 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attribute Inference Attacks in Online Multiplayer Video Games: a Case Study on Dota2
Oct 17, 2022
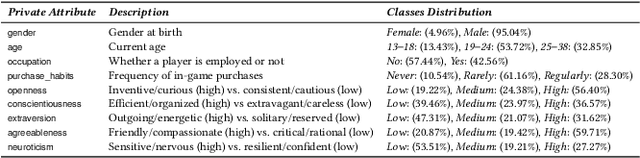
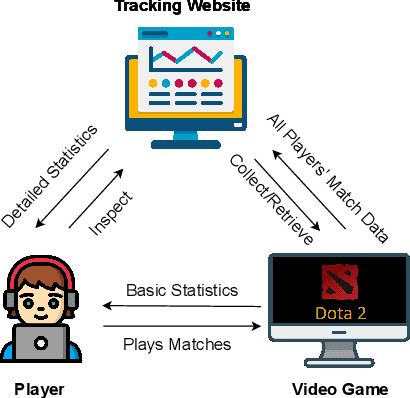
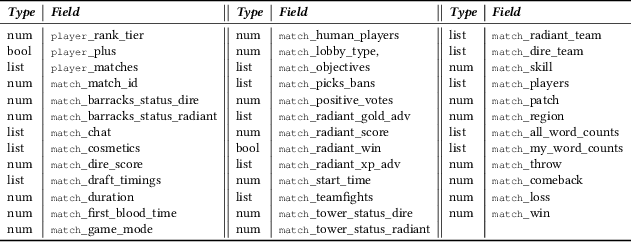
Did you know that over 70 million of Dota2 players have their in-game data freely accessible? What if such data is used in malicious ways? This paper is the first to investigate such a problem. Motivated by the widespread popularity of video games, we propose the first threat model for Attribute Inference Attacks (AIA) in the Dota2 context. We explain how (and why) attackers can exploit the abundant public data in the Dota2 ecosystem to infer private information about its players. Due to lack of concrete evidence on the efficacy of our AIA, we empirically prove and assess their impact in reality. By conducting an extensive survey on $\sim$500 Dota2 players spanning over 26k matches, we verify whether a correlation exists between a player's Dota2 activity and their real-life. Then, after finding such a link ($p\!<\!0.01$ and $\rho>0.3$), we ethically perform diverse AIA. We leverage the capabilities of machine learning to infer real-life attributes of the respondents of our survey by using their publicly available in-game data. Our results show that, by applying domain expertise, some AIA can reach up to 98% precision and over 90% accuracy. This paper hence raises the alarm on a subtle, but concrete threat that can potentially affect the entire competitive gaming landscape. We alerted the developers of Dota2.
GeoThermalCloud: Machine Learning for Geothermal Resource Exploration
Oct 17, 2022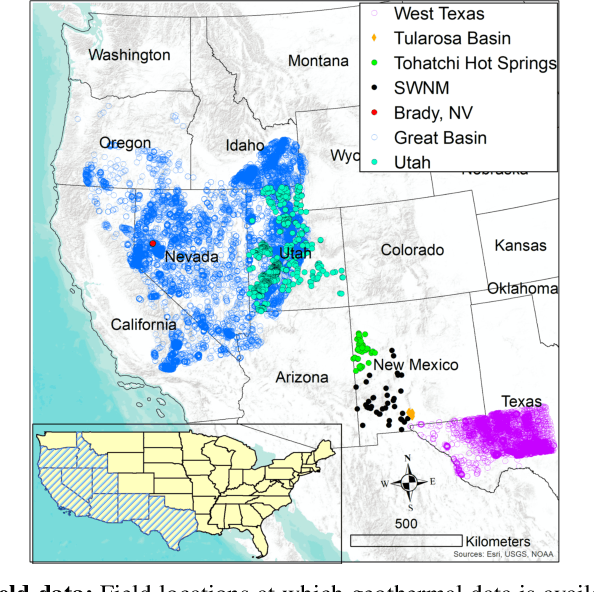
