 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Overlapped speech and gender detection with WavLM pre-trained features
Sep 09, 2022
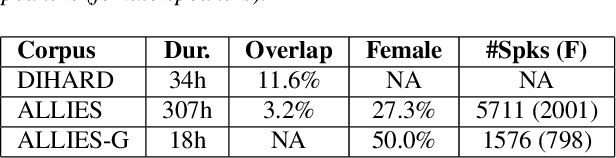
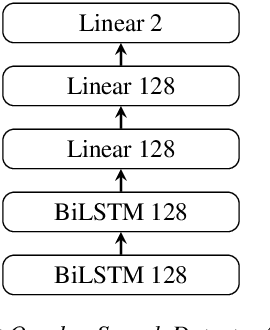
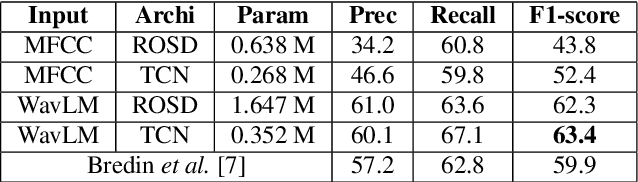
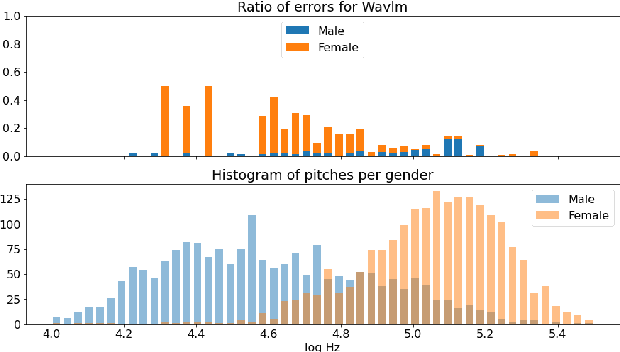
This article focuses on overlapped speech and gender detection in order to study interactions between women and men in French audiovisual media (Gender Equality Monitoring project). In this application context, we need to automatically segment the speech signal according to speakers gender, and to identify when at least two speakers speak at the same time. We propose to use WavLM model which has the advantage of being pre-trained on a huge amount of speech data, to build an overlapped speech detection (OSD) and a gender detection (GD) systems. In this study, we use two different corpora. The DIHARD III corpus which is well adapted for the OSD task but lack gender information. The ALLIES corpus fits with the project application context. Our best OSD system is a Temporal Convolutional Network (TCN) with WavLM pre-trained features as input, which reaches a new state-of-the-art F1-score performance on DIHARD. A neural GD is trained with WavLM inputs on a gender balanced subset of the French broadcast news ALLIES data, and obtains an accuracy of 97.9%. This work opens new perspectives for human science researchers regarding the differences of representation between women and men in French media.
Denoising Architecture for Unsupervised Anomaly Detection in Time-Series
Aug 30, 2022Anomalies in time-series provide insights of critical scenarios across a range of industries, from banking and aerospace to information technology, security, and medicine. However, identifying anomalies in time-series data is particularly challenging due to the imprecise definition of anomalies, the frequent absence of labels, and the enormously complex temporal correlations present in such data. The LSTM Autoencoder is an Encoder-Decoder scheme for Anomaly Detection based on Long Short Term Memory Networks that learns to reconstruct time-series behavior and then uses reconstruction error to identify abnormalities. We introduce the Denoising Architecture as a complement to this LSTM Encoder-Decoder model and investigate its effect on real-world as well as artificially generated datasets. We demonstrate that the proposed architecture increases both the accuracy and the training speed, thereby, making the LSTM Autoencoder more efficient for unsupervised anomaly detection tasks.
