 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MFFN: Multi-view Feature Fusion Network for Camouflaged Object Detection
Oct 12, 2022

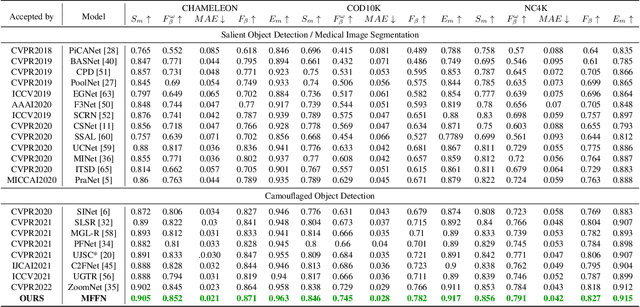
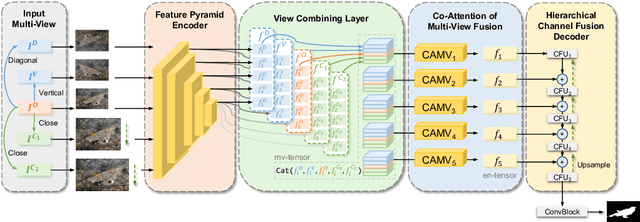

Recent research about camouflaged object detection (COD) aims to segment highly concealed objects hidden in complex surroundings. The tiny, fuzzy camouflaged objects result in visually indistinguishable properties. However, current single-view COD detectors are sensitive to background distractors. Therefore, blurred boundaries and variable shapes of the camouflaged objects are challenging to be fully captured with a single-view detector. To overcome these obstacles, we propose a behavior-inspired framework, called Multi-view Feature Fusion Network (MFFN), which mimics the human behaviors of finding indistinct objects in images, i.e., observing from multiple angles, distances, perspectives. Specifically, the key idea behind it is to generate multiple ways of observation (multi-view) by data augmentation and apply them as inputs. MFFN captures critical edge and semantic information by comparing and fusing extracted multi-view features. In addition, our MFFN exploits the dependence and interaction between views by the designed hierarchical view and channel integration modules. Furthermore, our methods leverage the complementary information between different views through a two-stage attention module called Co-attention of Multi-view (CAMV). And we designed a local-overall module called Channel Fusion Unit (CFU) to explore the channel-wise contextual clues of diverse feature maps in an iterative manner. The experiment results show that our method performs favorably against existing state-of-the-art methods via training with the same data. The code will be available at https: //github.com/dwardzheng/MFFN_COD.
Superpixel Perception Graph Neural Network for Intelligent Defect Detection
Oct 14, 2022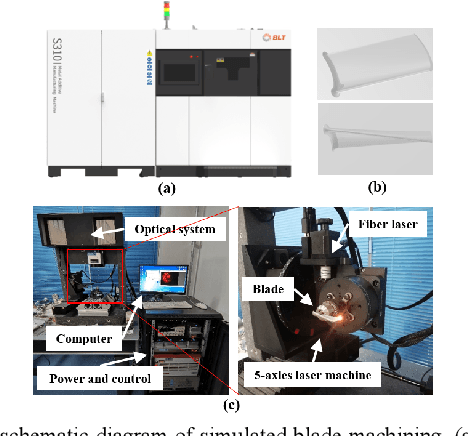

