 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Sep 28, 2022


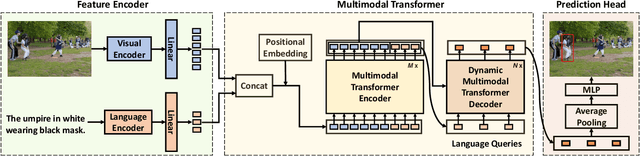
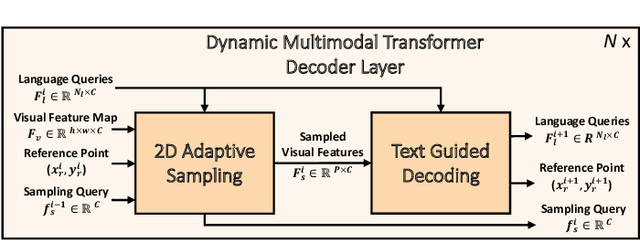
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.
Age of Semantics in Cooperative Communications: To Expedite Simulation Towards Real via Offline Reinforcement Learning
Sep 19, 2022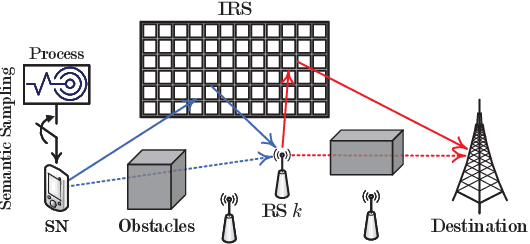
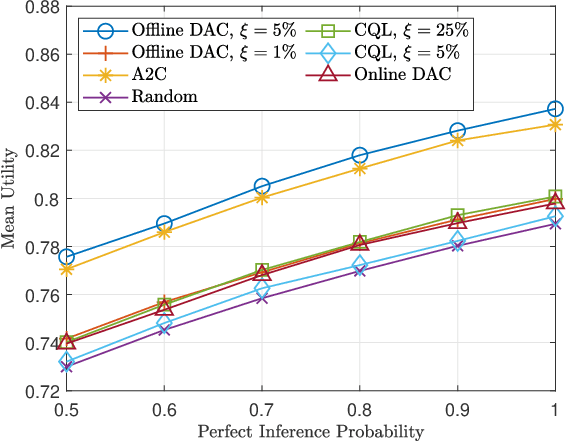
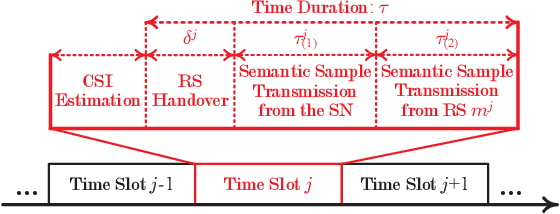
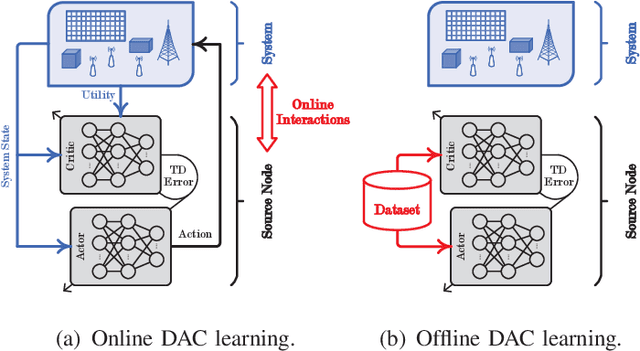
The age of information metric fails to correctly describe the intrinsic semantics of a status update. In an intelligent reflecting surface-aided cooperative relay communication system, we propose the age of semantics (AoS) for measuring semantics freshness of the status updates. Specifically, we focus on the status updating from a source node (SN) to the destination, which is formulated as a Markov decision process (MDP). The objective of the SN is to maximize the expected satisfaction of AoS and energy consumption under the maximum transmit power constraint. To seek the optimal control policy, we first derive an online deep actor-critic (DAC) learning scheme under the on-policy temporal difference learning framework. However, implementing the online DAC in practice poses the key challenge in infinitely repeated interactions between the SN and the system, which can be dangerous particularly during the exploration. We then put forward a novel offline DAC scheme, which estimates the optimal control policy from a previously collected dataset without any further interactions with the system. Numerical experiments verify the theoretical results and show that our offline DAC scheme significantly outperforms the online DAC scheme and the most representative baselines in terms of mean utility, demonstrating strong robustness to dataset quality.
