 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RZSR: Reference-based Zero-Shot Super-Resolution with Depth Guided Self-Exemplars
Aug 24, 2022
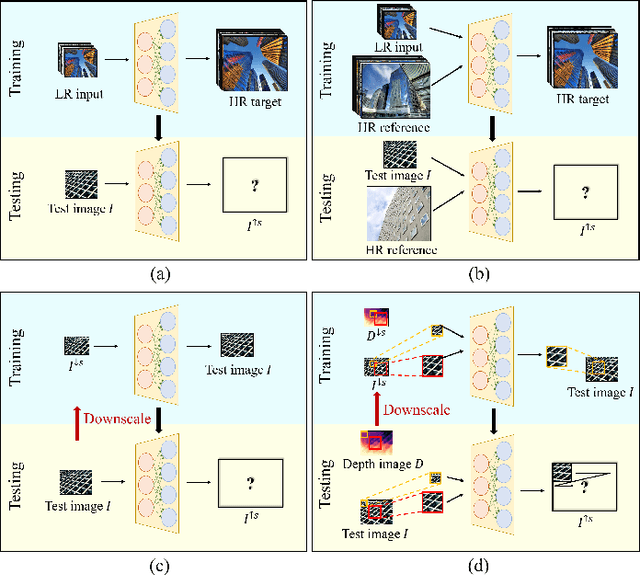
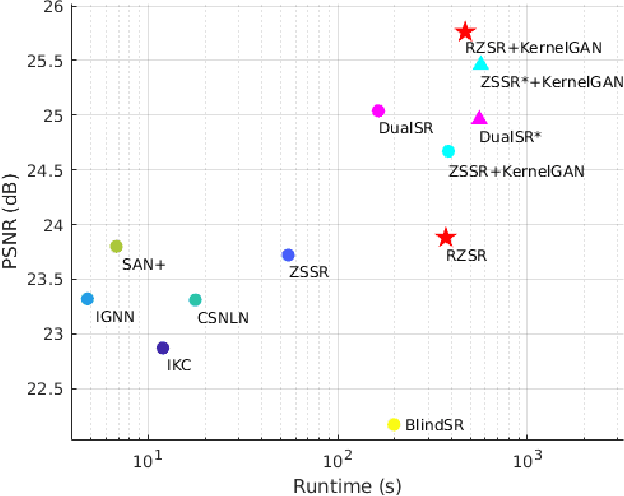
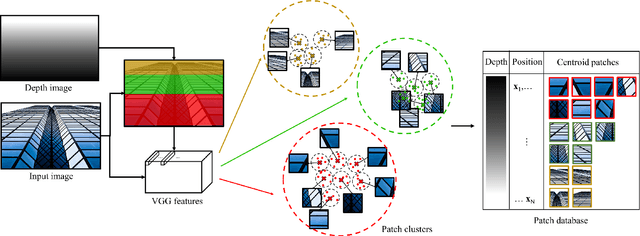
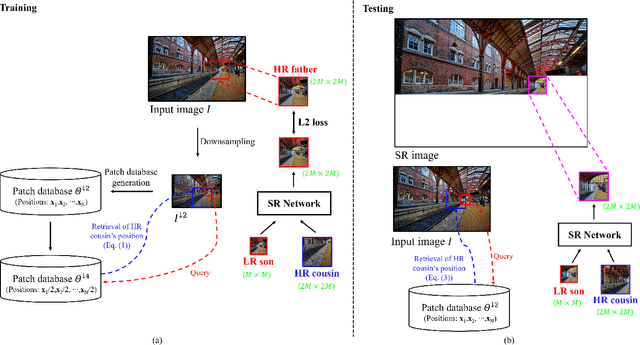
Recent methods for single image super-resolution (SISR) have demonstrated outstanding performance in generating high-resolution (HR) images from low-resolution (LR) images. However, most of these methods show their superiority using synthetically generated LR images, and their generalizability to real-world images is often not satisfactory. In this paper, we pay attention to two well-known strategies developed for robust super-resolution (SR), i.e., reference-based SR (RefSR) and zero-shot SR (ZSSR), and propose an integrated solution, called reference-based zero-shot SR (RZSR). Following the principle of ZSSR, we train an image-specific SR network at test time using training samples extracted only from the input image itself. To advance ZSSR, we obtain reference image patches with rich textures and high-frequency details which are also extracted only from the input image using cross-scale matching. To this end, we construct an internal reference dataset and retrieve reference image patches from the dataset using depth information. Using LR patches and their corresponding HR reference patches, we train a RefSR network that is embodied with a non-local attention module. Experimental results demonstrate the superiority of the proposed RZSR compared to the previous ZSSR methods and robustness to unseen images compared to other fully supervised SISR methods.
