 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Lottery Ticket Hypothesis for Vision Transformers
Nov 02, 2022
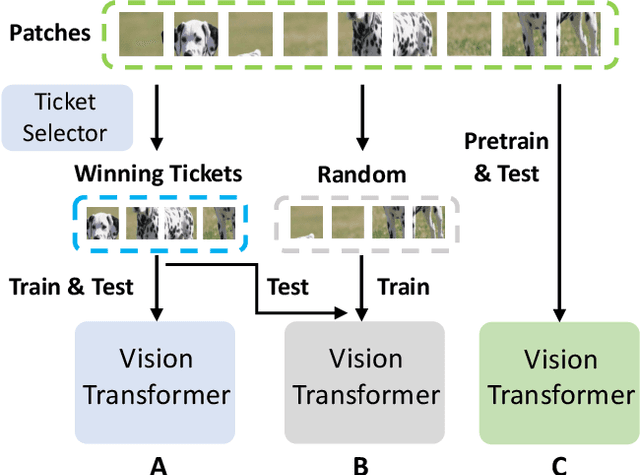
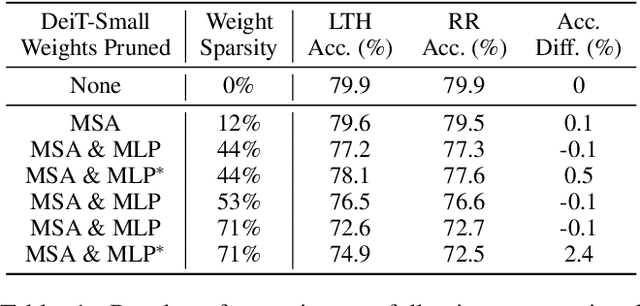
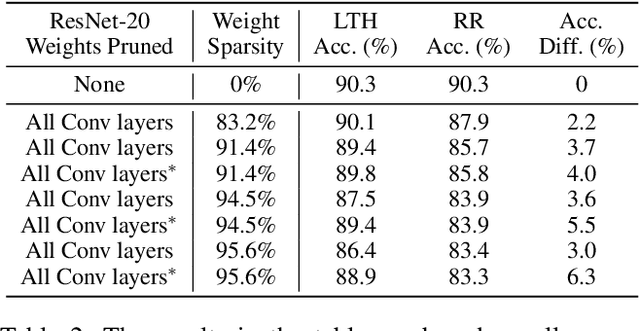
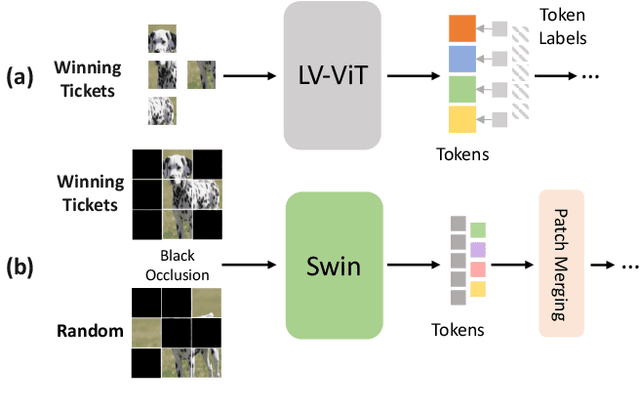
The conventional lottery ticket hypothesis (LTH) claims that there exists a sparse subnetwork within a dense neural network and a proper random initialization method, called the winning ticket, such that it can be trained from scratch to almost as good as the dense counterpart. Meanwhile, the research of LTH in vision transformers (ViTs) is scarcely evaluated. In this paper, we first show that the conventional winning ticket is hard to find at weight level of ViTs by existing methods. Then, we generalize the LTH for ViTs to input images consisting of image patches inspired by the input dependence of ViTs. That is, there exists a subset of input image patches such that a ViT can be trained from scratch by using only this subset of patches and achieve similar accuracy to the ViTs trained by using all image patches. We call this subset of input patches the winning tickets, which represent a significant amount of information in the input. Furthermore, we present a simple yet effective method to find the winning tickets in input patches for various types of ViT, including DeiT, LV-ViT, and Swin Transformers. More specifically, we use a ticket selector to generate the winning tickets based on the informativeness of patches. Meanwhile, we build another randomly selected subset of patches for comparison, and the experiments show that there is clear difference between the performance of models trained with winning tickets and randomly selected subsets.
