficient and accurate real-time prediction result. and the DT mapping connection between virtual and physical systems can be achieved. To exclude the effects of equipment errors, the effectiveness of the proposed method is verified on the physical experiment-verified FE simulation scenarios. At the same time, the common pre-training networks are compared with the proposed method. The results show that the proposed DT-enhanced prediction method is more accurate and efficient.
CT-SAT: Contextual Transformer for Sequential Audio Tagging
Mar 22, 2022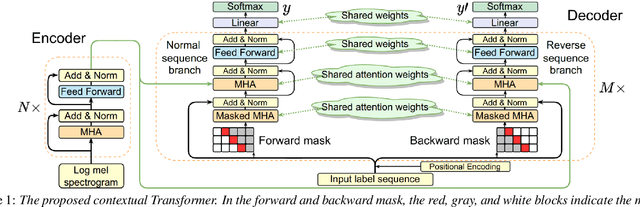
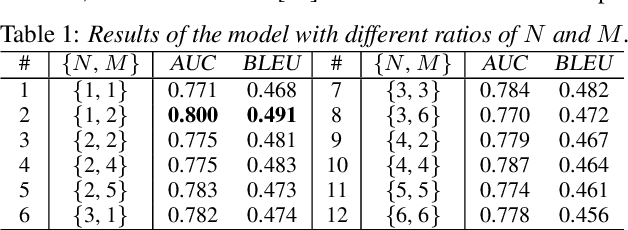

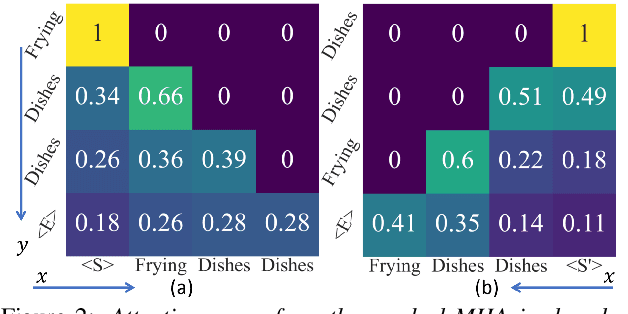
Sequential audio event tagging can provide not only the type information of audio events, but also the order information between events and the number of events that occur in an audio clip. Most previous works on audio event sequence analysis rely on connectionist temporal classification (CTC). However, CTC's conditional independence assumption prevents it from effectively learning correlations between diverse audio events. This paper first attempts to introduce Transformer into sequential audio tagging, since Transformers perform well in sequence-related tasks. To better utilize contextual information of audio event sequences, we draw on the idea of bidirectional recurrent neural networks, and propose a contextual Transformer (cTransformer) with a bidirectional decoder that could exploit the forward and backward information of event sequences. Experiments on the real-life polyphonic audio dataset show that, compared to CTC-based methods, the cTransformer can effectively combine the fine-grained acoustic representations from the encoder and coarse-grained audio event cues to exploit contextual information to successfully recognize and predict audio event sequences.
SparseTT: Visual Tracking with Sparse Transformers
May 08, 2022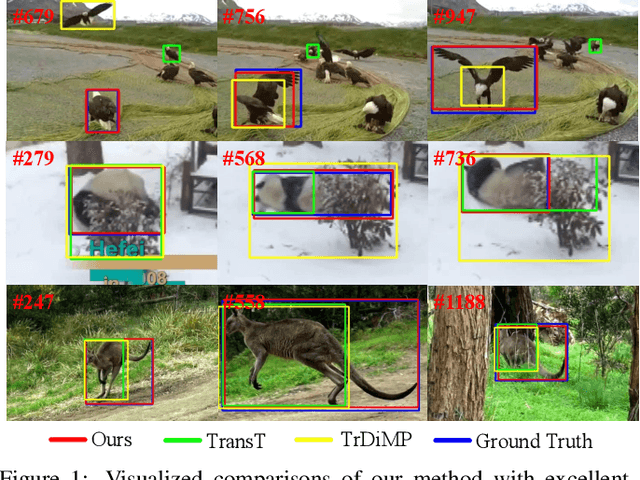
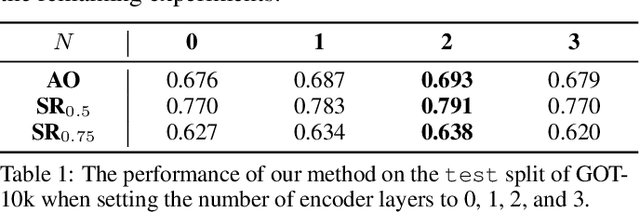
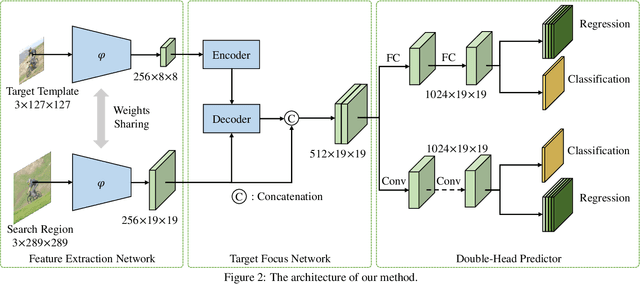
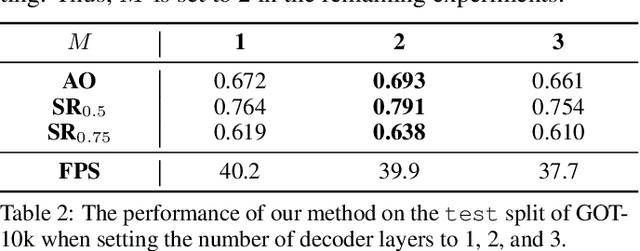