Using Chatbots to Teach Languages
Jul 31, 2022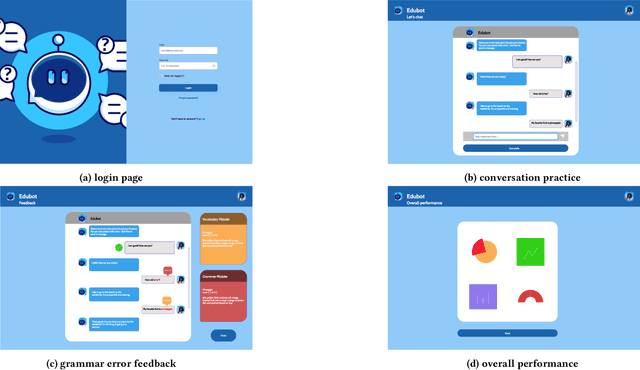

This paper reports on progress towards building an online language learning tool to provide learners with conversational experience by using dialog systems as conversation practice partners. Our system can adapt to users' language proficiency on the fly. We also provide automatic grammar error feedback to help users learn from their mistakes. According to our first adopters, our system is entertaining and useful. Furthermore, we will provide the learning technology community a large-scale conversation dataset on language learning and grammar correction. Our next step is to make our system more adaptive to user profile information by using reinforcement learning algorithms.
Massive MIMO Channel Prediction Using Machine Learning: Power of Domain Transformation
Aug 09, 2022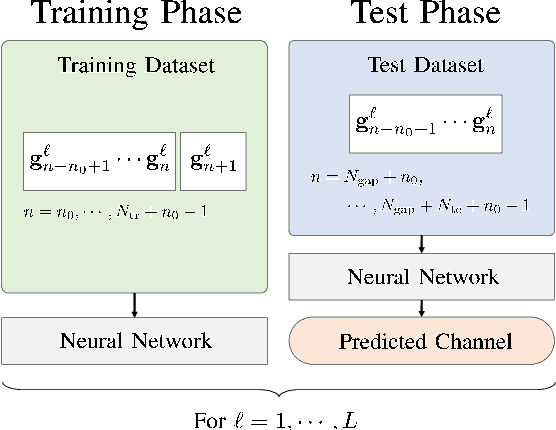
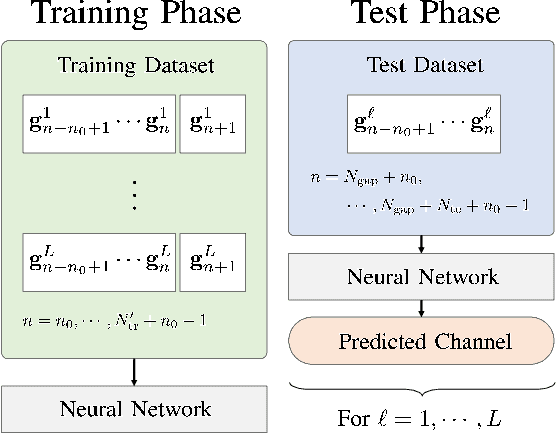
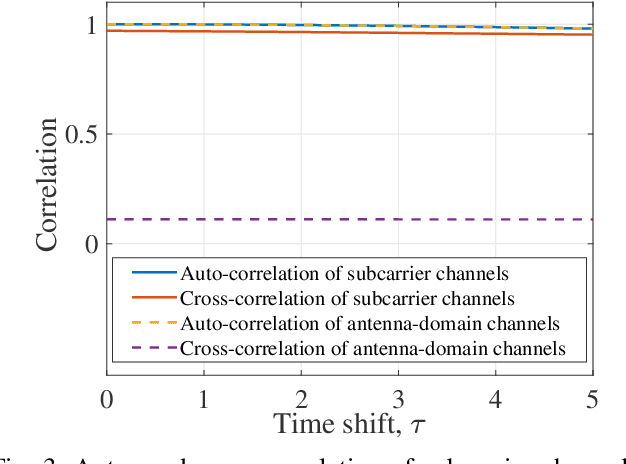
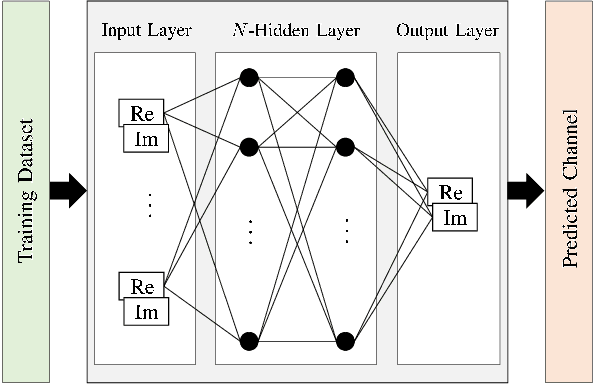
To compensate the loss from outdated channel state information in wideband massive multiple-input multipleoutput (MIMO) systems, channel prediction can be performed by leveraging the temporal correlation of wireless channels. Machine learning (ML)-based channel predictors for massive MIMO systems were designed recently; however, the time overhead to collect a large amount of training data directly affects the latency of the system. In this paper, we propose a novel ML-based channel prediction technique, which can reduce the time overhead to collect the training data by transforming the domain of channels from subcarrier to antenna in wideband massive MIMO systems. Numerical results show that the proposed technique can not only reduce the time overhead but also give additional performance gain compared to the ML-based channel prediction techniques without the domain transformation.