Resolving Copycat Problems in Visual Imitation Learning via Residual Action Prediction
Jul 20, 2022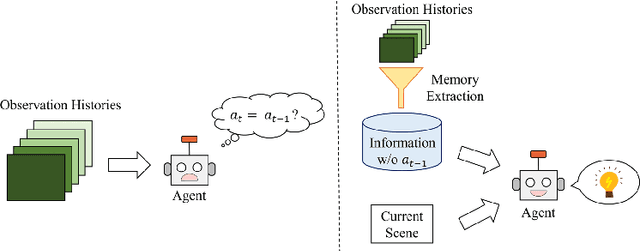

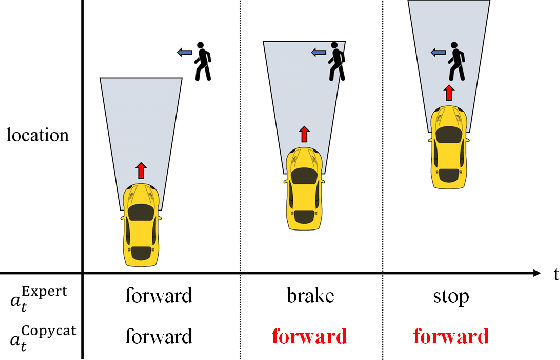
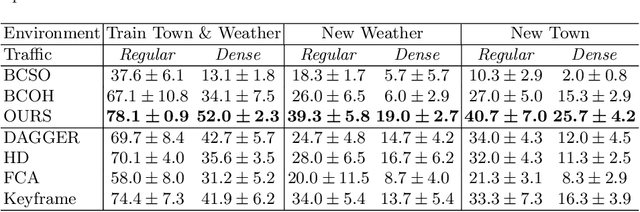
Imitation learning is a widely used policy learning method that enables intelligent agents to acquire complex skills from expert demonstrations. The input to the imitation learning algorithm is usually composed of both the current observation and historical observations since the most recent observation might not contain enough information. This is especially the case with image observations, where a single image only includes one view of the scene, and it suffers from a lack of motion information and object occlusions. In theory, providing multiple observations to the imitation learning agent will lead to better performance. However, surprisingly people find that sometimes imitation from observation histories performs worse than imitation from the most recent observation. In this paper, we explain this phenomenon from the information flow within the neural network perspective. We also propose a novel imitation learning neural network architecture that does not suffer from this issue by design. Furthermore, our method scales to high-dimensional image observations. Finally, we benchmark our approach on two widely used simulators, CARLA and MuJoCo, and it successfully alleviates the copycat problem and surpasses the existing solutions.
Model-driven Learning for Generic MIMO Downlink Beamforming With Uplink Channel Information
