 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Reading, Fast and Slow: When Do Models "Understand" Language?
Sep 15, 2022

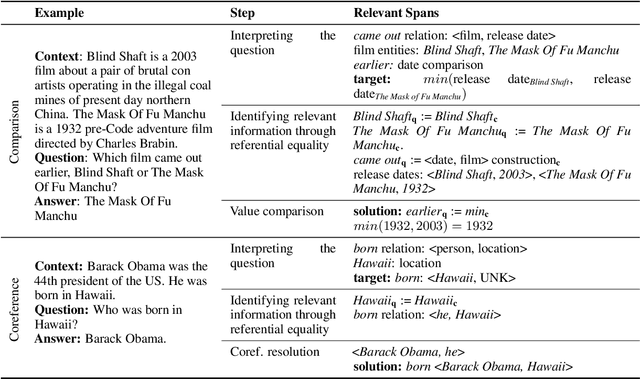
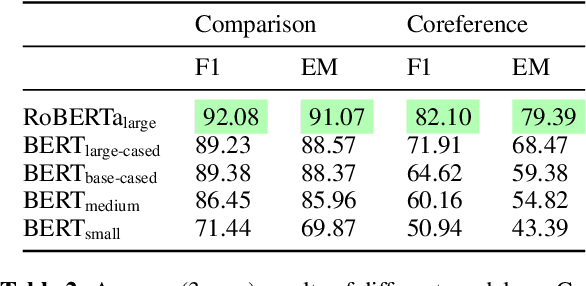

Two of the most fundamental challenges in Natural Language Understanding (NLU) at present are: (a) how to establish whether deep learning-based models score highly on NLU benchmarks for the 'right' reasons; and (b) to understand what those reasons would even be. We investigate the behavior of reading comprehension models with respect to two linguistic 'skills': coreference resolution and comparison. We propose a definition for the reasoning steps expected from a system that would be 'reading slowly', and compare that with the behavior of five models of the BERT family of various sizes, observed through saliency scores and counterfactual explanations. We find that for comparison (but not coreference) the systems based on larger encoders are more likely to rely on the 'right' information, but even they struggle with generalization, suggesting that they still learn specific lexical patterns rather than the general principles of comparison.
SLAMER: Simultaneous Localization and Map-Assisted Environment Recognition
Jul 20, 2022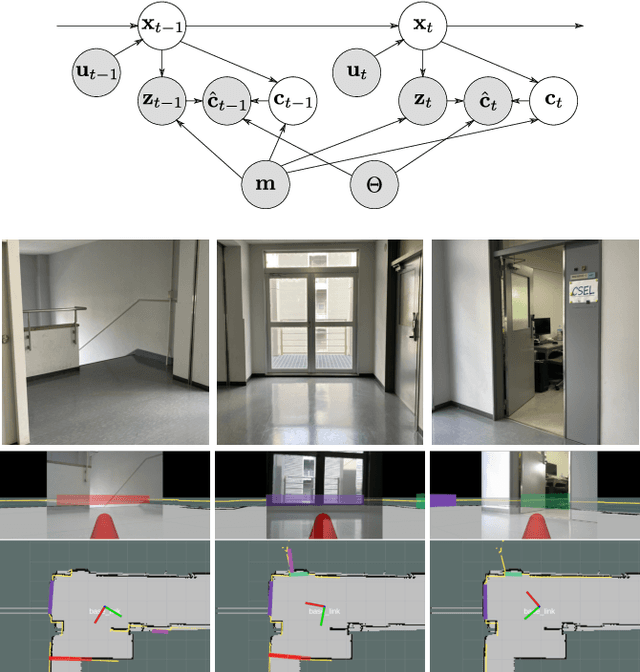

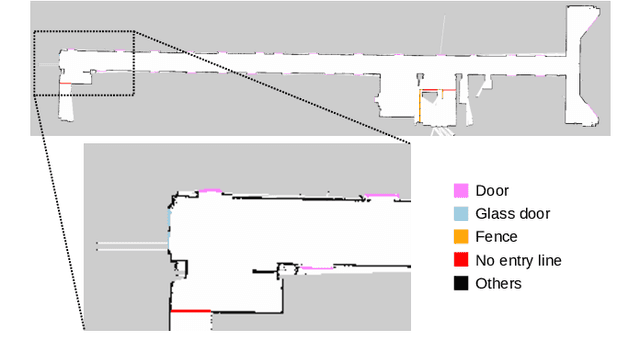
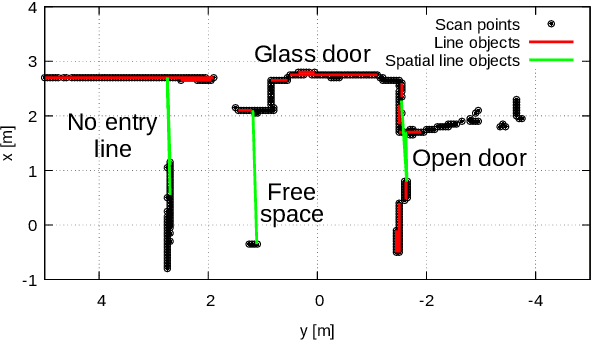