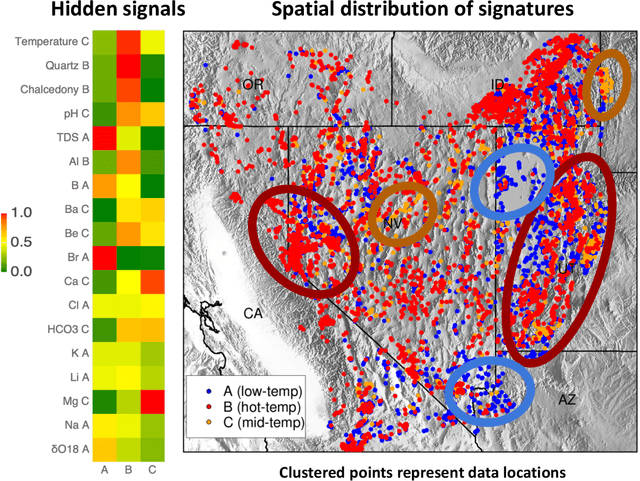
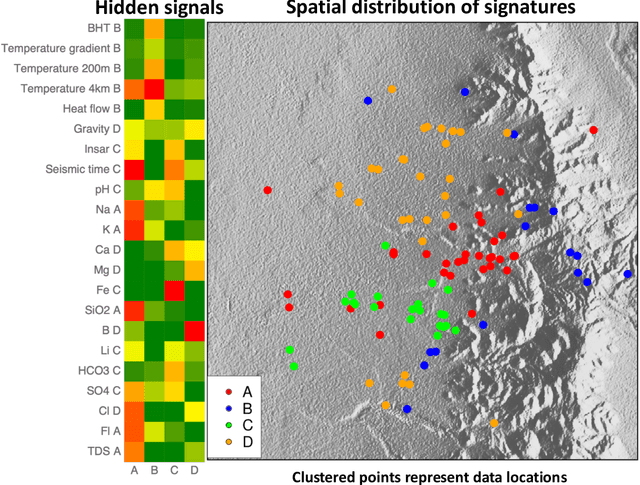
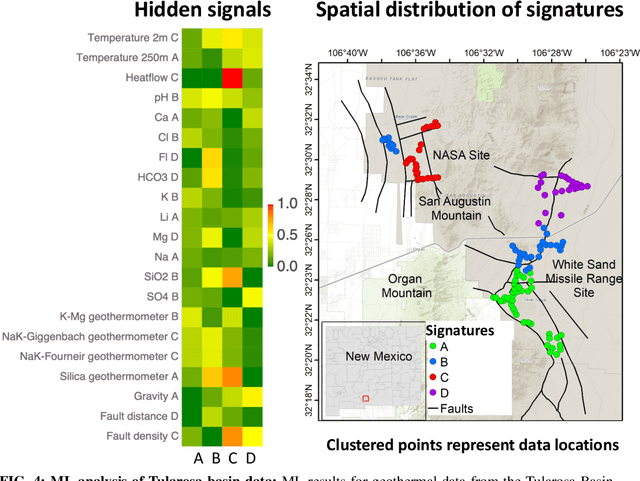
This paper presents a novel ML-based methodology for geothermal exploration towards PFA applications. Our methodology is provided through our open-source ML framework, GeoThermalCloud \url{https://github.com/SmartTensors/GeoThermalCloud.jl}. The GeoThermalCloud uses a series of unsupervised, supervised, and physics-informed ML methods available in SmartTensors AI platform \url{https://github.com/SmartTensors}. Here, the presented analyses are performed using our unsupervised ML algorithm called NMF$k$, which is available in the SmartTensors AI platform. Our ML algorithm facilitates the discovery of new phenomena, hidden patterns, and mechanisms that helps us to make informed decisions. Moreover, the GeoThermalCloud enhances the collected PFA data and discovers signatures representative of geothermal resources. Through GeoThermalCloud, we could identify hidden patterns in the geothermal field data needed to discover blind systems efficiently. Crucial geothermal signatures often overlooked in traditional PFA are extracted using the GeoThermalCloud and analyzed by the subject matter experts to provide ML-enhanced PFA, which is informative for efficient exploration. We applied our ML methodology to various open-source geothermal datasets within the U.S. (some of these are collected by past PFA work). The results provide valuable insights into resource types within those regions. This ML-enhanced workflow makes the GeoThermalCloud attractive for the geothermal community to improve existing datasets and extract valuable information often unnoticed during geothermal exploration.