Sep 16, 2021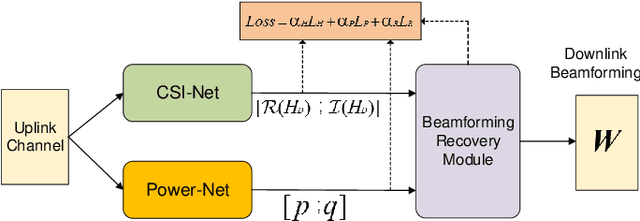
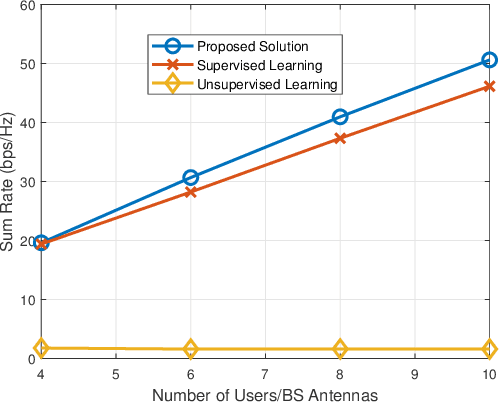
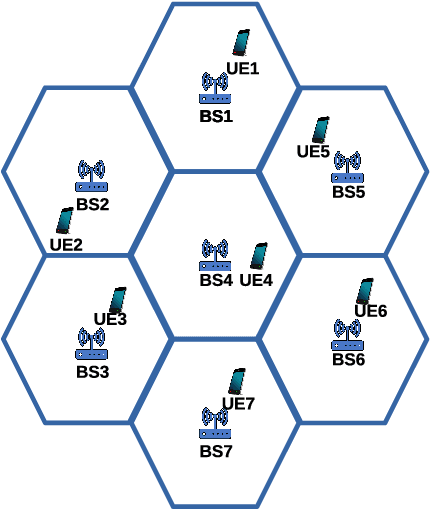
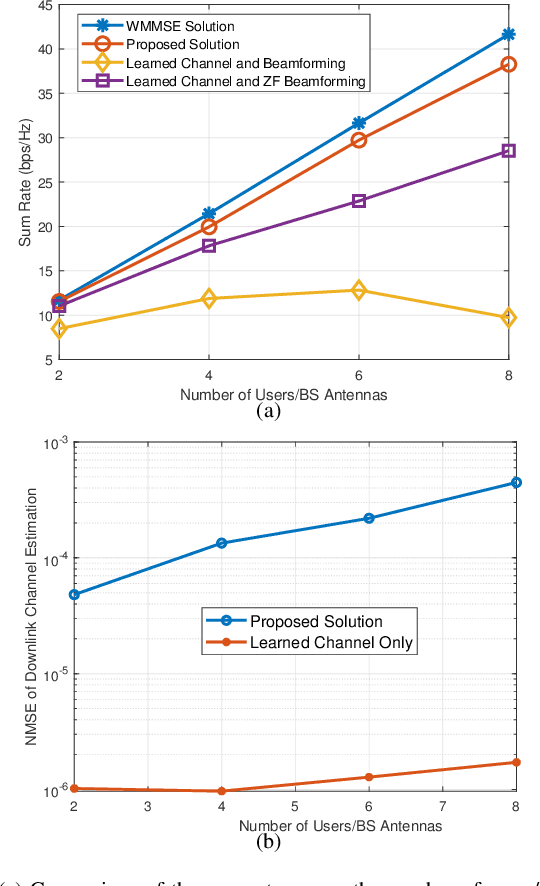
Accurate downlink channel information is crucial to the beamforming design, but it is difficult to obtain in practice. This paper investigates a deep learning-based optimization approach of the downlink beamforming to maximize the system sum rate, when only the uplink channel information is available. Our main contribution is to propose a model-driven learning technique that exploits the structure of the optimal downlink beamforming to design an effective hybrid learning strategy with the aim to maximize the sum rate performance. This is achieved by jointly considering the learning performance of the downlink channel, the power and the sum rate in the training stage. The proposed approach applies to generic cases in which the uplink channel information is available, but its relation to the downlink channel is unknown and does not require an explicit downlink channel estimation. We further extend the developed technique to massive multiple-input multiple-output scenarios and achieve a distributed learning strategy for multicell systems without an inter-cell signalling overhead. Simulation results verify that our proposed method provides the performance close to the state of the art numerical algorithms with perfect downlink channel information and significantly outperforms existing data-driven methods in terms of the sum rate.