This paper presents a simultaneous localization and map-assisted environment recognition (SLAMER) method. Mobile robots usually have an environment map and environment information can be assigned to the map. Important information for mobile robots such as no entry zone can be predicted if localization has succeeded since relative pose of them can be known. However, this prediction is failed when localization does not work. Uncertainty of pose estimate must be considered for robustly using the map information. In addition, robots have external sensors and environment information can be recognized using the sensors. This on-line recognition of course contains uncertainty; however, it has to be fused with the map information for robust environment recognition since the map also contains uncertainty owing to over time. SLAMER can simultaneously cope with these uncertainties and achieves accurate localization and environment recognition. In this paper, we demonstrate LiDAR-based implementation of SLAMER in two cases. In the first case, we use the SemanticKITTI dataset and show that SLAMER achieves accurate estimate more than traditional methods. In the second case, we use an indoor mobile robot and show that unmeasurable environmental objects such as open doors and no entry lines can be recognized.
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Aug 02, 2021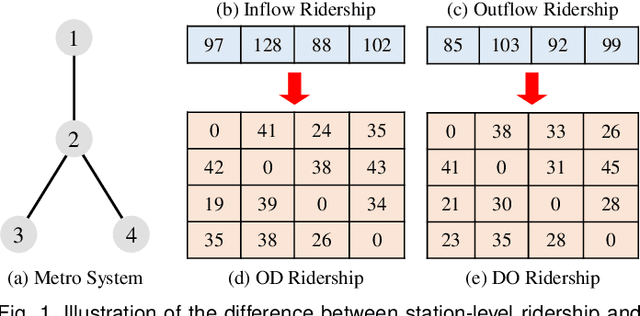
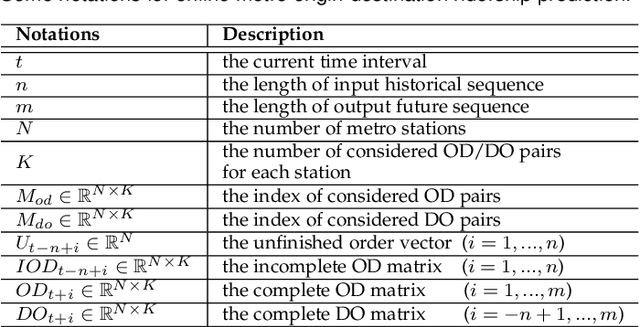
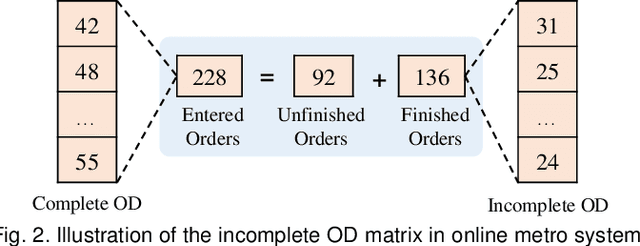
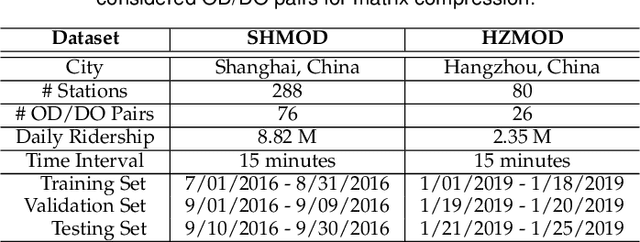
Metro origin-destination prediction is a crucial yet challenging time-series analysis task in intelligent transportation systems, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
