 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Few-shot Adaptive Object Detection with Cross-Domain CutMix
Aug 31, 2022
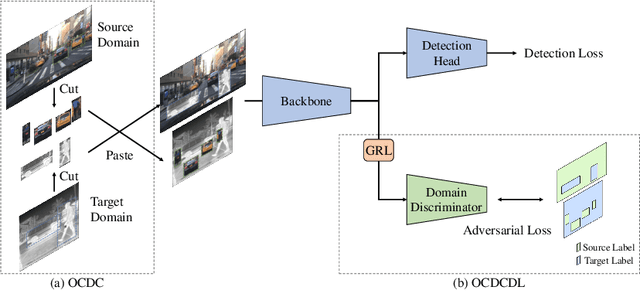
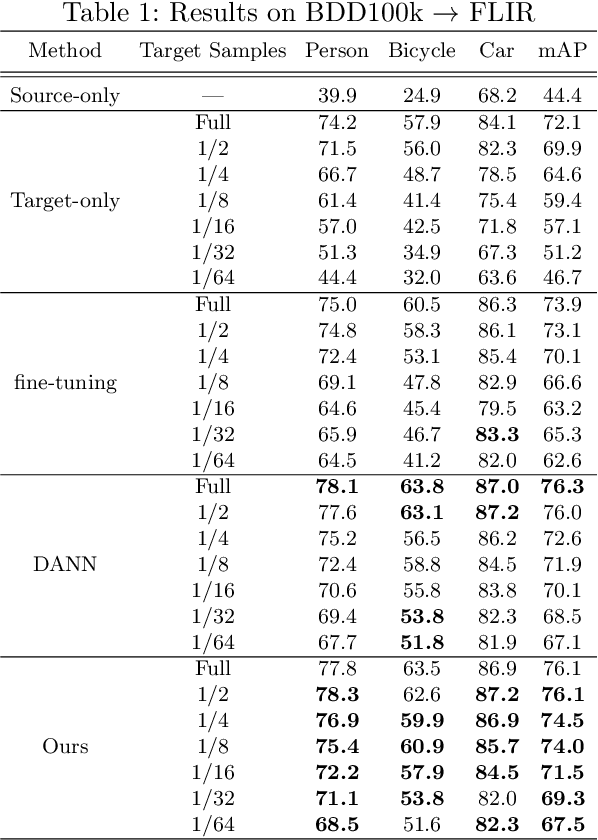
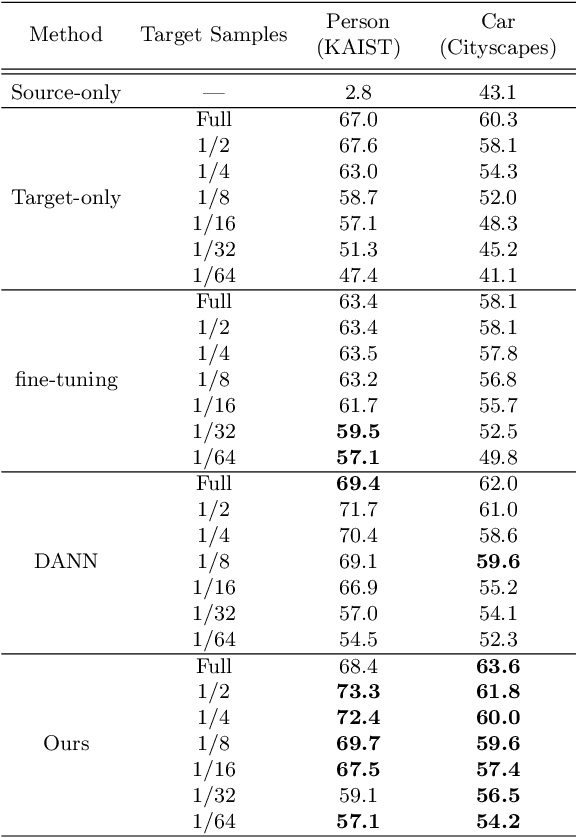
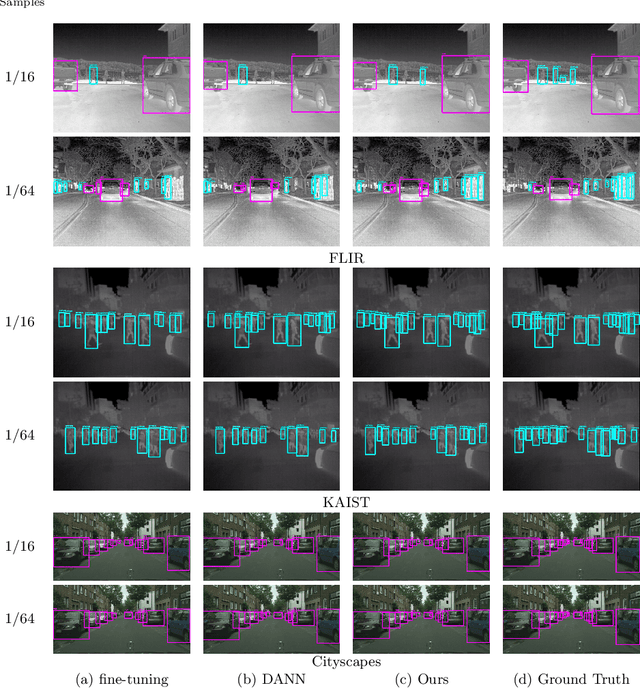
In object detection, data amount and cost are a trade-off, and collecting a large amount of data in a specific domain is labor intensive. Therefore, existing large-scale datasets are used for pre-training. However, conventional transfer learning and domain adaptation cannot bridge the domain gap when the target domain differs significantly from the source domain. We propose a data synthesis method that can solve the large domain gap problem. In this method, a part of the target image is pasted onto the source image, and the position of the pasted region is aligned by utilizing the information of the object bounding box. In addition, we introduce adversarial learning to discriminate whether the original or the pasted regions. The proposed method trains on a large number of source images and a few target domain images. The proposed method achieves higher accuracy than conventional methods in a very different domain problem setting, where RGB images are the source domain, and thermal infrared images are the target domain. Similarly, the proposed method achieves higher accuracy in the cases of simulation images to real images.