Multi-modal Streaming 3D Object Detection
Sep 12, 2022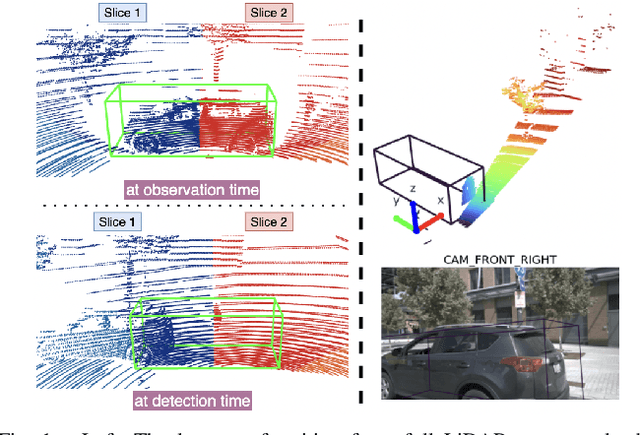
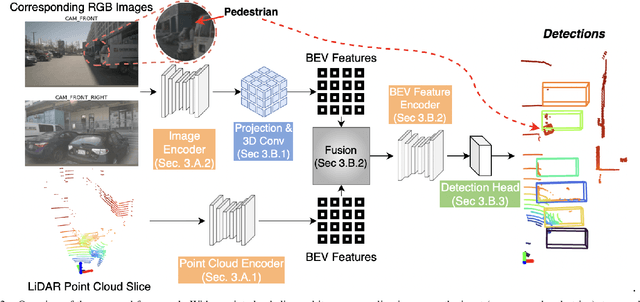
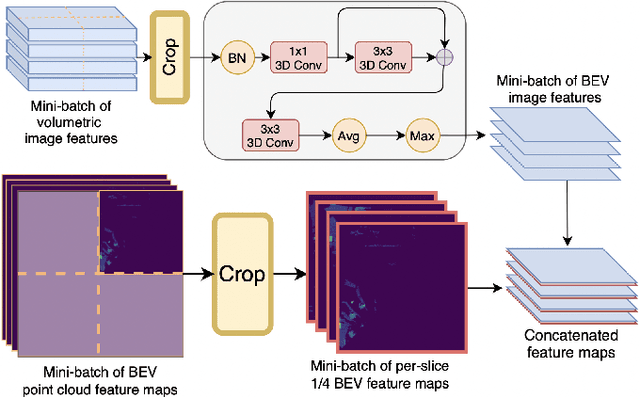

Modern autonomous vehicles rely heavily on mechanical LiDARs for perception. Current perception methods generally require 360{\deg} point clouds, collected sequentially as the LiDAR scans the azimuth and acquires consecutive wedge-shaped slices. The acquisition latency of a full scan (~ 100ms) may lead to outdated perception which is detrimental to safe operation. Recent streaming perception works proposed directly processing LiDAR slices and compensating for the narrow field of view (FOV) of a slice by reusing features from preceding slices. These works, however, are all based on a single modality and require past information which may be outdated. Meanwhile, images from high-frequency cameras can support streaming models as they provide a larger FoV compared to a LiDAR slice. However, this difference in FoV complicates sensor fusion. To address this research gap, we propose an innovative camera-LiDAR streaming 3D object detection framework that uses camera images instead of past LiDAR slices to provide an up-to-date, dense, and wide context for streaming perception. The proposed method outperforms prior streaming models on the challenging NuScenes benchmark. It also outperforms powerful full-scan detectors while being much faster. Our method is shown to be robust to missing camera images, narrow LiDAR slices, and small camera-LiDAR miscalibration.
Improving Knowledge-aware Recommendation with Multi-level Interactive Contrastive Learning
Aug 22, 2022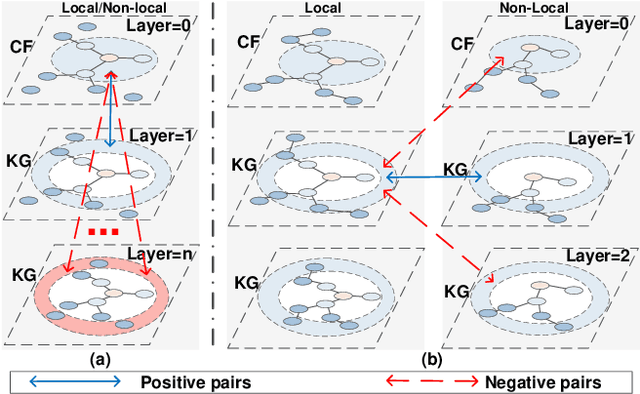
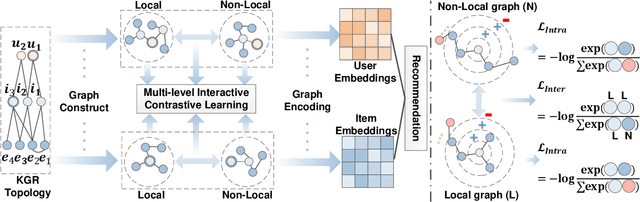
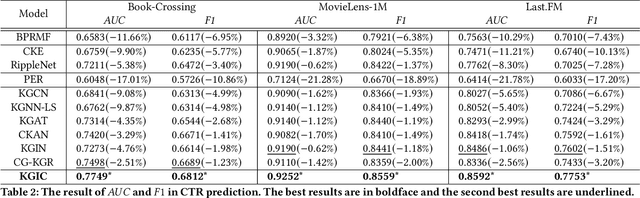