Transformers have been successfully applied to the visual tracking task and significantly promote tracking performance. The self-attention mechanism designed to model long-range dependencies is the key to the success of Transformers. However, self-attention lacks focusing on the most relevant information in the search regions, making it easy to be distracted by background. In this paper, we relieve this issue with a sparse attention mechanism by focusing the most relevant information in the search regions, which enables a much accurate tracking. Furthermore, we introduce a double-head predictor to boost the accuracy of foreground-background classification and regression of target bounding boxes, which further improve the tracking performance. Extensive experiments show that, without bells and whistles, our method significantly outperforms the state-of-the-art approaches on LaSOT, GOT-10k, TrackingNet, and UAV123, while running at 40 FPS. Notably, the training time of our method is reduced by 75% compared to that of TransT. The source code and models are available at https://github.com/fzh0917/SparseTT.
ABAW: Learning from Synthetic Data & Multi-Task Learning Challenges
Jul 05, 2022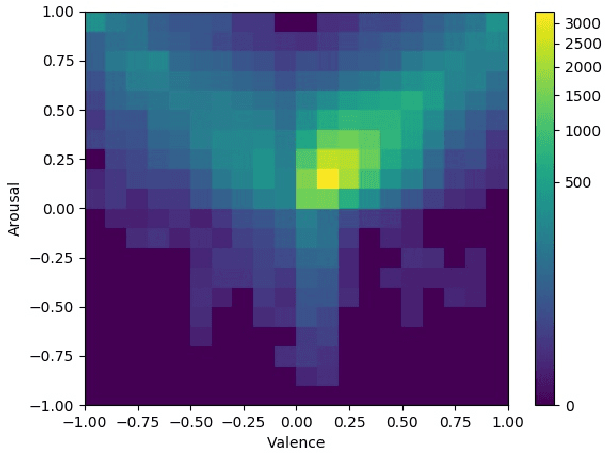
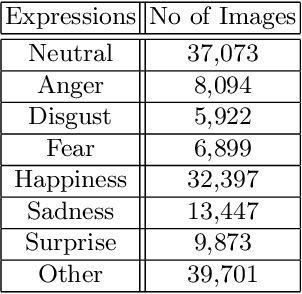
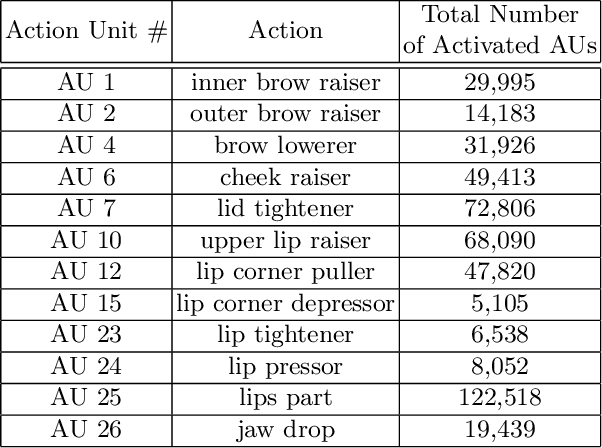
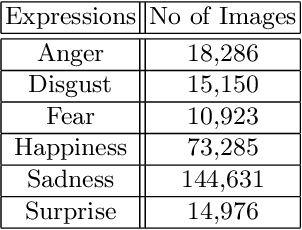
This paper describes the fourth Affective Behavior Analysis in-the-wild (ABAW) Competition, held in conjunction with European Conference on Computer Vision (ECCV), 2022. The 4th ABAW Competition is a continuation of the Competitions held at IEEE CVPR 2022, ICCV 2021, IEEE FG 2020 and IEEE CVPR 2017 Conferences, and aims at automatically analyzing affect. In the previous runs of this Competition, the Challenges targeted Valence-Arousal Estimation, Expression Classification and Action Unit Detection. This year the Competition encompasses two different Challenges: i) a Multi-Task-Learning one in which the goal is to learn at the same time (i.e., in a multi-task learning setting) all the three above mentioned tasks; and ii) a Learning from Synthetic Data one in which the goal is to learn to recognise the basic expressions from artificially generated data and generalise to real data. The Aff-Wild2 database is a large scale in-the-wild database and the first one that contains annotations for valence and arousal, expressions and action units. This database is the basis for the above Challenges. In more detail: i) s-Aff-Wild2 -- a static version of Aff-Wild2 database -- has been constructed and utilized for the purposes of the Multi-Task-Learning Challenge; and ii) some specific frames-images