Histopathological Image Classification based on Self-Supervised Vision Transformer and Weak Labels
Oct 17, 2022Whole Slide Image (WSI) analysis is a powerful method to facilitate the diagnosis of cancer in tissue samples. Automating this diagnosis poses various issues, most notably caused by the immense image resolution and limited annotations. WSIs commonly exhibit resolutions of 100Kx100K pixels. Annotating cancerous areas in WSIs on the pixel level is prohibitively labor-intensive and requires a high level of expert knowledge. Multiple instance learning (MIL) alleviates the need for expensive pixel-level annotations. In MIL, learning is performed on slide-level labels, in which a pathologist provides information about whether a slide includes cancerous tissue. Here, we propose Self-ViT-MIL, a novel approach for classifying and localizing cancerous areas based on slide-level annotations, eliminating the need for pixel-wise annotated training data. Self-ViT- MIL is pre-trained in a self-supervised setting to learn rich feature representation without relying on any labels. The recent Vision Transformer (ViT) architecture builds the feature extractor of Self-ViT-MIL. For localizing cancerous regions, a MIL aggregator with global attention is utilized. To the best of our knowledge, Self-ViT- MIL is the first approach to introduce self-supervised ViTs in MIL-based WSI analysis tasks. We showcase the effectiveness of our approach on the common Camelyon16 dataset. Self-ViT-MIL surpasses existing state-of-the-art MIL-based approaches in terms of accuracy and area under the curve (AUC).
Resource Allocation for Mobile Metaverse with the Internet of Vehicles over 6G Wireless Communications: A Deep Reinforcement Learning Approach
Sep 27, 2022
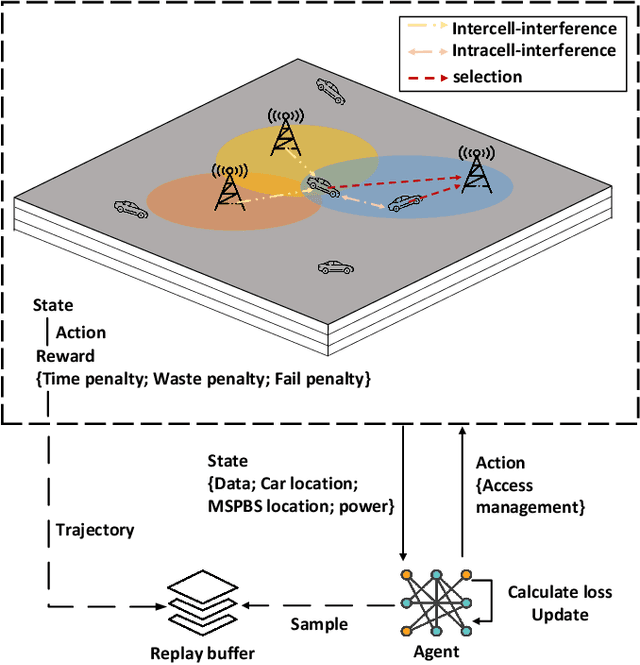
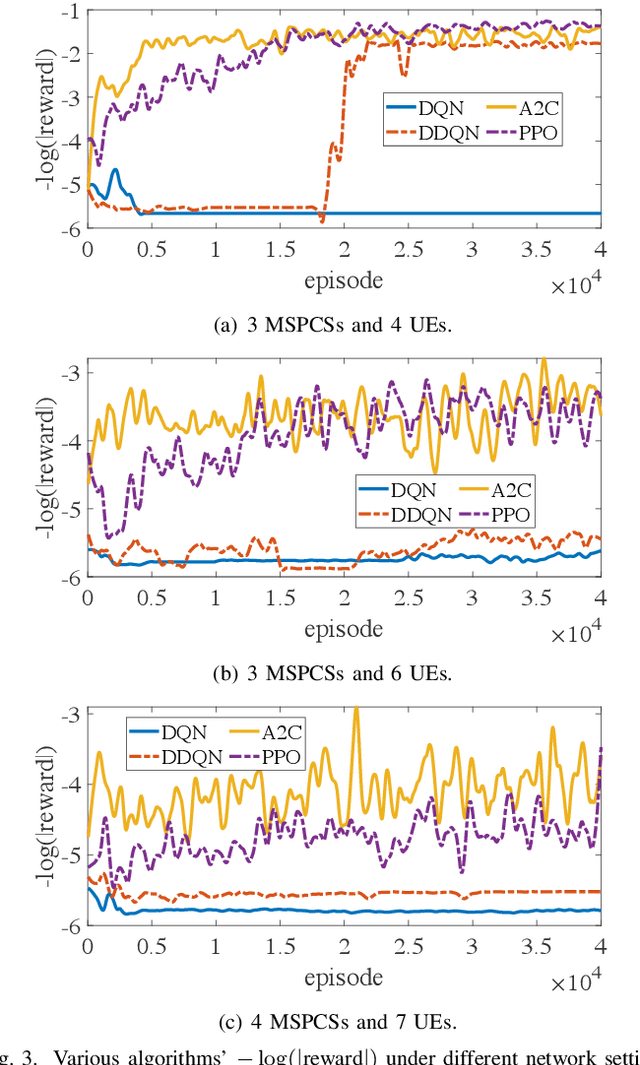
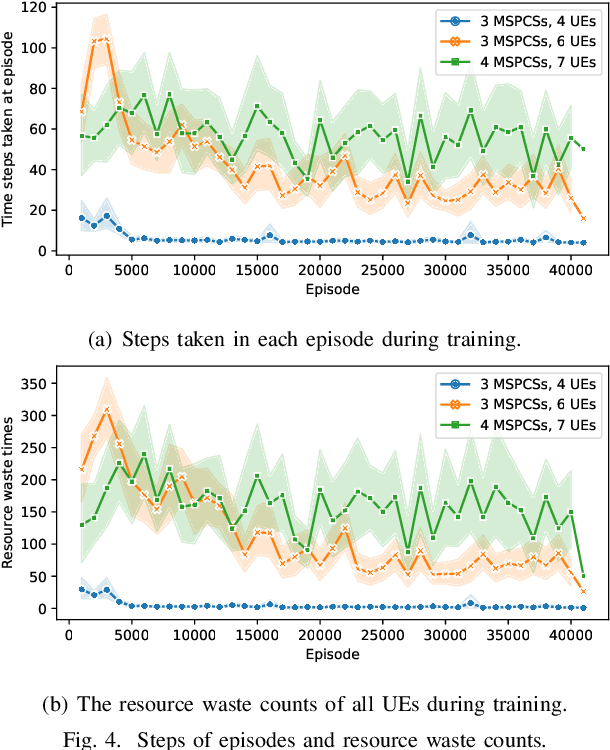
