 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Continual Domain Adaptation for Semantic Image Segmentation Using Internal Representations
Jan 02, 2024Semantic segmentation models trained on annotated data fail to generalize well when the input data distribution changes over extended time period, leading to requiring re-training to maintain performance. Classic Unsupervised domain adaptation (UDA) attempts to address a similar problem when there is target domain with no annotated data points through transferring knowledge from a source domain with annotated data. We develop an online UDA algorithm for semantic segmentation of images that improves model generalization on unannotated domains in scenarios where source data access is restricted during adaptation. We perform model adaptation is by minimizing the distributional distance between the source latent features and the target features in a shared embedding space. Our solution promotes a shared domain-agnostic latent feature space between the two domains, which allows for classifier generalization on the target dataset. To alleviate the need of access to source samples during adaptation, we approximate the source latent feature distribution via an appropriate surrogate distribution, in this case a Gassian mixture model (GMM). We evaluate our approach on well established semantic segmentation datasets and demonstrate it compares favorably against state-of-the-art (SOTA) UDA semantic segmentation methods.
Preserving Fairness in AI under Domain Shift
Jan 29, 2023Existing algorithms for ensuring fairness in AI use a single-shot training strategy, where an AI model is trained on an annotated training dataset with sensitive attributes and then fielded for utilization. This training strategy is effective in problems with stationary distributions, where both training and testing data are drawn from the same distribution. However, it is vulnerable with respect to distributional shifts in the input space that may occur after the initial training phase. As a result, the time-dependent nature of data can introduce biases into the model predictions. Model retraining from scratch using a new annotated dataset is a naive solution that is expensive and time-consuming. We develop an algorithm to adapt a fair model to remain fair under domain shift using solely new unannotated data points. We recast this learning setting as an unsupervised domain adaptation problem. Our algorithm is based on updating the model such that the internal representation of data remains unbiased despite distributional shifts in the input space. We provide extensive empirical validation on three widely employed fairness datasets to demonstrate the effectiveness of our algorithm.
Unsupervised Model Adaptation for Source-free Segmentation of Medical Images
Nov 02, 2022The recent prevalence of deep neural networks has lead semantic segmentation networks to achieve human-level performance in the medical field when sufficient training data is provided. Such networks however fail to generalize when tasked with predicting semantic maps for out-of-distribution images, requiring model re-training on the new distributions. This expensive process necessitates expert knowledge in order to generate training labels. Distribution shifts can arise naturally in the medical field via the choice of imaging device, i.e. MRI or CT scanners. To combat the need for labeling images in a target domain after a model is successfully trained in a fully annotated \textit{source domain} with a different data distribution, unsupervised domain adaptation (UDA) can be used. Most UDA approaches ensure target generalization by creating a shared source/target latent feature space. This allows a source trained classifier to maintain performance on the target domain. However most UDA approaches require joint source and target data access, which may create privacy leaks with respect to patient information. We propose an UDA algorithm for medical image segmentation that does not require access to source data during adaptation, and is thus capable in maintaining patient data privacy. We rely on an approximation of the source latent features at adaptation time, and create a joint source/target embedding space by minimizing a distributional distance metric based on optimal transport. We demonstrate our approach is competitive to recent UDA medical segmentation works even with the added privacy requisite.
