 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposeAnything: Composite Object Priors for Text-to-Image Generation
May 30, 2025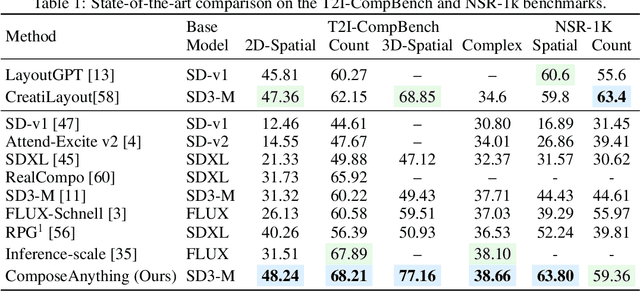
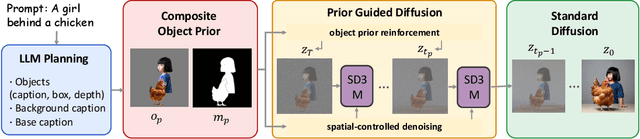
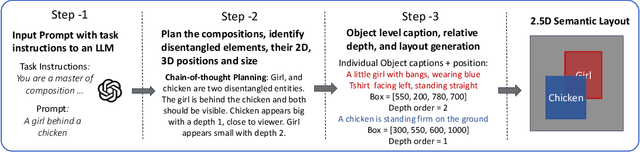
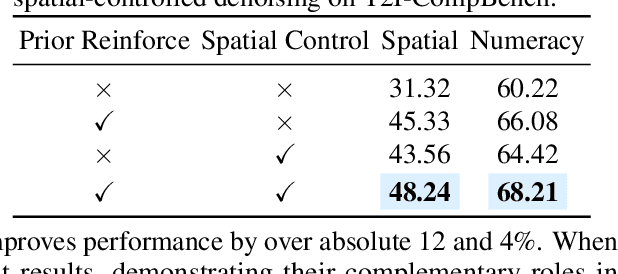
Generating images from text involving complex and novel object arrangements remains a significant challenge for current text-to-image (T2I) models. Although prior layout-based methods improve object arrangements using spatial constraints with 2D layouts, they often struggle to capture 3D positioning and sacrifice quality and coherence. In this work, we introduce ComposeAnything, a novel framework for improving compositional image generation without retraining existing T2I models. Our approach first leverages the chain-of-thought reasoning abilities of LLMs to produce 2.5D semantic layouts from text, consisting of 2D object bounding boxes enriched with depth information and detailed captions. Based on this layout, we generate a spatial and depth aware coarse composite of objects that captures the intended composition, serving as a strong and interpretable prior that replaces stochastic noise initialization in diffusion-based T2I models. This prior guides the denoising process through object prior reinforcement and spatial-controlled denoising, enabling seamless generation of compositional objects and coherent backgrounds, while allowing refinement of inaccurate priors. ComposeAnything outperforms state-of-the-art methods on the T2I-CompBench and NSR-1K benchmarks for prompts with 2D/3D spatial arrangements, high object counts, and surreal compositions. Human evaluations further demonstrate that our model generates high-quality images with compositions that faithfully reflect the text.
Leveraging the Domain Adaptation of Retrieval Augmented Generation Models for Question Answering and Reducing Hallucination
Oct 23, 2024



While ongoing advancements in Large Language Models have demonstrated remarkable success across various NLP tasks, Retrieval Augmented Generation Model stands out to be highly effective on downstream applications like Question Answering. Recently, RAG-end2end model further optimized the architecture and achieved notable performance improvements on domain adaptation. However, the effectiveness of these RAG-based architectures remains relatively unexplored when fine-tuned on specialized domains such as customer service for building a reliable conversational AI system. Furthermore, a critical challenge persists in reducing the occurrence of hallucinations while maintaining high domain-specific accuracy. In this paper, we investigated the performance of diverse RAG and RAG-like architectures through domain adaptation and evaluated their ability to generate accurate and relevant response grounded in the contextual knowledge base. To facilitate the evaluation of the models, we constructed a novel dataset HotelConvQA, sourced from wide range of hotel-related conversations and fine-tuned all the models on our domain specific dataset. We also addressed a critical research gap on determining the impact of domain adaptation on reducing hallucinations across different RAG architectures, an aspect that was not properly measured in prior work. Our evaluation shows positive results in all metrics by employing domain adaptation, demonstrating strong performance on QA tasks and providing insights into their efficacy in reducing hallucinations. Our findings clearly indicate that domain adaptation not only enhances the models' performance on QA tasks but also significantly reduces hallucination across all evaluated RAG architectures.