Improving the interactivity and interconnectivity between people is one of the highlights of the Metaverse. The Metaverse relies on a core approach, digital twinning, which is a means to replicate physical world objects, people, actions and scenes onto the virtual world. Being able to access scenes and information associated with the physical world, in the Metaverse in real-time and under mobility, is essential in developing a highly accessible, interactive and interconnective experience for all users. This development allows users from other locations to access high-quality real-world and up-to-date information about events happening in another location, and socialize with others hyper-interactively. Nevertheless, receiving continual, smooth updates generated by others from the Metaverse is a challenging task due to the large data size of the virtual world graphics and the need for low latency transmission. With the development of Mobile Augmented Reality (MAR), users can interact via the Metaverse in a highly interactive manner, even under mobility. Hence in our work, we considered an environment with users in moving Internet of Vehicles (IoV), downloading real-time virtual world updates from Metaverse Service Provider Cell Stations (MSPCSs) via wireless communications. We design an environment with multiple cell stations, where there will be a handover of users' virtual world graphic download tasks between cell stations. As transmission latency is the primary concern in receiving virtual world updates under mobility, our work aims to allocate system resources to minimize the total time taken for users in vehicles to download their virtual world scenes from the cell stations. We utilize deep reinforcement learning and evaluate the performance of the algorithms under different environmental configurations. Our work provides a use case of the Metaverse over AI-enabled 6G communications.
