 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dataset of Propaganda Techniques of the State-Sponsored Information Operation of the People's Republic of China
Jun 14, 2021
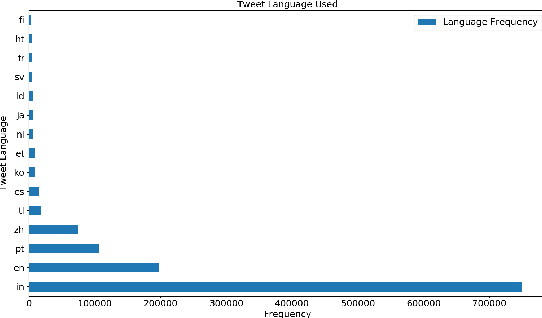

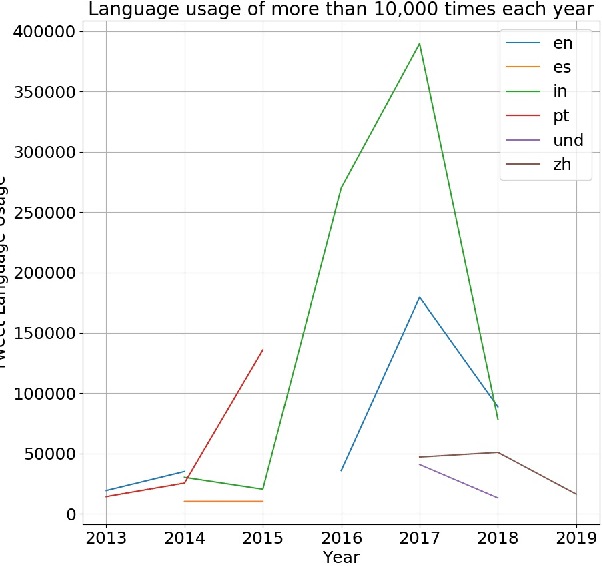

The digital media, identified as computational propaganda provides a pathway for propaganda to expand its reach without limit. State-backed propaganda aims to shape the audiences' cognition toward entities in favor of a certain political party or authority. Furthermore, it has become part of modern information warfare used in order to gain an advantage over opponents. Most of the current studies focus on using machine learning, quantitative, and qualitative methods to distinguish if a certain piece of information on social media is propaganda. Mainly conducted on English content, but very little research addresses Chinese Mandarin content. From propaganda detection, we want to go one step further to provide more fine-grained information on propaganda techniques that are applied. In this research, we aim to bridge the information gap by providing a multi-labeled propaganda techniques dataset in Mandarin based on a state-backed information operation dataset provided by Twitter. In addition to presenting the dataset, we apply a multi-label text classification using fine-tuned BERT. Potentially this could help future research in detecting state-backed propaganda online especially in a cross-lingual context and cross platforms identity consolidation.
SeLoC-ML: Semantic Low-Code Engineering for Machine Learning Applications in Industrial IoT
Jul 18, 2022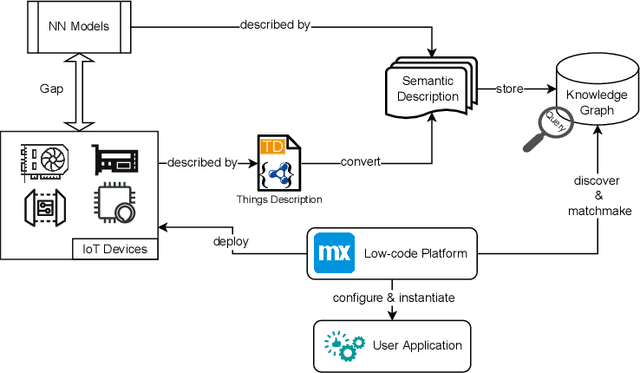

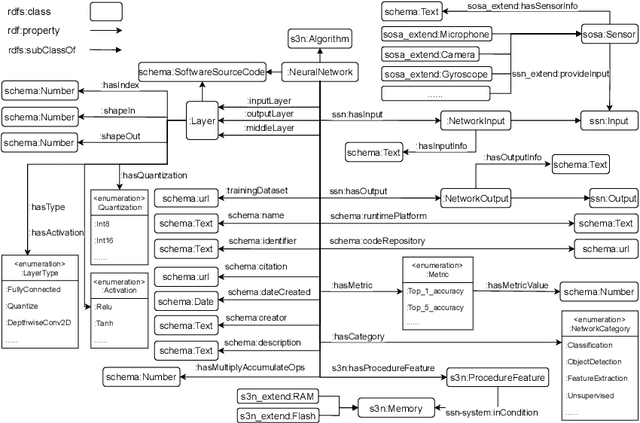

Internet of Things (IoT) is transforming the industry by bridging the gap between Information Technology (IT) and Operational Technology (OT). Machines are being integrated with connected sensors and managed by intelligent analytics applications, accelerating digital transformation and business operations. Bringing Machine Learning (ML) to industrial devices is an advancement aiming to promote the convergence of IT and OT. However, developing an ML application in industrial IoT (IIoT) presents various challenges, including hardware heterogeneity, non-standardized representations of ML models, device and