 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comparative Study of Meter Detection Methods for Automated Infrastructure Inspection
Apr 24, 2022
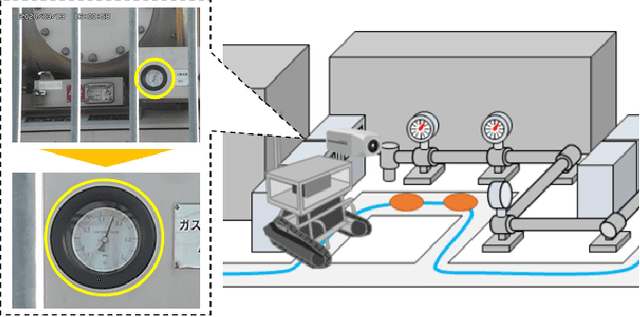

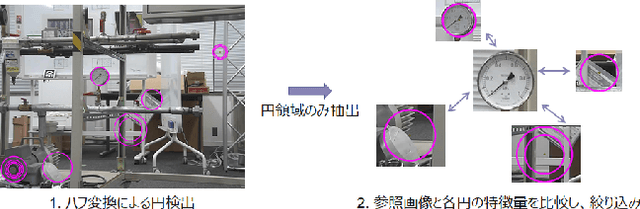
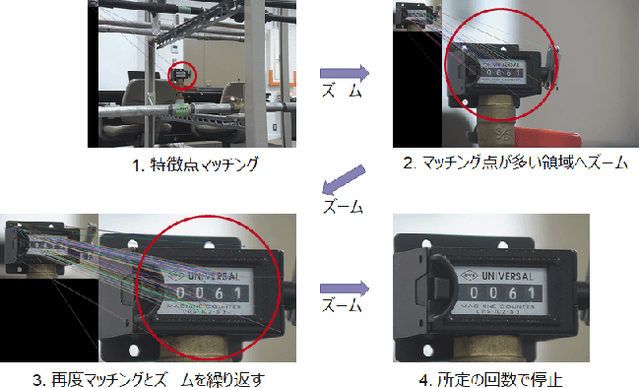
In order to read meter values from a camera on an autonomous inspection robot with positional errors, it is necessary to detect meter regions from the image. In this study, we developed shape-based, texture-based, and background information-based methods as meter area detection techniques and compared their effectiveness for meters of different shapes and sizes. As a result, we confirmed that the background information-based method can detect the farthest meters regardless of the shape and number of meters, and can stably detect meters with a diameter of 40px.
Estimating $α$-Rank by Maximizing Information Gain
Jan 22, 2021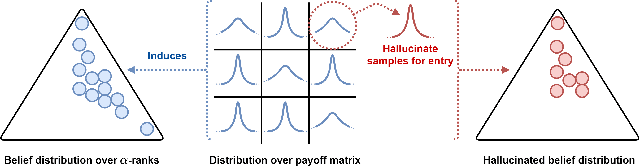
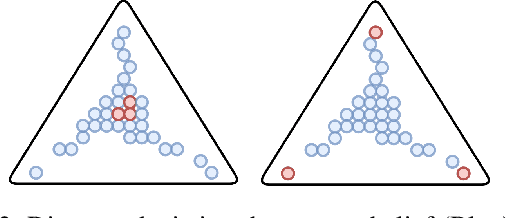
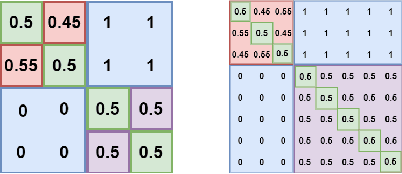
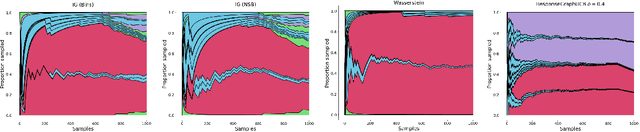
Game theory has been increasingly applied in settings where the game is not known outright, but has to be estimated by sampling. For example, meta-games that arise in multi-agent evaluation can only be accessed by running a succession of expensive experiments that may involve simultaneous deployment of several agents. In this paper, we focus on $\alpha$-rank, a popular game-theoretic solution concept designed to perform well in such scenarios. We aim to estimate the $\alpha$-rank of the game using as few samples as possible. Our algorithm maximizes information gain between an epistemic belief over the $\alpha$-ranks and the observed payoff. This approach has two main benefits. First, it allows us to focus our sampling on the entries that matter the most for identifying the $\alpha$-rank. Second, the Bayesian formulation provides a facility to build in modeling assumptions by using a prior over game payoffs. We show the benefits of using information gain as compared to the confidence interval criterion of ResponseGraphUCB (Rowland et al. 2019), and provide theoretical results justifying our method.