VELOCITI: Can Video-Language Models Bind Semantic Concepts through Time?
Jun 16, 2024Compositionality is a fundamental aspect of vision-language understanding and is especially required for videos since they contain multiple entities (e.g. persons, actions, and scenes) interacting dynamically over time. Existing benchmarks focus primarily on perception capabilities. However, they do not study binding, the ability of a model to associate entities through appropriate relationships. To this end, we propose VELOCITI, a new benchmark building on complex movie clips and dense semantic role label annotations to test perception and binding in video language models (contrastive and Video-LLMs). Our perception-based tests require discriminating video-caption pairs that share similar entities, and the binding tests require models to associate the correct entity to a given situation while ignoring the different yet plausible entities that also appear in the same video. While current state-of-the-art models perform moderately well on perception tests, accuracy is near random when both entities are present in the same video, indicating that they fail at binding tests. Even the powerful Gemini 1.5 Flash has a substantial gap (16-28%) with respect to human accuracy in such binding tests.
MICap: A Unified Model for Identity-aware Movie Descriptions
May 19, 2024



Characters are an important aspect of any storyline and identifying and including them in descriptions is necessary for story understanding. While previous work has largely ignored identity and generated captions with someone (anonymized names), recent work formulates id-aware captioning as a fill-in-the-blanks (FITB) task, where, given a caption with blanks, the goal is to predict person id labels. However, to predict captions with ids, a two-stage approach is required: first predict captions with someone, then fill in identities. In this work, we present a new single stage approach that can seamlessly switch between id-aware caption generation or FITB when given a caption with blanks. Our model, Movie-Identity Captioner (MICap), uses a shared auto-regressive decoder that benefits from training with FITB and full-caption generation objectives, while the encoder can benefit from or disregard captions with blanks as input. Another challenge with id-aware captioning is the lack of a metric to capture subtle differences between person ids. To this end, we introduce iSPICE, a caption evaluation metric that focuses on identity tuples created through intermediate scene graphs. We evaluate MICap on Large-Scale Movie Description Challenge (LSMDC), where we show a 4.2% improvement in FITB accuracy, and a 1-2% bump in classic captioning metrics.
FiGCLIP: Fine-Grained CLIP Adaptation via Densely Annotated Videos
Jan 15, 2024While contrastive language image pretraining (CLIP) have exhibited impressive performance by learning highly semantic and generalized representations, recent works have exposed a fundamental drawback in its syntactic properties, that includes interpreting fine-grained attributes, actions, spatial relations, states, and details that require compositional reasoning. One reason for this is that natural captions often do not capture all the visual details of a scene. This leads to unaddressed visual concepts being misattributed to the wrong words. And the pooled image and text features, ends up acting as a bag of words, hence losing the syntactic information. In this work, we ask: Is it possible to enhance CLIP's fine-grained and syntactic abilities without compromising its semantic properties? We show that this is possible by adapting CLIP efficiently on a high-quality, comprehensive, and relatively small dataset. We demonstrate our adaptation strategy on VidSitu, a video situation recognition dataset annotated with verbs and rich semantic role labels (SRL). We use the SRL and verb information to create rule-based detailed captions, making sure they capture most of the visual concepts. Combined with hard negatives and hierarchical losses, these annotations allow us to learn a powerful visual representation, dubbed Fine-Grained CLIP (FiGCLIP), that preserves semantic understanding while being detail-oriented. We evaluate on five diverse vision-language tasks in both fine-tuning and zero-shot settings, achieving consistent improvements over the base CLIP model.