Adaptive Mixture of Experts Learning for Generalizable Face Anti-Spoofing
Jul 20, 2022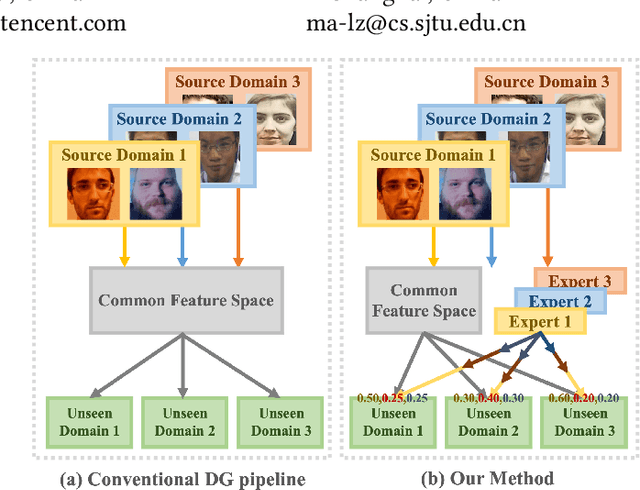
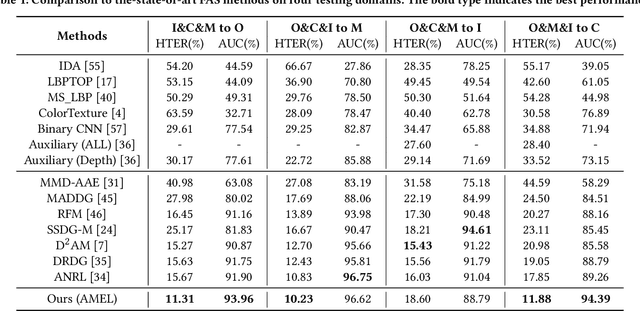
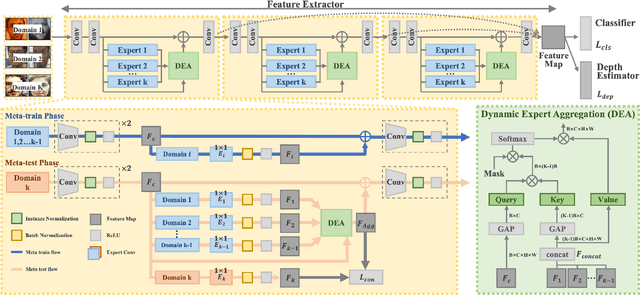
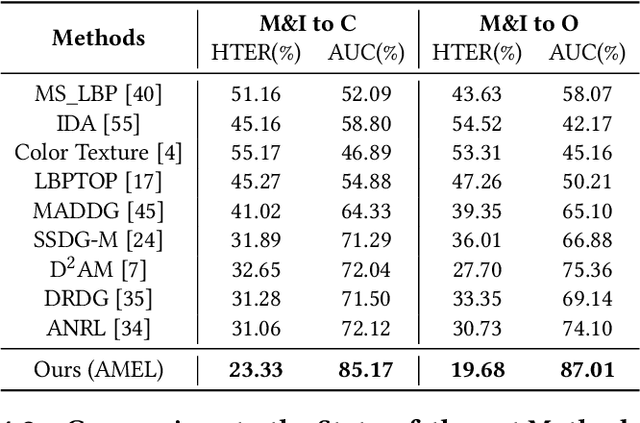
With various face presentation attacks emerging continually, face anti-spoofing (FAS) approaches based on domain generalization (DG) have drawn growing attention. Existing DG-based FAS approaches always capture the domain-invariant features for generalizing on the various unseen domains. However, they neglect individual source domains' discriminative characteristics and diverse domain-specific information of the unseen domains, and the trained model is not sufficient to be adapted to various unseen domains. To address this issue, we propose an Adaptive Mixture of Experts Learning (AMEL) framework, which exploits the domain-specific information to adaptively establish the link among the seen source domains and unseen target domains to further improve the generalization. Concretely, Domain-Specific Experts (DSE) are designed to investigate discriminative and unique domain-specific features as a complement to common domain-invariant features. Moreover, Dynamic Expert Aggregation (DEA) is proposed to adaptively aggregate the complementary information of each source expert based on the domain relevance to the unseen target domain. And combined with meta-learning, these modules work collaboratively to adaptively aggregate meaningful domain-specific information for the various unseen target domains. Extensive experiments and visualizations demonstrate the effectiveness of our method against the state-of-the-art competitors.