Incorporating Knowledge Graphs (KG) into recommeder system has attracted considerable attention. Recently, the technical trend of Knowledge-aware Recommendation (KGR) is to develop end-to-end models based on graph neural networks (GNNs). However, the extremely sparse user-item interactions significantly degrade the performance of the GNN-based models, as: 1) the sparse interaction, means inadequate supervision signals and limits the supervised GNN-based models; 2) the combination of sparse interactions (CF part) and redundant KG facts (KG part) results in an unbalanced information utilization. Besides, the GNN paradigm aggregates local neighbors for node representation learning, while ignoring the non-local KG facts and making the knowledge extraction insufficient. Inspired by the recent success of contrastive learning in mining supervised signals from data itself, in this paper, we focus on exploring contrastive learning in KGR and propose a novel multi-level interactive contrastive learning mechanism. Different from traditional contrastive learning methods which contrast nodes of two generated graph views, interactive contrastive mechanism conducts layer-wise self-supervised learning by contrasting layers of different parts within graphs, which is also an "interaction" action. Specifically, we first construct local and non-local graphs for user/item in KG, exploring more KG facts for KGR. Then an intra-graph level interactive contrastive learning is performed within each graph, which contrasts layers of the CF and KG parts, for more consistent information leveraging. Besides, an inter-graph level interactive contrastive learning is performed between the local and non-local graphs, for sufficiently and coherently extracting non-local KG signals. Extensive experiments conducted on three benchmark datasets show the superior performance of our proposed method over the state-of-the-arts.
Learning robot inverse dynamics using sparse online Gaussian process with forgetting mechanism
Aug 06, 2022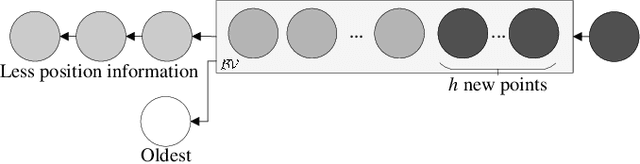
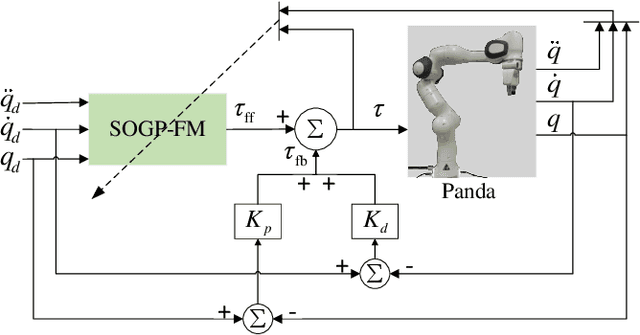
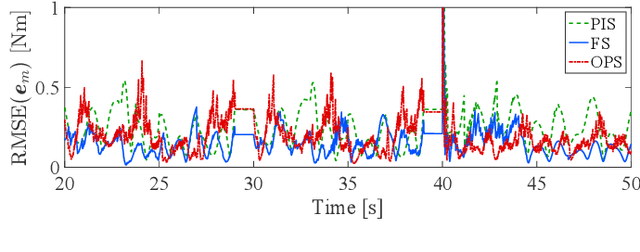
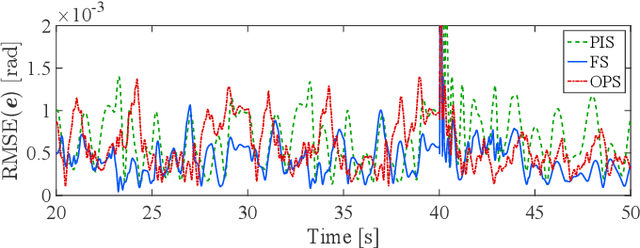