Grounded Video Situation Recognition
Oct 19, 2022
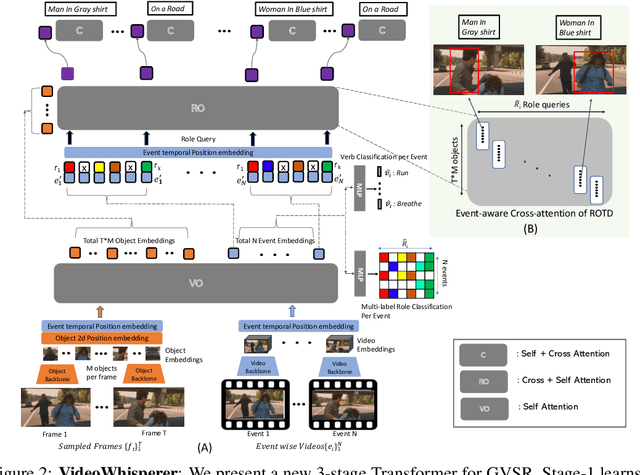


Dense video understanding requires answering several questions such as who is doing what to whom, with what, how, why, and where. Recently, Video Situation Recognition (VidSitu) is framed as a task for structured prediction of multiple events, their relationships, and actions and various verb-role pairs attached to descriptive entities. This task poses several challenges in identifying, disambiguating, and co-referencing entities across multiple verb-role pairs, but also faces some challenges of evaluation. In this work, we propose the addition of spatio-temporal grounding as an essential component of the structured prediction task in a weakly supervised setting, and present a novel three stage Transformer model, VideoWhisperer, that is empowered to make joint predictions. In stage one, we learn contextualised embeddings for video features in parallel with key objects that appear in the video clips to enable fine-grained spatio-temporal reasoning. The second stage sees verb-role queries attend and pool information from object embeddings, localising answers to questions posed about the action. The final stage generates these answers as captions to describe each verb-role pair present in the video. Our model operates on a group of events (clips) simultaneously and predicts verbs, verb-role pairs, their nouns, and their grounding on-the-fly. When evaluated on a grounding-augmented version of the VidSitu dataset, we observe a large improvement in entity captioning accuracy, as well as the ability to localize verb-roles without grounding annotations at training time.
DeepHS-HDRVideo: Deep High Speed High Dynamic Range Video Reconstruction
Oct 10, 2022
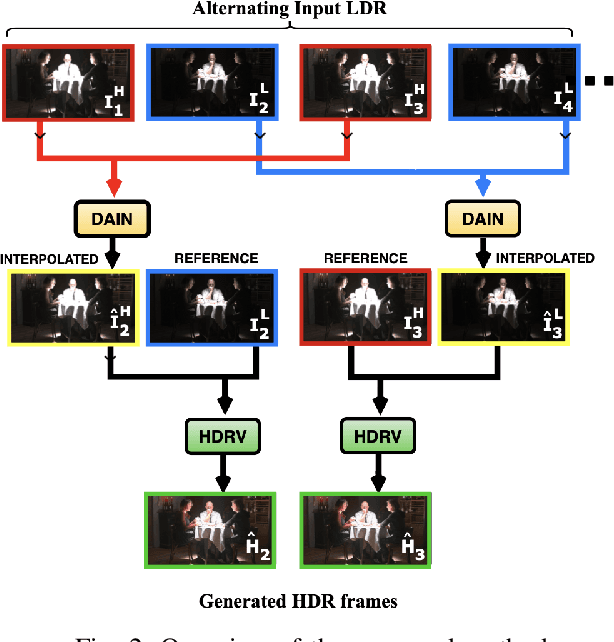
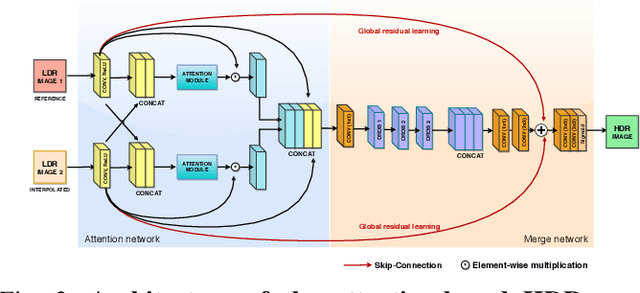

Due to hardware constraints, standard off-the-shelf digital cameras suffers from low dynamic range (LDR) and low frame per second (FPS) outputs. Previous works in high dynamic range (HDR) video reconstruction uses sequence of alternating exposure LDR frames as input, and align the neighbouring frames using optical flow based networks. However, these methods often result in motion artifacts in challenging situations. This is because, the alternate exposure frames have to be exposure matched in order to apply alignment using optical flow. Hence, over-saturation and noise in the LDR frames results in inaccurate alignment. To this end, we propose to align the input LDR frames using a pre-trained video frame interpolation network. This results in better alignment of LDR frames, since we circumvent the error-prone exposure matching step, and directly generate intermediate missing frames from the same exposure inputs. Furthermore, it allows us to generate high FPS HDR videos by recursively interpolating the intermediate frames. Through this work, we propose to use video frame interpolation for HDR video reconstruction, and present the first method to generate high FPS HDR videos. Experimental results demonstrate the efficacy of the proposed framework against optical flow based alignment methods, with an absolute improvement of 2.4 PSNR value on standard HDR video datasets [1], [2] and further benchmark our method for high FPS HDR video generation.
