 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Aligned Key Channel Pruning for Efficient Vision-Language Model Inference
May 19, 2026Vision-Language Models suffer severe KV cache pressure at inference, as a single image often encodes into thousands of tokens. Most existing methods exploit token sparsity through token pruning, but permanently discarding visual content causes substantial degradation on fine-grained perception tasks. This motivates a complementary axis, feature sparsity: under a fixed KV cache budget, compressing the channel dimension preserves more visual tokens at the same memory cost. Prior Key channel pruning methods, however, face a structural trade-off: token-wise channel pruning is expressive but unstructured and slow, while head-wise approach is hardware-friendly but less robust. We resolve this with RotateK, a rotation-based structured Key channel pruning framework. RotateK applies an online PCA-based rotation that aligns token-dependent channel importance into a shared low-dimensional subspace, enabling accurate pruning under lightweight head-wise masks; a fused Triton attention kernel operates directly on sparse-channel Keys for efficient decoding. Experiments on two representative VLM backbones show that RotateK consistently outperforms prior Key channel pruning in both accuracy and decoding latency, while joint token-channel pruning improves over token-only baselines at matched KV cache budgets.
RelayGen: Intra-Generation Model Switching for Efficient Reasoning
Feb 06, 2026Large reasoning models (LRMs) achieve strong performance on complex reasoning tasks by generating long, multi-step reasoning trajectories, but inference-time scaling incurs substantial deployment cost. A key challenge is that generation difficulty varies within a single output, whereas existing efficiency-oriented approaches either ignore this intra-generation variation or rely on supervised token-level routing with high system complexity. We present \textbf{RelayGen}, a training-free, segment-level runtime model switching framework that exploits difficulty variation in long-form reasoning. Through offline analysis of generation uncertainty using token probability margins, we show that coarse-grained segment-level control is sufficient to capture difficulty transitions within a reasoning trajectory. RelayGen identifies model-specific switch cues that signal transitions to lower-difficulty segments and dynamically delegates their continuation to a smaller model, while preserving high-difficulty reasoning on the large model. Across multiple reasoning benchmarks, RelayGen substantially reduces inference latency while preserving most of the accuracy of large models. When combined with speculative decoding, RelayGen achieves up to 2.2$\times$ end-to-end speedup with less than 2\% accuracy degradation, without requiring additional training or learned routing components.
Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection
Feb 03, 2026The quadratic complexity of attention remains the central bottleneck in long-context inference for large language models. Prior acceleration methods either sparsify the attention map with structured patterns or permanently evict tokens at specific layers, which can retain irrelevant tokens or rely on irreversible early decisions despite the layer-/head-wise dynamics of token importance. In this paper, we propose Token Sparse Attention, a lightweight and dynamic token-level sparsification mechanism that compresses per-head $Q$, $K$, $V$ to a reduced token set during attention and then decompresses the output back to the original sequence, enabling token information to be reconsidered in subsequent layers. Furthermore, Token Sparse Attention exposes a new design point at the intersection of token selection and sparse attention. Our approach is fully compatible with dense attention implementations, including Flash Attention, and can be seamlessly composed with existing sparse attention kernels. Experimental results show that Token Sparse Attention consistently improves accuracy-latency trade-off, achieving up to $\times$3.23 attention speedup at 128K context with less than 1% accuracy degradation. These results demonstrate that dynamic and interleaved token-level sparsification is a complementary and effective strategy for scalable long-context inference.
LRAgent: Efficient KV Cache Sharing for Multi-LoRA LLM Agents
Feb 01, 2026Role specialization in multi-LLM agent systems is often realized via multi-LoRA, where agents share a pretrained backbone and differ only through lightweight adapters. Despite sharing base model weights, each agent independently builds and stores its own KV cache for the same long, tool-augmented trajectories, incurring substantial memory and compute overhead. Existing KV cache sharing methods largely overlook this multi-LoRA setting. We observe that, across agents, cache differences are dominated by adapter outputs, while activations from the shared pretrained backbone remain highly similar. Based on this observation, we propose LRAgent, a KV cache sharing framework for multi-LoRA agents that decomposes the cache into a shared base component from the pretrained weights and an adapter-dependent component from LoRA weights. LRAgent reduces memory overhead by sharing the base component and storing the adapter component in its inherent low-rank form, and further reduces compute overhead, enabled by shared-$A$ multi-LoRA architectures, by also sharing the low-rank cache and avoiding redundant computations for contexts already processed by other agents. To efficiently reconstruct adapter contributions at runtime, we introduce Flash-LoRA-Attention, a kernel that reorders attention computation to avoid materializing the low-rank cache to full dimension. LRAgent achieves throughput and time-to-first-token latency close to fully shared caching, while preserving accuracy near the non-shared caching baseline across agentic question-answering benchmarks.