Unsupervised Model Adaptation for Source-free Segmentation of Medical Images
Nov 02, 2022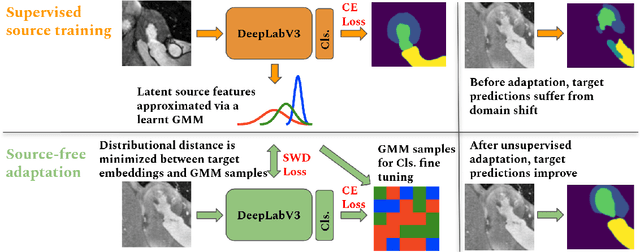
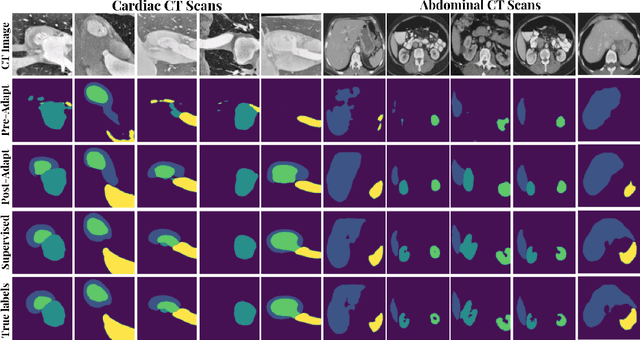

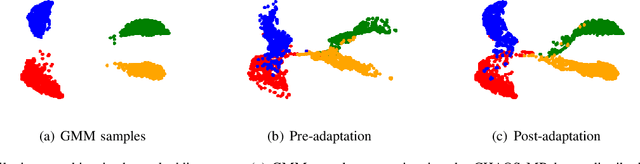
The recent prevalence of deep neural networks has lead semantic segmentation networks to achieve human-level performance in the medical field when sufficient training data is provided. Such networks however fail to generalize when tasked with predicting semantic maps for out-of-distribution images, requiring model re-training on the new distributions. This expensive process necessitates expert knowledge in order to generate training labels. Distribution shifts can arise naturally in the medical field via the choice of imaging device, i.e. MRI or CT scanners. To combat the need for labeling images in a target domain after a model is successfully trained in a fully annotated \textit{source domain} with a different data distribution, unsupervised domain adaptation (UDA) can be used. Most UDA approaches ensure target generalization by creating a shared source/target latent feature space. This allows a source trained classifier to maintain performance on the target domain. However most UDA approaches require joint source and target data access, which may create privacy leaks with respect to patient information. We propose an UDA algorithm for medical image segmentation that does not require access to source data during adaptation, and is thus capable in maintaining patient data privacy. We rely on an approximation of the source latent features at adaptation time, and create a joint source/target embedding space by minimizing a distributional distance metric based on optimal transport. We demonstrate our approach is competitive to recent UDA medical segmentation works even with the added privacy requisite.