More Parameters? No Thanks!
Jul 20, 2021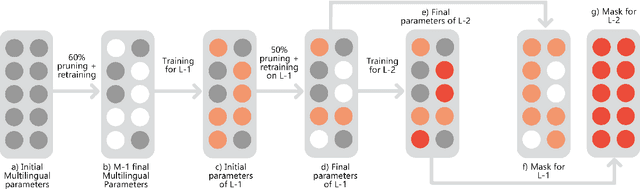
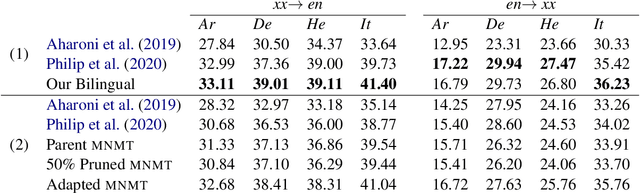
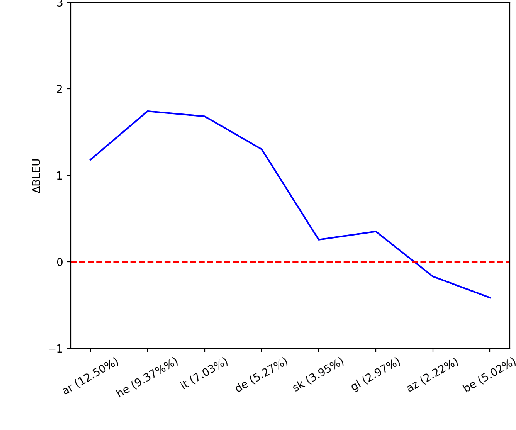

This work studies the long-standing problems of model capacity and negative interference in multilingual neural machine translation MNMT. We use network pruning techniques and observe that pruning 50-70% of the parameters from a trained MNMT model results only in a 0.29-1.98 drop in the BLEU score. Suggesting that there exist large redundancies even in MNMT models. These observations motivate us to use the redundant parameters and counter the interference problem efficiently. We propose a novel adaptation strategy, where we iteratively prune and retrain the redundant parameters of an MNMT to improve bilingual representations while retaining the multilinguality. Negative interference severely affects high resource languages, and our method alleviates it without any additional adapter modules. Hence, we call it parameter-free adaptation strategy, paving way for the efficient adaptation of MNMT. We demonstrate the effectiveness of our method on a 9 language MNMT trained on TED talks, and report an average improvement of +1.36 BLEU on high resource pairs. Code will be released here.
Exploring Pair-Wise NMT for Indian Languages
Dec 10, 2020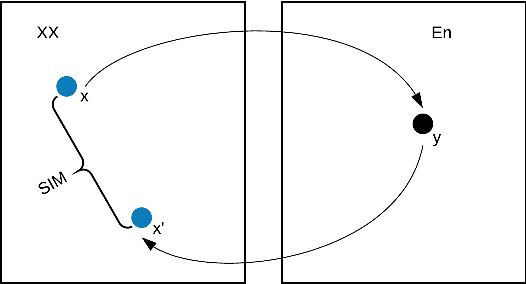
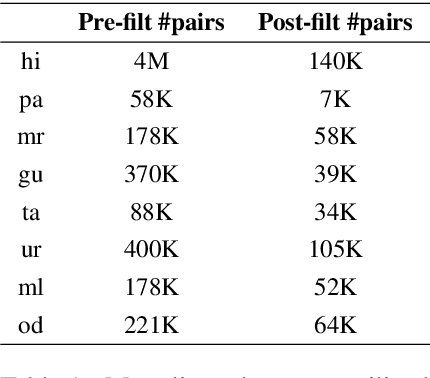
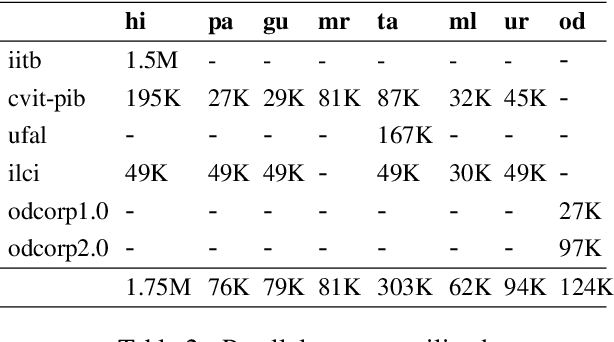
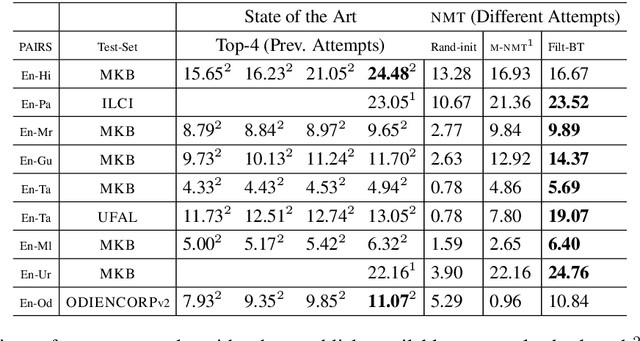
In this paper, we address the task of improving pair-wise machine translation for specific low resource Indian languages. Multilingual NMT models have demonstrated a reasonable amount of effectiveness on resource-poor languages. In this work, we show that the performance of these