LiteStage: Latency-aware Layer Skipping for Multi-stage Reasoning
Oct 16, 2025Multi-stage reasoning has emerged as an effective strategy for enhancing the reasoning capability of small language models by decomposing complex problems into sequential sub-stages. However, this comes at the cost of increased latency. We observe that existing adaptive acceleration techniques, such as layer skipping, struggle to balance efficiency and accuracy in this setting due to two key challenges: (1) stage-wise variation in skip sensitivity, and (2) the generation of redundant output tokens. To address these, we propose LiteStage, a latency-aware layer skipping framework for multi-stage reasoning. LiteStage combines a stage-wise offline search that allocates optimal layer budgets with an online confidence-based generation early exit to suppress unnecessary decoding. Experiments on three benchmarks, e.g., OBQA, CSQA, and StrategyQA, show that LiteStage achieves up to 1.70x speedup with less than 4.0% accuracy loss, outperforming prior training-free layer skipping methods.
Retrospective Sparse Attention for Efficient Long-Context Generation
Aug 12, 2025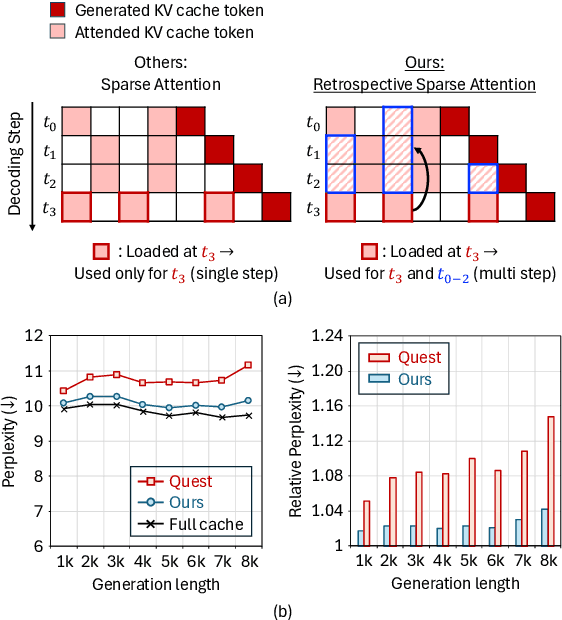
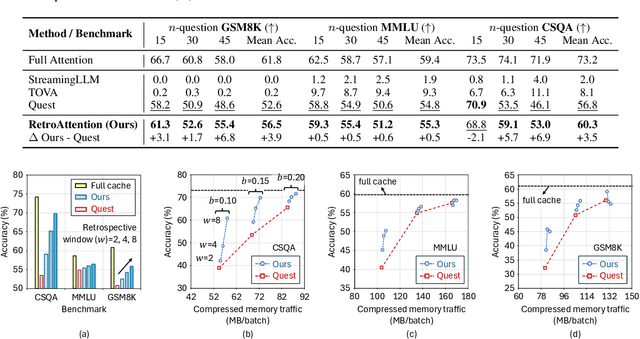
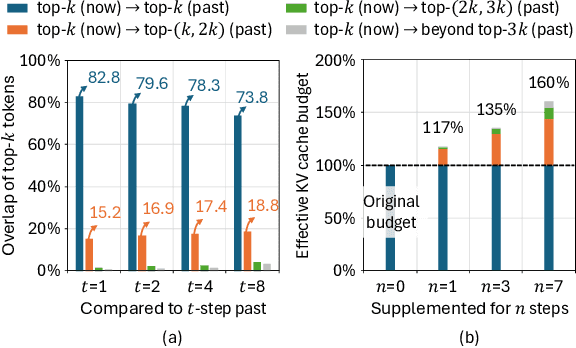
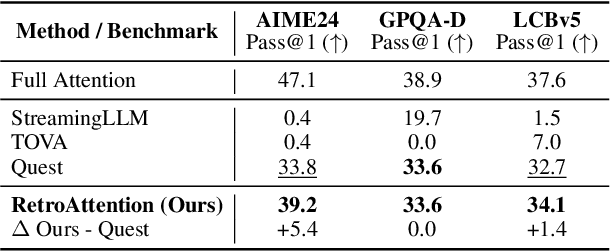
Large Language Models (LLMs) are increasingly deployed in long-context tasks such as reasoning, code generation, and multi-turn dialogue. However, inference over extended contexts is bottlenecked by the Key-Value (KV) cache, whose memory footprint grows linearly with sequence length and dominates latency at each decoding step. While recent KV cache compression methods identify and load important tokens, they focus predominantly on input contexts and fail to address the cumulative attention errors that arise during long decoding. In this paper, we introduce RetroAttention, a novel KV cache update technique that retrospectively revises past attention outputs using newly arrived KV entries from subsequent decoding steps. By maintaining a lightweight output cache, RetroAttention enables past queries to efficiently access more relevant context, while incurring minimal latency overhead. This breaks the fixed-attention-output paradigm and allows continual correction of prior approximations. Extensive experiments on long-generation benchmarks show that RetroAttention consistently outperforms state-of-the-art (SOTA) KV compression methods, increasing effective KV exposure by up to 1.6$\times$ and accuracy by up to 21.9\%.
