 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond-order Approximation of Minimum Discrimination Information in Independent Component Analysis
Nov 30, 2021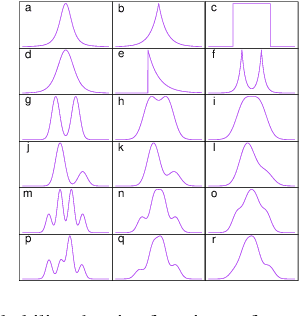
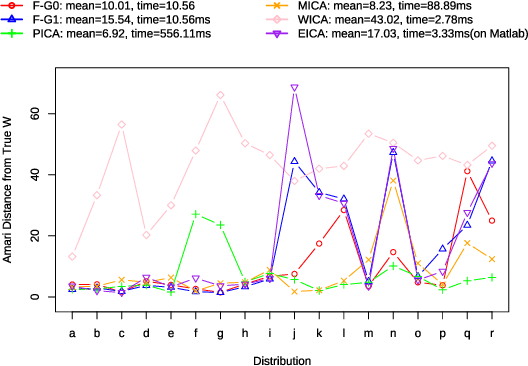

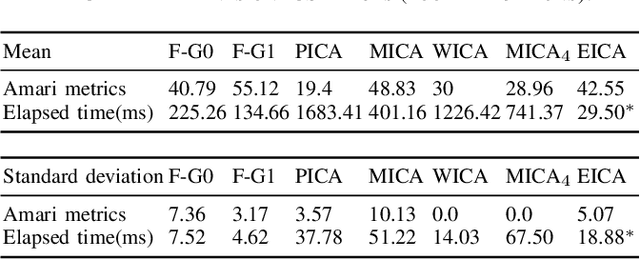
Independent Component Analysis (ICA) is intended to recover the mutually independent sources from their linear mixtures, and F astICA is one of the most successful ICA algorithms. Although it seems reasonable to improve the performance of F astICA by introducing more nonlinear functions to the negentropy estimation, the original fixed-point method (approximate Newton method) in F astICA degenerates under this circumstance. To alleviate this problem, we propose a novel method based on the second-order approximation of minimum discrimination information (MDI). The joint maximization in our method is consisted of minimizing single weighted least squares and seeking unmixing matrix by the fixed-point method. Experimental results validate its efficiency compared with other popular ICA algorithms.
Modifications of FastICA in Convolutive Blind Source Separation
Jul 24, 2021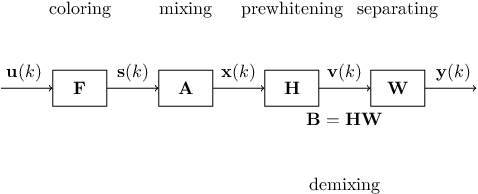
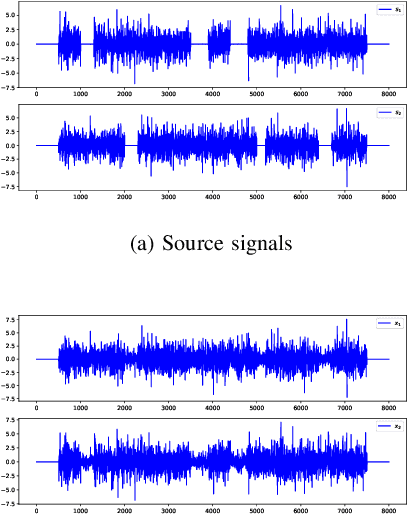
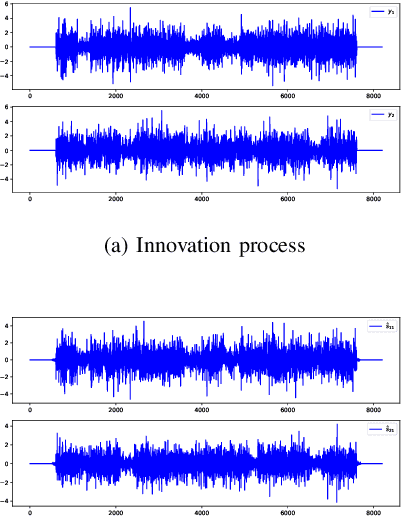
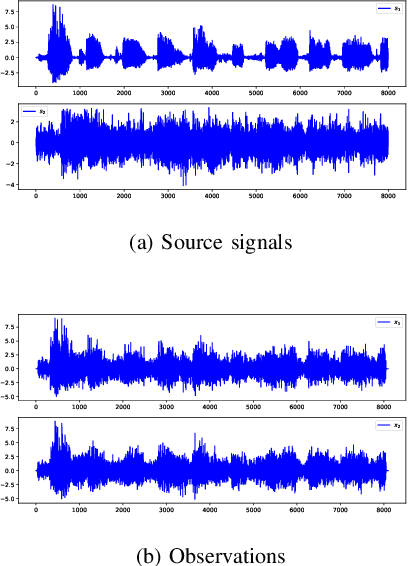
Convolutive blind source separation (BSS) is intended to recover the unknown components from their convolutive mixtures. Contrary to the contrast functions used in instantaneous cases, the spatial-temporal prewhitening stage and the para-unitary filters constraint are difficult to implement in a convolutive context. In this paper, we propose several modifications of FastICA to alleviate these difficulties. Our method performs the simple prewhitening step on convolutive mixtures prior to the separation and optimizes the contrast function under the diagonalization constraint implemented by single value decomposition (SVD). Numerical simulations are implemented to verify the performance of the proposed method.
