 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncertainty quantification for predictions of atomistic neural networks
Jul 21, 2022
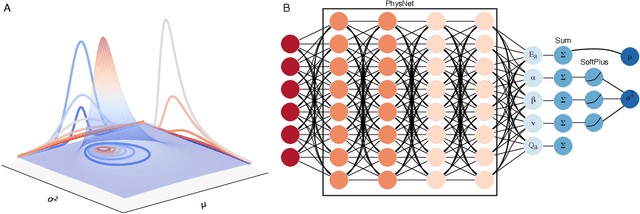
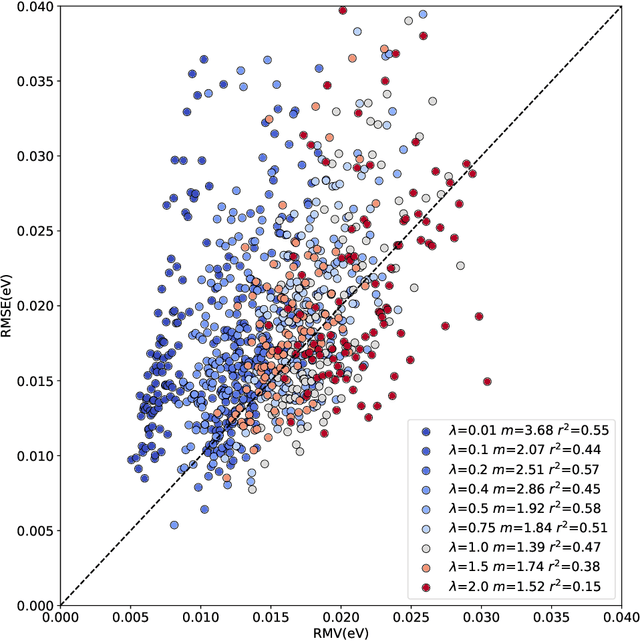
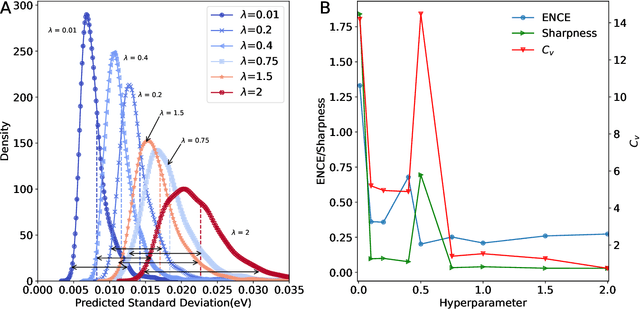
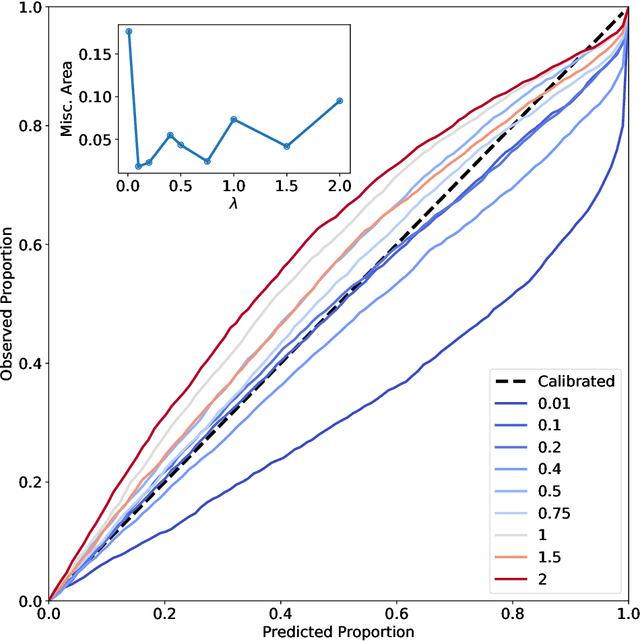
The value of uncertainty quantification on predictions for trained neural networks (NNs) on quantum chemical reference data is quantitatively explored. For this, the architecture of the PhysNet NN was suitably modified and the resulting model was evaluated with different metrics to quantify calibration, quality of predictions, and whether prediction error and the predicted uncertainty can be correlated. The results from training on the QM9 database and evaluating data from the test set within and outside the distribution indicate that error and uncertainty are not linearly related. The results clarify that noise and redundancy complicate property prediction for molecules even in cases for which changes - e.g. double bond migration in two otherwise identical molecules - are small. The model was then applied to a real database of tautomerization reactions. Analysis of the distance between members in feature space combined with other parameters shows that redundant information in the training dataset can lead to large variances and small errors whereas the presence of similar but unspecific information returns large errors but small variances. This was, e.g., observed for nitro-containing aliphatic chains for which predictions were difficult although the training set contained several examples for nitro groups bound to aromatic molecules. This underlines the importance of the composition of the training data and provides chemical insight into how this affects the prediction capabilities of a ML model. Finally, the approach put forward can be used for information-based improvement of chemical databases for target applications through active learning optimization.