Binary Representation via Jointly Personalized Sparse Hashing
Aug 31, 2022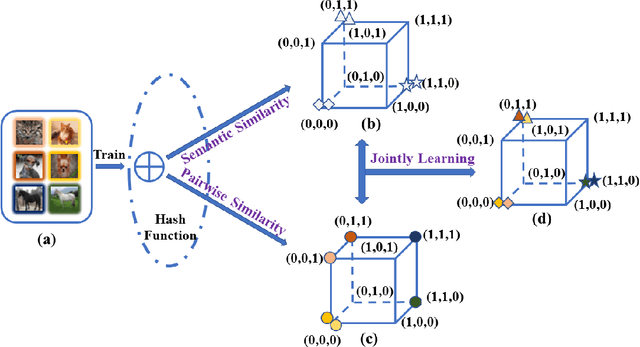
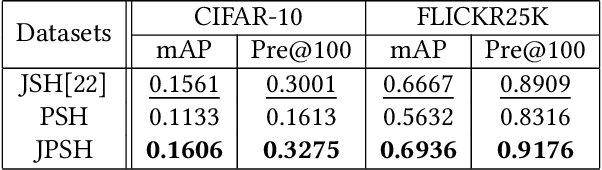
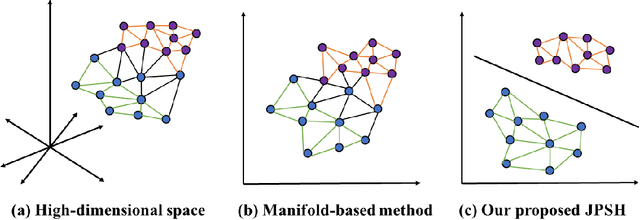
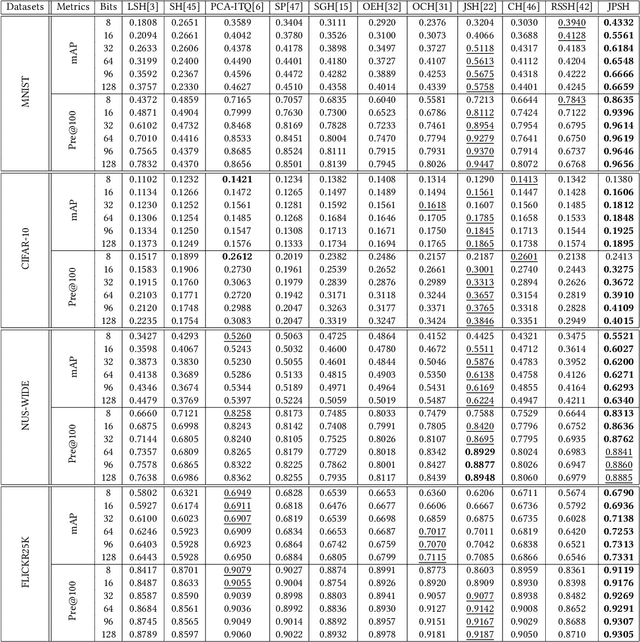
Unsupervised hashing has attracted much attention for binary representation learning due to the requirement of economical storage and efficiency of binary codes. It aims to encode high-dimensional features in the Hamming space with similarity preservation between instances. However, most existing methods learn hash functions in manifold-based approaches. Those methods capture the local geometric structures (i.e., pairwise relationships) of data, and lack satisfactory performance in dealing with real-world scenarios that produce similar features (e.g. color and shape) with different semantic information. To address this challenge, in this work, we propose an effective unsupervised method, namely Jointly Personalized Sparse Hashing (JPSH), for binary representation learning. To be specific, firstly, we propose a novel personalized hashing module, i.e., Personalized Sparse Hashing (PSH). Different personalized subspaces are constructed to reflect category-specific attributes for different clusters, adaptively mapping instances within the same cluster to the same Hamming space. In addition, we deploy sparse constraints for different personalized subspaces to select important features. We also collect the strengths of the other clusters to build the PSH module with avoiding over-fitting. Then, to simultaneously preserve semantic and pairwise similarities in our JPSH, we incorporate the PSH and manifold-based hash learning into the seamless formulation. As such, JPSH not only distinguishes the instances from different clusters, but also preserves local neighborhood structures within the cluster. Finally, an alternating optimization algorithm is adopted to iteratively capture analytical solutions of the JPSH model. Extensive experiments on four benchmark datasets verify that the JPSH outperforms several hashing algorithms on the similarity search task.