models can be significantly improved upon by using back-translation through a filtered back-translation process and subsequent fine-tuning on the limited pair-wise language corpora. The analysis in this paper suggests that this method can significantly improve a multilingual model's performance over its baseline, yielding state-of-the-art results for various Indian languages.
FHDR: HDR Image Reconstruction from a Single LDR Image using Feedback Network
Dec 24, 2019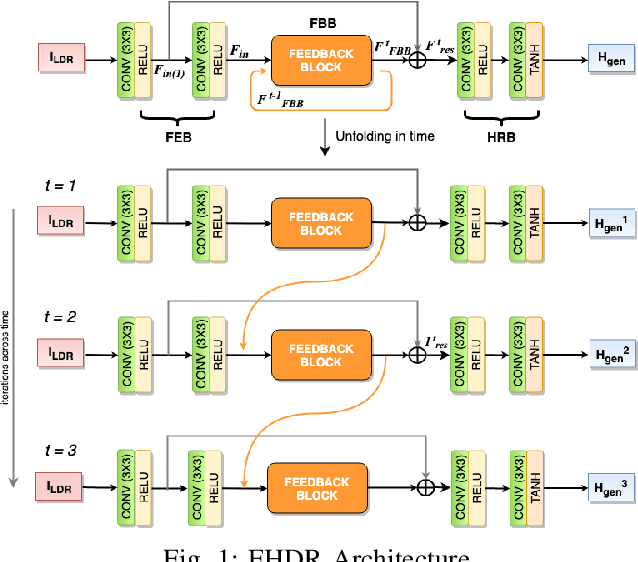
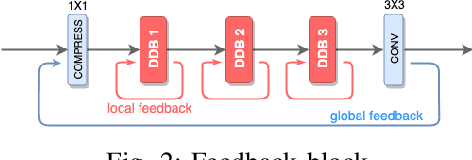
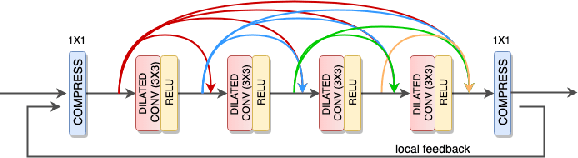

High dynamic range (HDR) image generation from a single exposure low dynamic range (LDR) image has been made possible due to the recent advances in Deep Learning. Various feed-forward Convolutional Neural Networks (CNNs) have been proposed for learning LDR to HDR representations. To better utilize the power of CNNs, we exploit the idea of feedback, where the initial low level features are guided by the high level features using a hidden state of a Recurrent Neural Network. Unlike a single forward pass in a conventional feed-forward network, the reconstruction from LDR to HDR in a feedback network is learned over multiple iterations. This enables us to create a coarse-to-fine representation, leading to an improved reconstruction at every iteration. Various advantages over standard feed-forward networks include early reconstruction ability and better reconstruction quality with fewer network parameters. We design a dense feedback block and propose an end-to-end feedback network- FHDR for HDR image generation from a single exposure LDR image. Qualitative and quantitative evaluations show the superiority of our approach over the state-of-the-art methods.