Adaptive QoS of WebRTC for Vehicular Media Communications
Aug 24, 2022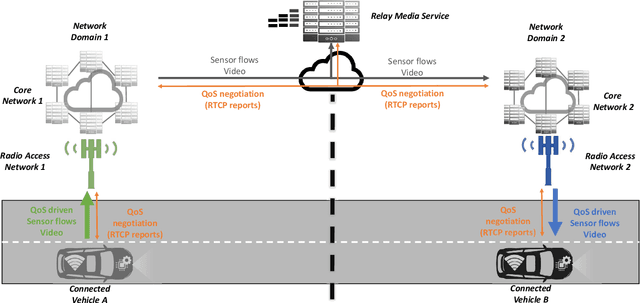
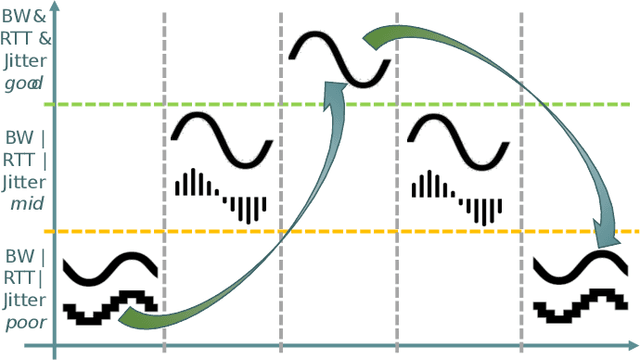


Vehicles shipping sensors for onboard systems are gaining connectivity. This enables information sharing to realize a more comprehensive understanding of the environment. However, peer communication through public cellular networks brings multiple networking hurdles to address, needing in-network systems to relay communications and connect parties that cannot connect directly. Web Real-Time Communication (WebRTC) is a good candidate for media streaming across vehicles as it enables low latency communications, while bringing standard protocols to security handshake, discovering public IPs and transverse Network Address Translation (NAT) systems. However, the end-to-end Quality of Service (QoS) adaptation in an infrastructure where transmission and reception are decoupled by a relay, needs a mechanism to adapt the video stream to the network capacity efficiently. To this end, this paper investigates a mechanism to apply changes on resolution, framerate and bitrate by exploiting the Real Time Transport Control Protocol (RTCP) metrics, such as bandwidth and round-trip time. The solution aims to ensure that the receiving onboard system gets relevant information in time. The impact on end-to-end throughput efficiency and reaction time when applying different approaches to QoS adaptation are analyzed in a real 5G testbed.