PSAQ-ViT V2: Towards Accurate and General Data-Free Quantization for Vision Transformers
Sep 13, 2022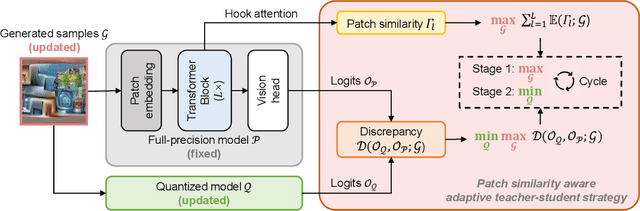
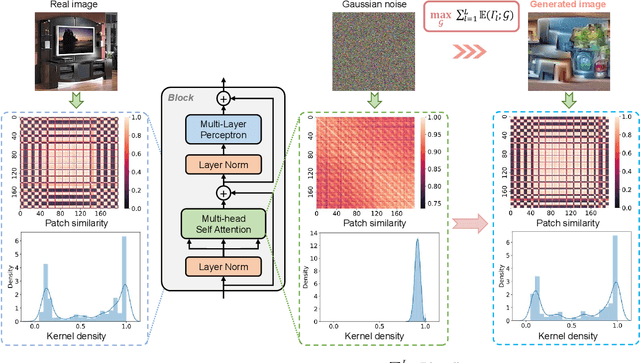

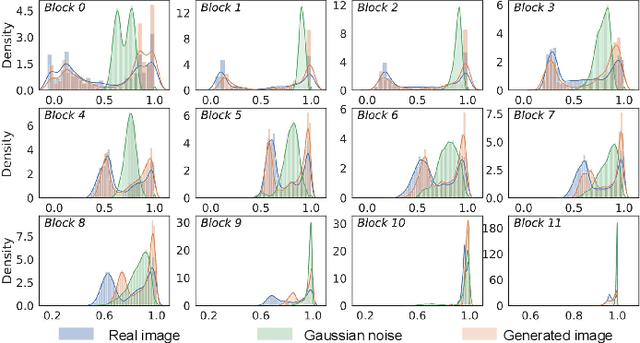
Data-free quantization can potentially address data privacy and security concerns in model compression, and thus has been widely investigated. Recently, PSAQ-ViT designs a relative value metric, patch similarity, to generate data from pre-trained vision transformers (ViTs), achieving the first attempt at data-free quantization for ViTs. In this paper, we propose PSAQ-ViT V2, a more accurate and general data-free quantization framework for ViTs, built on top of PSAQ-ViT. More specifically, following the patch similarity metric in PSAQ-ViT, we introduce an adaptive teacher-student strategy, which facilitates the constant cyclic evolution of the generated samples and the quantized model (student) in a competitive and interactive fashion under the supervision of the full-precision model (teacher), thus significantly improving the accuracy of the quantized model. Moreover, without the auxiliary category guidance, we employ the task- and model-independent prior information, making the general-purpose scheme compatible with a broad range of vision tasks and models. Extensive experiments are conducted on various models on image classification, object detection, and semantic segmentation tasks, and PSAQ-ViT V2, with the naive quantization strategy and without access to real-world data, consistently achieves competitive results, showing potential as a powerful baseline on data-free quantization for ViTs. For instance, with Swin-S as the (backbone) model, 8-bit quantization reaches 82.13 top-1 accuracy on ImageNet, 50.9 box AP and 44.1 mask AP on COCO, and 47.2 mIoU on ADE20K. We hope that accurate and general PSAQ-ViT V2 can serve as a potential and practice solution in real-world applications involving sensitive data. Code will be released and merged at: https://github.com/zkkli/PSAQ-ViT.