Reasoning Path Compression: Compressing Generation Trajectories for Efficient LLM Reasoning
May 20, 2025



Recent reasoning-focused language models achieve high accuracy by generating lengthy intermediate reasoning paths before producing final answers. While this approach is effective in solving problems that require logical thinking, long reasoning paths significantly increase memory usage and throughput of token generation, limiting the practical deployment of such models. We propose Reasoning Path Compression (RPC), a training-free method that accelerates inference by leveraging the semantic sparsity of reasoning paths. RPC periodically compresses the KV cache by retaining KV cache that receive high importance score, which are computed using a selector window composed of recently generated queries. Experiments show that RPC improves generation throughput of QwQ-32B by up to 1.60$\times$ compared to the inference with full KV cache, with an accuracy drop of 1.2% on the AIME 2024 benchmark. Our findings demonstrate that semantic sparsity in reasoning traces can be effectively exploited for compression, offering a practical path toward efficient deployment of reasoning LLMs. Our code is available at https://github.com/jiwonsong-dev/ReasoningPathCompression.
FastKV: KV Cache Compression for Fast Long-Context Processing with Token-Selective Propagation
Feb 03, 2025While large language models (LLMs) excel at handling long-context sequences, they require substantial key-value (KV) caches to store contextual information, which can heavily burden computational efficiency and memory usage. Previous efforts to compress these KV caches primarily focused on reducing memory demands but were limited in enhancing latency. To address this issue, we introduce FastKV, a KV cache compression method designed to enhance latency for long-context sequences. To enhance processing speeds while maintaining accuracy, FastKV adopts a novel Token-Selective Propagation (TSP) approach that retains the full context information in the initial layers of LLMs and selectively propagates only a portion of this information in deeper layers even in the prefill stage. Additionally, FastKV incorporates grouped-query attention (GQA)-aware KV cache compression to exploit the advantages of GQA in both memory and computational efficiency. Our experimental results show that FastKV achieves 2.00$\times$ and 1.40$\times$ improvements in time-to-first-token (TTFT) and throughput, respectively, compared to HeadKV, the state-of-the-art KV cache compression method. Moreover, FastKV successfully maintains accuracy on long-context benchmarks at levels comparable to the baselines. Our code is available at https://github.com/dongwonjo/FastKV.
COMPASS: A Compiler Framework for Resource-Constrained Crossbar-Array Based In-Memory Deep Learning Accelerators
Jan 12, 2025



Recently, crossbar array based in-memory accelerators have been gaining interest due to their high throughput and energy efficiency. While software and compiler support for the in-memory accelerators has also been introduced, they are currently limited to the case where all weights are assumed to be on-chip. This limitation becomes apparent with the significantly increasing network sizes compared to the in-memory footprint. Weight replacement schemes are essential to address this issue. We propose COMPASS, a compiler framework for resource-constrained crossbar-based processing-in-memory (PIM) deep neural network (DNN) accelerators. COMPASS is specially targeted for networks that exceed the capacity of PIM crossbar arrays, necessitating access to external memories. We propose an algorithm to determine the optimal partitioning that divides the layers so that each partition can be accelerated on chip. Our scheme takes into account the data dependence between layers, core utilization, and the number of write instructions to minimize latency, memory accesses, and improve energy efficiency. Simulation results demonstrate that COMPASS can accommodate much more networks using a minimal memory footprint, while improving throughput by 1.78X and providing 1.28X savings in energy-delay product (EDP) over baseline partitioning methods.
Mixture of Scales: Memory-Efficient Token-Adaptive Binarization for Large Language Models
Jun 18, 2024



Binarization, which converts weight parameters to binary values, has emerged as an effective strategy to reduce the size of large language models (LLMs). However, typical binarization techniques significantly diminish linguistic effectiveness of LLMs. To address this issue, we introduce a novel binarization technique called Mixture of Scales (BinaryMoS). Unlike conventional methods, BinaryMoS employs multiple scaling experts for binary weights, dynamically merging these experts for each token to adaptively generate scaling factors. This token-adaptive approach boosts the representational power of binarized LLMs by enabling contextual adjustments to the values of binary weights. Moreover, because this adaptive process only involves the scaling factors rather than the entire weight matrix, BinaryMoS maintains compression efficiency similar to traditional static binarization methods. Our experimental results reveal that BinaryMoS surpasses conventional binarization techniques in various natural language processing tasks and even outperforms 2-bit quantization methods, all while maintaining similar model size to static binarization techniques.