Secure Domain Adaptation with Multiple Sources
Jun 23, 2021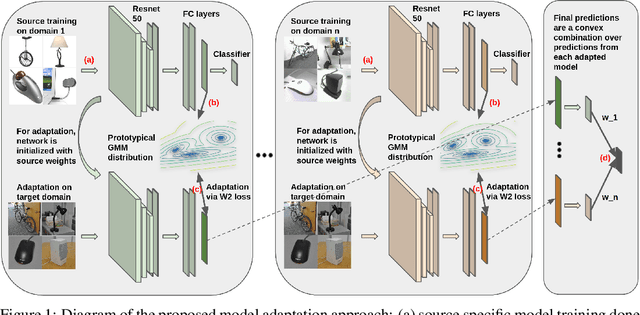
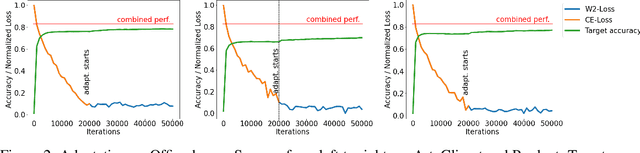
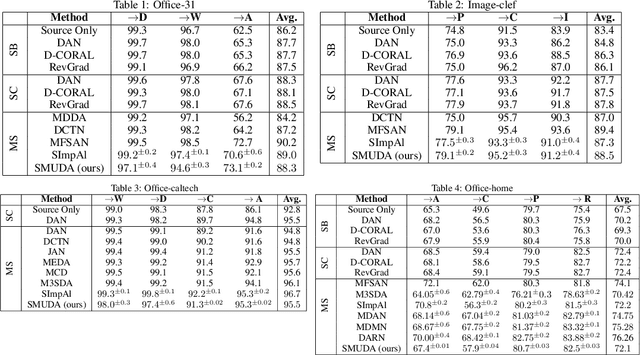
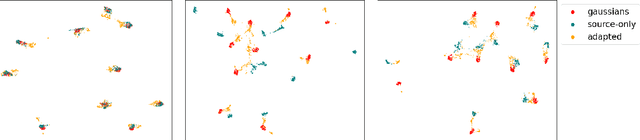
Multi-source unsupervised domain adaptation (MUDA) is a recently explored learning framework, where the goal is to address the challenge of labeled data scarcity in a target domain via transferring knowledge from multiple source domains with annotated data. Since the source data is distributed, the privacy of source domains' data can be a natural concern. We benefit from the idea of domain alignment in an embedding space to address the privacy concern for MUDA. Our method is based on aligning the sources and target distributions indirectly via internally learned distributions, without communicating data samples between domains. We justify our approach theoretically and perform extensive experiments to demonstrate that our method is effective and compares favorably against existing methods.
Privacy Preserving Domain Adaptation for Semantic Segmentation of Medical Images
Jan 02, 2021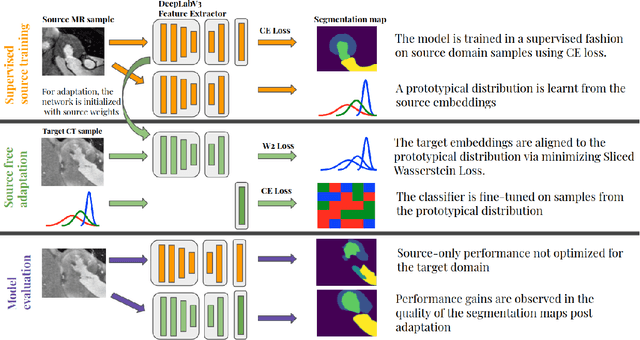
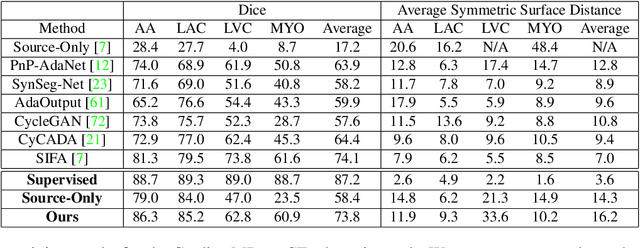
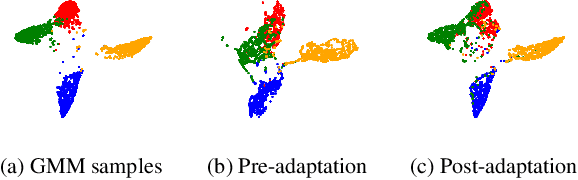
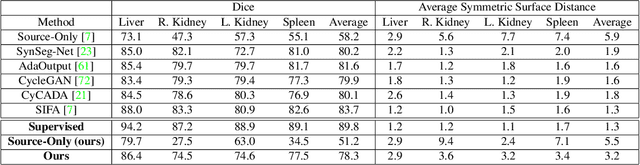
Convolutional neural networks (CNNs) have led to significant improvements in tasks involving semantic segmentation of images. CNNs are vulnerable in the area of biomedical image segmentation because of distributional gap between two source and target domains with different data modalities which leads to domain shift. Domain shift makes data annotations in new modalities necessary because models must be retrained from scratch. Unsupervised domain adaptation (UDA) is proposed to adapt a model to new modalities using solely unlabeled target domain data. Common UDA algorithms require access to data points in the source domain which may not be feasible in medical imaging due to privacy concerns. In this work, we develop an algorithm for UDA in a privacy-constrained setting, where the source domain data is inaccessible. Our idea is based on encoding the information from the source samples into a prototypical distribution that is used as an intermediate distribution for aligning the target domain distribution with the source domain distribution. We demonstrate the effectiveness of our algorithm by comparing it to state-of-the-art medical image semantic segmentation approaches on two medical image semantic segmentation datasets.