Finding neural signatures for obesity using source-localized EEG features
Aug 30, 2022
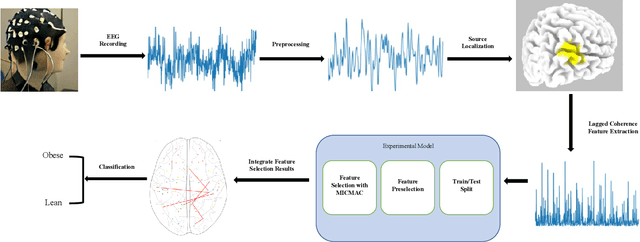
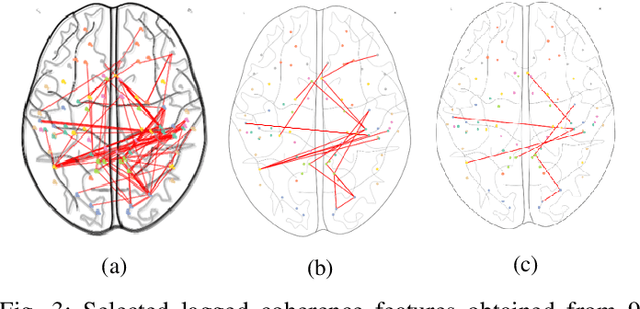
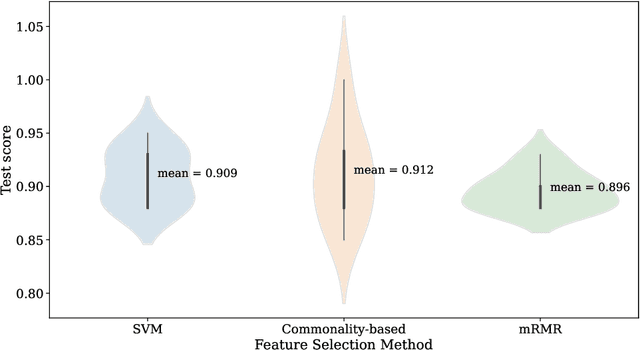
Obesity is a serious issue in the modern society since it associates to a significantly reduced quality of life. Current research conducted to explore the obesity-related neurological evidences using electroencephalography (EEG) data are limited to traditional approaches. In this study, we developed a novel machine learning model to identify brain networks of obese females using alpha band functional connectivity features derived from EEG data. An overall classification accuracy of 90% is achieved. Our finding suggests that the obese brain is characterized by a dysfunctional network in which the areas that are responsible for processing self-referential information such as energy requirement are impaired.