Human Activity Recognition using Attribute-Based Neural Networks and Context Information
Oct 28, 2021
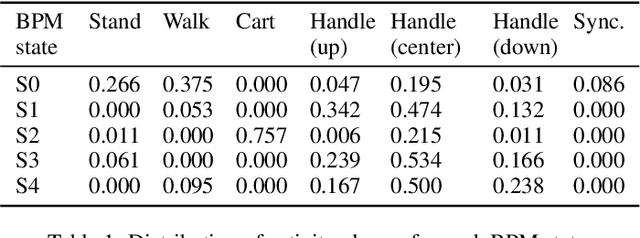
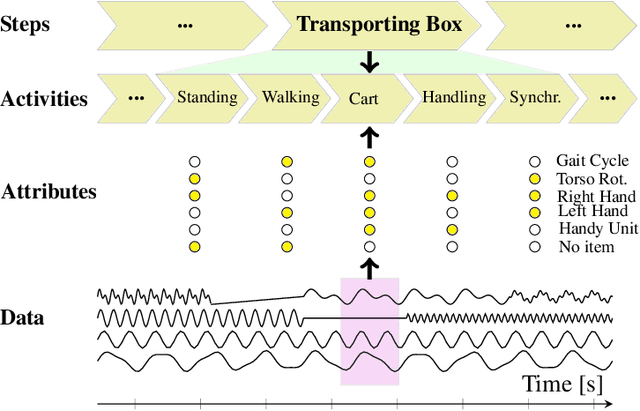
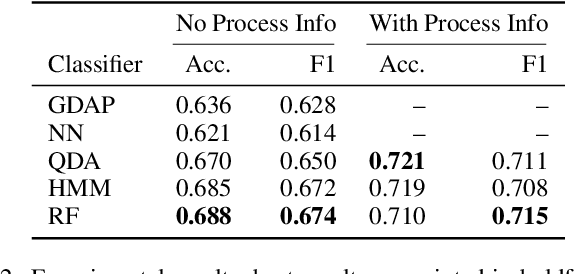
We consider human activity recognition (HAR) from wearable sensor data in manual-work processes, like warehouse order-picking. Such structured domains can often be partitioned into distinct process steps, e.g., packaging or transporting. Each process step can have a different prior distribution over activity classes, e.g., standing or walking, and different system dynamics. Here, we show how such context information can be integrated systematically into a deep neural network-based HAR system. Specifically, we propose a hybrid architecture that combines a deep neural network-that estimates high-level movement descriptors, attributes, from the raw-sensor data-and a shallow classifier, which predicts activity classes from the estimated attributes and (optional) context information, like the currently executed process step. We empirically show that our proposed architecture increases HAR performance, compared to state-of-the-art methods. Additionally, we show that HAR performance can be further increased when information about process steps is incorporated, even when that information is only partially correct.
Grounded Video Situation Recognition
Oct 19, 2022
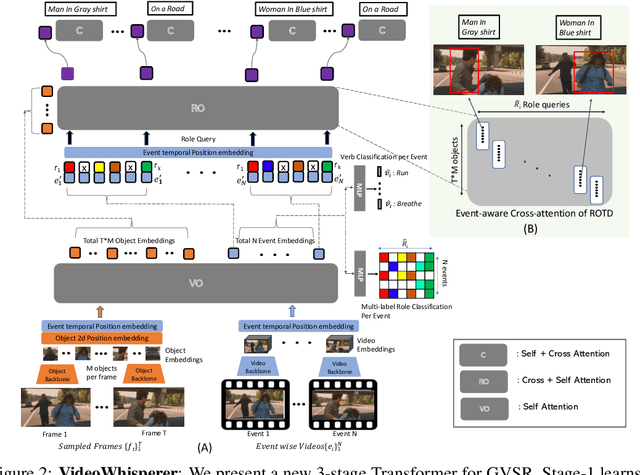


Dense video understanding requires answering several questions such as who is doing what to whom, with what, how, why, and where. Recently, Video Situation Recognition (VidSitu) is framed as a task for structured prediction of multiple events, their relationships, and actions and various verb-role pairs attached to descriptive entities. This task poses several challenges in identifying, disambiguating, and co-referencing entities across multiple verb-role pairs, but also faces some challenges of evaluation. In this work, we propose the addition of spatio-temporal grounding as an essential component of the structured prediction task in a weakly supervised setting, and present a novel three stage Transformer model, VideoWhisperer, that is empowered to make joint predictions. In stage one, we learn contextualised embeddings for video features in parallel with key objects that appear in the video clips to enable fine-grained spatio-temporal reasoning. The second stage sees verb-role queries attend and pool information from object embeddings, localising answers to questions posed about the action. The final stage generates these answers as captions to describe each verb-role pair present in the video. Our model operates on a group of events (clips) simultaneously and predicts verbs, verb-role pairs, their nouns, and their grounding on-the-fly. When evaluated on a grounding-augmented version of the VidSitu dataset, we observe a large improvement in entity captioning accuracy, as well as the ability to localize verb-roles without grounding annotations at training time.