Unsupervised Model Adaptation for Continual Semantic Segmentation
Sep 26, 2020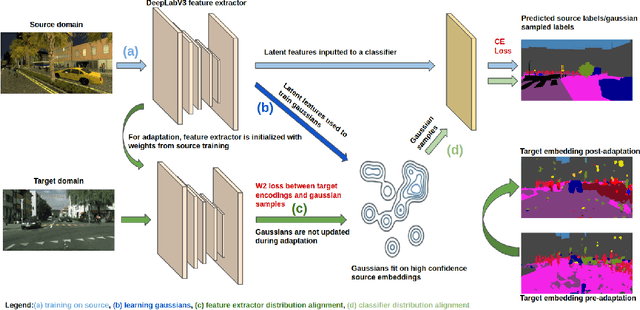
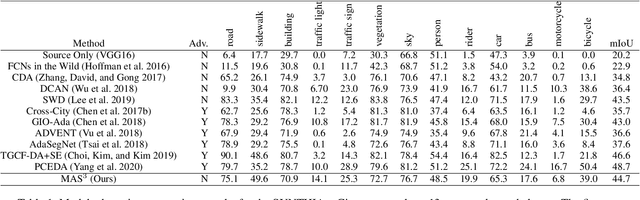
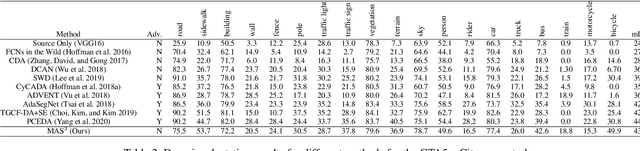
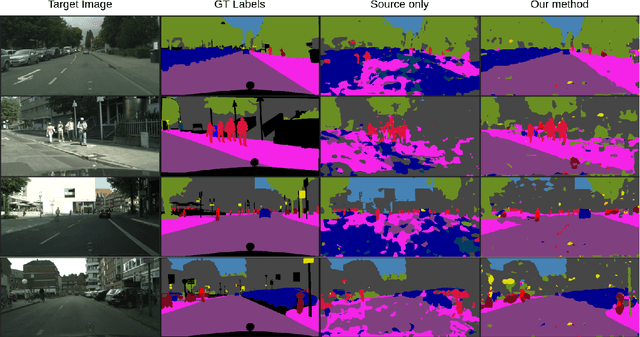
We develop an algorithm for adapting a semantic segmentation model that is trained using a labeled source domain to generalize well in an unlabeled target domain. A similar problem has been studied extensively in the unsupervised domain adaptation (UDA) literature, but existing UDA algorithms require access to both the source domain labeled data and the target domain unlabeled data for training a domain agnostic semantic segmentation model. Relaxing this constraint enables a user to adapt pretrained models to generalize in a target domain, without requiring access to source data. To this end, we learn a prototypical distribution for the source domain in an intermediate embedding space. This distribution encodes the abstract knowledge that is learned from the source domain. We then use this distribution for aligning the target domain distribution with the source domain distribution in the embedding space. We provide theoretical analysis and explain conditions under which our algorithm is effective. Experiments on benchmark adaptation task demonstrate our method achieves competitive performance even compared with joint UDA approaches.