 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Shadows: Data Alignment, Parameter Footprints, and Generalization in Large Language Models
Apr 01, 2026Large language models often achieve strong benchmark gains without corresponding improvements in broader capability. We hypothesize that this discrepancy arises from differences in training regimes induced by data distribution. To investigate this, we design controlled data interventions that isolate distributional effects under fixed training settings. We find that benchmark-aligned data improves narrow evaluation metrics while limiting broader representational development, whereas coverage-expanding data leads to more distributed parameter adaptation and better generalization. We further introduce parameter-space diagnostics based on spectral and rank analyses, which reveal distinct structural signatures of these regimes. Similar patterns are observed across diverse open-source model families, including multimodal models as a key case study, suggesting that these effects extend beyond controlled settings. A case study on prompt repetition shows that not all data artifacts induce regime shifts. These results indicate that benchmark performance alone is insufficient to characterize model capability, and highlight the importance of data distribution in shaping learning dynamics.
DyTed: Disentangling Temporal Invariance and Fluctuations in Dynamic Graph Representation Learning
Oct 19, 2022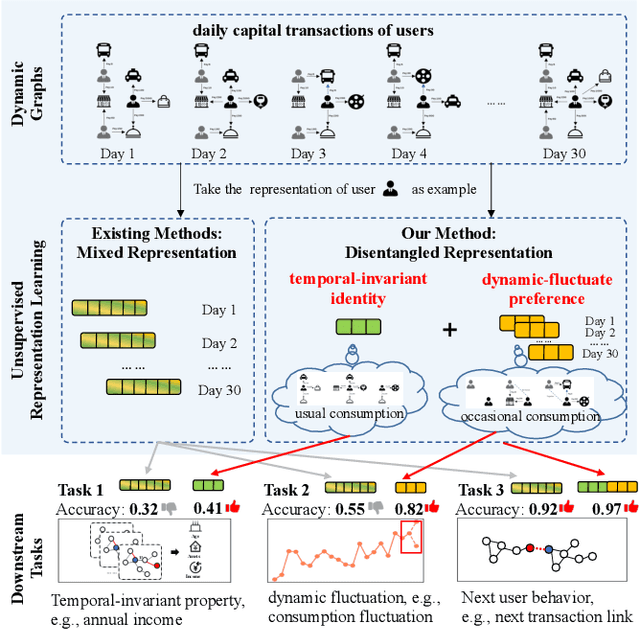
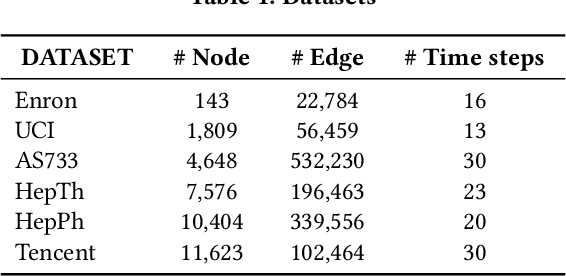
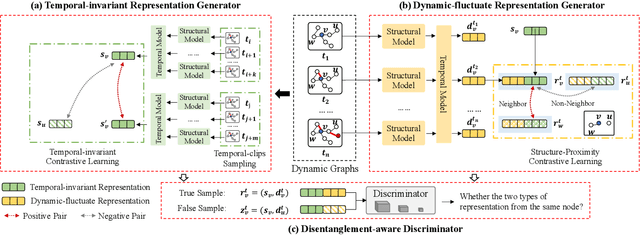
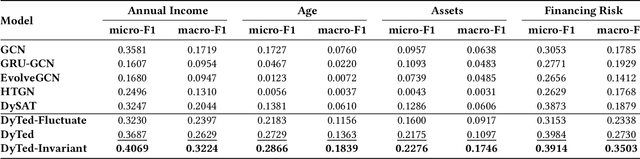
Unsupervised representation learning for dynamic graphs has attracted a lot of research attention in recent years. Compared with static graphs, dynamic graphs are the integrative reflection of both the temporal-invariant or stable characteristics of nodes and the dynamic-fluctuate preference changing with time. However, existing dynamic graph representation learning methods generally confound these two types of information into a shared representation space, which may lead to poor explanation, less robustness, and a limited ability when applied to different downstream tasks. Taking the real dynamic graphs of daily capital transactions on Tencent as an example, the learned representation of the state-of-the-art method achieves only 32% accuracy in predicting temporal-invariant characteristics of users like annual income. In this paper, we introduce a novel temporal invariance-fluctuation disentangled representation learning framework for dynamic graphs, namely DyTed. In particular, we propose a temporal-invariant representation generator and a dynamic-fluctuate representation generator with carefully designed pretext tasks to identify the two types of representations in dynamic graphs. To further enhance the disentanglement or separation, we propose a disentanglement-aware discriminator under an adversarial learning framework. Extensive experiments on Tencent and five commonly used public datasets demonstrate that the different parts of our disentangled representation can achieve state-of-the-art performance on various downstream tasks, as well as be more robust against noise, and is a general framework that can further improve existing methods.