Identifying Damage-Sensitive Spatial Vibration Characteristics of Bridges from Widespread Smartphone Data
Nov 02, 2022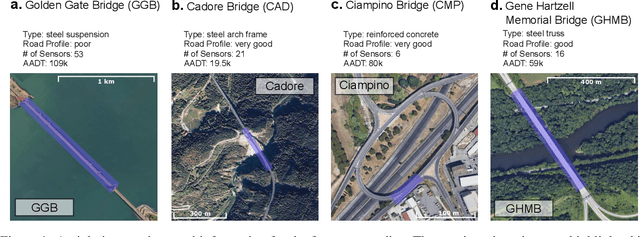

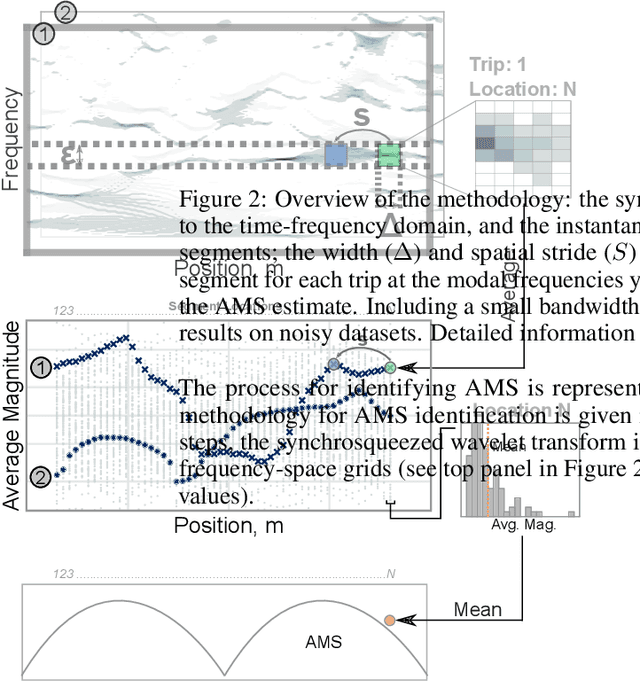
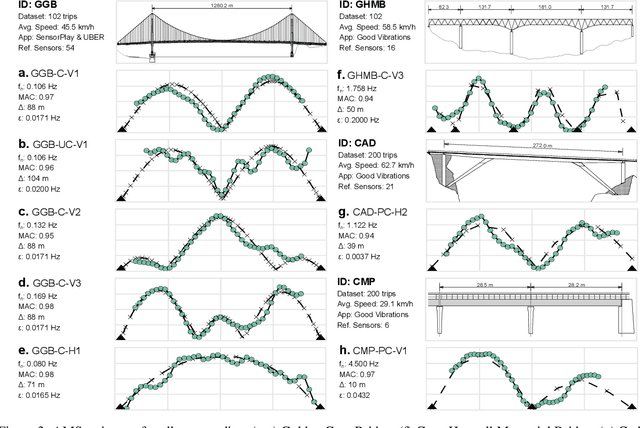
The knowledge gap in the expected and actual conditions of bridges has created worldwide deficits in infrastructure service and funding challenges. Despite rapid advances over the past four decades, sensing technology is still not a part of bridge inspection protocols. Every time a vehicle with a mobile device passes over a bridge, there is an opportunity to capture potentially important structural response information at a very low cost. Prior work has shown how bridge modal frequencies can be accurately determined with crowdsourced smartphone-vehicle trip (SVT) data in real-world settings. However, modal frequencies provide very limited insight on the structural health conditions of the bridge. Here, we present a novel method to extract spatial vibration characteristics of real bridges, namely, absolute mode shapes, from crowdsourced SVT data. These characteristics have a demonstrable sensitivity to structural damage and provide superior, yet complementary, indicators of bridge condition. Furthermore, they are useful in the development of accurate mathematical models of the structural system and help reconcile the differences between models and real systems. We demonstrate successful applications on four very different bridges, with span lengths ranging from about 30 to 1300 meters, collectively representing about one quarter of bridges in the US. Supplementary work applies this computational approach to accurately detect simulated bridge damage entirely from crowdsourced SVT data in an unprecedentedly timely fashion. The results presented in this article open the way towards large-scale crowdsourced monitoring of bridge infrastructure.