SIND: A Drone Dataset at Signalized Intersection in China
Sep 06, 2022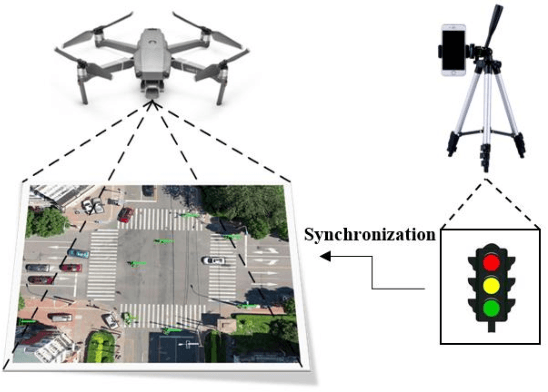

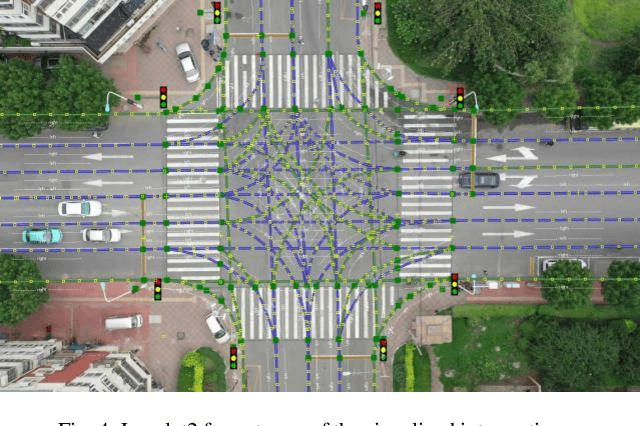
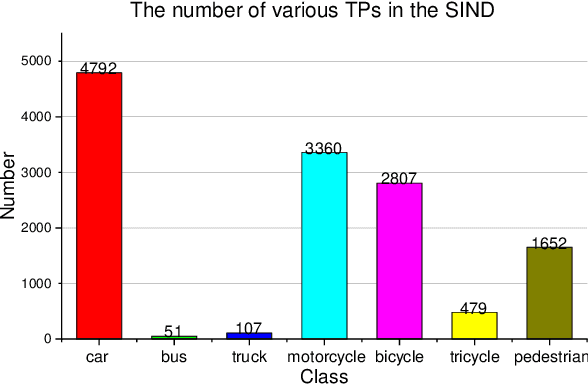
Intersection is one of the most challenging scenarios for autonomous driving tasks. Due to the complexity and stochasticity, essential applications (e.g., behavior modeling, motion prediction, safety validation, etc.) at intersections rely heavily on data-driven techniques. Thus, there is an intense demand for trajectory datasets of traffic participants (TPs) in intersections. Currently, most intersections in urban areas are equipped with traffic lights. However, there is not yet a large-scale, high-quality, publicly available trajectory dataset for signalized intersections. Therefore, in this paper, a typical two-phase signalized intersection is selected in Tianjin, China. Besides, a pipeline is designed to construct a Signalized INtersection Dataset (SIND), which contains 7 hours of recording including over 13,000 TPs with 7 types. Then, the behaviors of traffic light violations in SIND are recorded. Furthermore, the SIND is also compared with other similar works. The features of the SIND can be summarized as follows: 1) SIND provides more comprehensive information, including traffic light states, motion parameters, High Definition (HD) map, etc. 2) The category of TPs is diverse and characteristic, where the proportion of vulnerable road users (VRUs) is up to 62.6% 3) Multiple traffic light violations of non-motor vehicles are shown. We believe that SIND would be an effective supplement to existing datasets and can promote related research on autonomous driving.The dataset is available online via: https://github.com/SOTIF-AVLab/SinD
Joint optimal beamforming and power control in cell-free massive MIMO
Aug 11, 2022
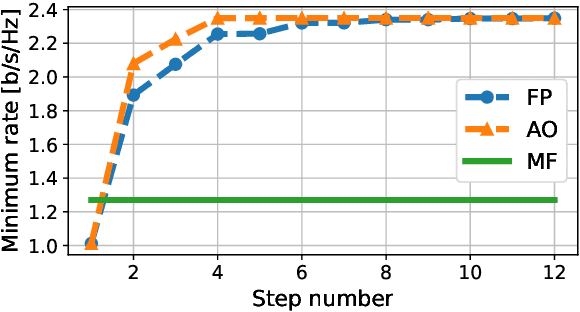
We derive a fast and optimal algorithm for solving practical weighted max-min SINR problems in cell-free massive MIMO networks. For the first time, the optimization problem jointly covers long-term power control and distributed beamforming design under imperfect cooperation. In particular, we consider user-centric clusters of access points cooperating on the basis of possibly limited channel state information sharing. Our optimal algorithm merges powerful power control tools based on interference calculus with the recently developed team theoretic framework for distributed beamforming design. In addition, we propose a variation that shows faster convergence in practice.