Unintended memorisation of unique features in neural networks
May 20, 2022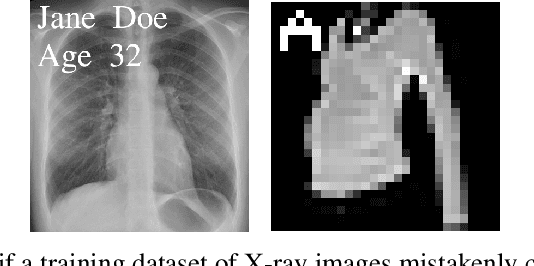
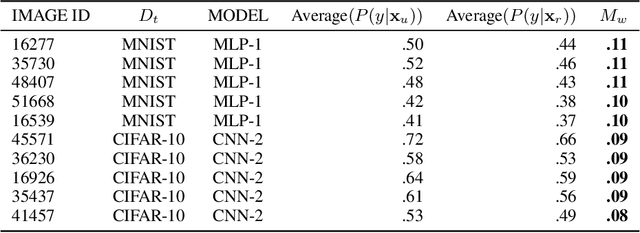

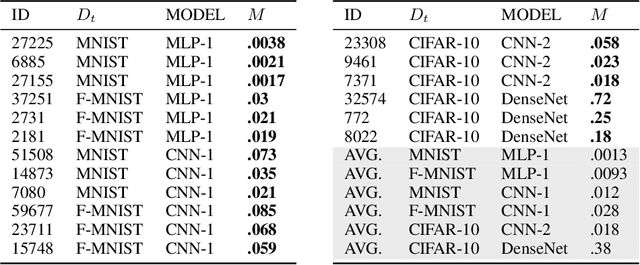
Neural networks pose a privacy risk due to their propensity to memorise and leak training data. We show that unique features occurring only once in training data are memorised by discriminative multi-layer perceptrons and convolutional neural networks trained on benchmark imaging datasets. We design our method for settings where sensitive training data is not available, for example medical imaging. Our setting knows the unique feature, but not the training data, model weights or the unique feature's label. We develop a score estimating a model's sensitivity to a unique feature by comparing the KL divergences of the model's output distributions given modified out-of-distribution images. We find that typical strategies to prevent overfitting do not prevent unique feature memorisation. And that images containing a unique feature are highly influential, regardless of the influence the images's other features. We also find a significant variation in memorisation with training seed. These results imply that neural networks pose a privacy risk to rarely occurring private information. This risk is more pronounced in healthcare applications since sensitive patient information can be memorised when it remains in training data due to an imperfect data sanitisation process.
INSTA-BNN: Binary Neural Network with INSTAnce-aware Threshold
Apr 18, 2022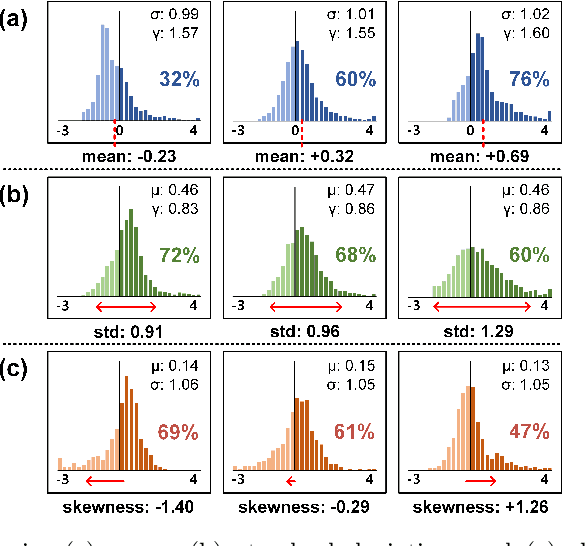
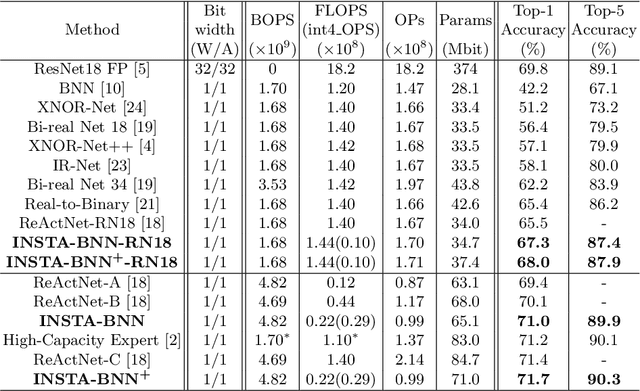
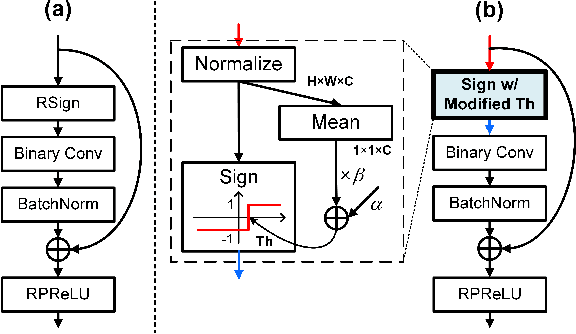

Binary Neural Networks (BNNs) have emerged as a promising solution for reducing the memory footprint and compute costs of deep neural networks. BNNs, on the other hand, suffer from information loss because binary activations are limited to only two values, resulting in reduced accuracy. To improve the accuracy, previous studies have attempted to control the distribution of binary activation by manually shifting the threshold of the activation function or making the shift amount trainable. During the process, they usually depended