Online Gaussian processes (GPs), typically used for learning models from time-series data, are more flexible and robust than offline GPs. Both local and sparse approximations of GPs can efficiently learn complex models online. Yet, these approaches assume that all signals are relatively accurate and that all data are available for learning without misleading data. Besides, the online learning capacity of GPs is limited for high-dimension problems and long-term tasks in practice. This paper proposes a sparse online GP (SOGP) with a forgetting mechanism to forget distant model information at a specific rate. The proposed approach combines two general data deletion schemes for the basis vector set of SOGP: The position information-based scheme and the oldest points-based scheme. We apply our approach to learn the inverse dynamics of a collaborative robot with 7 degrees of freedom under a two-segment trajectory tracking problem with task switching. Both simulations and experiments have shown that the proposed approach achieves better tracking accuracy and predictive smoothness compared with the two general data deletion schemes.
Doppler Exploitation in Bistatic mmWave Radio SLAM
Aug 22, 2022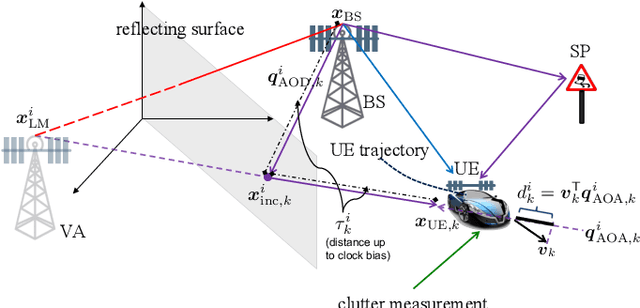
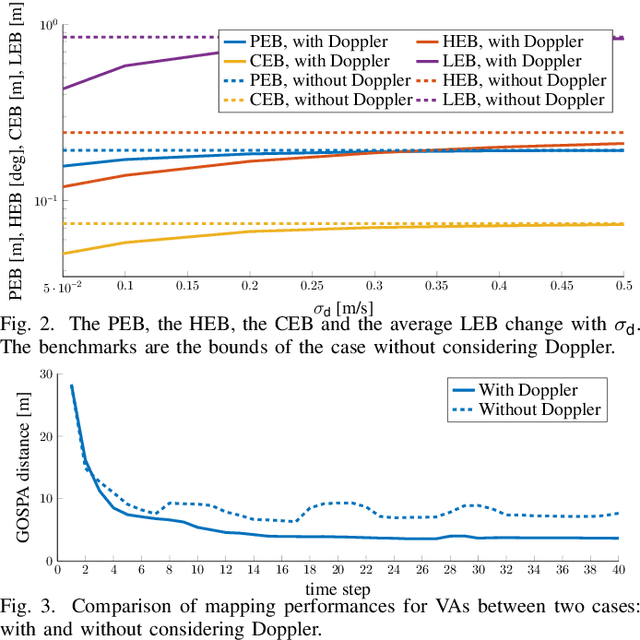
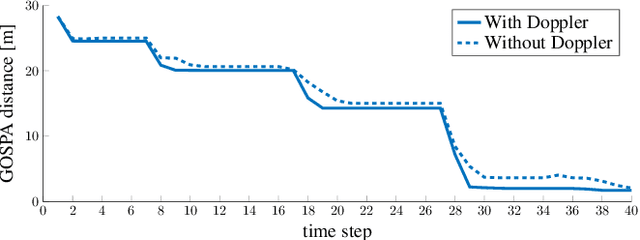
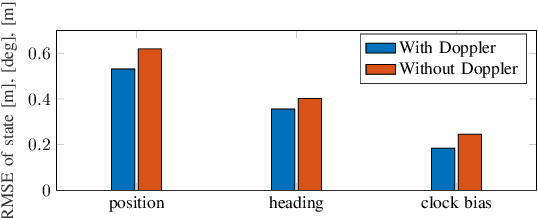
Networks in 5G and beyond utilize millimeter wave (mmWave) radio signals, large bandwidths, and large antenna arrays, which bring opportunities in jointly localizing the user equipment and mapping the propagation environment, termed as simultaneous localization and mapping (SLAM). Existing approaches mainly rely on delays and angles, and ignore the Doppler, although it contains geometric information. In this paper, we study the benefits of exploiting Doppler in SLAM through deriving the posterior Cram\'er-Rao bounds (PCRBs) and formulating the extended Kalman-Poisson multi-Bernoulli sequential filtering solution with Doppler as one of the involved measurements. Both theoretical PCRB analysis and simulation results demonstrate the efficacy of utilizing Doppler.