ML model compatibility issues, and slow application development. Successful deployment in this area requires a deep understanding of hardware, algorithms, software tools, and applications. Therefore, this paper presents a framework called Semantic Low-Code Engineering for ML Applications (SeLoC-ML), built on a low-code platform to support the rapid development of ML applications in IIoT by leveraging Semantic Web technologies. SeLoC-ML enables non-experts to easily model, discover, reuse, and matchmake ML models and devices at scale. The project code can be automatically generated for deployment on hardware based on the matching results. Developers can benefit from semantic application templates, called recipes, to fast prototype end-user applications. The evaluations confirm an engineering effort reduction by a factor of at least three compared to traditional approaches on an industrial ML classification case study, showing the efficiency and usefulness of SeLoC-ML. We share the code and welcome any contributions.
Eliciting and Learning with Soft Labels from Every Annotator
Jul 02, 2022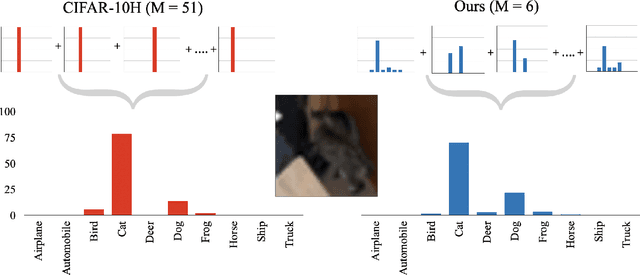

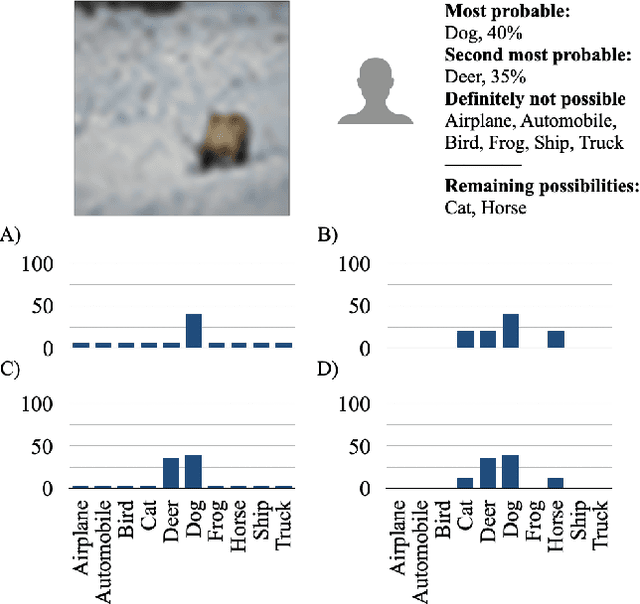

The labels used to train machine learning (ML) models are of paramount importance. Typically for ML classification tasks, datasets contain hard labels, yet learning using soft labels has been shown to yield benefits for model generalization, robustness, and calibration. Earlier work found success in forming soft labels from multiple annotators' hard labels; however, this approach may not converge to the best labels and necessitates many annotators, which can be expensive and inefficient. We focus on efficiently eliciting soft labels from individual annotators. We collect and release a dataset of soft labels for CIFAR-10 via a crowdsourcing study ($N=242$). We demonstrate that learning with our labels achieves comparable model performance to prior approaches while requiring far fewer annotators. Our elicitation methodology therefore shows promise towards enabling practitioners to enjoy the benefits of improved model performance and reliability with fewer annotators, and serves as a guide for future dataset curators on the benefits of leveraging richer information, such as categorical uncertainty, from individual annotators.