May the force be with you
Aug 13, 2022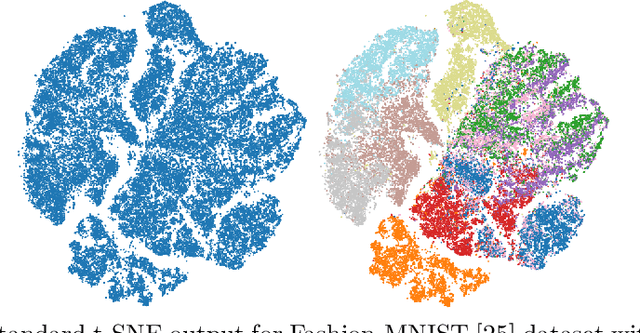
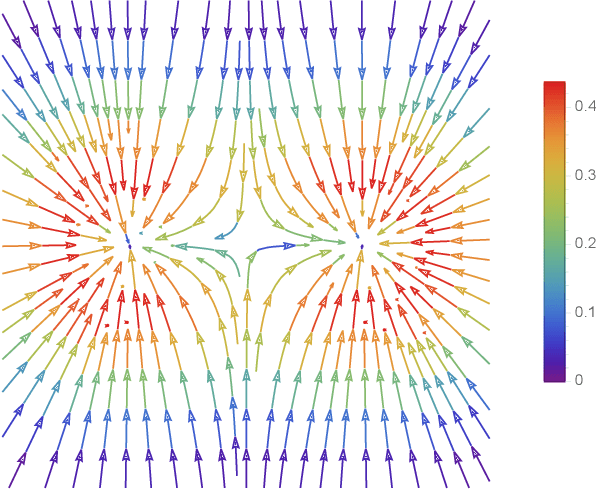
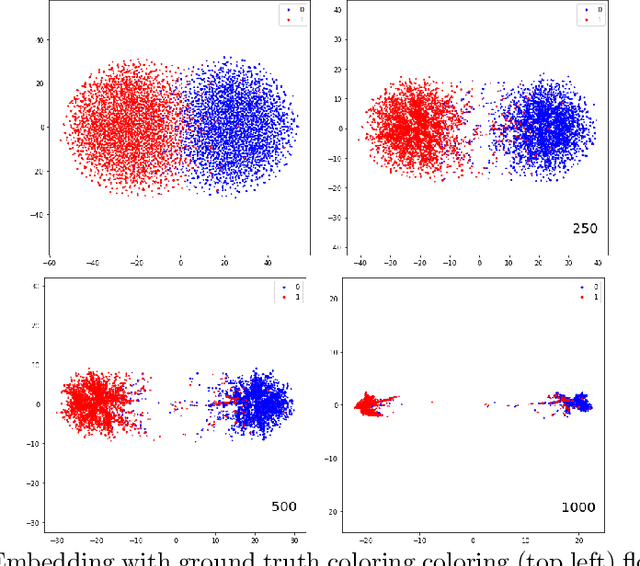
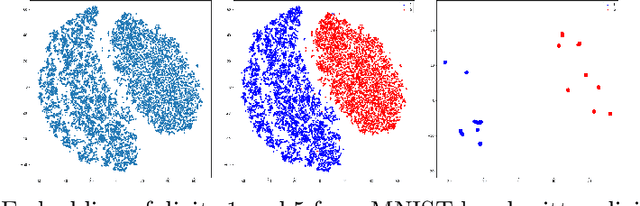
Modern methods in dimensionality reduction are dominated by nonlinear attraction-repulsion force-based methods (this includes t-SNE, UMAP, ForceAtlas2, LargeVis, and many more). The purpose of this paper is to demonstrate that all such methods, by design, come with an additional feature that is being automatically computed along the way, namely the vector field associated with these forces. We show how this vector field gives additional high-quality information and propose a general refinement strategy based on ideas from Morse theory. The efficiency of these ideas is illustrated specifically using t-SNE on synthetic and real-life data sets.