Continuous-Aperture MIMO for Electromagnetic Information Theory
Nov 16, 2021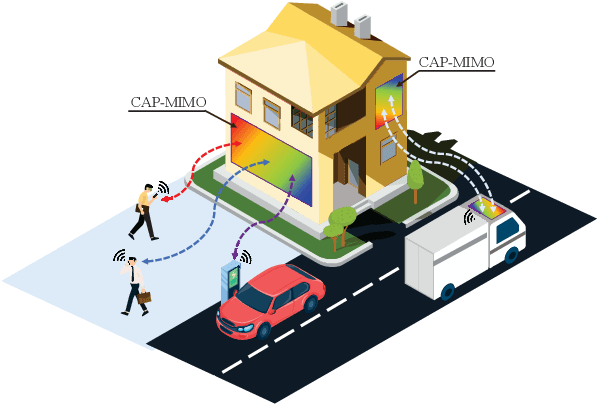
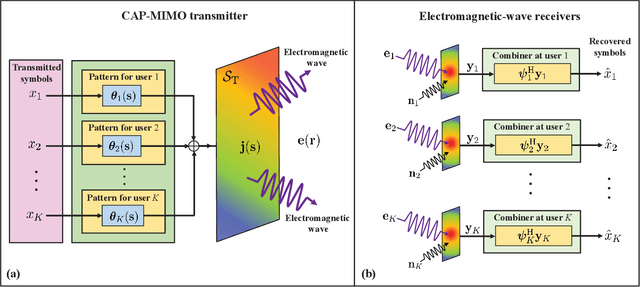
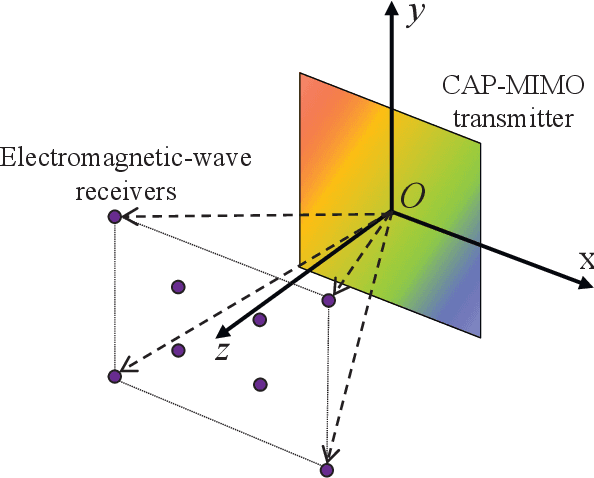
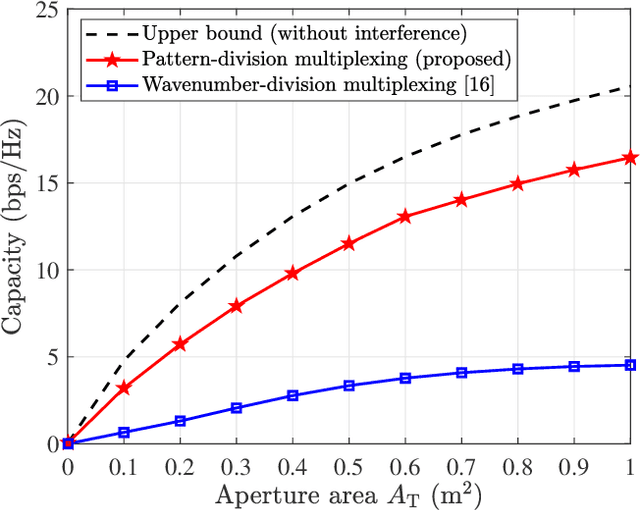
In recent years, the concept of continuous-aperture MIMO (CAP-MIMO) is reinvestigated to achieve improved communication performance with limited antenna apertures. Unlike the classical MIMO composed of discrete antennas, CAP-MIMO has a continuous antenna surface, which is expected to generate any current distribution (i.e., pattern) and induce controllable spatial electromagnetic waves. In this way, the information can be modulated on the electromagnetic waves, which makes it promising to approach the ultimate capacity of finite apertures. The pattern design is the key factor to determine the system performance of CAP-MIMO, but it has not been well studied in the literature. In this paper, we propose the pattern-division multiplexing to design the patterns for CAP-MIMO. Specifically, we first derive the system model of a typical CAP-MIMO system, which allows us to formulate the capacity maximization problem. Then we propose a general pattern-division multiplexing technique to transform the design of continuous pattern functions to the design of their projection lengths on finite orthogonal bases, which is able to overcome the design challenge of continuous functions. Based on this technique, we further propose an alternating optimization based pattern design scheme to solve the formulated capacity maximization problem. Simulation results show that, the capacity achieved by the proposed scheme is about 260% higher than that achieved by the benchmark scheme, which demonstrates the effectiveness of the proposed pattern-division multiplexing for CAP-MIMO.