DyTed: Disentangling Temporal Invariance and Fluctuations in Dynamic Graph Representation Learning
Oct 19, 2022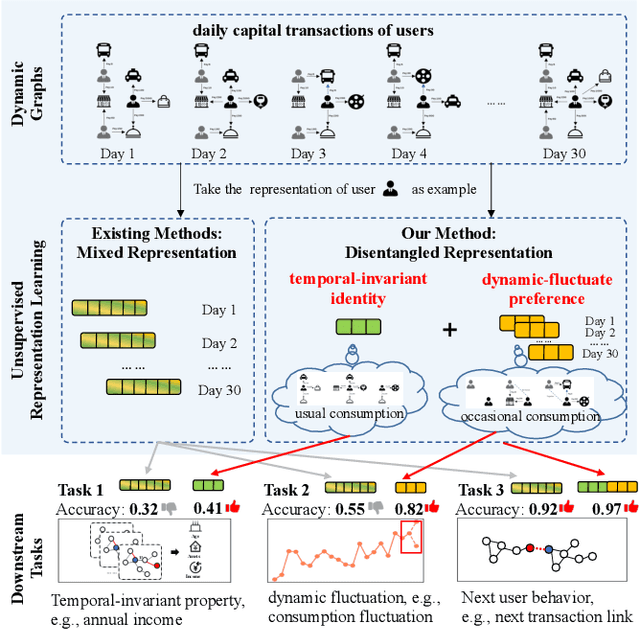
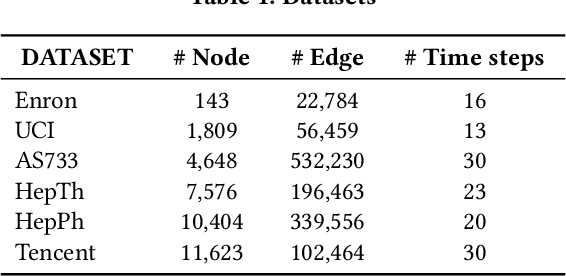
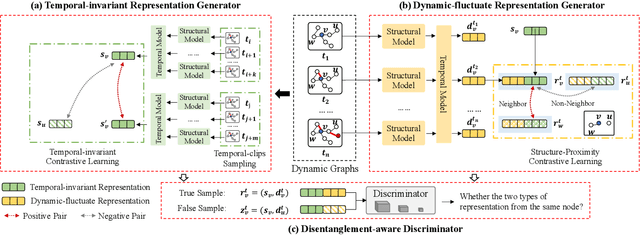
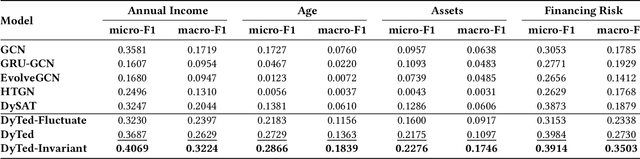
Unsupervised representation learning for dynamic graphs has attracted a lot of research attention in recent years. Compared with static graphs, dynamic graphs are the integrative reflection of both the temporal-invariant or stable characteristics of nodes and the dynamic-fluctuate preference changing with time. However, existing dynamic graph representation learning methods generally confound these two types of information into a shared representation space, which may lead to poor explanation, less robustness, and a limited ability when applied to different downstream tasks. Taking the real dynamic graphs of daily capital transactions on Tencent as an example, the learned representation of the state-of-the-art method achieves only 32% accuracy in predicting temporal-invariant characteristics of users like annual income. In this paper, we introduce a novel temporal invariance-fluctuation disentangled representation learning framework for dynamic graphs, namely DyTed. In particular, we propose a temporal-invariant representation generator and a dynamic-fluctuate representation generator with carefully designed pretext tasks to identify the two types of representations in dynamic graphs. To further enhance the disentanglement or separation, we propose a disentanglement-aware discriminator under an adversarial learning framework. Extensive experiments on Tencent and five commonly used public datasets demonstrate that the different parts of our disentangled representation can achieve state-of-the-art performance on various downstream tasks, as well as be more robust against noise, and is a general framework that can further improve existing methods.