Meta-Learning based Degradation Representation for Blind Super-Resolution
Jul 28, 2022


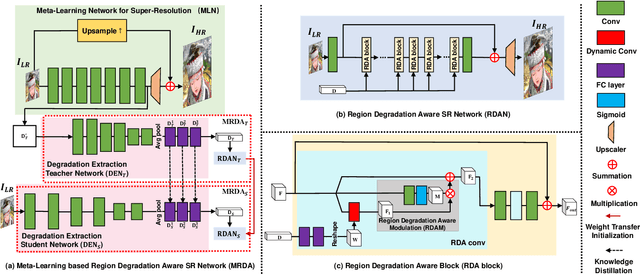
The most of CNN based super-resolution (SR) methods assume that the degradation is known (\eg, bicubic). These methods will suffer a severe performance drop when the degradation is different from their assumption. Therefore, some approaches attempt to train SR networks with the complex combination of multiple degradations to cover the real degradation space. To adapt to multiple unknown degradations, introducing an explicit degradation estimator can actually facilitate SR performance. However, previous explicit degradation estimation methods usually predict Gaussian blur with the supervision of groundtruth blur kernels, and estimation errors may lead to SR failure. Thus, it is necessary to design a method that can extract implicit discriminative degradation representation. To this end, we propose a Meta-Learning based Region Degradation Aware SR Network (MRDA), including Meta-Learning Network (MLN), Degradation Extraction Network (DEN), and Region Degradation Aware SR Network (RDAN). To handle the lack of groundtruth degradation, we use the MLN to rapidly adapt to the specific complex degradation after several iterations and extract implicit degradation information. Subsequently, a teacher network MRDA$_{T}$ is designed to further utilize the degradation information extracted by MLN for SR. However, MLN requires iterating on paired low-resolution (LR) and corresponding high-resolution (HR) images, which is unavailable in the inference phase. Therefore, we adopt knowledge distillation (KD) to make the student network learn to directly extract the same implicit degradation representation (IDR) as the teacher from LR images.