from the Aff-Wild2 database have been used in an expression manipulation manner for creating the synthetic dataset, which is the basis for the Learning from Synthetic Data Challenge. In this paper, at first we present the two Challenges, along with the utilized corpora, then we outline the evaluation metrics and finally present the baseline systems per Challenge, as well as their derived results. More information regarding the Competition can be found in the competition's website: https://ibug.doc.ic.ac.uk/resources/eccv-2023-4th-abaw/.
End-to-end Spoken Conversational Question Answering: Task, Dataset and Model
Apr 29, 2022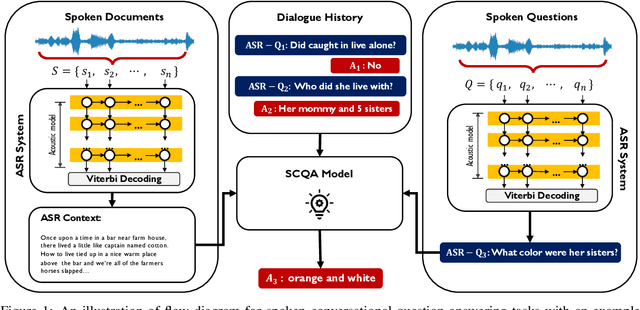

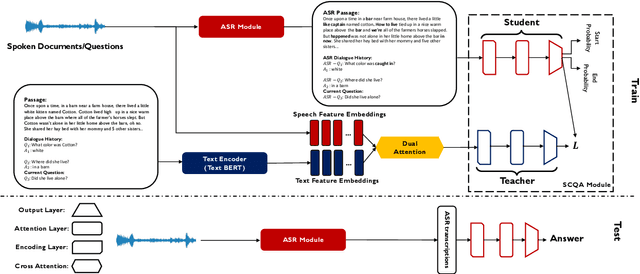

In spoken question answering, the systems are designed to answer questions from contiguous text spans within the related speech transcripts. However, the most natural way that human seek or test their knowledge is via human conversations. Therefore, we propose a new Spoken Conversational Question Answering task (SCQA), aiming at enabling the systems to model complex dialogue flows given the speech documents. In this task, our main objective is to build the system to deal with conversational questions based on the audio recordings, and to explore the plausibility of providing more cues from different modalities with systems in information gathering. To this end, instead of directly adopting automatically generated speech transcripts with highly noisy data, we propose a novel unified data distillation approach, DDNet, which effectively ingests cross-modal information to achieve fine-grained representations of the speech and language modalities. Moreover, we propose a simple and novel mechanism, termed Dual Attention, by encouraging better alignments between audio and text to ease the process of knowledge transfer. To evaluate the capacity of SCQA systems in a dialogue-style interaction, we assemble a Spoken Conversational Question Answering (Spoken-CoQA) dataset with more than 40k question-answer pairs from 4k conversations. The performance of the existing state-of-the-art methods significantly degrade on our dataset, hence demonstrating the necessity of cross-modal information integration. Our experimental results demonstrate that our proposed method achieves superior performance in spoken conversational question answering tasks.