AdvDrop: Adversarial Attack to DNNs by Dropping Information
Aug 20, 2021


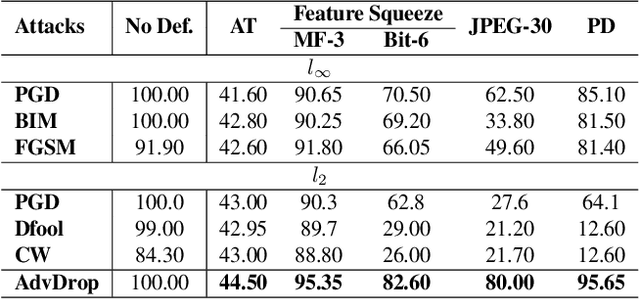
Human can easily recognize visual objects with lost information: even losing most details with only contour reserved, e.g. cartoon. However, in terms of visual perception of Deep Neural Networks (DNNs), the ability for recognizing abstract objects (visual objects with lost information) is still a challenge. In this work, we investigate this issue from an adversarial viewpoint: will the performance of DNNs decrease even for the images only losing a little information? Towards this end, we propose a novel adversarial attack, named \textit{AdvDrop}, which crafts adversarial examples by dropping existing information of images. Previously, most adversarial attacks add extra disturbing information on clean images explicitly. Opposite to previous works, our proposed work explores the adversarial robustness of DNN models in a novel perspective by dropping imperceptible details to craft adversarial examples. We demonstrate the effectiveness of \textit{AdvDrop} by extensive experiments, and show that this new type of adversarial examples is more difficult to be defended by current defense systems.
Mushroom image recognition and distance generation based on attention-mechanism model and genetic information
Jun 27, 2022
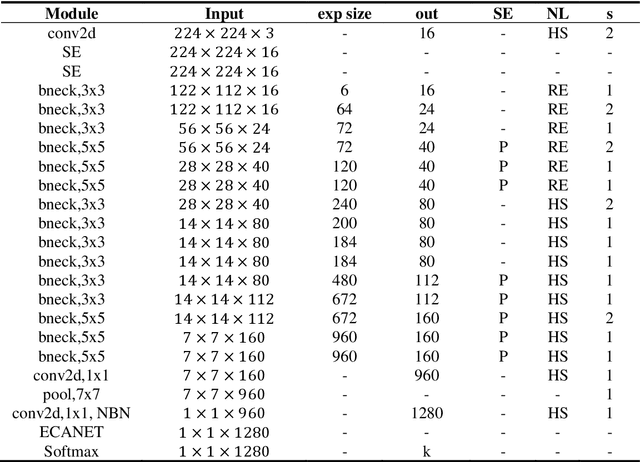

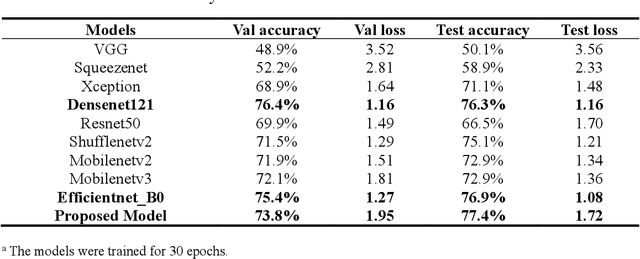
The species identification of Macrofungi, i.e. mushrooms, has always been a challenging task. There are still a large number of poisonous mushrooms that have not been found, which poses a risk to people's life. However, the traditional identification method requires a large number of experts with knowledge in the field of taxonomy for manual identification, it is not only inefficient but also consumes a lot of manpower and capital costs. In this paper, we propose a new model based on attention-mechanism, MushroomNet, which applies the lightweight network MobileNetV3 as the backbone model, combined with the attention structure proposed by us, and has achieved excellent performance in the mushroom recognition task. On the public dataset, the test accuracy of the MushroomNet model has reached 83.9%, and on the local dataset, the test accuracy has reached 77.4%. The proposed attention mechanisms well focused