ResAttUNet: Detecting Marine Debris using an Attention activated Residual UNet
Oct 16, 2022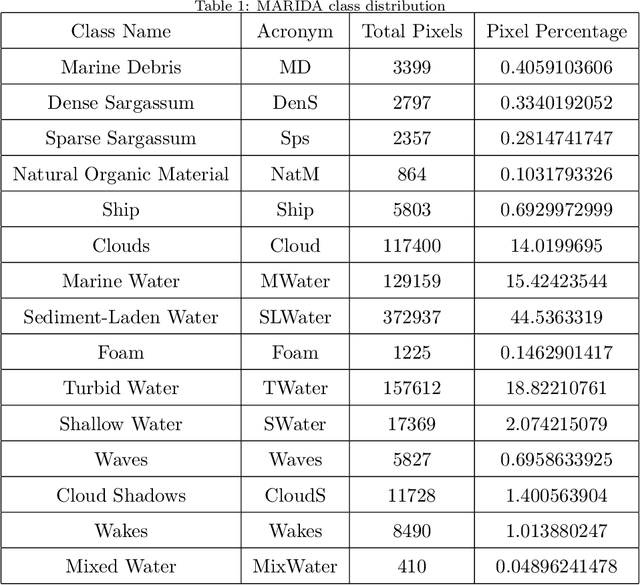
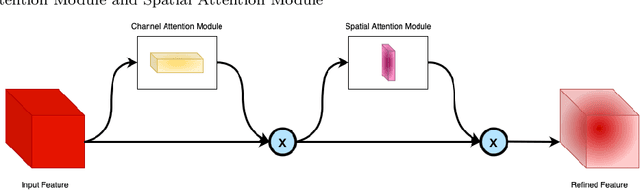
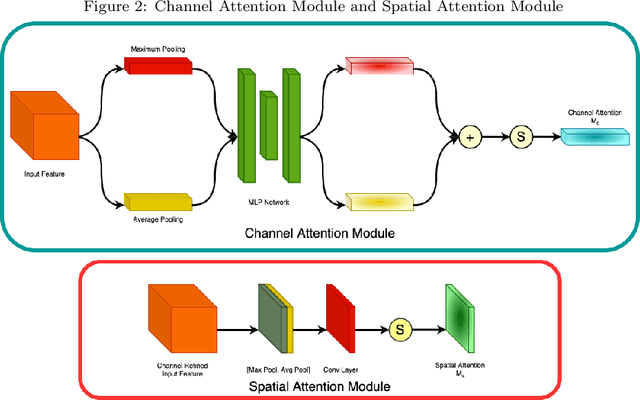
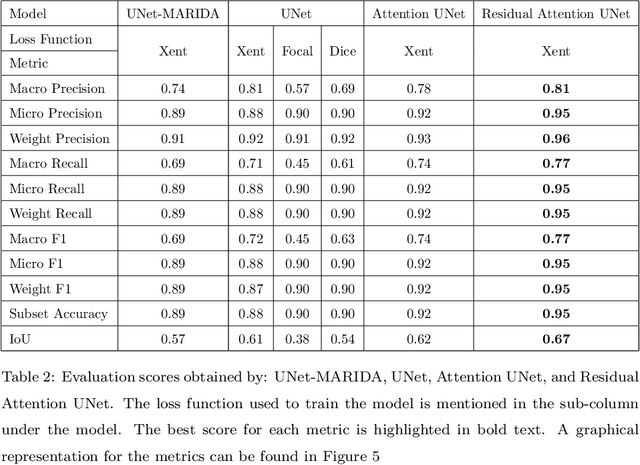
Currently, a significant amount of research has been done in field of Remote Sensing with the use of deep learning techniques. The introduction of Marine Debris Archive (MARIDA), an open-source dataset with benchmark results, for marine debris detection opened new pathways to use deep learning techniques for the task of debris detection and segmentation. This paper introduces a novel attention based segmentation technique that outperforms the existing state-of-the-art results introduced with MARIDA. The paper presents a novel spatial aware encoder and decoder architecture to maintain the contextual information and structure of sparse ground truth patches present in the images. The attained results are expected to pave the path for further research involving deep learning using remote sensing images. The code is available at https://github.com/sheikhazhanmohammed/SADMA.git
CDConv: A Benchmark for Contradiction Detection in Chinese Conversations
Oct 16, 2022
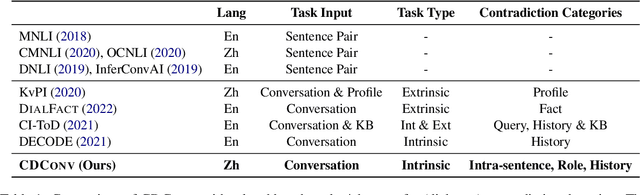

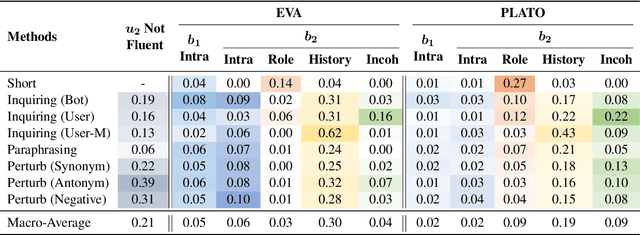
Dialogue contradiction is a critical issue in open-domain dialogue systems. The contextualization nature of conversations makes dialogue contradiction detection rather challenging. In this work, we propose a benchmark for Contradiction Detection in Chinese Conversations, namely CDConv. It contains 12K multi-turn conversations annotated with three typical