Reborn Mechanism: Rethinking the Negative Phase Information Flow in Convolutional Neural Network
Jun 13, 2021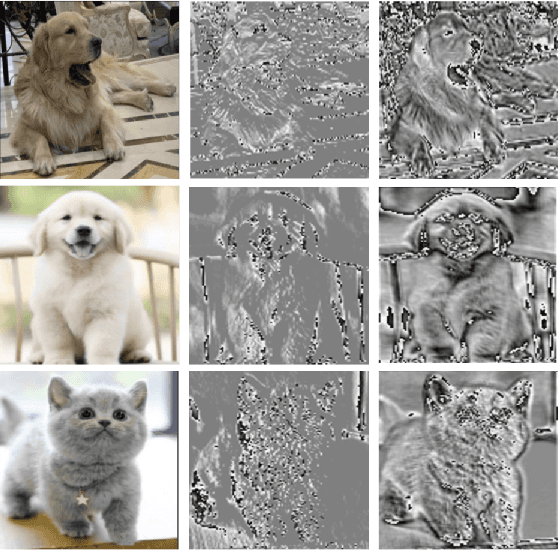
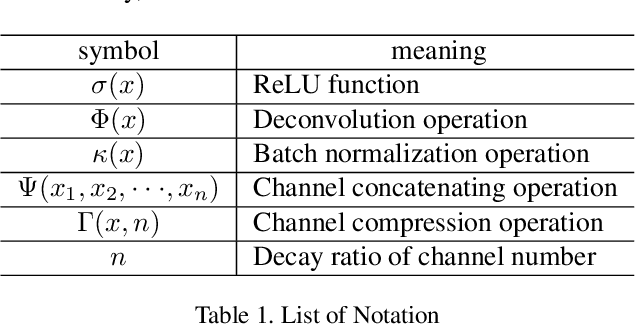
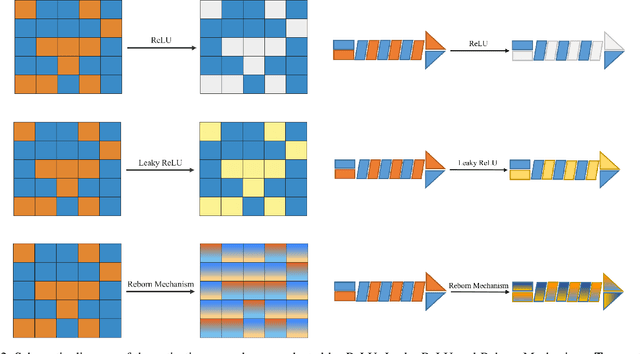
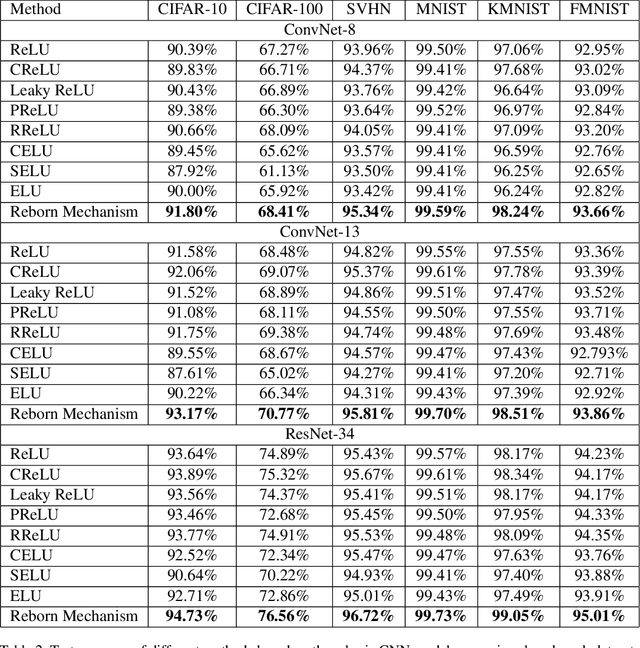
This paper proposes a novel nonlinear activation mechanism typically for convolutional neural network (CNN), named as reborn mechanism. In sharp contrast to ReLU which cuts off the negative phase value, the reborn mechanism enjoys the capacity to reborn and reconstruct dead neurons. Compared to other improved ReLU functions, reborn mechanism introduces a more proper way to utilize the negative phase information. Extensive experiments validate that this activation mechanism is able to enhance the model representation ability more significantly and make the better use of the input data information while maintaining the advantages of the original ReLU function. Moreover, reborn mechanism enables a non-symmetry that is hardly achieved by traditional CNNs and can act as a channel compensation method, offering competitive or even better performance but with fewer learned parameters than traditional methods. Reborn mechanism was tested on various benchmark datasets, all obtaining better performance than previous nonlinear activation functions.