on statistical information computed from a batch. We argue that using statistical data from a batch fails to capture the crucial information for each input instance in BNN computations, and the differences between statistical information computed from each instance need to be considered when determining the binary activation threshold of each instance. Based on the concept, we propose the Binary Neural Network with INSTAnce-aware threshold (INSTA-BNN), which decides the activation threshold value considering the difference between statistical data computed from a batch and each instance. The proposed INSTA-BNN outperforms the baseline by 2.5% and 2.3% on the ImageNet classification task with comparable computing cost, achieving 68.0% and 71.7% top-1 accuracy on ResNet-18 and MobileNetV1 based models, respectively.
Learning Representations for Control with Hierarchical Forward Models
Jun 22, 2022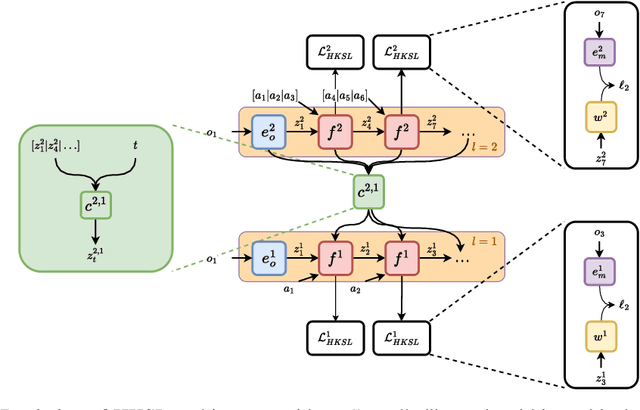
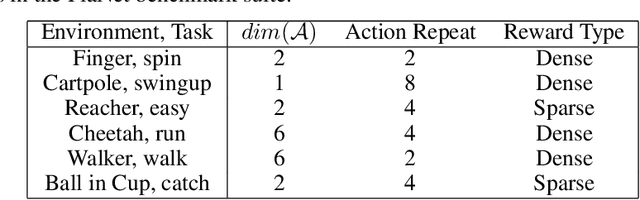
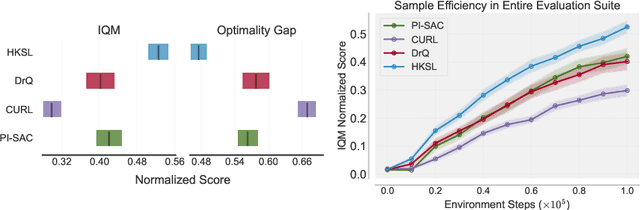

Learning control from pixels is difficult for reinforcement learning (RL) agents because representation learning and policy learning are intertwined. Previous approaches remedy this issue with auxiliary representation learning tasks, but they either do not consider the temporal aspect of the problem or only consider single-step transitions. Instead, we propose Hierarchical $k$-Step Latent (HKSL), an auxiliary task that learns representations via a hierarchy of forward models that operate at varying magnitudes of step skipping while also learning to communicate between levels in the hierarchy. We evaluate HKSL in a suite of 30 robotic control tasks and find that HKSL either reaches higher episodic returns or converges to maximum performance more quickly than several current baselines. Also, we find that levels in HKSL's hierarchy can learn to specialize in long- or short-term consequences of agent actions, thereby providing the downstream control policy with more informative representations. Finally, we determine that communication channels between hierarchy levels organize information based on both sides of the communication process, which improves sample efficiency.