Intelligence as information processing: brains, swarms, and computers
Aug 09, 2021There is no agreed definition of intelligence, so it is problematic to simply ask whether brains, swarms, computers, or other systems are intelligent or not. To compare the potential intelligence exhibited by different cognitive systems, I use the common approach used by artificial intelligence and artificial life: Instead of studying the substrate of systems, let us focus on their organization. This organization can be measured with information. Thus, I apply an informationist epistemology to describe cognitive systems, including brains and computers. This allows me to frame the usefulness and limitations of the brain-computer analogy in different contexts. I also use this perspective to discuss the evolution and ecology of intelligence.
A Hierarchical Interactive Network for Joint Span-based Aspect-Sentiment Analysis
Aug 24, 2022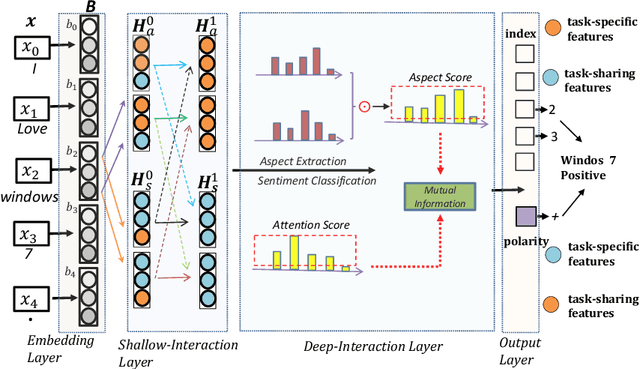
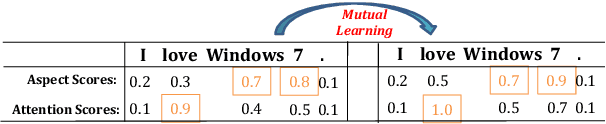
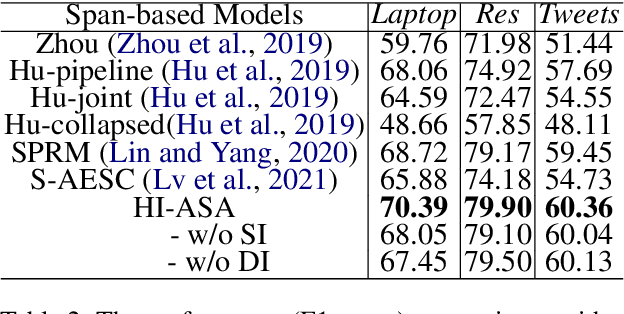
Recently, some span-based methods have achieved encouraging performances for joint aspect-sentiment analysis, which first extract aspects (aspect extraction) by detecting aspect boundaries and then classify the span-level sentiments (sentiment classification). However, most existing approaches either sequentially extract task-specific features, leading to insufficient feature interactions, or they encode aspect features and sentiment features in a parallel manner, implying that feature representation in each task is largely independent of each other except for input sharing. Both of them ignore the internal correlations between the aspect extraction and sentiment classification. To solve this problem, we novelly propose a hierarchical interactive network (HI-ASA) to model two-way interactions between two tasks appropriately, where the hierarchical interactions involve two steps: shallow-level interaction and deep-level interaction. First, we utilize cross-stitch mechanism to combine the different task-specific features selectively as the input to ensure proper two-way interactions. Second, the mutual information technique is applied to mutually constrain learning between two tasks in the output layer, thus the aspect input and the sentiment input are capable of encoding features of the other task via backpropagation. Extensive experiments on three real-world datasets demonstrate HI-ASA's superiority over baselines.