Active Learning for Optimal Intervention Design in Causal Models
Sep 10, 2022
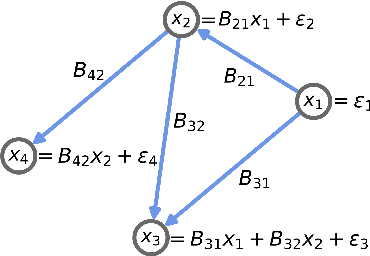
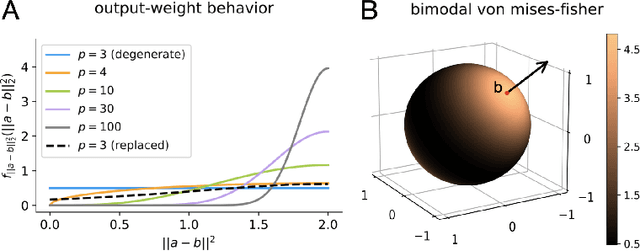
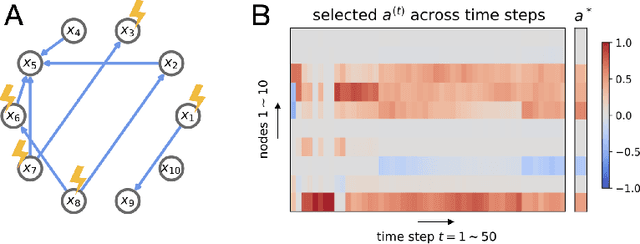
An important problem across disciplines is the discovery of interventions that produce a desired outcome. When the space of possible interventions is large, making an exhaustive search infeasible, experimental design strategies are needed. In this context, encoding the causal relationships between the variables, and thus the effect of interventions on the system, is critical in order to identify desirable interventions efficiently. We develop an iterative causal method to identify optimal interventions, as measured by the discrepancy between the post-interventional mean of the distribution and a desired target mean. We formulate an active learning strategy that uses the samples obtained so far from different interventions to update the belief about the underlying causal model, as well as to identify samples that are most informative about optimal interventions and thus should be acquired in the next batch. The approach employs a Bayesian update for the causal model and prioritizes interventions using a carefully designed, causally informed acquisition function. This acquisition function is evaluated in closed form, allowing for efficient optimization. The resulting algorithms are theoretically grounded with information-theoretic bounds and provable consistency results. We illustrate the method on both synthetic data and real-world biological data, namely gene expression data from Perturb-CITE-seq experiments, to identify optimal perturbations that induce a specific cell state transition; the proposed causal approach is observed to achieve better sample efficiency compared to several baselines. In both cases we observe that the causally informed acquisition function notably outperforms existing criteria allowing for optimal intervention design with significantly less experiments.