Voxurf: Voxel-based Efficient and Accurate Neural Surface Reconstruction
Aug 29, 2022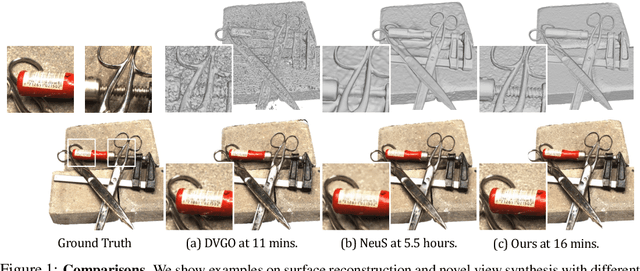
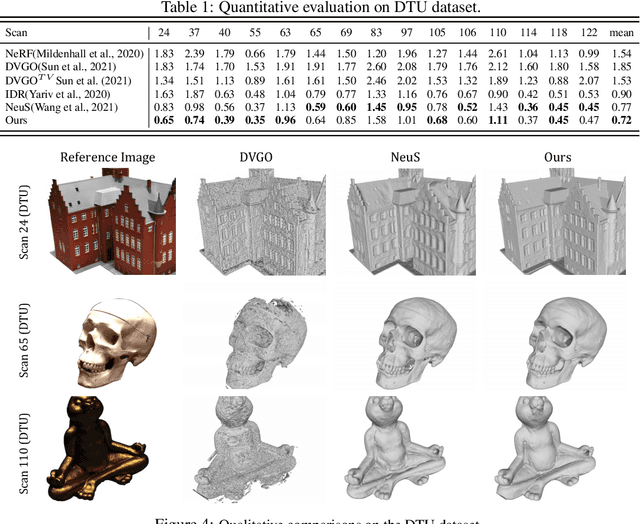

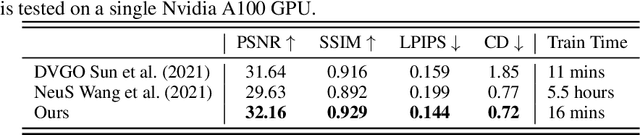
Neural surface reconstruction aims to reconstruct accurate 3D surfaces based on multi-view images. Previous methods based on neural volume rendering mostly train a fully implicit model, and they require hours of training for a single scene. Recent efforts explore the explicit volumetric representation, which substantially accelerates the optimization process by memorizing significant information in learnable voxel grids. However, these voxel-based methods often struggle in reconstructing fine-grained geometry. Through empirical studies, we found that high-quality surface reconstruction hinges on two key factors: the capability of constructing a coherent shape and the precise modeling of color-geometry dependency. In particular, the latter is the key to the accurate reconstruction of fine details. Inspired by these findings, we develop Voxurf, a voxel-based approach for efficient and accurate neural surface reconstruction, which consists of two stages: 1) leverage a learnable feature grid to construct the color field and obtain a coherent coarse shape, and 2) refine detailed geometry with a dual color network that captures precise color-geometry dependency. We further introduce a hierarchical geometry feature to enable information sharing across voxels. Our experiments show that Voxurf achieves high efficiency and high quality at the same time. On the DTU benchmark, Voxurf achieves higher reconstruction quality compared to state-of-the-art methods, with 20x speedup in training.