Taxonomy and evolution predicting using deep learning in images
Jun 28, 2022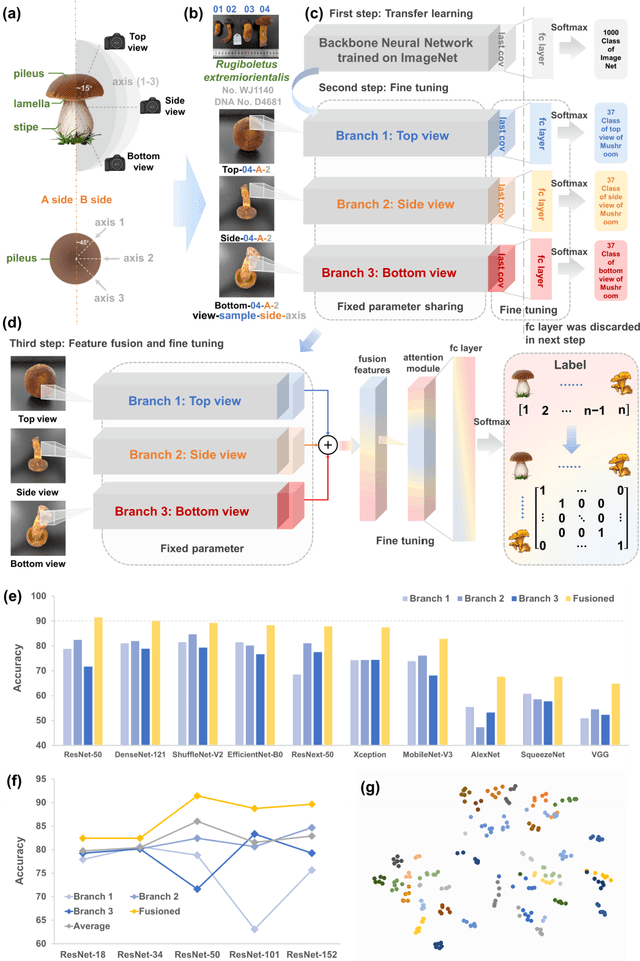
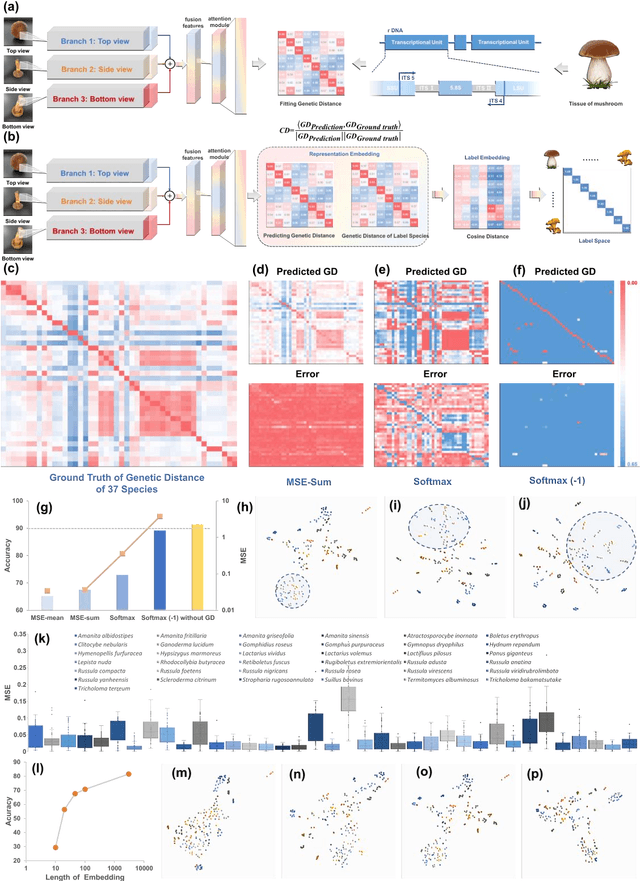
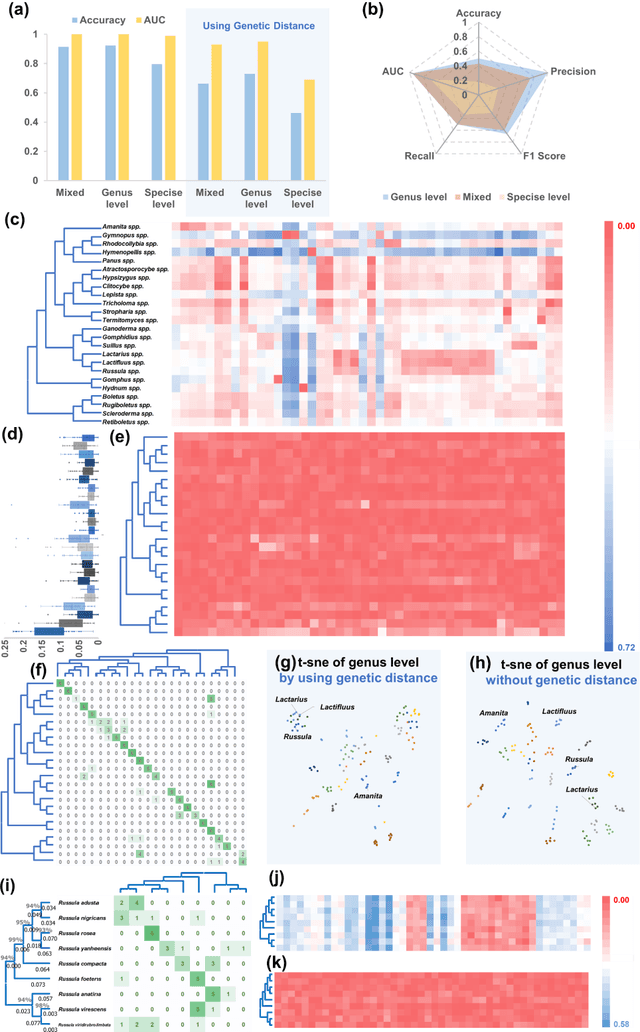
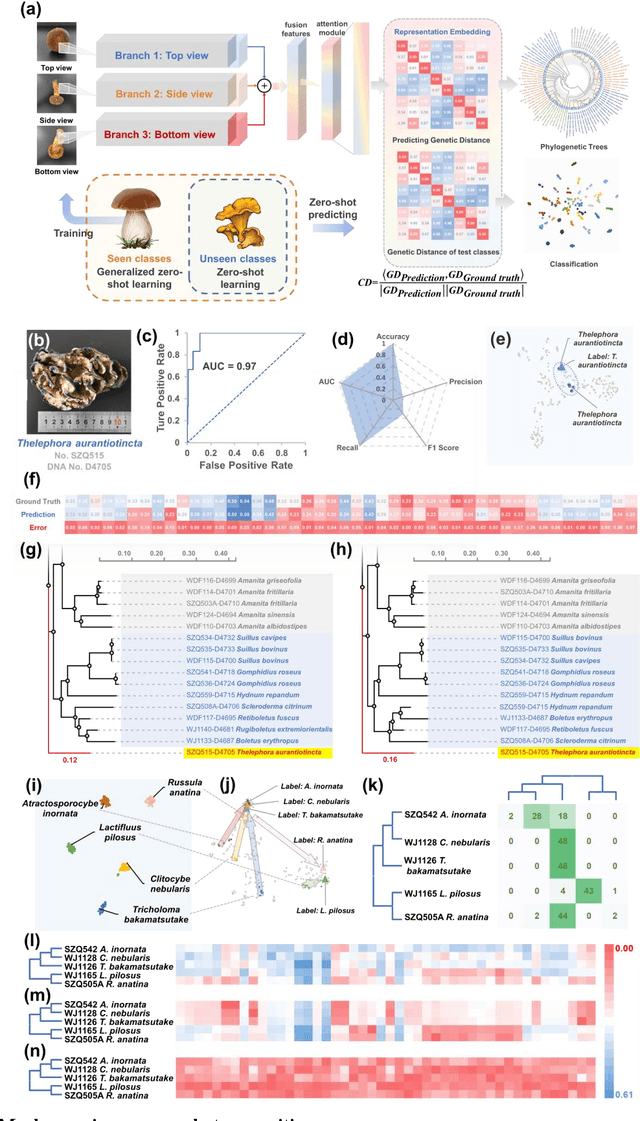
Molecular and morphological characters, as important parts of biological taxonomy, are contradictory but need to be integrated. Organism's image recognition and bioinformatics are emerging and hot problems nowadays but with a gap between them. In this work, a multi-branching recognition framework mediated by genetic information bridges this barrier, which establishes the link between macro-morphology and micro-molecular information of mushrooms. The novel multi-perspective structure is proposed to fuse the feature images from three branching models, which significantly improves the accuracy of recognition by about 10% and up to more than 90%. Further, genetic information is implemented to the mushroom image recognition task by using genetic distance embeddings as the representation space for predicting image distance and species identification. Semantic overfitting of traditional classification tasks and the granularity of fine-grained image recognition are also discussed in depth for the first time. The generalizability of the model was investigated in fine-grained scenarios using zero-shot learning tasks, which could predict the taxonomic and evolutionary information of unseen samples. We presented the first method to map images to DNA, namely used an encoder mapping image to genetic distances, and then decoded DNA through a pre-trained decoder, where the total test accuracy on 37 species for DNA prediction is 87.45%. This study creates a novel recognition framework by systematically studying the mushroom image recognition problem, bridging the gap between macroscopic biological information and microscopic molecular information, which will provide a new reference for intelligent biometrics in the future.