Algorithmic Differentiation for Automatized Modelling of Machine Learned Force Fields
Aug 25, 2022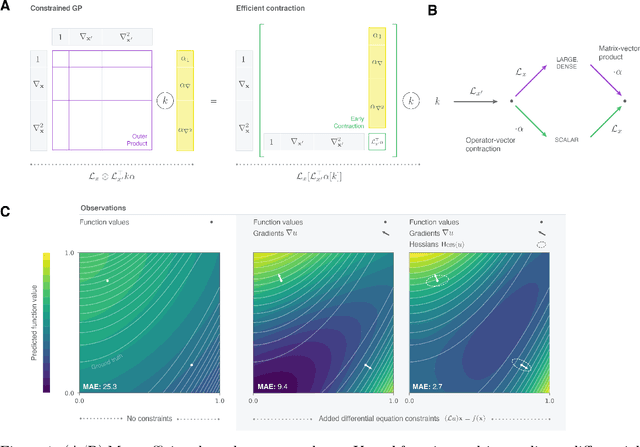


Reconstructing force fields (FF) from atomistic simulation data is a challenge since accurate data can be highly expensive. Here, machine learning (ML) models can help to be data economic as they can be successfully constrained using the underlying symmetry and conservation laws of physics. However, so far, every descriptor newly proposed for an ML model has required a cumbersome and mathematically tedious remodeling. We therefore propose to use modern techniques from algorithmic differentiation within the ML modeling process -- effectively enabling the usage of novel descriptors or models fully automatically at an order of magnitude higher computational efficiency. This paradigmatic approach enables not only a versatile usage of novel representations, the efficient computation of larger systems -- all of high value to the FF community -- but also the simple inclusion of further physical knowledge such as higher-order information (e.g.~Hessians, more complex partial differential equations constraints etc.), even beyond the presented FF domain.
Boosting Video-Text Retrieval with Explicit High-Level Semantics
Aug 08, 2022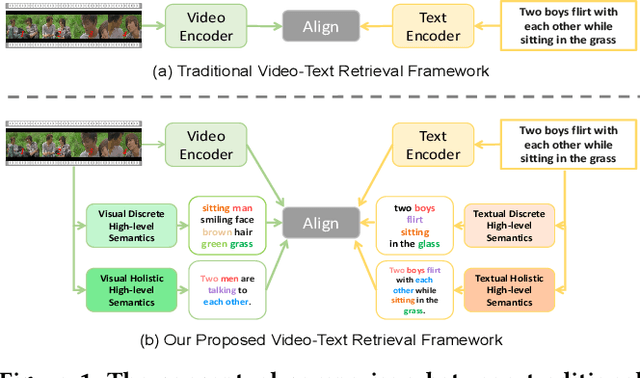
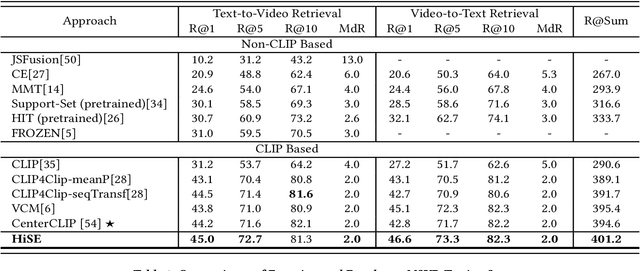
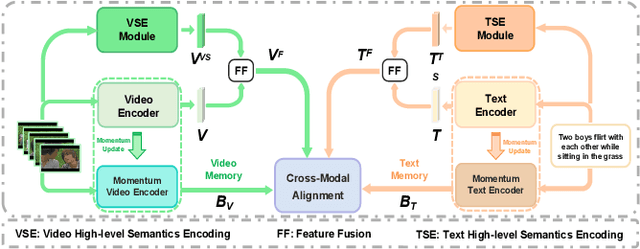
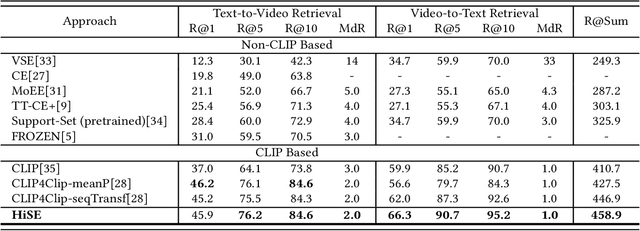
Video-text retrieval (VTR) is an attractive yet challenging task for multi-modal understanding, which aims to search for relevant video (text) given a query (video). Existing methods typically employ completely heterogeneous visual-textual information to align video and text, whilst lacking the awareness of homogeneous high-level semantic information residing in both modalities. To fill this gap, in this work, we propose a novel visual-linguistic aligning model named HiSE for VTR, which improves the cross-modal representation by incorporating explicit high-level semantics. First, we explore the hierarchical property of explicit high-level semantics, and further decompose it into two levels, i.e. discrete semantics and holistic semantics. Specifically, for visual branch, we exploit an off-the-shelf semantic entity predictor to generate discrete high-level semantics. In parallel, a trained video captioning model is employed to output holistic high-level semantics. As for the textual modality, we parse the text into three parts including occurrence, action and entity. In particular, the occurrence corresponds to the holistic high-level semantics, meanwhile both action and entity represent the discrete ones. Then, different graph reasoning techniques are utilized to promote the interaction between holistic and discrete high-level semantics. Extensive experiments demonstrate that, with the aid of explicit high-level semantics, our method achieves the superior performance over state-of-the-art methods on three benchmark datasets, including MSR-VTT, MSVD and DiDeMo.