Translation, Scale and Rotation: Cross-Modal Alignment Meets RGB-Infrared Vehicle Detection
Sep 28, 2022
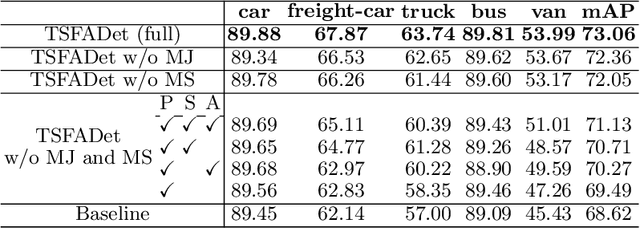
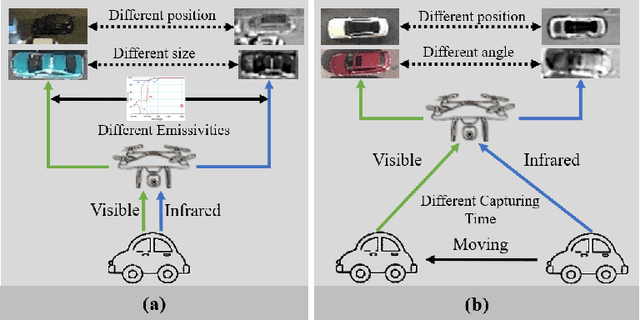

Integrating multispectral data in object detection, especially visible and infrared images, has received great attention in recent years. Since visible (RGB) and infrared (IR) images can provide complementary information to handle light variations, the paired images are used in many fields, such as multispectral pedestrian detection, RGB-IR crowd counting and RGB-IR salient object detection. Compared with natural RGB-IR images, we find detection in aerial RGB-IR images suffers from cross-modal weakly misalignment problems, which are manifested in the position, size and angle deviations of the same object. In this paper, we mainly address the challenge of cross-modal weakly misalignment in aerial RGB-IR images. Specifically, we firstly explain and analyze the cause of the weakly misalignment problem. Then, we propose a Translation-Scale-Rotation Alignment (TSRA) module to address the problem by calibrating the feature maps from these two modalities. The module predicts the deviation between two modality objects through an alignment