Adaptive Information Seeking for Open-Domain Question Answering
Sep 14, 2021
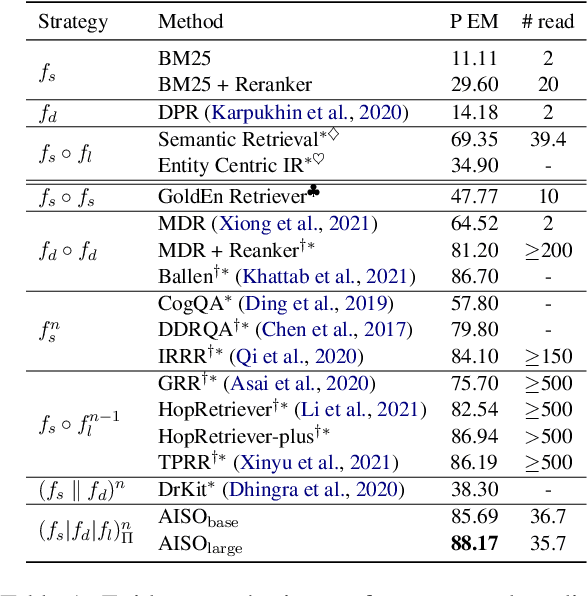
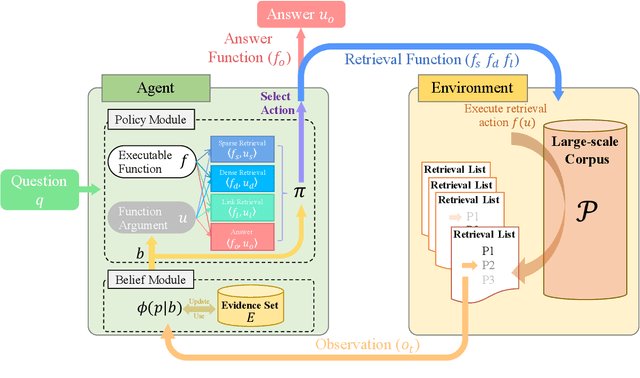
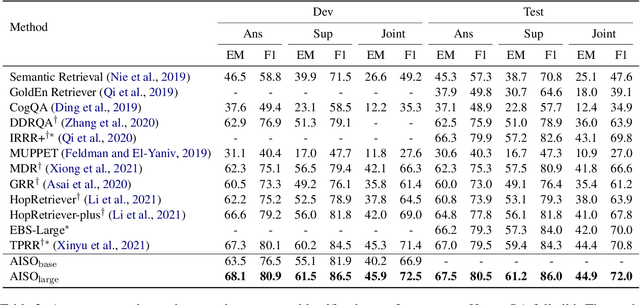
Information seeking is an essential step for open-domain question answering to efficiently gather evidence from a large corpus. Recently, iterative approaches have been proven to be effective for complex questions, by recursively retrieving new evidence at each step. However, almost all existing iterative approaches use predefined strategies, either applying the same retrieval function multiple times or fixing the order of different retrieval functions, which cannot fulfill the diverse requirements of various questions. In this paper, we propose a novel adaptive information-seeking strategy for open-domain question answering, namely AISO. Specifically, the whole retrieval and answer process is modeled as a partially observed Markov decision process, where three types of retrieval operations (e.g., BM25, DPR, and hyperlink) and one answer operation are defined as actions. According to the learned policy, AISO could adaptively select a proper retrieval action to seek the missing evidence at each step, based on the collected evidence and the reformulated query, or directly output the answer when the evidence set is sufficient for the question. Experiments on SQuAD Open and HotpotQA fullwiki, which serve as single-hop and multi-hop open-domain QA benchmarks, show that AISO outperforms all baseline methods with predefined strategies in terms of both retrieval and answer evaluations.