Joint Optimization for Secure and Reliable Communications in Finite Blocklength Regime
Aug 03, 2022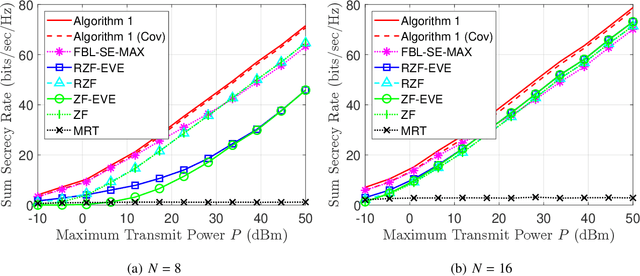
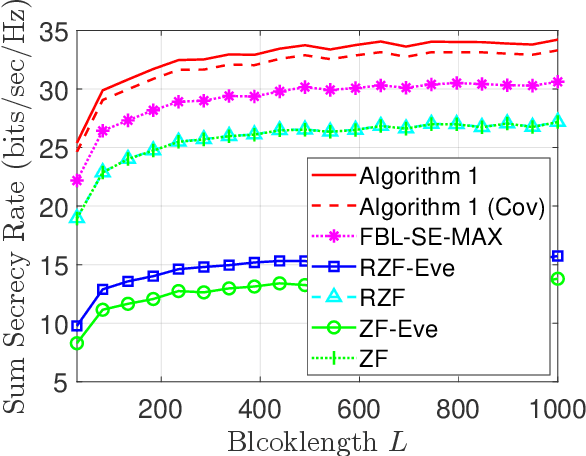
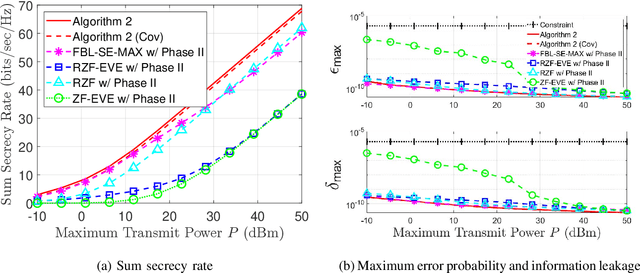
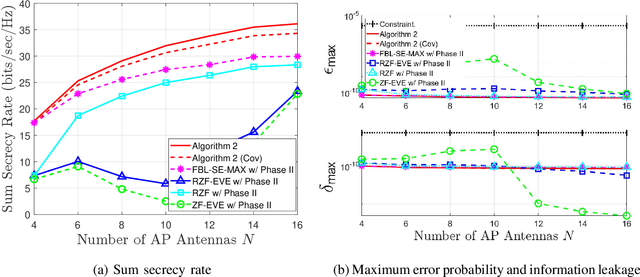
To realize ultra-reliable low latency communications with high spectral efficiency and security, we investigate a joint optimization problem for downlink communications with multiple users and eavesdroppers in the finite blocklength (FBL) regime. We formulate a multi-objective optimization problem to maximize a sum secrecy rate by developing a secure precoder and to minimize a maximum error probability and information leakage rate. The main challenges arise from the complicated multi-objective problem, non-tractable back-off factors from the FBL assumption, non-convexity and non-smoothness of the secrecy rate, and the intertwined optimization variables. To address these challenges, we adopt an alternating optimization approach by decomposing the problem into two phases: secure precoding design, and maximum error probability and information leakage rate minimization. In the first phase, we obtain a lower bound of the secrecy rate and derive a first-order Karush-Kuhn-Tucker (KKT) condition to identify local optimal solutions with respect to the precoders. Interpreting the condition as a generalized eigenvalue problem, we solve the problem by using a power iteration-based method. In the second phase, we adopt a weighted-sum approach and derive KKT conditions in terms of the error probabilities and leakage rates for given precoders. Simulations validate the proposed algorithm.