attention on the bodies of mushroom image for mixed channel attention and the attention heat maps visualized by Grad-CAM. Further, in this study, genetic distance was added to the mushroom image recognition task, the genetic distance was used as the representation space, and the genetic distance between each pair of mushroom species in the dataset was used as the embedding of the genetic distance representation space, so as to predict the image distance and species. identify. We found that using the MES activation function can predict the genetic distance of mushrooms very well, but the accuracy is lower than that of SoftMax. The proposed MushroomNet was demonstrated it shows great potential for automatic and online mushroom image and the proposed automatic procedure would assist and be a reference to traditional mushroom classification.
Point Transformer V2: Grouped Vector Attention and Partition-based Pooling
Oct 12, 2022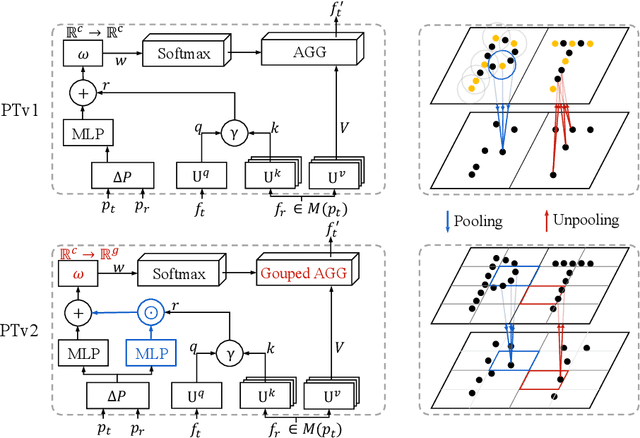
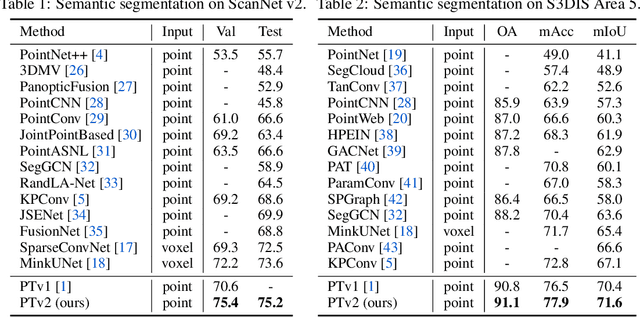


As a pioneering work exploring transformer architecture for 3D point cloud understanding, Point Transformer achieves impressive results on multiple highly competitive benchmarks. In this work, we analyze the limitations of the Point Transformer and propose our powerful and efficient Point Transformer V2 model with novel designs that overcome the limitations of previous work. In particular, we first propose group vector attention, which is more effective than the previous version of vector attention. Inheriting the advantages of both learnable weight encoding and multi-head attention, we present a highly effective implementation of grouped vector attention with a novel grouped weight encoding layer. We also strengthen the position information for attention by an additional position encoding multiplier. Furthermore, we design novel and lightweight partition-based pooling methods which enable better spatial alignment and more efficient sampling. Extensive experiments show that our model achieves better performance than its predecessor and achieves state-of-the-art on several challenging 3D point cloud understanding benchmarks, including 3D point cloud segmentation on ScanNet v2 and S3DIS and 3D point cloud classification on ModelNet40. Our code will be available at https://github.com/Gofinge/PointTransformerV2.