Differential evolution variants for Searching D- and A-optimal designs
Aug 24, 2022
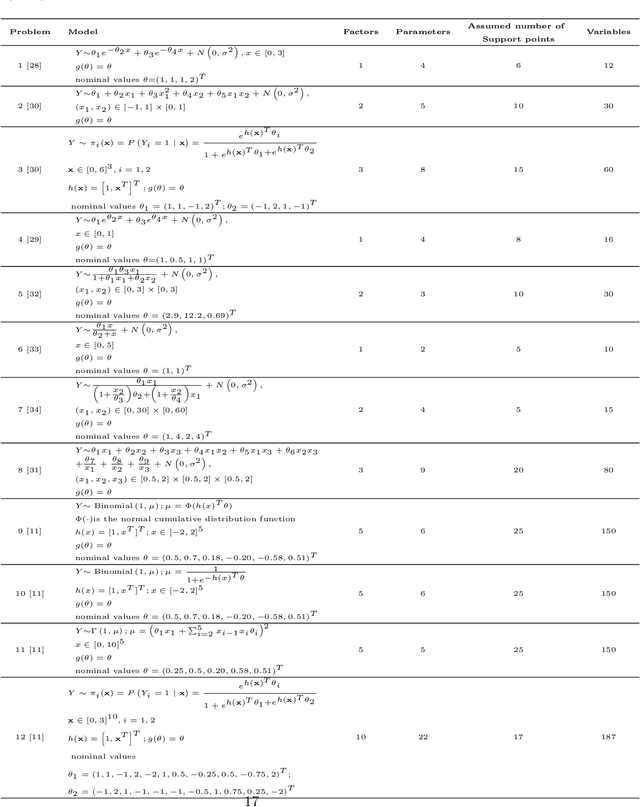
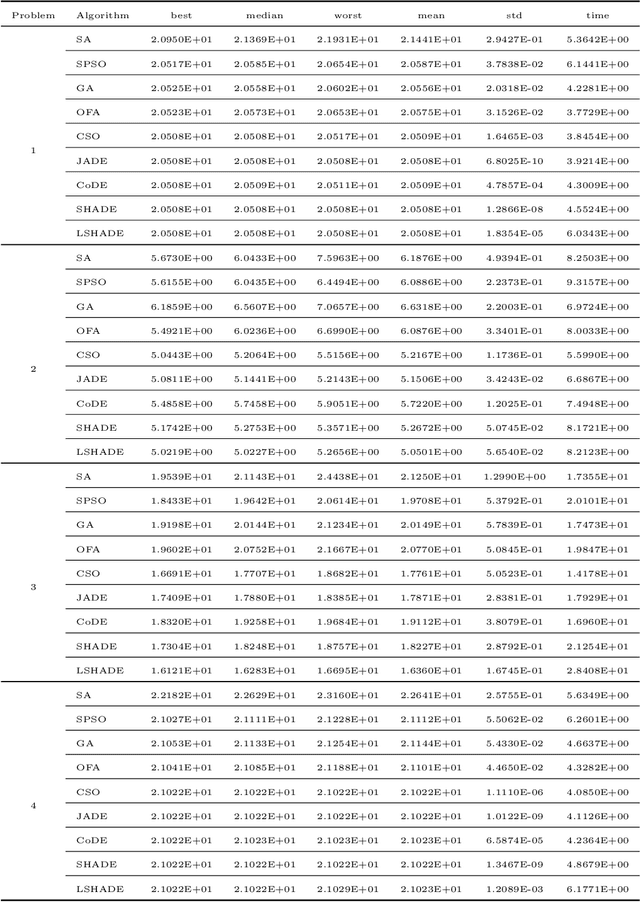
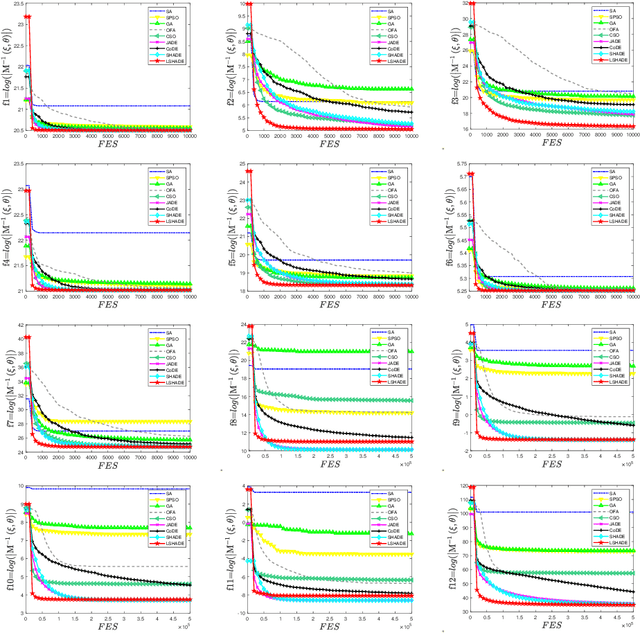
Optimal experimental design is an essential subfield of statistics that maximizes the chances of experimental success. The D- and A-optimal design is a very challenging problem in the field of optimal design, namely minimizing the determinant and trace of the inverse Fisher information matrix. Due to the flexibility and ease of implementation, traditional evolutionary algorithms (EAs) are applied to deal with a small part of experimental optimization design problems without mathematical derivation and assumption. However, the current EAs remain the issues of determining the support point number, handling the infeasible weight solution, and the insufficient experiment. To address the above issues, this paper investigates differential evolution (DE) variants for finding D- and A-optimal designs on several different statistical models. The repair operation is proposed to automatically determine the support point by combining similar support points with their corresponding weights based on Euclidean distance and deleting the support point with less weight. Furthermore, the repair operation fixes the infeasible weight solution into the feasible weight solution. To enrich our optimal design experiments, we utilize the proposed DE variants to test the D- and A-optimal design problems on 12 statistical models. Compared with other competitor algorithms, simulation experiments show that LSHADE can achieve better performance on the D- and A-optimal design problems.
Semantic Interleaving Global Channel Attention for Multilabel Remote Sensing Image Classification