contradiction categories: Intra-sentence Contradiction, Role Confusion, and History Contradiction. To efficiently construct the CDConv conversations, we devise a series of methods for automatic conversation generation, which simulate common user behaviors that trigger chatbots to make contradictions. We conduct careful manual quality screening of the constructed conversations and show that state-of-the-art Chinese chatbots can be easily goaded into making contradictions. Experiments on CDConv show that properly modeling contextual information is critical for dialogue contradiction detection, but there are still unresolved challenges that require future research.
mRobust04: A Multilingual Version of the TREC Robust 2004 Benchmark
Sep 27, 2022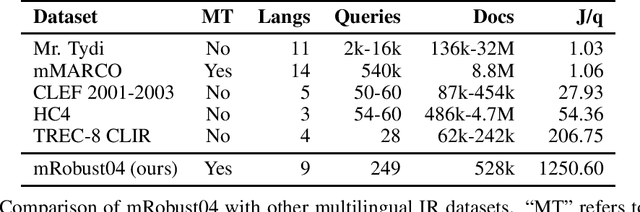
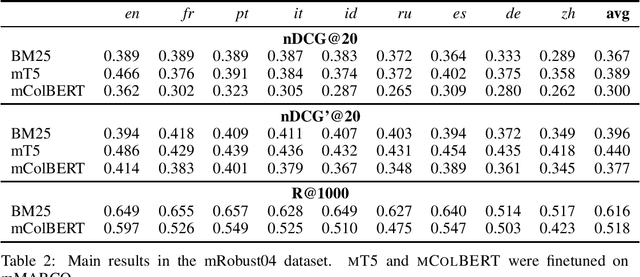
Robust 2004 is an information retrieval benchmark whose large number of judgments per query make it a reliable evaluation dataset. In this paper, we present mRobust04, a multilingual version of Robust04 that was translated to 8 languages using Google Translate. We also provide results of three different multilingual retrievers on this dataset. The dataset is available at https://huggingface.co/datasets/unicamp-dl/mrobust
MLT-LE: predicting drug-target binding affinity with multi-task residual neural networks
Sep 13, 2022

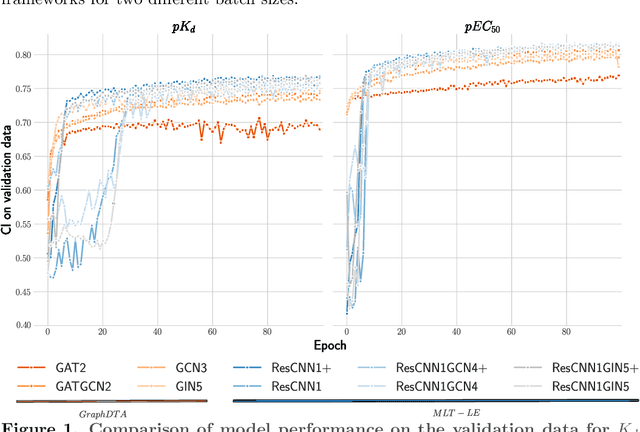
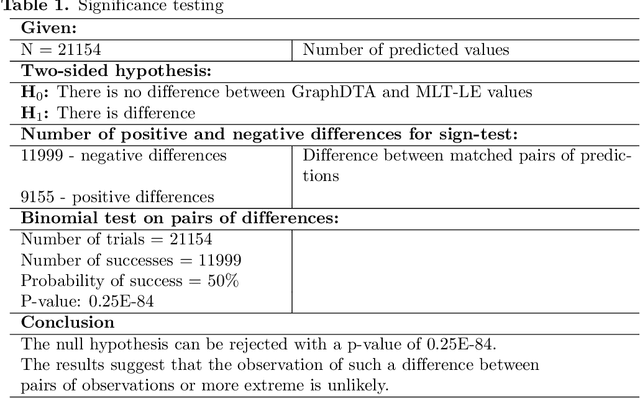