Boosting Video Super Resolution with Patch-Based Temporal Redundancy Optimization
Jul 18, 2022

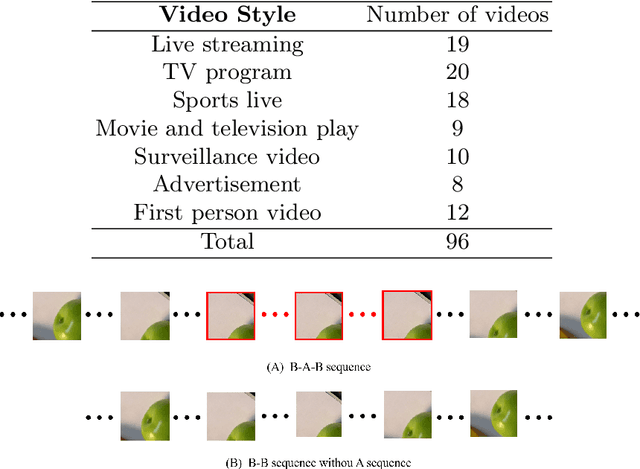

The success of existing video super-resolution (VSR) algorithms stems mainly exploiting the temporal information from the neighboring frames. However, none of these methods have discussed the influence of the temporal redundancy in the patches with stationary objects and background and usually use all the information in the adjacent frames without any discrimination. In this paper, we observe that the temporal redundancy will bring adverse effect to the information propagation,which limits the performance of the most existing VSR methods. Motivated by this observation, we aim to improve existing VSR algorithms by handling the temporal redundancy patches in an optimized manner. We develop two simple yet effective plug and play methods to improve the performance of existing local and non-local propagation-based VSR algorithms on widely-used public videos. For more comprehensive evaluating the robustness and performance of existing VSR algorithms, we also collect a new dataset which contains a variety of public videos as testing set. Extensive evaluations show that the proposed methods can significantly improve the performance of existing VSR methods on the collected videos from wild scenarios while maintain their performance on existing commonly used datasets. The code is available at https://github.com/HYHsimon/Boosted-VSR.
Action-based Contrastive Learning for Trajectory Prediction
Jul 18, 2022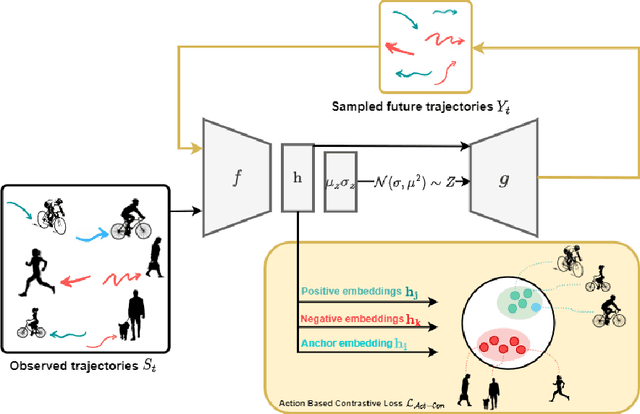
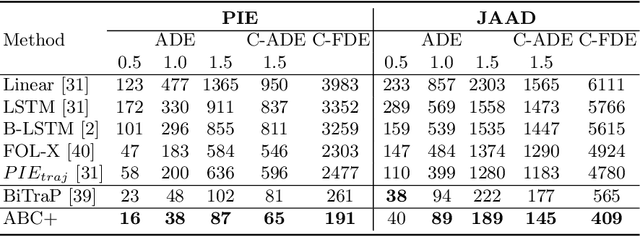

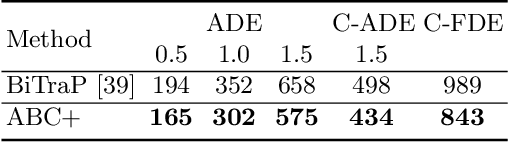
Trajectory prediction is an essential task for successful human robot interaction, such as in autonomous driving. In this work, we address the problem of predicting future pedestrian trajectories in a first person view setting with a moving camera. To that end, we propose a novel action-based contrastive learning loss, that utilizes pedestrian action information to improve the learned trajectory embeddings. The fundamental idea behind this new loss is that trajectories of pedestrians performing the same action should be closer to each other in the feature space than the trajectories of pedestrians with significantly different actions. In other words, we argue that behavioral information about pedestrian action influences their future trajectory. Furthermore, we introduce a novel sampling strategy for trajectories that is able to effectively increase negative and positive contrastive samples. Additional synthetic trajectory samples are generated using a trained Conditional Variational Autoencoder (CVAE), which is at the core of several models developed for trajectory prediction. Results show that our proposed contrastive framework employs contextual information about pedestrian behavior, i.e. action, effectively, and it learns a better trajectory representation. Thus, integrating the proposed contrastive framework within a trajectory prediction model improves its results and outperforms state-of-the-art methods on three trajectory prediction benchmarks [31, 32, 26].