process and utilizes Modality-Selection (MS) strategy to improve the performance of alignment. Finally, a two-stream feature alignment detector (TSFADet) based on the TSRA module is constructed for RGB-IR object detection in aerial images. With comprehensive experiments on the public DroneVehicle datasets, we verify that our method reduces the effect of the cross-modal misalignment and achieve robust detection results.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 16, 2022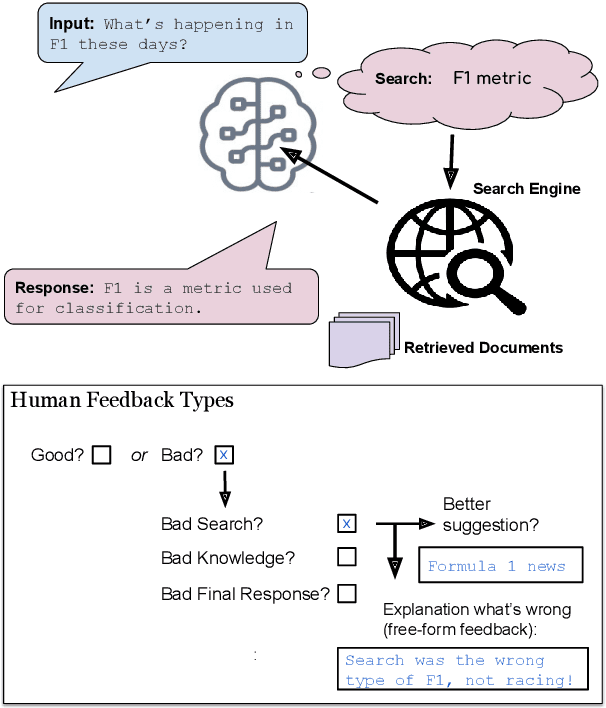
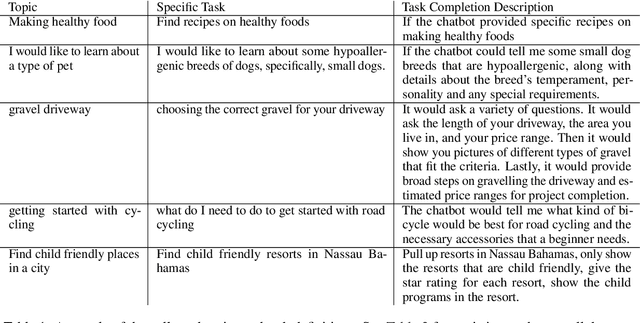
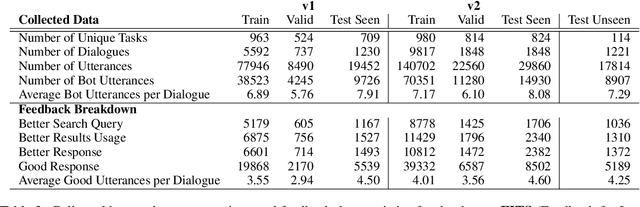
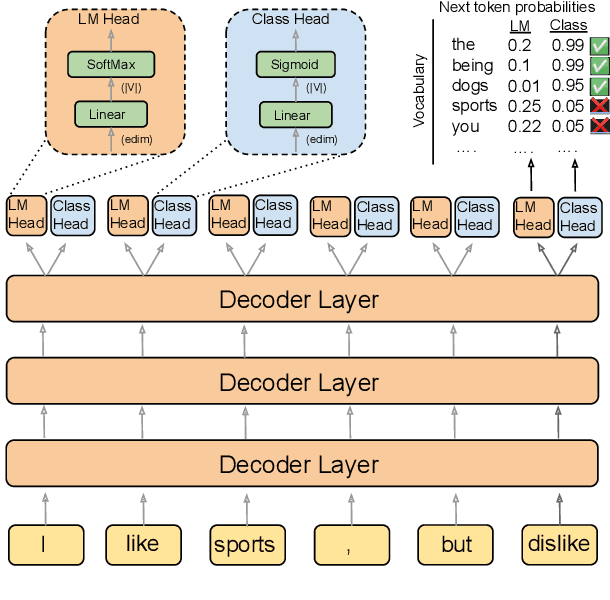
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.
Grad-Align+: Empowering Gradual Network Alignment Using Attribute Augmentation
Aug 24, 2022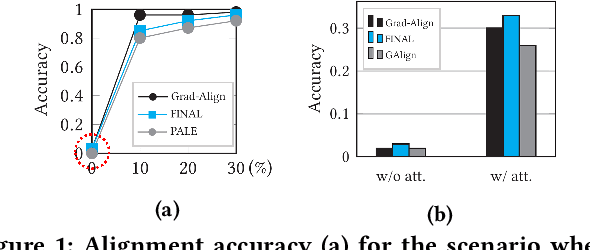
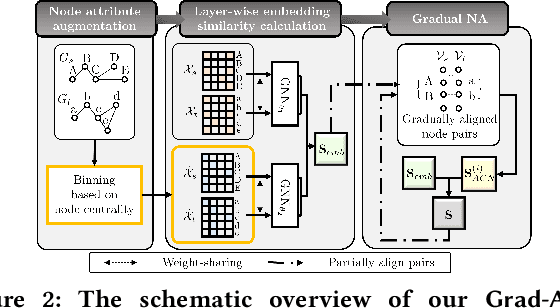
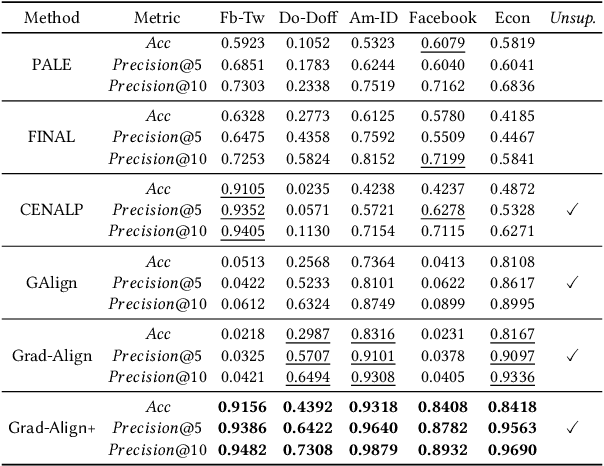
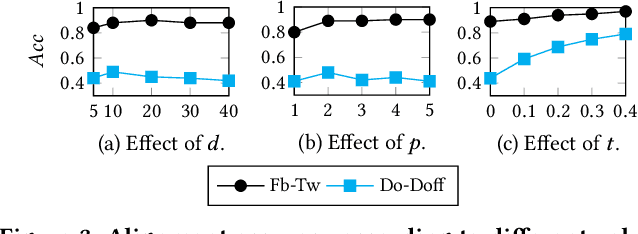
Network alignment (NA) is the task of discovering node correspondences across different networks. Although NA methods have achieved remarkable success in a myriad of scenarios, their satisfactory performance is not without prior anchor link information and/or node attributes, which