Assessing drug-target affinity is a critical step in the drug discovery and development process, but to obtain such data experimentally is both time consuming and expensive. For this reason, computational methods for predicting binding strength are being widely developed. However, these methods typically use a single-task approach for prediction, thus ignoring the additional information that can be extracted from the data and used to drive the learning process. Thereafter in this work, we present a multi-task approach for binding strength prediction. Our results suggest that these prediction can indeed benefit from a multi-task learning approach, by utilizing added information from related tasks and multi-task induced regularization.
Cross-modal Learning for Image-Guided Point Cloud Shape Completion
Sep 20, 2022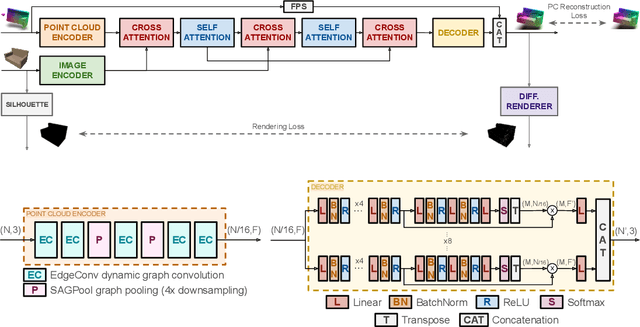
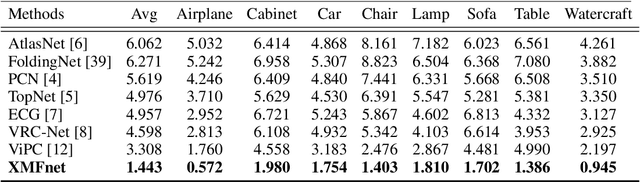
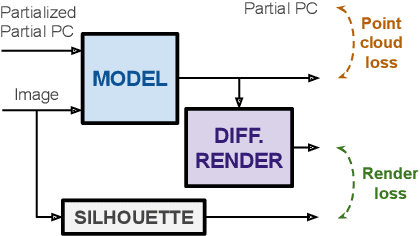
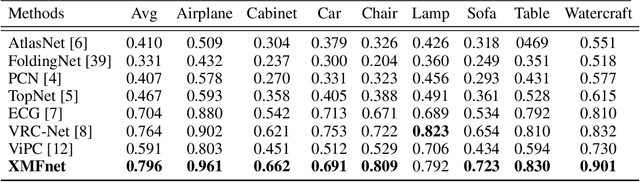
In this paper we explore the recent topic of point cloud completion, guided by an auxiliary image. We show how it is possible to effectively combine the information from the two modalities in a localized latent space, thus avoiding the need for complex point cloud reconstruction methods from single views used by the state-of-the-art. We also investigate a novel weakly-supervised setting where the auxiliary image provides a supervisory signal to the training process by using a differentiable renderer on the completed point cloud to measure fidelity in the image space. Experiments show significant improvements over state-of-the-art supervised methods for both unimodal and multimodal completion. We also show the effectiveness of the weakly-supervised approach which outperforms a number of supervised methods and is competitive with the latest supervised models only exploiting point cloud information.