Few-Shot Diffusion Models
May 30, 2022

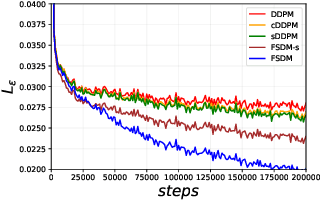
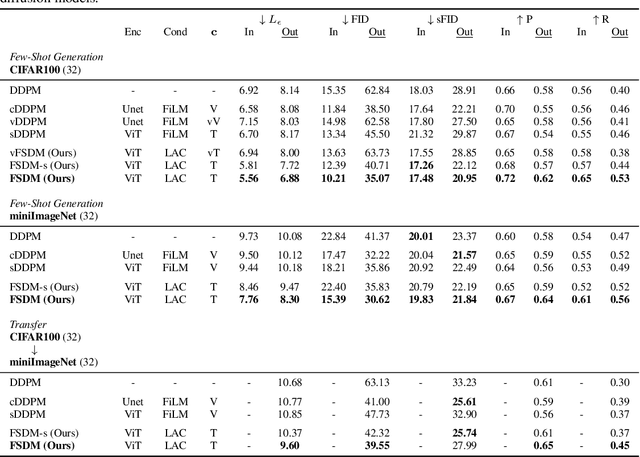
Denoising diffusion probabilistic models (DDPM) are powerful hierarchical latent variable models with remarkable sample generation quality and training stability. These properties can be attributed to parameter sharing in the generative hierarchy, as well as a parameter-free diffusion-based inference procedure. In this paper, we present Few-Shot Diffusion Models (FSDM), a framework for few-shot generation leveraging conditional DDPMs. FSDMs are trained to adapt the generative process conditioned on a small set of images from a given class by aggregating image patch information using a set-based Vision Transformer (ViT). At test time, the model is able to generate samples from previously unseen classes conditioned on as few as 5 samples from that class. We empirically show that FSDM can perform few-shot generation and transfer to new datasets. We benchmark variants of our method on complex vision datasets for few-shot learning and compare to unconditional and conditional DDPM baselines. Additionally, we show how conditioning the model on patch-based input set information improves training convergence.
Multi-User Rate Splitting in Optical Wireless Networks
Jul 23, 2022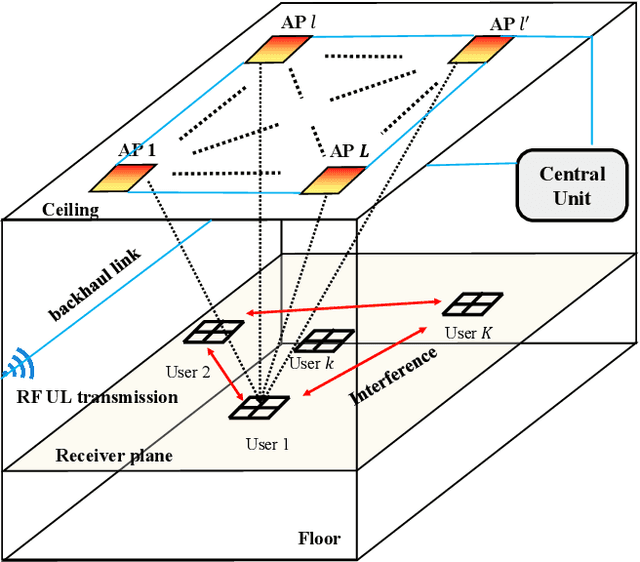
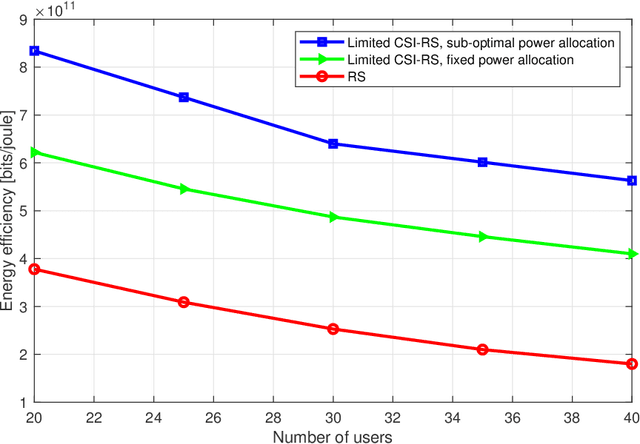
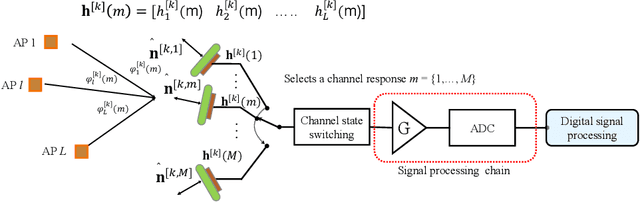
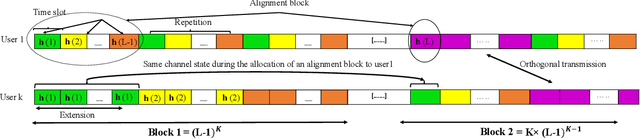
Optical wireless communication (OWC) has recently received massive interest as a new technology that can support the enormous data traffic increasing on daily basis. Laser-based OWC networks can provide terabits per second (Tbps) aggregate data rates. However, the emerging OWC networks require clusters of optical transmitters to provide uniform coverage for multiple users. In this context, multi-user interference (MUI) is a crucial issue that must be managed efficiently to provide high spectral efficiency. Rate splitting (RS) is proposed as a transmission scheme to serve