RX-ADS: Interpretable Anomaly Detection using Adversarial ML for Electric Vehicle CAN data
Sep 05, 2022
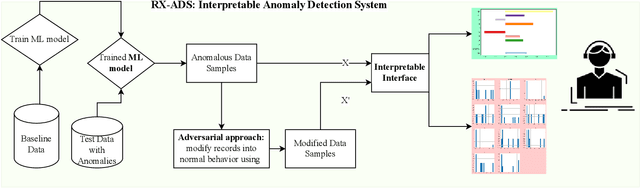
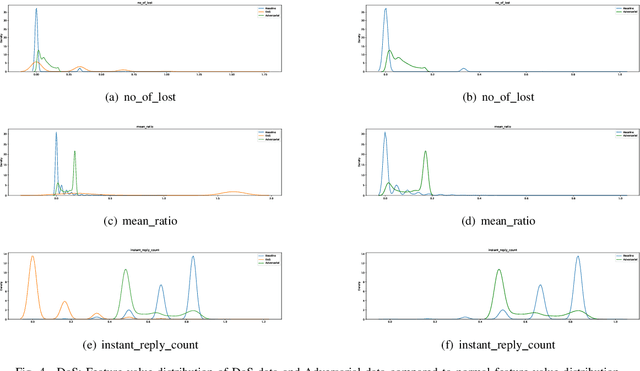
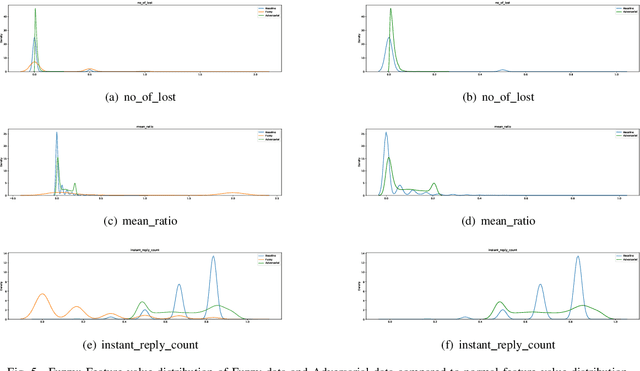
Recent year has brought considerable advancements in Electric Vehicles (EVs) and associated infrastructures/communications. Intrusion Detection Systems (IDS) are widely deployed for anomaly detection in such critical infrastructures. This paper presents an Interpretable Anomaly Detection System (RX-ADS) for intrusion detection in CAN protocol communication in EVs. Contributions include: 1) window based feature extraction method; 2) deep Autoencoder based anomaly detection method; and 3) adversarial machine learning based explanation generation methodology. The presented approach was tested on two benchmark CAN datasets: OTIDS and Car Hacking. The anomaly detection performance of RX-ADS was compared against the state-of-the-art approaches on these datasets: HIDS and GIDS. The RX-ADS approach presented performance comparable to the HIDS approach (OTIDS dataset) and has outperformed HIDS and GIDS approaches (Car Hacking dataset). Further, the proposed approach was able to generate explanations for detected abnormal behaviors arising from various intrusions. These explanations were later validated by information used by domain experts to detect anomalies. Other advantages of RX-ADS include: 1) the method can be trained on unlabeled data; 2) explanations help experts in understanding anomalies and root course analysis, and also help with AI model debugging and diagnostics, ultimately improving user trust in AI systems.
HOME: High-Order Mixed-Moment-based Embedding for Representation Learning
Jul 15, 2022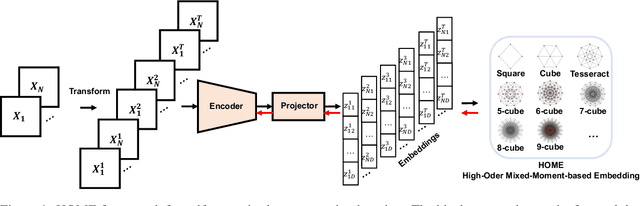
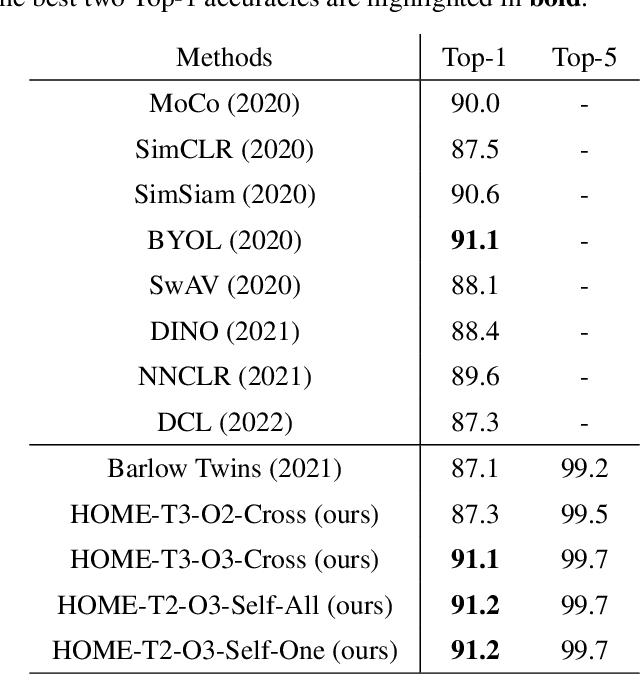
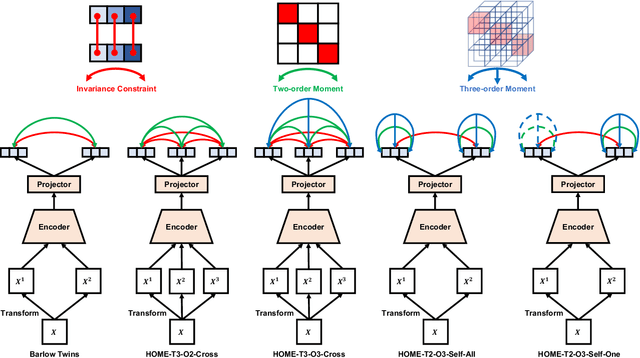
Minimum redundancy among different elements of an embedding in a latent space is a fundamental requirement or major preference in representation learning to capture intrinsic informational structures. Current self-supervised learning methods minimize a pair-wise covariance matrix to reduce the feature redundancy and produce promising results. However, such representation features of multiple variables may contain the redundancy among more than two feature variables that cannot be minimized via the pairwise regularization. Here we propose the High-Order Mixed-Moment-based Embedding (HOME) strategy to reduce the redundancy between any sets of feature variables, which is to our best knowledge the first attempt to utilize high-order statistics/information in this context. Multivariate mutual information is minimum if and only if multiple variables are mutually independent, which suggests the necessary conditions of factorized mixed moments among multiple variables. Based on these statistical and information theoretic principles, our general HOME framework is presented for self-supervised representation learning. Our initial experiments show that a simple version in the form of a three-order HOME scheme already significantly outperforms the current two-order baseline method (i.e., Barlow Twins) in terms of the linear evaluation on representation features.