Aug 04, 2022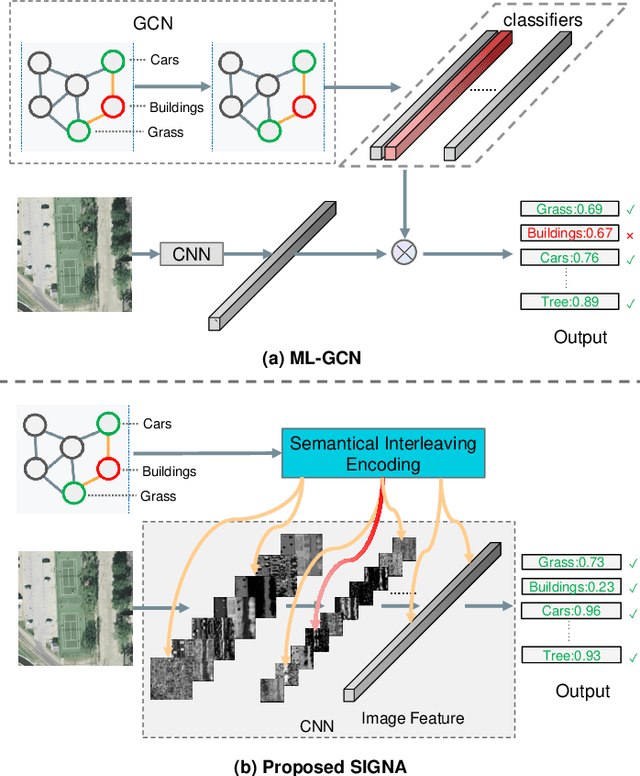
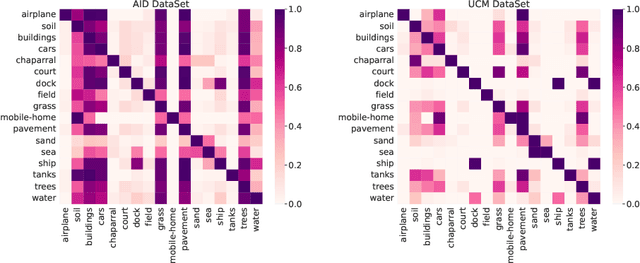
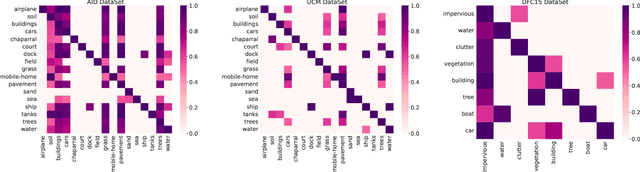
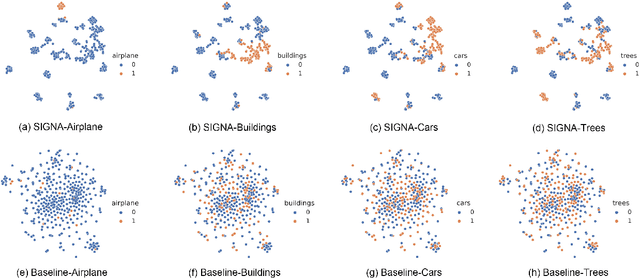
Multi-Label Remote Sensing Image Classification (MLRSIC) has received increasing research interest. Taking the cooccurrence relationship of multiple labels as additional information helps to improve the performance of this task. Current methods focus on using it to constrain the final feature output of a Convolutional Neural Network (CNN). On the one hand, these methods do not make full use of label correlation to form feature representation. On the other hand, they increase the label noise sensitivity of the system, resulting in poor robustness. In this paper, a novel method called Semantic Interleaving Global Channel Attention (SIGNA) is proposed for MLRSIC. First, the label co-occurrence graph is obtained according to the statistical information of the data set. The label co-occurrence graph is used as the input of the Graph Neural Network (GNN) to generate optimal feature representations. Then, the semantic features and visual features are interleaved, to guide the feature expression of the image from the original feature space to the semantic feature space with embedded label relations. SIGNA triggers global attention of feature maps channels in a new semantic feature space to extract more important visual features. Multihead SIGNA based feature adaptive weighting networks are proposed to act on any layer of CNN in a plug-and-play manner. For remote sensing images, better classification performance can be achieved by inserting CNN into the shallow layer. We conduct extensive experimental comparisons on three data sets: UCM data set, AID data set, and DFC15 data set. Experimental