HSVI can solve zero-sum Partially Observable Stochastic Games
Oct 26, 2022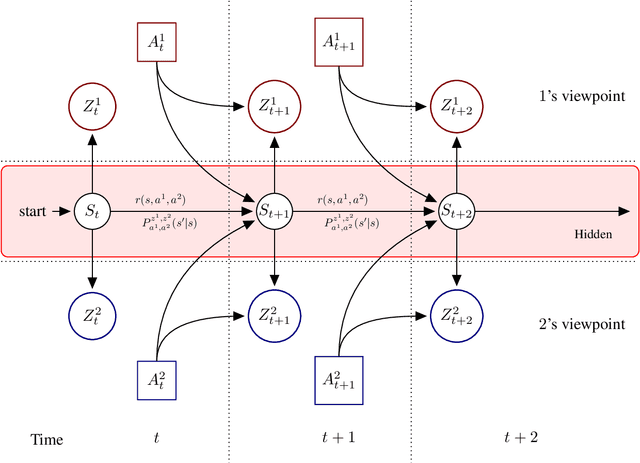
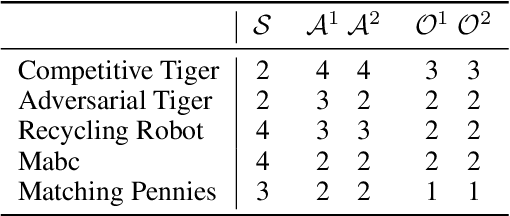
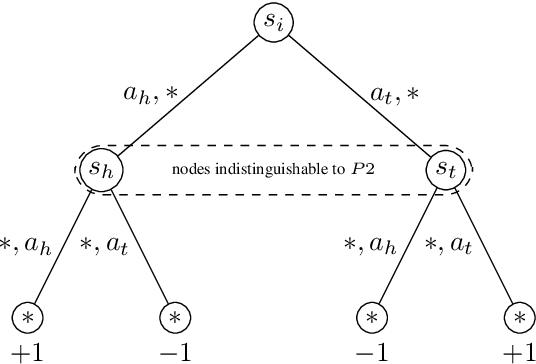
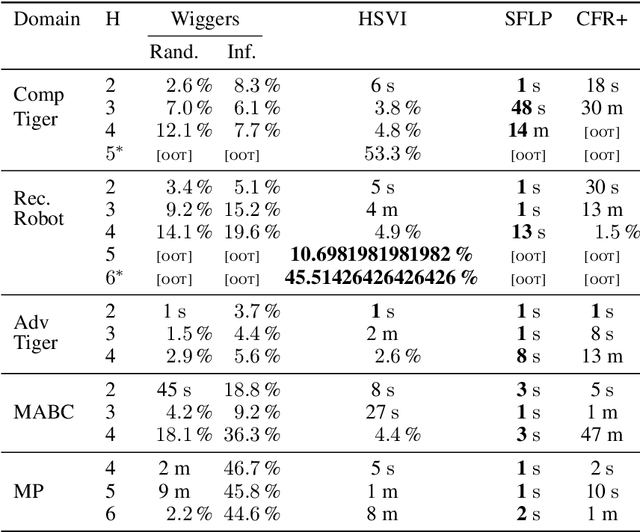
State-of-the-art methods for solving 2-player zero-sum imperfect information games rely on linear programming or regret minimization, though not on dynamic programming (DP) or heuristic search (HS), while the latter are often at the core of state-of-the-art solvers for other sequential decision-making problems. In partially observable or collaborative settings (e.g., POMDPs and Dec- POMDPs), DP and HS require introducing an appropriate statistic that induces a fully observable problem as well as bounding (convex) approximators of the optimal value function. This approach has succeeded in some subclasses of 2-player zero-sum partially observable stochastic games (zs- POSGs) as well, but how to apply it in the general case still remains an open question. We answer it by (i) rigorously defining an equivalent game to work with, (ii) proving mathematical properties of the optimal value function that allow deriving bounds that come with solution strategies, (iii) proposing for the first time an HSVI-like solver that provably converges to an $\epsilon$-optimal solution in finite time, and (iv) empirically analyzing it. This opens the door to a novel family of promising approaches complementing those relying on linear programming or iterative methods.