Consensus-based Fast and Energy-Efficient Multi-Robot Task Allocation
Sep 21, 2022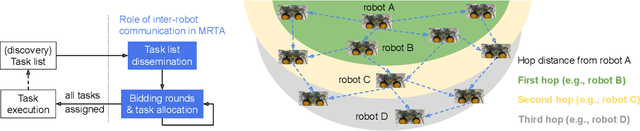
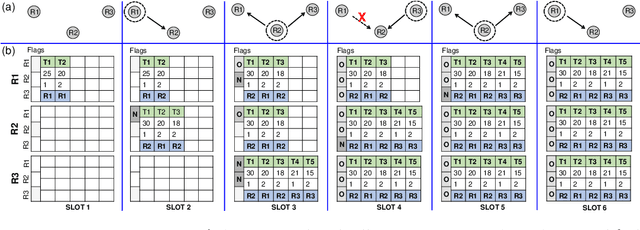
In a multi-robot system, the appropriate allocation of the tasks to the individual robots is a very significant component. The availability of a centralized infrastructure can guarantee an optimal allocation of the tasks. However, in many important scenarios such as search and rescue, exploration, disaster-management, war-field, etc., on-the-fly allocation of the dynamic tasks to the robots in a decentralized fashion is the only possible option. Efficient communication among the robots plays a crucial role in any such decentralized setting. Existing works on distributed Multi-Robot Task Allocation (MRTA) either assume that the network is available or a naive communication paradigm is used. On the contrary, in most of these scenarios, the network infrastructure is either unstable or unavailable and ad-hoc networking is the only resort. Recent developments in synchronous-transmission (ST) based wireless communication protocols are shown to be more efficient than the traditional asynchronous transmission-based protocols in ad hoc networks such as Wireless Sensor Network (WSN)/Internet of Things (IoT) applications. The current work is the first effort that utilizes ST for MRTA. Specifically, we propose an algorithm that efficiently adapts ST-based many-to-many interaction and minimizes the information exchange to reach a consensus for task allocation. We showcase the efficacy of the proposed algorithm through an extensive simulation-based study of its latency and energy-efficiency under different settings.
Second-order Approximation of Minimum Discrimination Information in Independent Component Analysis
Nov 30, 2021
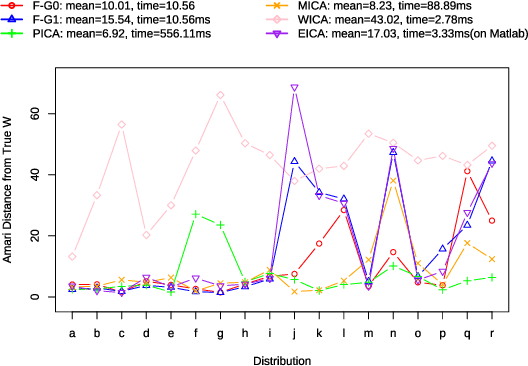

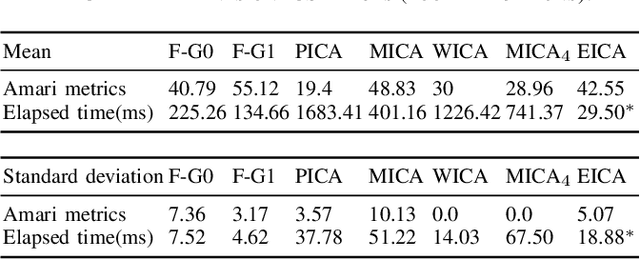
Independent Component Analysis (ICA) is intended to recover the mutually independent sources from their linear mixtures, and F astICA is one of the most successful ICA algorithms. Although it seems reasonable to improve the performance of F astICA by introducing more nonlinear functions to the negentropy estimation, the original fixed-point method (approximate Newton method) in F astICA degenerates under this circumstance. To alleviate this problem, we propose a novel method based on the second-order approximation of minimum discrimination information (MDI). The joint maximization in our method is consisted of minimizing single weighted least squares and seeking unmixing matrix by the fixed-point method. Experimental results validate its efficiency compared with other popular ICA algorithms.