Boosting in Univariate Nonparametric Maximum Likelihood Estimation
Jan 21, 2021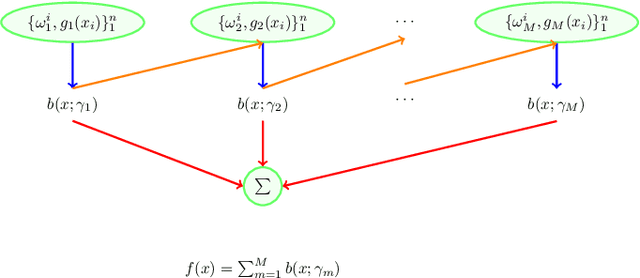
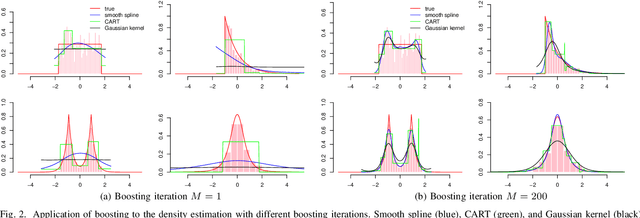
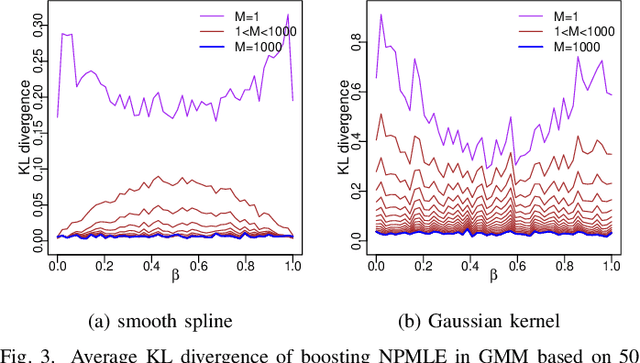
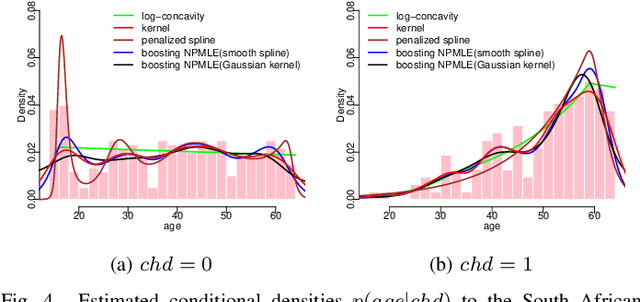
Nonparametric maximum likelihood estimation is intended to infer the unknown density distribution while making as few assumptions as possible. To alleviate the over parameterization in nonparametric data fitting, smoothing assumptions are usually merged into the estimation. In this paper a novel boosting-based method is introduced to the nonparametric estimation in univariate cases. We deduce the boosting algorithm by the second-order approximation of nonparametric log-likelihood. Gaussian kernel and smooth spline are chosen as weak learners in boosting to satisfy the smoothing assumptions. Simulations and real data experiments demonstrate the efficacy of the proposed approach.