Deep Learning is Provably Robust to Symmetric Label Noise
Oct 26, 2022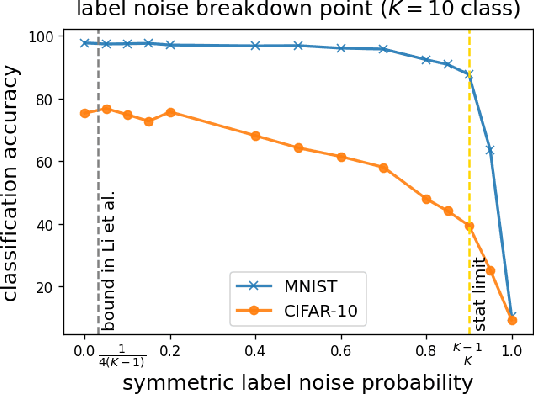
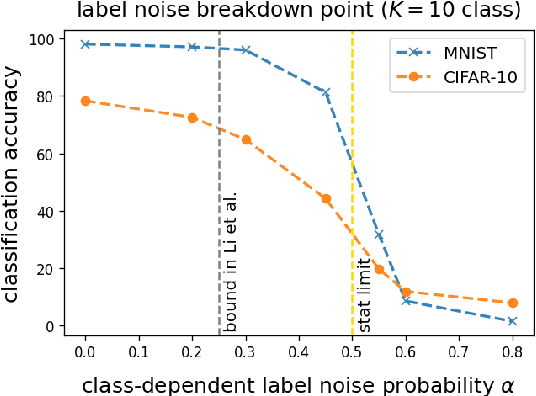
Deep neural networks (DNNs) are capable of perfectly fitting the training data, including memorizing noisy data. It is commonly believed that memorization hurts generalization. Therefore, many recent works propose mitigation strategies to avoid noisy data or correct memorization. In this work, we step back and ask the question: Can deep learning be robust against massive label noise without any mitigation? We provide an affirmative answer for the case of symmetric label noise: We find that certain DNNs, including under-parameterized and over-parameterized models, can tolerate massive symmetric label noise up to the information-theoretic threshold. By appealing to classical statistical theory and universal consistency of DNNs, we prove that for multiclass classification, $L_1$-consistent DNN classifiers trained under symmetric label noise can achieve Bayes optimality asymptotically if the label noise probability is less than $\frac{K-1}{K}$, where $K \ge 2$ is the number of classes. Our results show that for symmetric label noise, no mitigation is necessary for $L_1$-consistent estimators. We conjecture that for general label noise, mitigation strategies that make use of the noisy data will outperform those that ignore the noisy data.