multiple users simultaneously by splitting the message of a given user into common and private messages, and then, each user decodes the desired message following a certain procedure. In radio frequency (RF) networks, RS provides higher spectral efficiency compared with orthogonal and non-orthogonal transmission schemes. Considering the high density of OWC networks, the performance of RS is limited by the cost of providing channel state information (CSI) at transmitters and by the noise resulting from interference cancellation. In this work, a user-grouping algorithm is proposed and used to form multiple groups, each group contains users spatially clustered. Then, an outer precoder is designed to manage inter-group interference following the methodology of blind interference alignment (BIA), which reduces the requirements of CSI at RF or optical transmitters. For intra-group interference, RS is applied within each group where the users belonging to a given group receive a unique common message on which their private messages are superimposed. Furthermore, an optimization problem is formulated to allocate the power among the private messages intended to all users such that the sum rate of the network is maximized.
Open-world Semantic Segmentation via Contrasting and Clustering Vision-Language Embedding
Jul 18, 2022
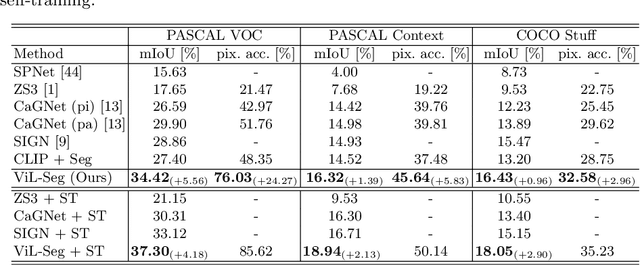
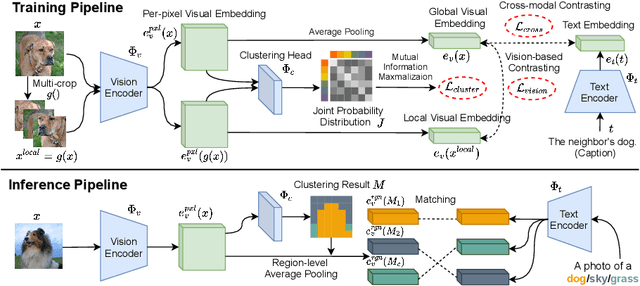
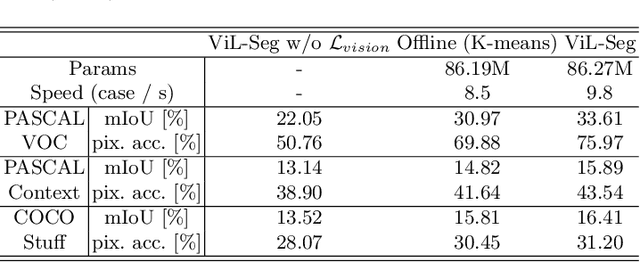
To bridge the gap between supervised semantic segmentation and real-world applications that acquires one model to recognize arbitrary new concepts, recent zero-shot segmentation attracts a lot of attention by exploring the relationships between unseen and seen object categories, yet requiring large amounts of densely-annotated data with diverse base classes. In this paper, we propose a new open-world semantic segmentation pipeline that makes the first attempt to learn to segment semantic objects of various open-world categories without any efforts on dense annotations, by purely