Fair Representation Learning for Heterogeneous Information Networks
Apr 18, 2021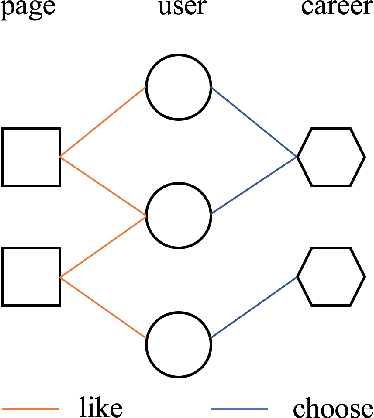
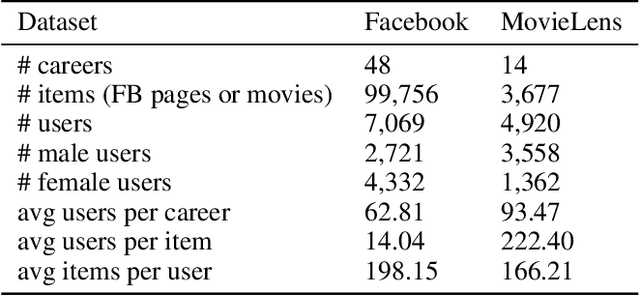
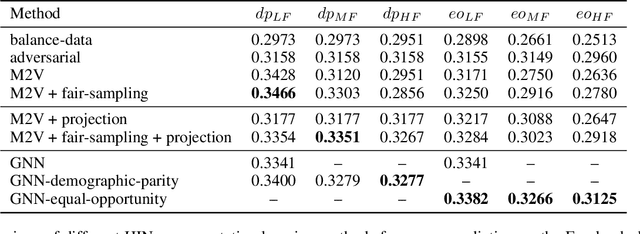
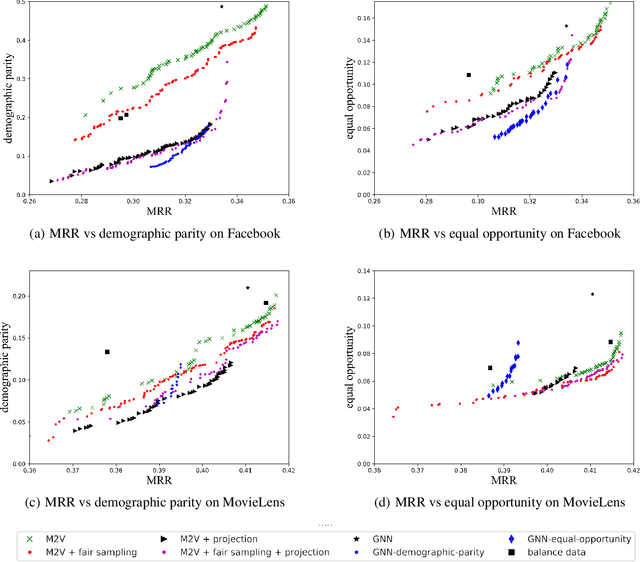
Recently, much attention has been paid to the societal impact of AI, especially concerns regarding its fairness. A growing body of research has identified unfair AI systems and proposed methods to debias them, yet many challenges remain. Representation learning for Heterogeneous Information Networks (HINs), a fundamental building block used in complex network mining, has socially consequential applications such as automated career counseling, but there have been few attempts to ensure that it will not encode or amplify harmful biases, e.g. sexism in the job market. To address this gap, in this paper we propose a comprehensive set of de-biasing methods for fair HINs representation learning, including sampling-based, projection-based, and graph neural networks (GNNs)-based techniques. We systematically study the behavior of these algorithms, especially their capability in balancing the trade-off between fairness and prediction accuracy. We evaluate the performance of the proposed methods in an automated career counseling application where we mitigate gender bias in career recommendation. Based on the evaluation results on two datasets, we identify the most effective fair HINs representation learning techniques under different conditions.