Bayesian Quickest Change Detection of an Intruder in Acknowledgments for Private Remote State Estimation
Jul 18, 2022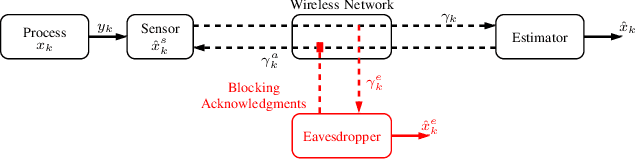
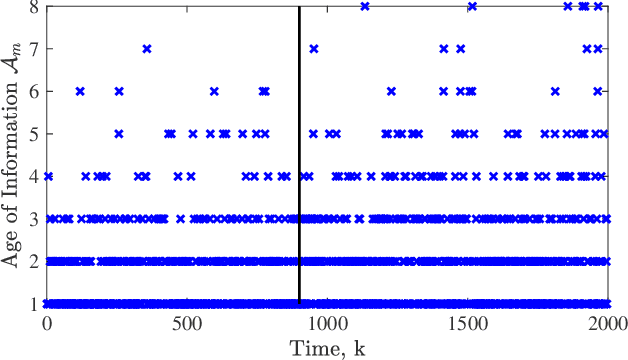
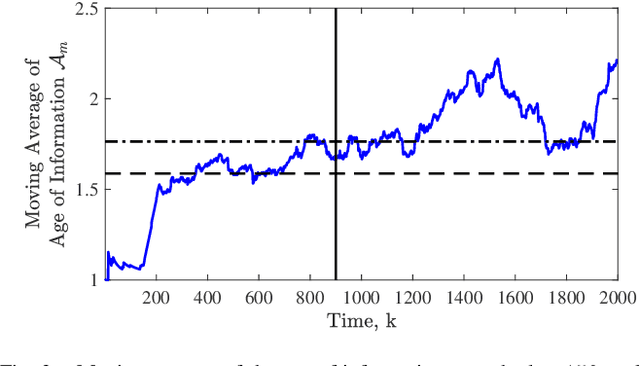
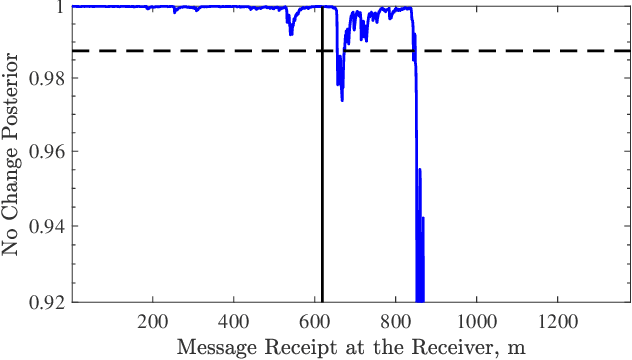
For geographically separated cyber-physical systems, state estimation at a remote monitoring or control site is important to ensure stability and reliability of the system. Often for safety or commercial reasons it is necessary to ensure confidentiality of the process state and control information. A current topic of interest is the private transmission of confidential state information. Many transmission encoding schemes rely on acknowledgments, which may be susceptible to interference from an adversary. We consider a stealthy intruder that selectively blocks acknowledgments allowing an eavesdropper to obtain a reliable state estimate defeating an encoding scheme. We utilize Bayesian Quickest Change Detection techniques to quickly detect online the presence of an intruder at both the remote transmitter and receiver.