exploiting the image-caption data that naturally exist on the Internet. Our method, Vision-language-driven Semantic Segmentation (ViL-Seg), employs an image and a text encoder to generate visual and text embeddings for the image-caption data, with two core components that endow its segmentation ability: First, the image encoder is jointly trained with a vision-based contrasting and a cross-modal contrasting, which encourage the visual embeddings to preserve both fine-grained semantics and high-level category information that are crucial for the segmentation task. Furthermore, an online clustering head is devised over the image encoder, which allows to dynamically segment the visual embeddings into distinct semantic groups such that they can be classified by comparing with various text embeddings to complete our segmentation pipeline. Experiments show that without using any data with dense annotations, our method can directly segment objects of arbitrary categories, outperforming zero-shot segmentation methods that require data labeling on three benchmark datasets.
Learning Joint Detection, Equalization and Decoding for Short-Packet Communications
Jul 12, 2022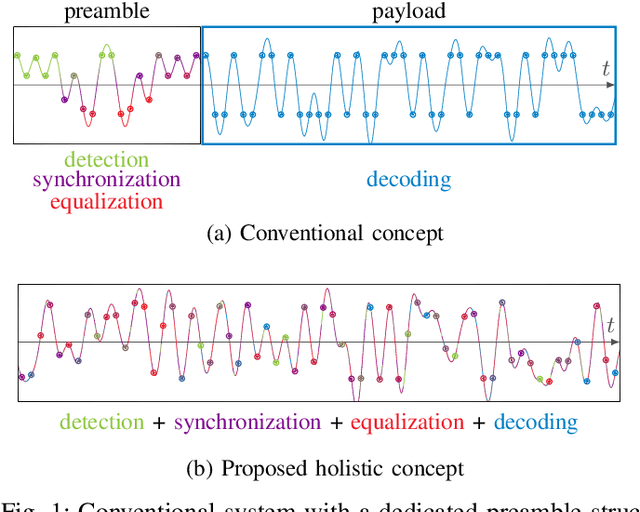
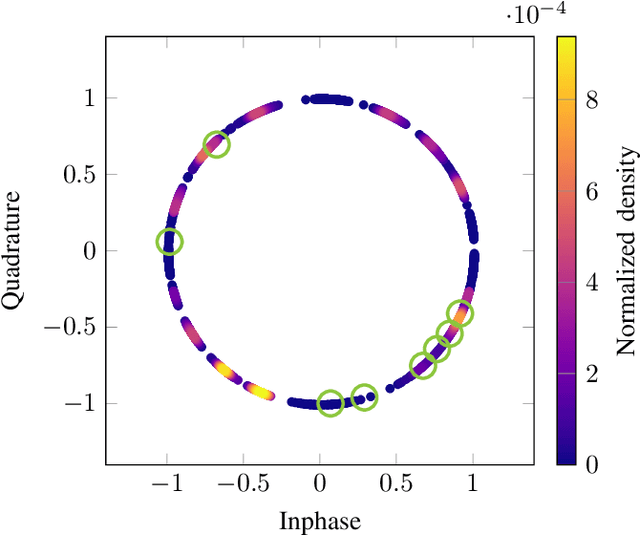
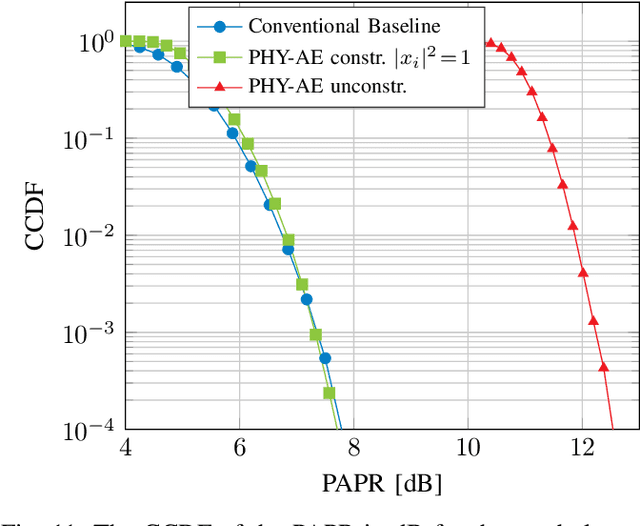
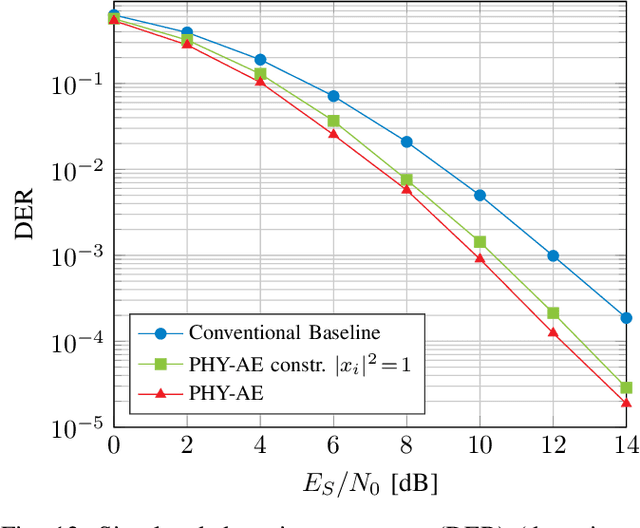
We propose and practically demonstrate a joint detection and decoding scheme for short-packet wireless communications in scenarios that require to first detect the presence of a message before actually decoding it. For this, we extend the recently proposed serial Turbo-autoencoder neural network (NN) architecture and train it to find short messages that can be, all "at once", detected, synchronized, equalized and decoded when sent over an unsynchronized channel with memory. The conceptional advantage of the proposed system stems from a holistic message structure with superimposed pilots for joint detection and decoding without the need of relying on a dedicated preamble. This results not only in higher