Resonant tunnelling diode nano-optoelectronic spiking nodes for neuromorphic information processing
Jul 21, 2021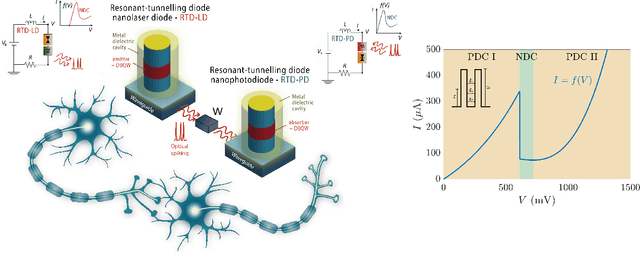
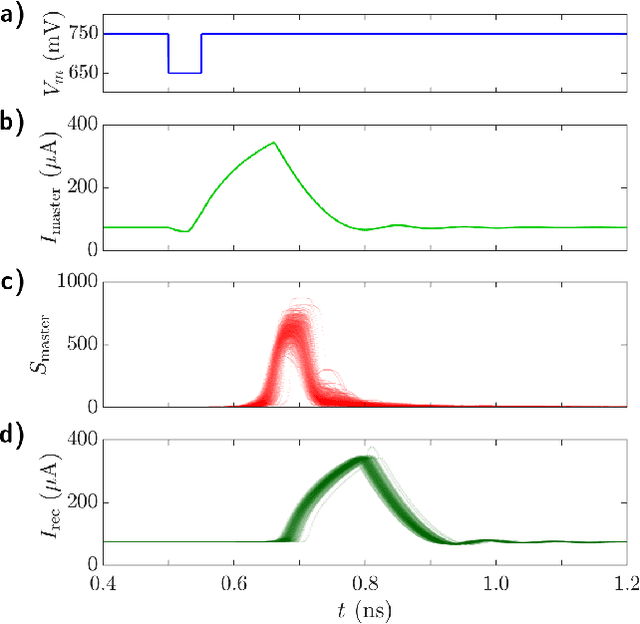
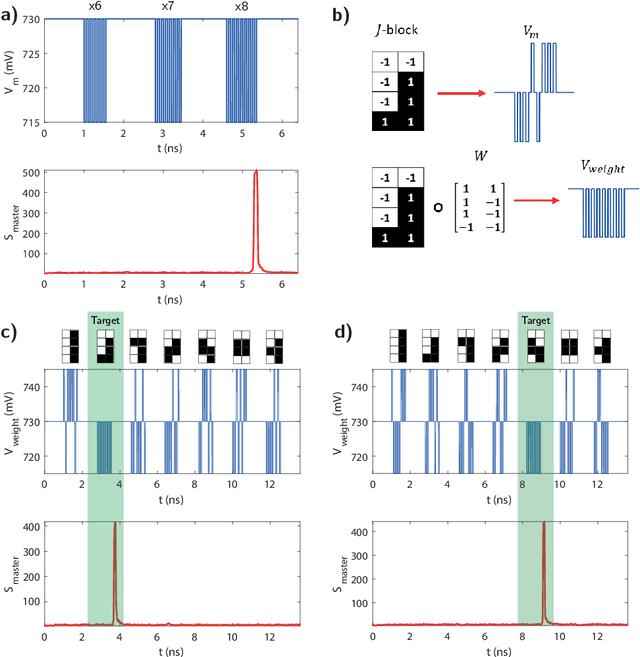
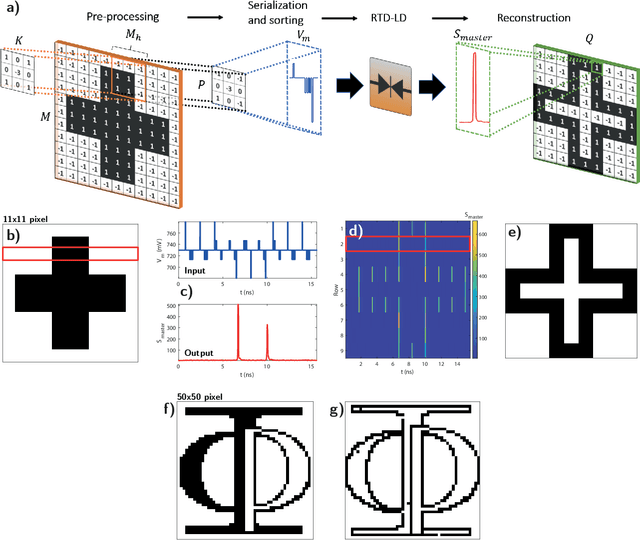
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
View-labels Are Indispensable: A Multifacet Complementarity Study of Multi-view Clustering
May 05, 2022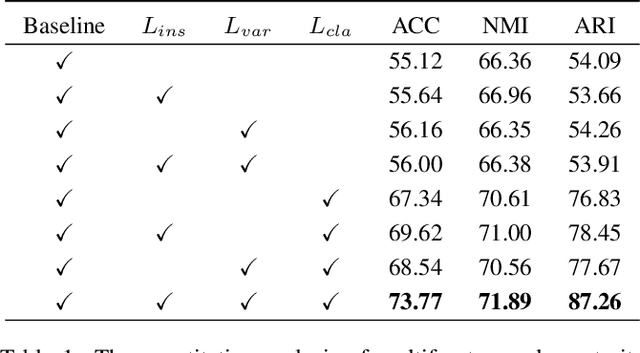
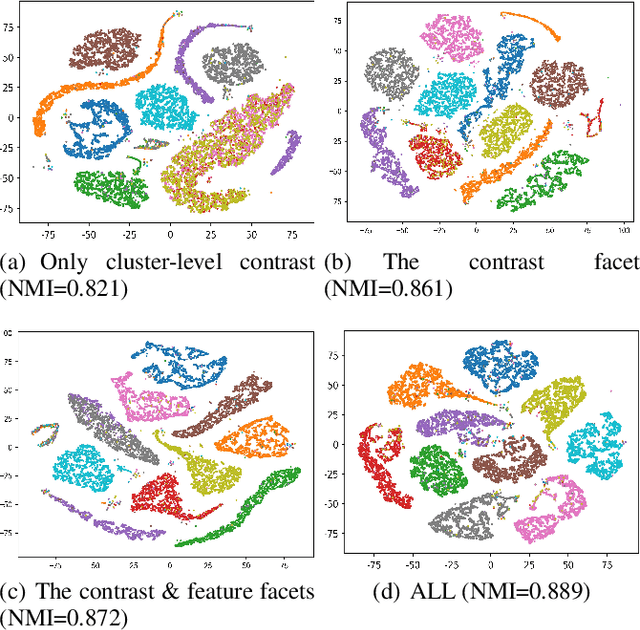
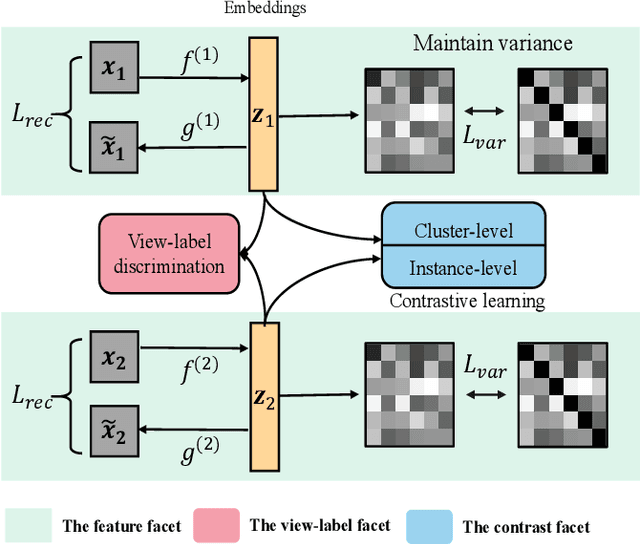
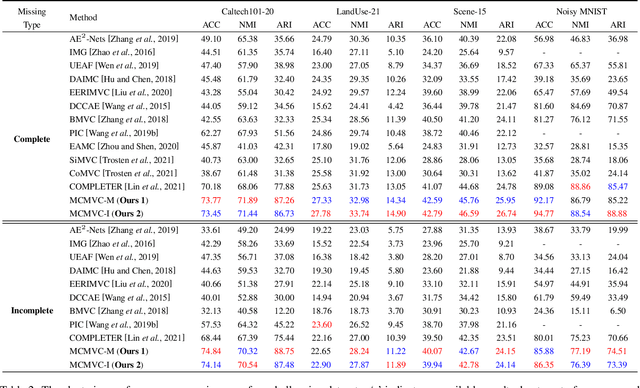
Consistency and complementarity are two key ingredients for boosting multi-view clustering (MVC). Recently with the introduction of popular contrastive learning, the consistency learning of views has been further enhanced in MVC, leading to promising performance. However, by contrast, the complementarity has not received sufficient attention except just in the feature facet, where the Hilbert Schmidt Independence Criterion (HSIC) term or the independent encoder-decoder network is usually adopted to capture view-specific information. This motivates us to reconsider the complementarity learning of views comprehensively from multiple facets including the feature-, view-label- and contrast- facets, while maintaining the view consistency. We empirically find that all the facets contribute to the complementarity learning, especially the view-label facet, which is usually neglected by existing methods. Based on this, we develop a novel \underline{M}ultifacet \underline{C}omplementarity learning framework for \underline{M}ulti-\underline{V}iew \underline{C}lustering (MCMVC), which fuses multifacet complementarity information, especially explicitly embedding the view-label information. To our best knowledge, it is the first time to use view-labels explicitly to guide the complementarity learning of views. Compared with the SOTA baseline, MCMVC achieves remarkable improvements, e.g., by average margins over $5.00\%$ and $7.00\%$ respectively in complete and incomplete MVC settings on Caltech101-20 in terms of three evaluation metrics.