TFN: An Interpretable Neural Network with Time-Frequency Transform Embedded for Intelligent Fault Diagnosis
Sep 05, 2022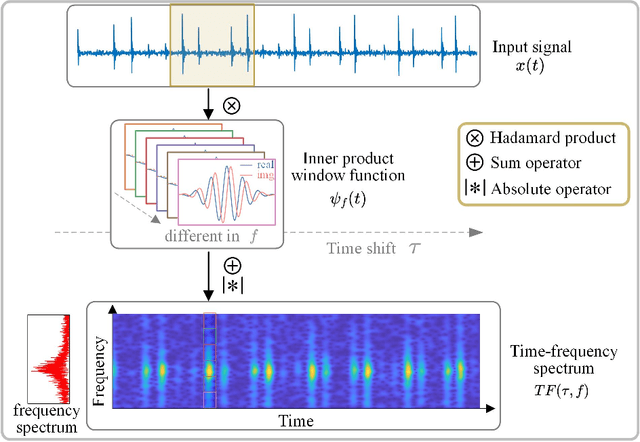

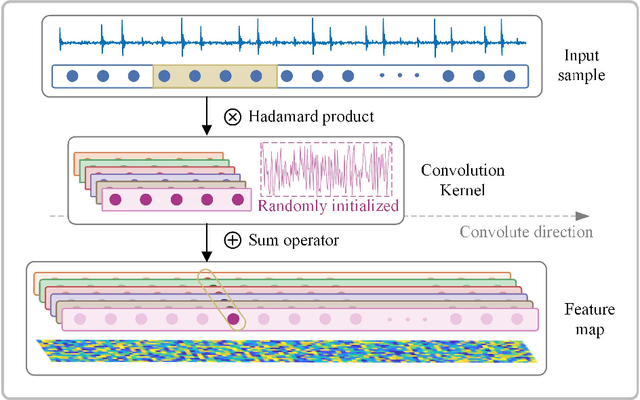

Convolutional Neural Networks (CNNs) are widely used in fault diagnosis of mechanical systems due to their powerful feature extraction and classification capabilities. However, the CNN is a typical black-box model, and the mechanism of CNN's decision-making are not clear, which limits its application in high-reliability-required fault diagnosis scenarios. To tackle this issue, we propose a novel interpretable neural network termed as Time-Frequency Network (TFN), where the physically meaningful time-frequency transform (TFT) method is embedded into the traditional convolutional layer as an adaptive preprocessing layer. This preprocessing layer named as time-frequency convolutional (TFconv) layer, is constrained by a well-designed kernel function to extract fault-related time-frequency information. It not only improves the diagnostic performance but also reveals the logical foundation of the CNN prediction in the frequency domain. Different TFT methods correspond to different kernel functions of the TFconv layer. In this study, four typical TFT methods are considered to formulate the TFNs and their effectiveness and interpretability are proved through three mechanical fault diagnosis experiments. Experimental results also show that the proposed TFconv layer can be easily generalized to other CNNs with different depths. The code of TFN is available on https://github.com/ChenQian0618/TFN.
Detecting Political Biases of Named Entities and Hashtags on Twitter
Sep 16, 2022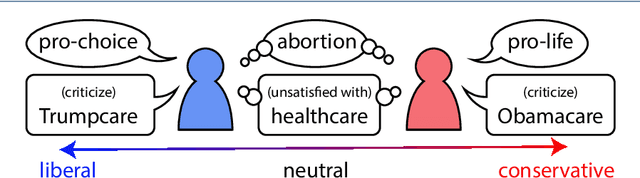

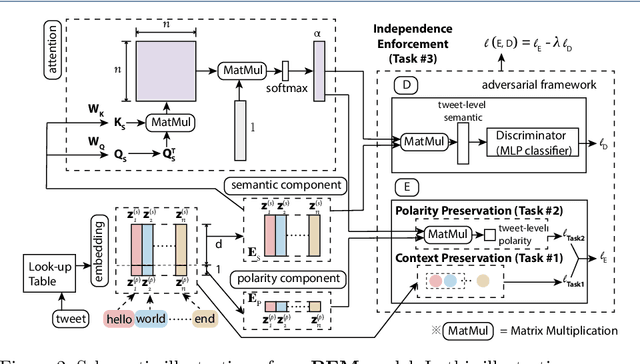
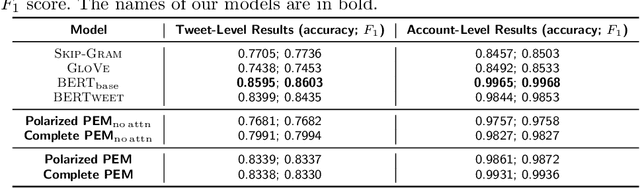
Ideological divisions in the United States have become increasingly prominent in daily communication. Accordingly, there has been much research on political polarization, including many recent efforts that take a computational perspective. By detecting political biases in a corpus of text, one can attempt to describe and discern the polarity of that text. Intuitively, the named entities (i.e., the nouns and phrases that act as nouns) and hashtags in text often carry information about political views. For example, people who use the term "pro-choice" are likely to be liberal, whereas people who use the term "pro-life" are likely to be conservative. In this paper, we seek to reveal political polarities in social-media text data and to quantify these polarities by explicitly assigning a polarity score to entities and hashtags. Although this idea is straightforward, it is difficult to perform such inference in a trustworthy quantitative way. Key challenges include the small number of known labels, the continuous spectrum of political views, and the preservation of both a polarity score and a polarity-neutral semantic meaning in an embedding vector of words. To attempt to overcome these challenges, we propose the Polarity-aware Embedding Multi-task learning (PEM) model. This model consists of (1) a self-supervised context-preservation task, (2) an attention-based tweet-level polarity-inference task, and (3) an adversarial learning task that promotes independence between an embedding's polarity dimension and its semantic dimensions. Our experimental results demonstrate that our PEM model can successfully learn polarity-aware embeddings. We examine a variety of applications and we thereby demonstrate the effectiveness of our PEM model. We also discuss important limitations of our work and stress caution when applying the PEM model to real-world scenarios.