spectral efficiency, but also translates into the possibility of shorter messages compared to using a dedicated preamble. We compare the detection error rate (DER), bit error rate (BER) and block error rate (BLER) performance of the proposed system with a hand-crafted state-of-the-art conventional baseline and our simulations show a significant advantage of the proposed autoencoder-based system over the conventional baseline in every scenario up to messages conveying k = 96 information bits. Finally, we practically evaluate and confirm the improved performance of the proposed system over-the-air (OTA) using a software-defined radio (SDR)-based measurement testbed.
Speak Like a Dog: Human to Non-human creature Voice Conversion
Jun 09, 2022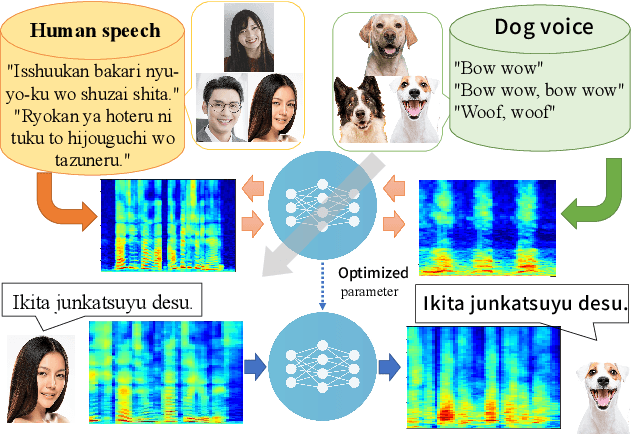
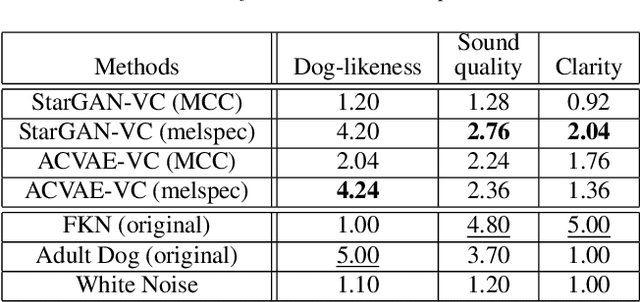
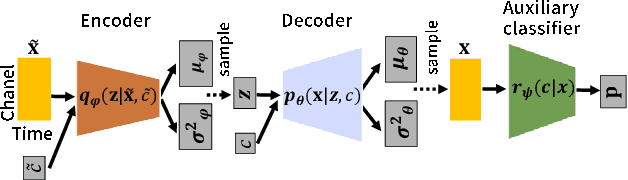
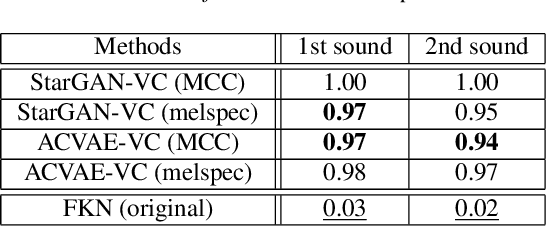
This paper proposes a new voice conversion (VC) task from human speech to dog-like speech while preserving linguistic information as an example of human to non-human creature voice conversion (H2NH-VC) tasks. Although most VC studies deal with human to human VC, H2NH-VC aims to convert human speech into non-human creature-like speech. Non-parallel VC allows us to develop H2NH-VC, because we cannot collect a parallel dataset that non-human creatures speak human language. In this study, we propose to use dogs as an example of a non-human creature target domain and define the "speak like a dog" task. To clarify the possibilities and characteristics of the "speak like a dog" task, we conducted a comparative experiment using existing representative non-parallel VC methods in acoustic features (Mel-cepstral coefficients and Mel-spectrograms), network architectures (five different kernel-size settings), and training criteria (variational autoencoder (VAE)- based and generative adversarial network-based). Finally, the converted voices were evaluated using mean opinion scores: dog-likeness, sound quality and intelligibility, and character error rate (CER). The experiment showed that the employment of the Mel-spectrogram improved the dog-likeness of the converted speech, while it is challenging to preserve linguistic information. Challenges and limitations of the current VC methods for H2NH-VC are highlighted.