Tac2Structure: Object Surface Reconstruction Only through Multi Times Touch
Sep 14, 2022


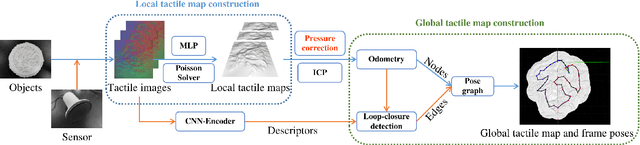
Inspired by the ability of humans to perceive the surface texture of unfamiliar objects without relying on vision, the sense of tactile can play a crucial role in the process of robots exploring the environment, especially in some scenes where vision is difficult to apply or occlusion is inevitable to exist. Existing tactile surface reconstruction methods rely on external sensors or have strong prior assumptions, which will limit their application scenarios and make the operation more complex. This paper presents a surface reconstruction algorithm that uses only a new vision-based tactile sensor where the surface structure of an unfamiliar object is reconstructed by multiple tactile measurements. Compared with existing algorithms, the proposed algorithm doesn't rely on external devices and focuses on improving the reconstruction accuracy of the large-scale object surface. Aiming at the difficulty that the reconstruction accuracy is easily affected by the pressure of sampling, we propose a correction algorithm to adapt it. Multi-frame tactile imprints generated from many times contact can accurately reconstruct global object surface by jointly using the point cloud registration algorithm, loop-closure detection algorithm based on deep learning, and pose graph optimization algorithm. Experiments verify the proposed algorithm can achieve millimeter-level accuracy in reconstructing the surface of interactive objects and provide accurate tactile information for the robot to perceive the surrounding environment.
Data-based price discrimination: information theoretic limitations and a minimax optimal strategy
Apr 27, 2022
This paper studies the gap between the classical pricing theory and the data-based pricing theory. We focus on the problem of price discrimination with a continuum of buyer types based on a finite sample of observations. Our first set of results provides sharp lower bounds in the worst-case scenario for the discrepancy between any data-based pricing strategies and the theoretical optimal third-degree price discrimination (3PD) strategy (respectively, uniform pricing strategy) derived from the distribution (where the sample is drawn) ranging over a large class of distributions. Consequently, there is an inevitable gap between revenues based on any data-based pricing strategy and the revenue based on the theoretical optimal 3PD (respectively, uniform pricing) strategy. We then propose easy-to-implement data-based 3PD and uniform pricing strategies and show each strategy is minimax optimal in the sense that the gap between their respective revenue and the revenue based on the theoretical optimal 3PD (respectively, uniform pricing) strategy matches our worst-case lower bounds up to constant factors (that are independent of the sample size $n$). We show that 3PD strategies are revenue superior to uniform pricing strategies if and only if the sample size $n$ is large enough. In other words, if $n$ is below a threshold, uniform pricing strategies are revenue superior to 3PD strategies. We further provide upper bounds for the gaps between the welfare generated by our minimax optimal 3PD (respectively, uniform pricing) strategy and the welfare based on the theoretical optimal 3PD (respectively, uniform pricing) strategy.