 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
SEAL: Scaling to Emphasize Attention for Long-Context Retrieval
Jan 25, 2025



In this work, we introduce a novel approach called Scaling to Emphasize Attention for Long-context retrieval (SEAL), which enhances the retrieval performance of large language models (LLMs) over extended contexts. Previous studies have shown that each attention head in LLMs has a unique functionality and collectively contributes to the overall behavior of the model. Similarly, we observe that specific heads are closely tied to long-context retrieval, showing positive or negative correlation with retrieval scores. Built on this insight, we propose a learning-based mechanism using zero-shot generated data to emphasize these heads, improving the model's performance in long-context retrieval tasks. By applying SEAL, we can achieve significant improvements in in-domain retrieval performance, including document QA tasks from LongBench, and considerable improvements in out-of-domain cases. Additionally, when combined with existing training-free context extension techniques, SEAL extends the context limits of LLMs while maintaining highly reliable outputs, opening new avenues for research in this field.
PTQ4VM: Post-Training Quantization for Visual Mamba
Dec 29, 2024



Visual Mamba is an approach that extends the selective space state model, Mamba, to vision tasks. It processes image tokens sequentially in a fixed order, accumulating information to generate outputs. Despite its growing popularity for delivering high-quality outputs at a low computational cost across various tasks, Visual Mamba is highly susceptible to quantization, which makes further performance improvements challenging. Our analysis reveals that the fixed token access order in Visual Mamba introduces unique quantization challenges, which we categorize into three main issues: 1) token-wise variance, 2) channel-wise outliers, and 3) a long tail of activations. To address these challenges, we propose Post-Training Quantization for Visual Mamba (PTQ4VM), which introduces two key strategies: Per-Token Static (PTS) quantization and Joint Learning of Smoothing Scale and Step Size (JLSS). To the our best knowledge, this is the first quantization study on Visual Mamba. PTQ4VM can be applied to various Visual Mamba backbones, converting the pretrained model to a quantized format in under 15 minutes without notable quality degradation. Extensive experiments on large-scale classification and regression tasks demonstrate its effectiveness, achieving up to 1.83x speedup on GPUs with negligible accuracy loss compared to FP16. Our code is available at https://github.com/YoungHyun197/ptq4vm.
QEFT: Quantization for Efficient Fine-Tuning of LLMs
Oct 11, 2024With the rapid growth in the use of fine-tuning for large language models (LLMs), optimizing fine-tuning while keeping inference efficient has become highly important. However, this is a challenging task as it requires improvements in all aspects, including inference speed, fine-tuning speed, memory consumption, and, most importantly, model quality. Previous studies have attempted to achieve this by combining quantization with fine-tuning, but they have failed to enhance all four aspects simultaneously. In this study, we propose a new lightweight technique called Quantization for Efficient Fine-Tuning (QEFT). QEFT accelerates both inference and fine-tuning, is supported by robust theoretical foundations, offers high flexibility, and maintains good hardware compatibility. Our extensive experiments demonstrate that QEFT matches the quality and versatility of full-precision parameter-efficient fine-tuning, while using fewer resources. Our code is available at https://github.com/xvyaward/qeft.
Repurformer: Transformers for Repurposing-Aware Molecule Generation
Jul 16, 2024



Generating as diverse molecules as possible with desired properties is crucial for drug discovery research, which invokes many approaches based on deep generative models today. Despite recent advancements in these models, particularly in variational autoencoders (VAEs), generative adversarial networks (GANs), Transformers, and diffusion models, a significant challenge known as \textit{the sample bias problem} remains. This problem occurs when generated molecules targeting the same protein tend to be structurally similar, reducing the diversity of generation. To address this, we propose leveraging multi-hop relationships among proteins and compounds. Our model, Repurformer, integrates bi-directional pretraining with Fast Fourier Transform (FFT) and low-pass filtering (LPF) to capture complex interactions and generate diverse molecules. A series of experiments on BindingDB dataset confirm that Repurformer successfully creates substitutes for anchor compounds that resemble positive compounds, increasing diversity between the anchor and generated compounds.
A Bi-objective Perspective on Controllable Language Models: Reward Dropout Improves Off-policy Control Performance
Oct 06, 2023