results demonstrate that the proposed SIGNA achieves superior classification performance compared to state-of-the-art (SOTA) methods. It is worth mentioning that the codes of this paper will be open to the community for reproducibility research. Our codes are available at https://github.com/kyle-one/SIGNA.
Learning to Rank with Small Set of Ground Truth Data
Jul 04, 2022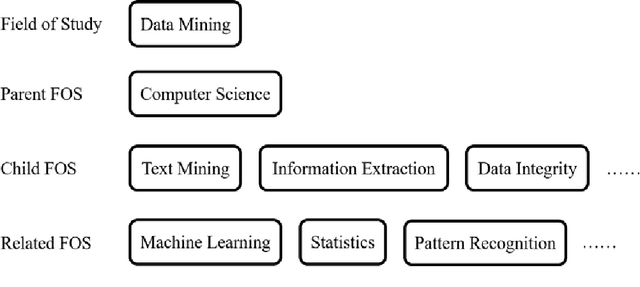


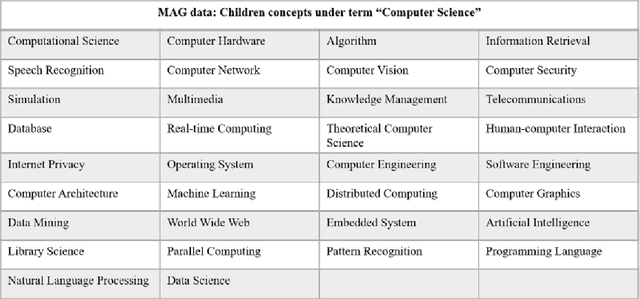
Over the past decades, researchers had put lots of effort investigating ranking techniques used to rank query results retrieved during information retrieval, or to rank the recommended products in recommender systems. In this project, we aim to investigate searching, ranking, as well as recommendation techniques to help to realize a university academia searching platform. Unlike the usual information retrieval scenarios where lots of ground truth ranking data is present, in our case, we have only limited ground truth knowledge regarding the academia ranking. For instance, given some search queries, we only know a few researchers who are highly relevant and thus should be ranked at the top, and for some other search queries, we have no knowledge about which researcher should be ranked at the top at all. The limited amount of ground truth data makes some of the conventional ranking techniques and evaluation metrics become infeasible, and this is a huge challenge we faced during this project. This project enhances the user's academia searching experience to a large extent, it helps to achieve an academic searching platform which includes researchers, publications and fields of study information, which will be beneficial not only to the university faculties but also to students' research experiences.