Single Morphing Attack Detection using Feature Selection and Visualisation based on Mutual Information
Oct 26, 2021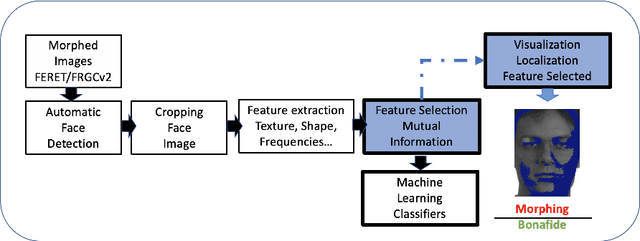
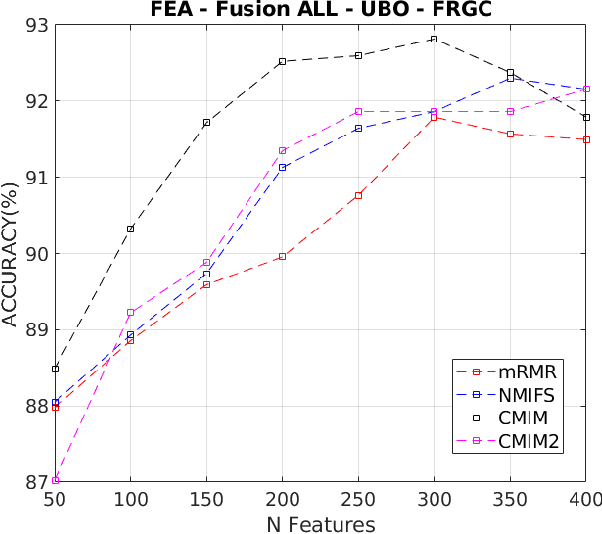
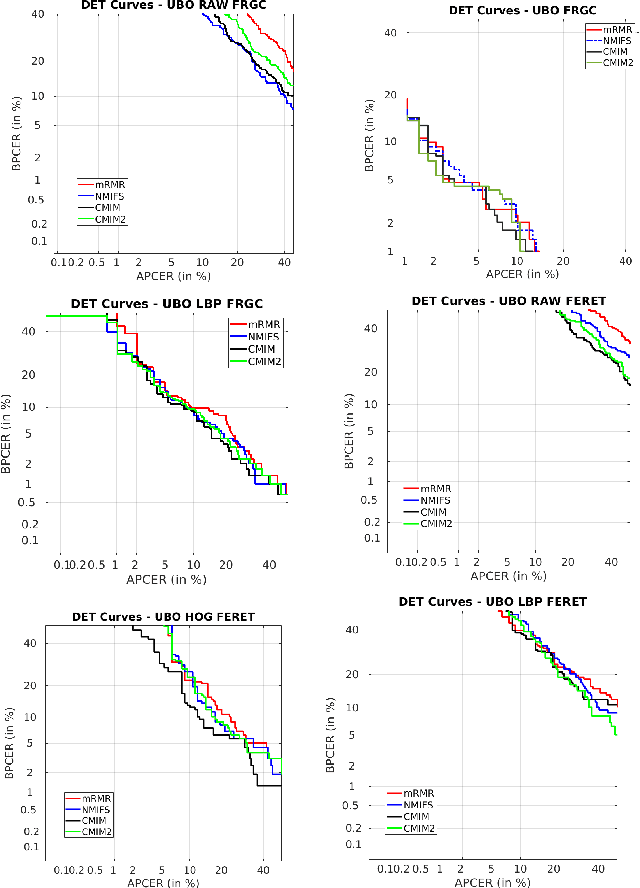
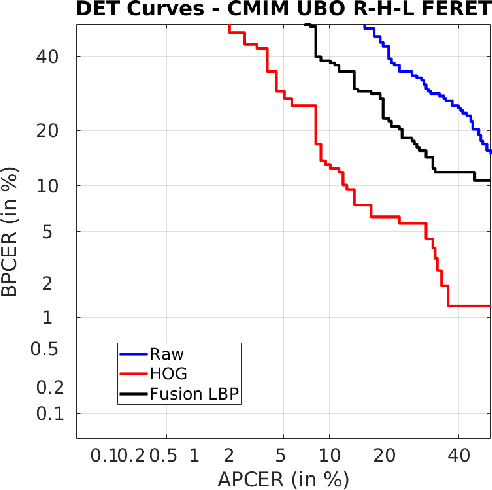
Face morphing attack detection is a challenging task. Automatic classification methods and manual inspection are realised in automatic border control gates to detect morphing attacks. Understanding how a machine learning system can detect morphed faces and the most relevant facial areas is crucial. Those relevant areas contain texture signals that allow us to separate the bona fide and the morph images. Also, it helps in the manual examination to detect a passport generated with morphed images. This paper explores features extracted from intensity, shape, texture, and proposes a feature selection stage based on the Mutual Information filter to select the most relevant and less redundant features. This selection allows us to reduce the workload and know the exact localisation of such areas to understand the morphing impact and create a robust classifier. The best results were obtained for the method based on Conditional Mutual Information and Shape features using only 500 features for FERET images and 800 features for FRGCv2 images from 1,048 features available. The eyes and nose are identified as the most critical areas to be analysed.
