 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUBAKU: An Adversarial Benchmark for Exposing Culturally Grounded Stereotypes in Japanese LLMs
Mar 21, 2026Social biases reflected in language are inherently shaped by cultural norms, which vary significantly across regions and lead to diverse manifestations of stereotypes. Existing evaluations of social bias in large language models (LLMs) for non-English contexts, however, often rely on translations of English benchmarks. Such benchmarks fail to reflect local cultural norms, including those found in Japanese. For instance, Western benchmarks may overlook Japan-specific stereotypes related to hierarchical relationships, regional dialects, or traditional gender roles. To address this limitation, we introduce Japanese cUlture adversarial BiAs benchmarK Under handcrafted creation (JUBAKU), a benchmark tailored to Japanese cultural contexts. JUBAKU uses adversarial construction to expose latent biases across ten distinct cultural categories. Unlike existing benchmarks, JUBAKU features dialogue scenarios hand-crafted by native Japanese annotators, specifically designed to trigger and reveal latent social biases in Japanese LLMs. We evaluated nine Japanese LLMs on JUBAKU and three others adapted from English benchmarks. All models clearly exhibited biases on JUBAKU, performing below the random baseline of 50% with an average accuracy of 23% (ranging from 13% to 33%), despite higher accuracy on the other benchmarks. Human annotators achieved 91% accuracy in identifying unbiased responses, confirming JUBAKU's reliability and its adversarial nature to LLMs.
Few-shot Adaptive Object Detection with Cross-Domain CutMix
Aug 31, 2022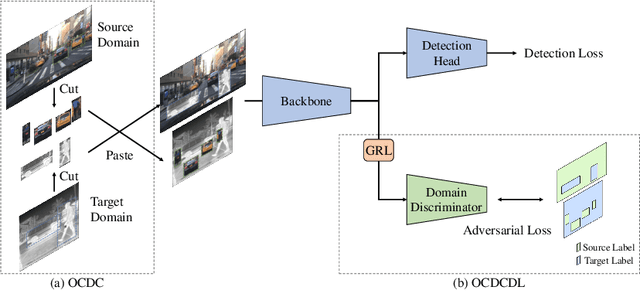
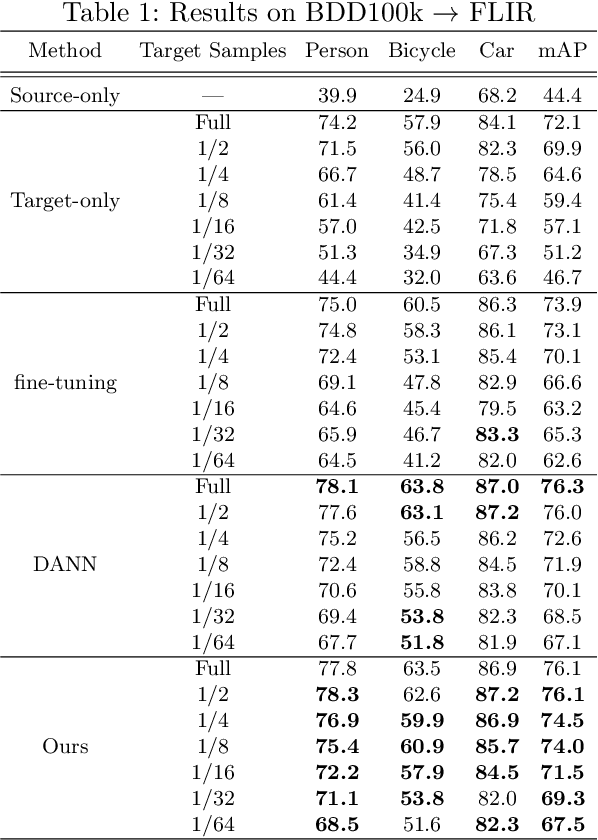
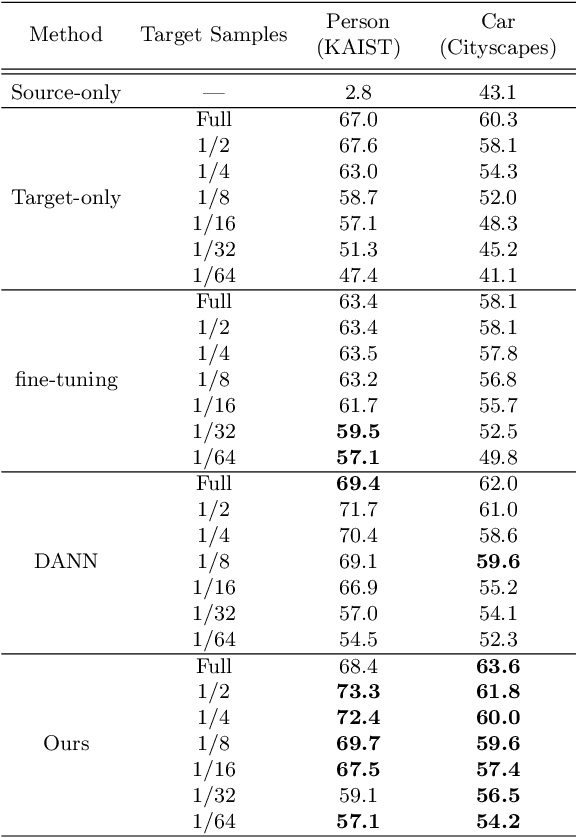
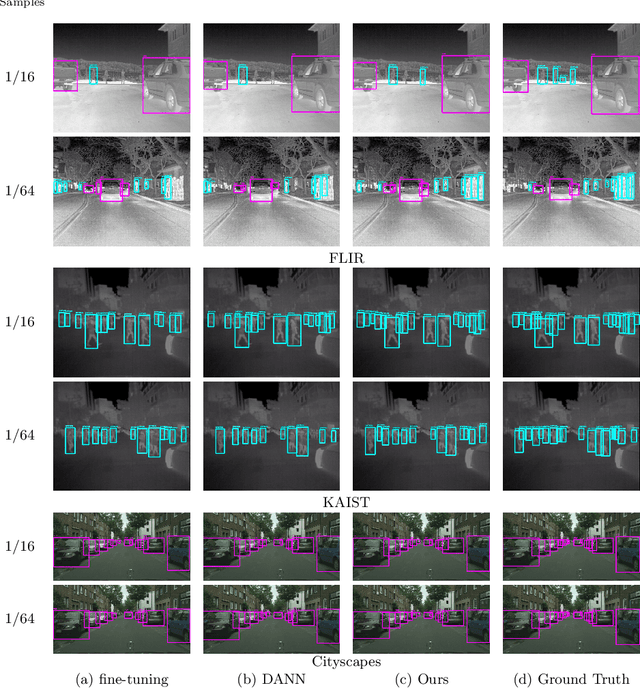
In object detection, data amount and cost are a trade-off, and collecting a large amount of data in a specific domain is labor intensive. Therefore, existing large-scale datasets are used for pre-training. However, conventional transfer learning and domain adaptation cannot bridge the domain gap when the target domain differs significantly from the source domain. We propose a data synthesis method that can solve the large domain gap problem. In this method, a part of the target image is pasted onto the source image, and the position of the pasted region is aligned by utilizing the information of the object bounding box. In addition, we introduce adversarial learning to discriminate whether the original or the pasted regions. The proposed method trains on a large number of source images and a few target domain images. The proposed method achieves higher accuracy than conventional methods in a very different domain problem setting, where RGB images are the source domain, and thermal infrared images are the target domain. Similarly, the proposed method achieves higher accuracy in the cases of simulation images to real images.