Information Harvesting for Far-Field Wireless Power Transfer
May 26, 2021
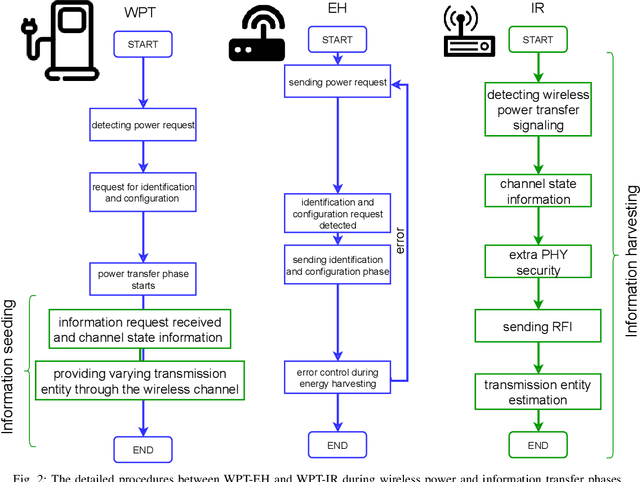
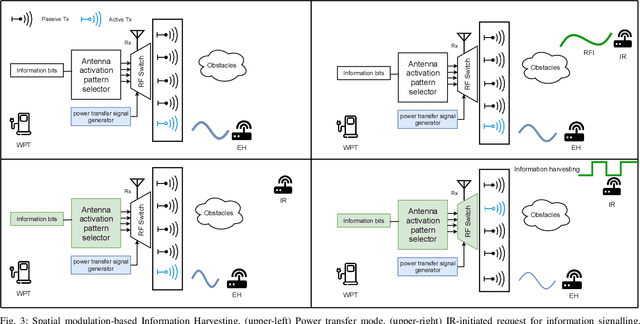
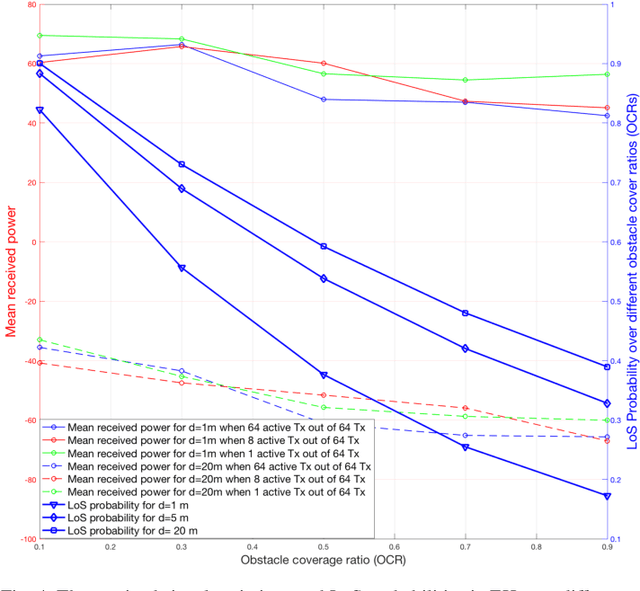
Considering ubiquitous connectivity and advanced information processing capability, huge amount of low-power IoT devices are deployed nowadays and the maintenance of those devices which includes firmware/software updates and recharging the units has become a bottleneck for IoT systems. For addressing limited battery constraints, wireless power transfer is a promising approach such that it does not require any physical link between energy harvester and power transfer. Furthermore, combining wireless power transfer with information transmission has become more appealing. In the systems that apply radio signals the wireless power transfer has become a popular trend to harvest RF-radiated energy from received information signal in IoT devices. For those systems, design frameworks mainly deal with the trade-off between information capacity and energy harvesting efficiency. Therein various signaling design frameworks have been proposed for different system preferences between power and information. In addition to this, protecting the information part from potential eavesdropping activity in a service area introduces security considerations for those systems. In this paper, we propose a novel concept, Information Harvesting, for wireless power transfer systems. It introduces a novel protocol design from opposite perspective compared to the existing studies. Particularly, Information Harvesting aims to transmit information through existing wireless power transfer mechanism without interfering/interrupting power transfer.