Towards Semantic Communications: Deep Learning-Based Image Semantic Coding
Aug 08, 2022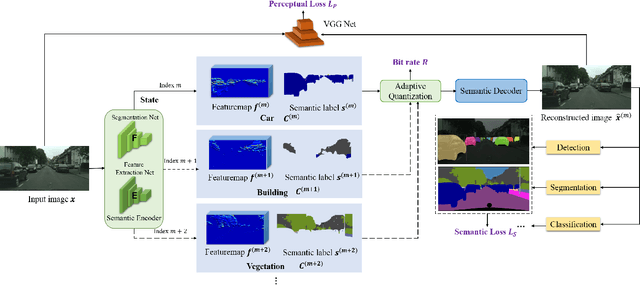

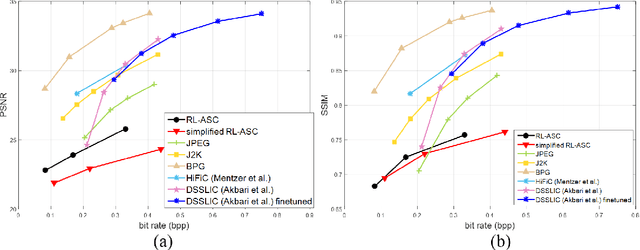
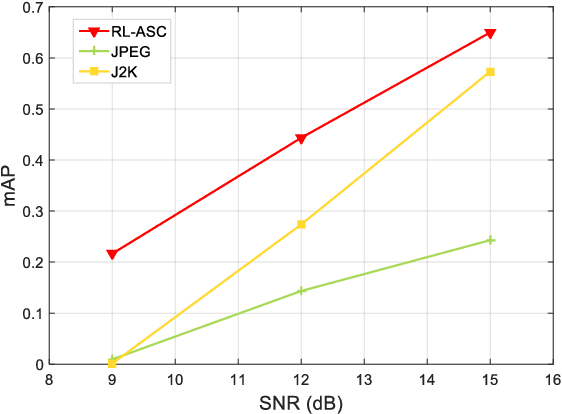
Semantic communications has received growing interest since it can remarkably reduce the amount of data to be transmitted without missing critical information. Most existing works explore the semantic encoding and transmission for text and apply techniques in Natural Language Processing (NLP) to interpret the meaning of the text. In this paper, we conceive the semantic communications for image data that is much more richer in semantics and bandwidth sensitive. We propose an reinforcement learning based adaptive semantic coding (RL-ASC) approach that encodes images beyond pixel level. Firstly, we define the semantic concept of image data that includes the category, spatial arrangement, and visual feature as the representation unit, and propose a convolutional semantic encoder to extract semantic concepts. Secondly, we propose the image reconstruction criterion that evolves from the traditional pixel similarity to semantic similarity and perceptual performance. Thirdly, we design a novel RL-based semantic bit allocation model, whose reward is the increase in rate-semantic-perceptual performance after encoding a certain semantic concept with adaptive quantization level. Thus, the task-related information is preserved and reconstructed properly while less important data is discarded. Finally, we propose the Generative Adversarial Nets (GANs) based semantic decoder that fuses both locally and globally features via an attention module. Experimental results demonstrate that the proposed RL-ASC is noise robust and could reconstruct visually pleasant and semantic consistent image, and saves times of bit cost compared to standard codecs and other deep learning-based image codecs.