Hiding Your Signals: A Security Analysis of PPG-based Biometric Authentication
Jul 10, 2022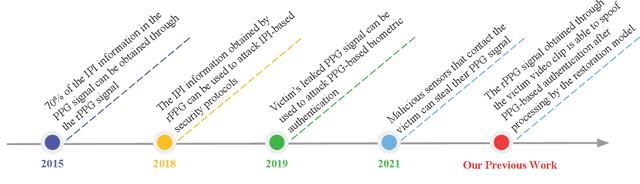
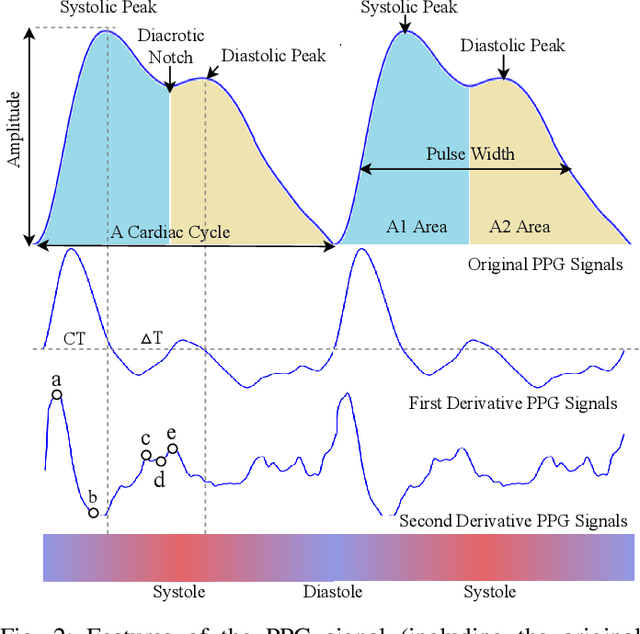
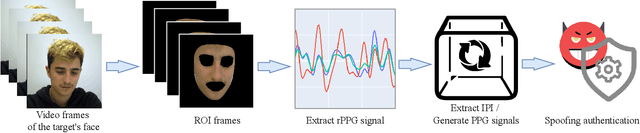
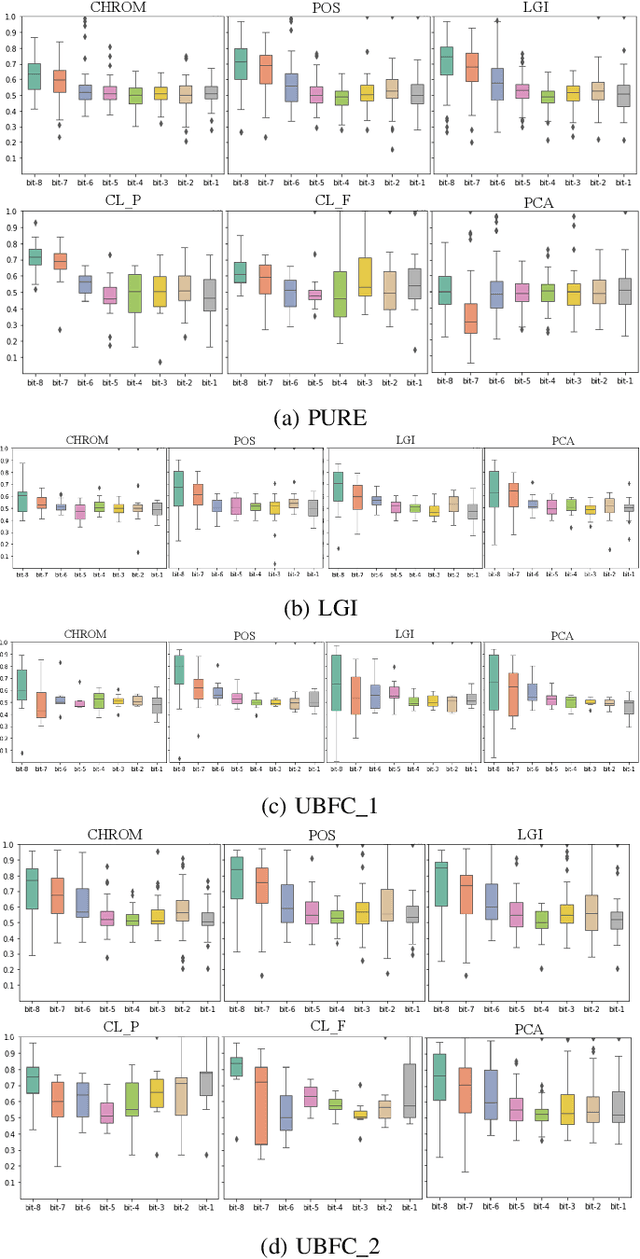
Recently, physiological signal-based biometric systems have received wide attention. Unlike traditional biometric features, physiological signals can not be easily compromised (usually unobservable to human eyes). Photoplethysmography (PPG) signal is easy to measure, making it more attractive than many other physiological signals for biometric authentication. However, with the advent of remote PPG (rPPG), unobservability has been challenged when the attacker can remotely steal the rPPG signals by monitoring the victim's face, subsequently posing a threat to PPG-based biometrics. In PPG-based biometric authentication, current attack approaches mandate the victim's PPG signal, making rPPG-based attacks neglected. In this paper, we firstly analyze the security of PPG-based biometrics, including user authentication and communication protocols. We evaluate the signal waveforms, heart rate and inter-pulse-interval information extracted by five rPPG methods, including four traditional optical computing methods (CHROM, POS, LGI, PCA) and one deep learning method (CL_rPPG). We conducted experiments on five datasets (PURE, UBFC_rPPG, UBFC_Phys, LGI_PPGI, and COHFACE) to collect a comprehensive set of results. Our empirical studies show that rPPG poses a serious threat to the authentication system. The success rate of the rPPG signal spoofing attack in the user authentication system reached 0.35. The bit hit rate is 0.6 in inter-pulse-interval-based security protocols. Further, we propose an active defence strategy to hide the physiological signals of the face to resist the attack. It reduces the success rate of rPPG spoofing attacks in user authentication to 0.05. The bit hit rate was reduced to 0.5, which is at the level of a random guess. Our strategy effectively prevents the exposure of PPG signals to protect users' sensitive physiological data.