TokenMix: Rethinking Image Mixing for Data Augmentation in Vision Transformers
Jul 18, 2022
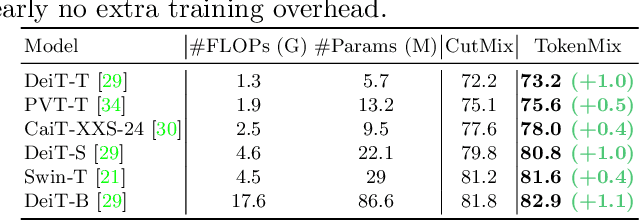
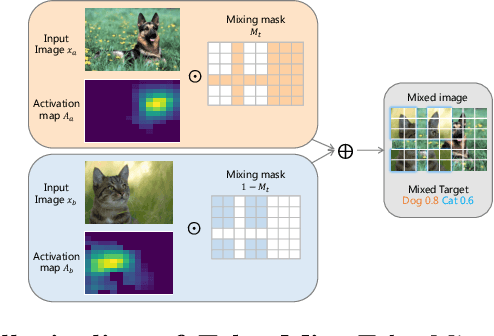

CutMix is a popular augmentation technique commonly used for training modern convolutional and transformer vision networks. It was originally designed to encourage Convolution Neural Networks (CNNs) to focus more on an image's global context instead of local information, which greatly improves the performance of CNNs. However, we found it to have limited benefits for transformer-based architectures that naturally have a global receptive field. In this paper, we propose a novel data augmentation technique TokenMix to improve the performance of vision transformers. TokenMix mixes two images at token level via partitioning the mixing region into multiple separated parts. Besides, we show that the mixed learning target in CutMix, a linear combination of a pair of the ground truth labels, might be inaccurate and sometimes counter-intuitive. To obtain a more suitable target, we propose to assign the target score according to the content-based neural activation maps of the two images from a pre-trained teacher model, which does not need to have high performance. With plenty of experiments on various vision transformer architectures, we show that our proposed TokenMix helps vision transformers focus on the foreground area to infer the classes and enhances their robustness to occlusion, with consistent performance gains. Notably, we improve DeiT-T/S/B with +1% ImageNet top-1 accuracy. Besides, TokenMix enjoys longer training, which achieves 81.2% top-1 accuracy on ImageNet with DeiT-S trained for 400 epochs. Code is available at https://github.com/Sense-X/TokenMix.