Hyperspectral Remote Sensing Benchmark Database for Oil Spill Detection with an Isolation Forest-Guided Unsupervised Detector
Sep 28, 2022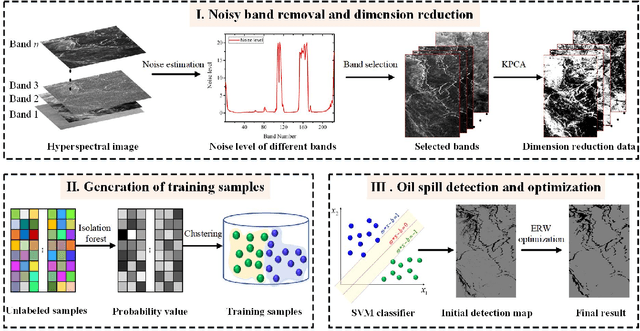
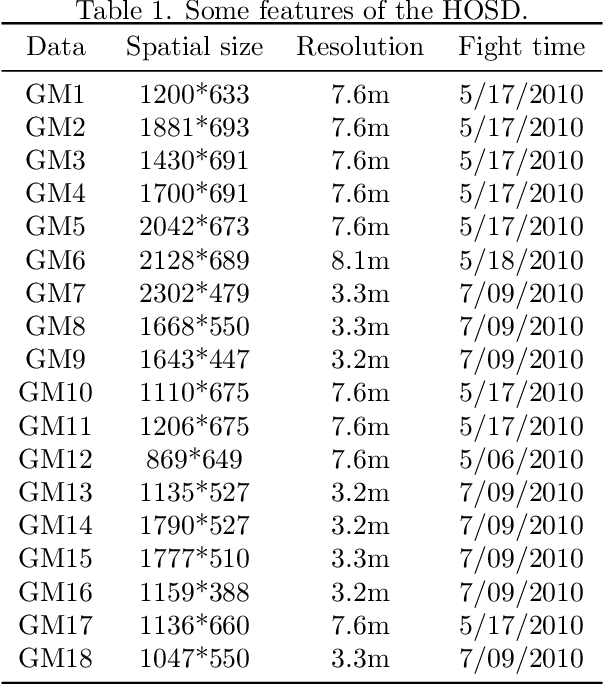
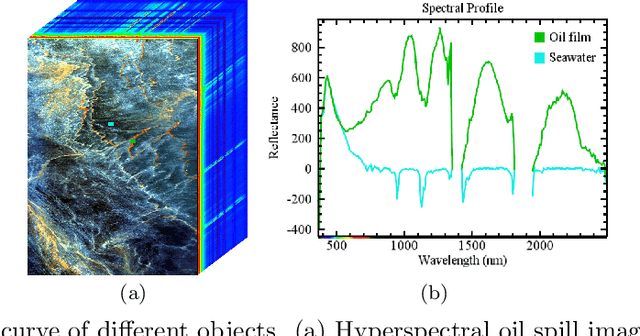
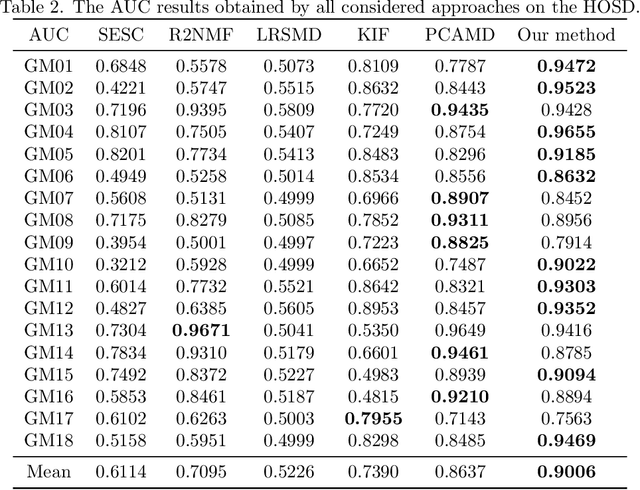
Oil spill detection has attracted increasing attention in recent years since marine oil spill accidents severely affect environments, natural resources, and the lives of coastal inhabitants. Hyperspectral remote sensing images provide rich spectral information which is beneficial for the monitoring of oil spills in complex ocean scenarios. However, most of the existing approaches are based on supervised and semi-supervised frameworks to detect oil spills from hyperspectral images (HSIs), which require a huge amount of effort to annotate a certain number of high-quality training sets. In this study, we make the first attempt to develop an unsupervised oil spill detection method based on isolation forest for HSIs. First, considering that the noise level varies among different bands, a noise variance estimation method is exploited to evaluate the noise level of different bands, and the bands corrupted by severe noise are removed. Second, kernel principal component analysis (KPCA) is employed to reduce the high dimensionality of the HSIs. Then, the probability of each pixel belonging to one of the classes of seawater and oil spills is estimated with the isolation forest, and a set of pseudo-labeled training samples is automatically produced using the clustering algorithm on the detected probability. Finally, an initial detection map can be obtained by performing the support vector machine (SVM) on the dimension-reduced data, and then, the initial detection result is further optimized with the extended random walker (ERW) model so as to improve the detection accuracy of oil spills. Experiments on airborne hyperspectral oil spill data (HOSD) created by ourselves demonstrate that the proposed method obtains superior detection performance with respect to other state-of-the-art detection approaches.