A Computational Model for Logical Analysis of Data
Jul 12, 2022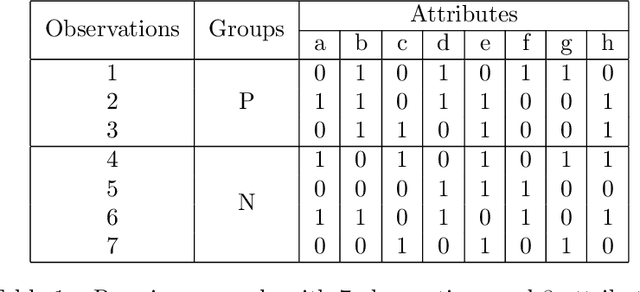
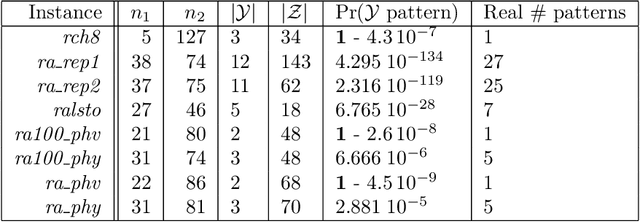
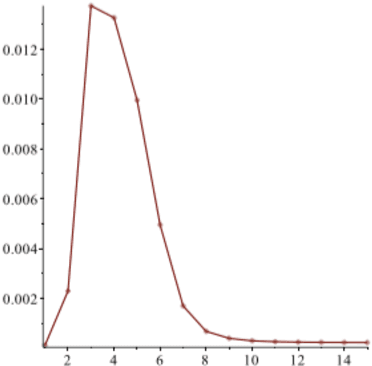
Initially introduced by Peter Hammer, Logical Analysis of Data is a methodology that aims at computing a logical justification for dividing a group of data in two groups of observations, usually called the positive and negative groups. Consider this partition into positive and negative groups as the description of a partially defined Boolean function; the data is then processed to identify a subset of attributes, whose values may be used to characterize the observations of the positive groups against those of the negative group. LAD constitutes an interesting rule-based learning alternative to classic statistical learning techniques and has many practical applications. Nevertheless, the computation of group characterization may be costly, depending on the properties of the data instances. A major aim of our work is to provide effective tools for speeding up the computations, by computing some \emph{a priori} probability that a given set of attributes does characterize the positive and negative groups. To this effect, we propose several models for representing the data set of observations, according to the information we have on it. These models, and the probabilities they allow us to compute, are also helpful for quickly assessing some properties of the real data at hand; furthermore they may help us to better analyze and understand the computational difficulties encountered by solving methods. Once our models have been established, the mathematical tools for computing probabilities come from Analytic Combinatorics. They allow us to express the desired probabilities as ratios of generating functions coefficients, which then provide a quick computation of their numerical values. A further, long-range goal of this paper is to show that the methods of Analytic Combinatorics can help in analyzing the performance of various algorithms in LAD and related fields.