may not always be available. In this paper, we propose Grad-Align+, a novel NA method using node attribute augmentation that is quite robust to the absence of such additional information. Grad-Align+ is built upon a recent state-of-the-art NA method, the so-called Grad-Align, that gradually discovers only a part of node pairs until all node pairs are found. Specifically, Grad-Align+ is composed of the following key components: 1) augmenting node attributes based on nodes' centrality measures, 2) calculating an embedding similarity matrix extracted from a graph neural network into which the augmented node attributes are fed, and 3) gradually discovering node pairs by calculating similarities between cross-network nodes with respect to the aligned cross-network neighbor-pair. Experimental results demonstrate that Grad-Align+ exhibits (a) superiority over benchmark NA methods, (b) empirical validation of our theoretical findings, and (c) the effectiveness of our attribute augmentation module.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
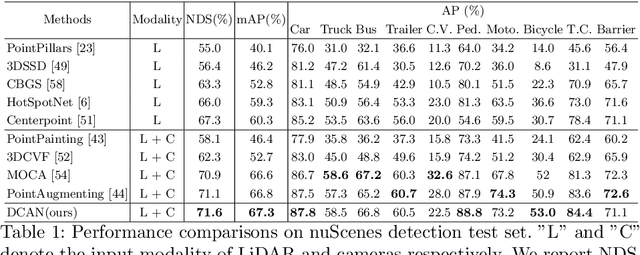
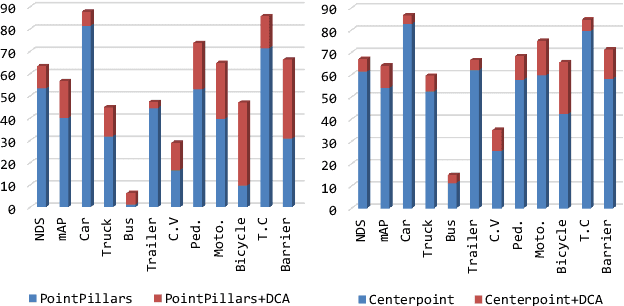
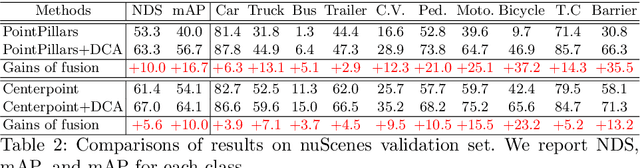
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.