Narcissus: A Practical Clean-Label Backdoor Attack with Limited Information
Apr 15, 2022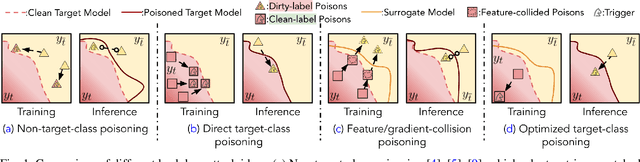

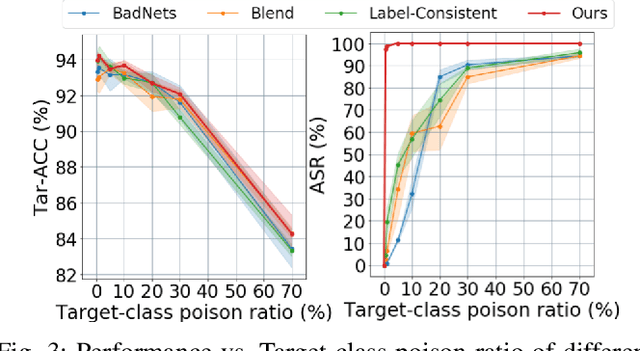
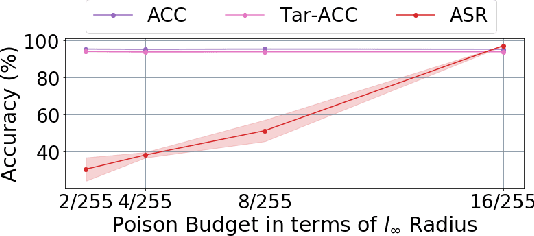
Backdoor attacks insert malicious data into a training set so that, during inference time, it misclassifies inputs that have been patched with a backdoor trigger as the malware specified label. For backdoor attacks to bypass human inspection, it is essential that the injected data appear to be correctly labeled. The attacks with such property are often referred to as "clean-label attacks." Existing clean-label backdoor attacks require knowledge of the entire training set to be effective. Obtaining such knowledge is difficult or impossible because training data are often gathered from multiple sources (e.g., face images from different users). It remains a question whether backdoor attacks still present a real threat. This paper provides an affirmative answer to this question by designing an algorithm to mount clean-label backdoor attacks based only on the knowledge of representative examples from the target class. With poisoning equal to or less than 0.5% of the target-class data and 0.05% of the training set, we can train a model to classify test examples from arbitrary classes into the target class when the examples are patched with a backdoor trigger. Our attack works well across datasets and models, even when the trigger presents in the physical world. We explore the space of defenses and find that, surprisingly, our attack can evade the latest state-of-the-art defenses in their vanilla form, or after a simple twist, we can adapt to the downstream defenses. We study the cause of the intriguing effectiveness and find that because the trigger synthesized by our attack contains features as persistent as the original semantic features of the target class, any attempt to remove such triggers would inevitably hurt the model accuracy first.