We study the theoretical aspects of CLMs (Controllable Language Models) from a bi-objective optimization perspective. Specifically, we consider the CLMs as an off-policy RL problem that requires simultaneously maximizing the reward and likelihood objectives. Our main contribution consists of three parts. First, we establish the theoretical foundations of CLM by presenting reward upper bound and Pareto improvement/optimality conditions. Second, we analyze conditions that improve and violate Pareto optimality itself, respectively. Finally, we propose Reward Dropout, a simple yet powerful method to guarantee policy improvement based on a Pareto improvement condition. Our theoretical outcomes are supported by not only deductive proofs but also empirical results. The performance of Reward Dropout was evaluated on five CLM benchmark datasets, and it turns out that the Reward Dropout significantly improves the performance of CLMs.
OWQ: Lessons learned from activation outliers for weight quantization in large language models
Jun 13, 2023



Large language models (LLMs) with hundreds of billions of parameters show impressive results across various language tasks using simple prompt tuning and few-shot examples, without the need for task-specific fine-tuning. However, their enormous size requires multiple server-grade GPUs even for inference, creating a significant cost barrier. To address this limitation, we introduce a novel post-training quantization method for weights with minimal quality degradation. While activation outliers are known to be problematic in activation quantization, our theoretical analysis suggests that we can identify factors contributing to weight quantization errors by considering activation outliers. We propose an innovative PTQ scheme called outlier-aware weight quantization (OWQ), which identifies vulnerable weights and allocates high-precision to them. Our extensive experiments demonstrate that the 3.01-bit models produced by OWQ exhibit comparable quality to the 4-bit models generated by OPTQ.
INSTA-BNN: Binary Neural Network with INSTAnce-aware Threshold
Apr 18, 2022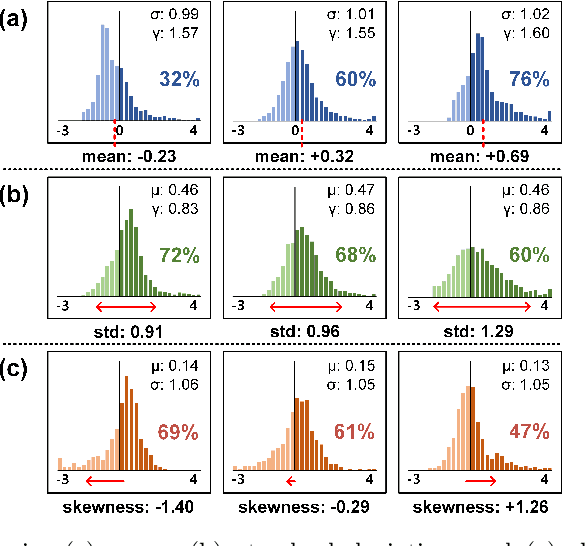
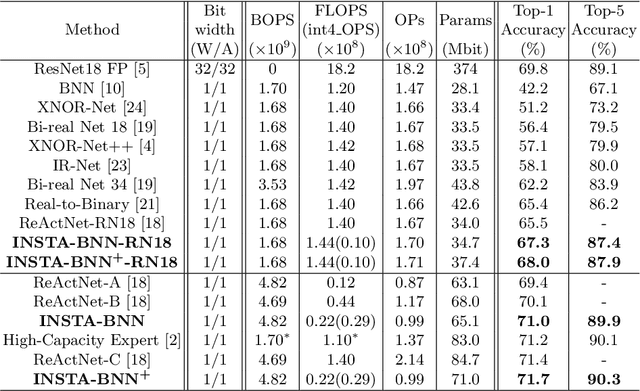
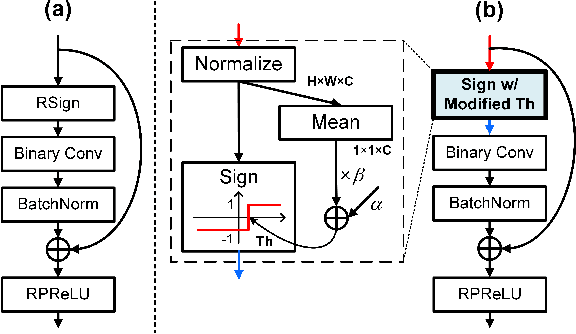

Binary Neural Networks (BNNs) have emerged as a promising solution for reducing the memory footprint and compute costs of deep neural networks. BNNs, on the other hand, suffer from information loss because binary activations are limited to only two values, resulting in reduced accuracy. To improve the accuracy, previous studies have attempted to control the distribution of binary activation by manually shifting the threshold of the activation function or making the shift amount trainable. During the process, they usually depended on statistical information computed from a batch. We argue that using statistical data from a batch fails to capture the crucial information for each input instance in BNN computations, and the differences between statistical information computed from each instance need to be considered when determining the binary activation threshold of each instance. Based on the concept, we propose the Binary Neural Network with INSTAnce-aware threshold (INSTA-BNN), which decides the activation threshold value considering the difference between statistical data computed from a batch and each instance. The proposed INSTA-BNN outperforms the baseline by 2.5% and 2.3% on the ImageNet classification task with comparable computing cost, achieving 68.0% and 71.7% top-1 accuracy on ResNet-18 and MobileNetV1 based models, respectively.
Improving Accuracy of Binary Neural Networks using Unbalanced Activation Distribution
Dec 02, 2020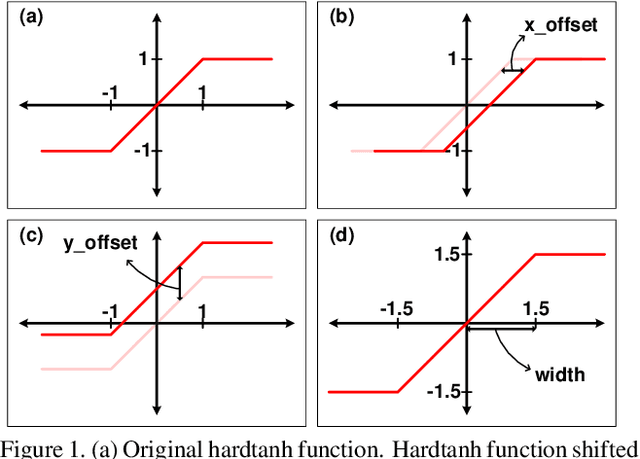
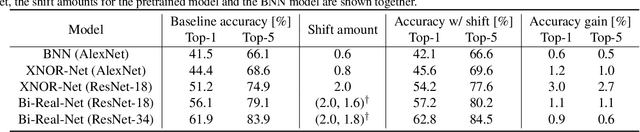
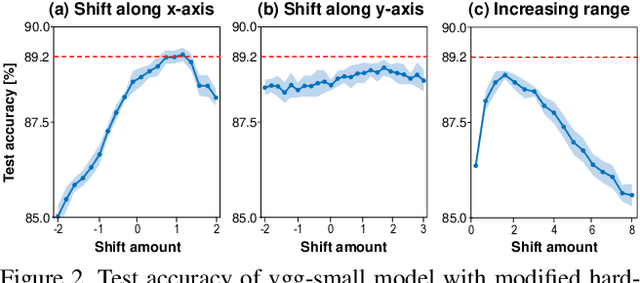
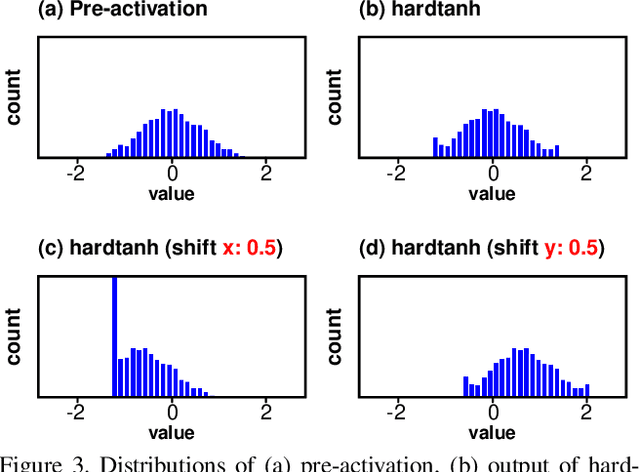
Binarization of neural network models is considered as one of the promising methods to deploy deep neural network models on resource-constrained environments such as mobile devices. However, Binary Neural Networks (BNNs) tend to suffer from severe accuracy degradation compared to the full-precision counterpart model. Several techniques were proposed to improve the accuracy of BNNs. One of the approaches is to balance the distribution of binary activations so that the amount of information in the binary activations becomes maximum. Based on extensive analysis, in stark contrast to previous work, we argue that unbalanced activation distribution can actually improve the accuracy of BNNs. We also show that adjusting the threshold values of binary activation functions results in the unbalanced distribution of the binary activation, which increases the accuracy of BNN models. Experimental results show that the accuracy of previous BNN models (e.g. XNOR-Net and Bi-Real-Net) can be improved by simply shifting the threshold values of binary activation functions without requiring any other modification.