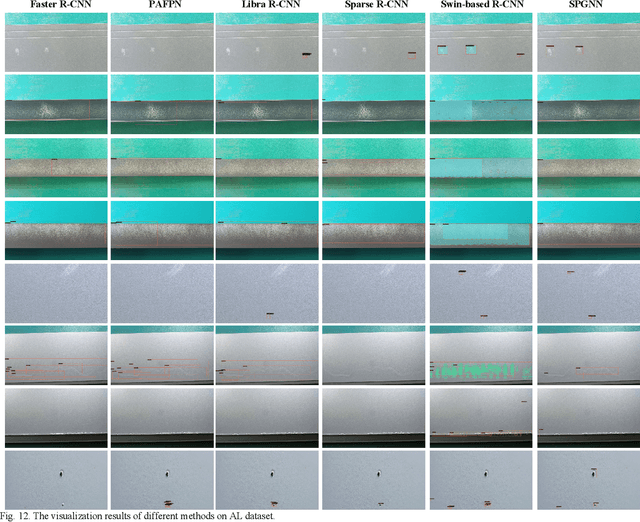
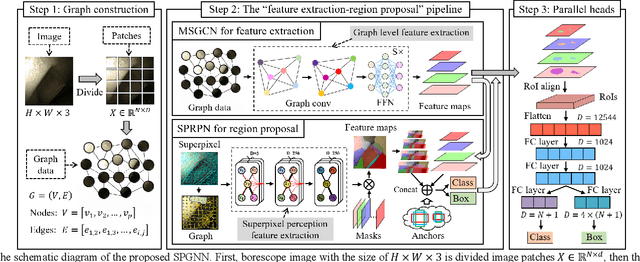
Aero-engine is the core component of aircraft and other spacecraft. The high-speed rotating blades provide power by sucking in air and fully combusting, and various defects will inevitably occur, threatening the operation safety of aero-engine. Therefore, regular inspections are essential for such a complex system. However, existing traditional technology which is borescope inspection is labor-intensive, time-consuming, and experience-dependent. To endow this technology with intelligence, a novel superpixel perception graph neural network (SPGNN) is proposed by utilizing a multi-stage graph convolutional network (MSGCN) for feature extraction and superpixel perception region proposal network (SPRPN) for region proposal. First, to capture complex and irregular textures, the images are transformed into a series of patches, to obtain their graph representations. Then, MSGCN composed of several GCN blocks extracts graph structure features and performs graph information processing at graph level. Last but not least, the SPRPN is proposed to generate perceptual bounding boxes by fusing graph representation features and superpixel perception features. Therefore, the proposed SPGNN always implements feature extraction and information transmission at the graph level in the whole SPGNN pipeline, and SPRPN and MSGNN mutually benefit from each other. To verify the effectiveness of SPGNN, we meticulously construct a simulated blade dataset with 3000 images. A public aluminum dataset is also used to validate the performances of different methods. The experimental results demonstrate that the proposed SPGNN has superior performance compared with the state-of-the-art methods. The source code will be available at https://github.com/githbshang/SPGNN.
Optimizing Vision Transformers for Medical Image Segmentation and Few-Shot Domain Adaptation
Oct 14, 2022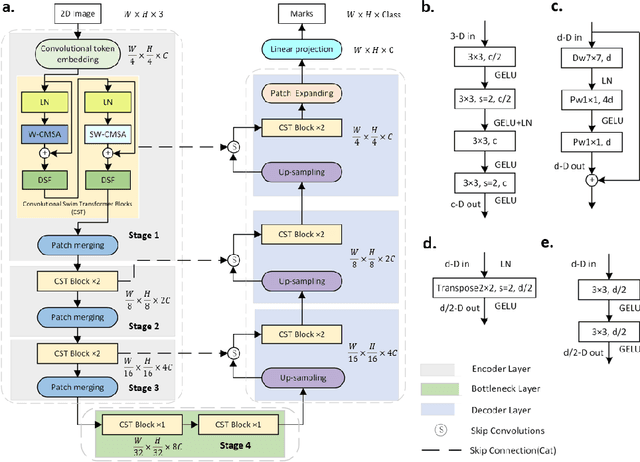
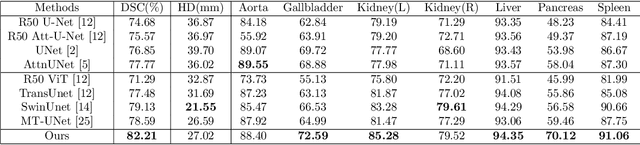
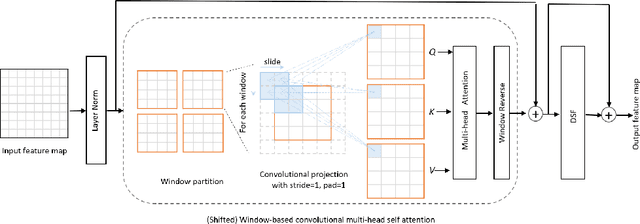
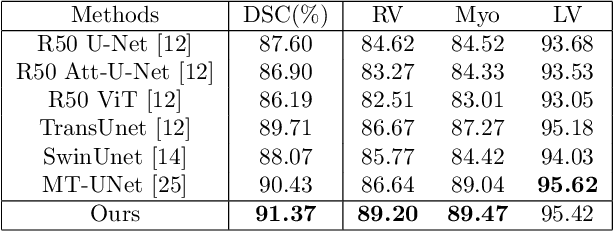
The adaptation of transformers to computer vision is not straightforward because the modelling of image contextual information results in quadratic computational complexity with relation to the input features. Most of existing methods require extensive pre-training on massive datasets such as ImageNet and therefore their application to fields such as healthcare is less effective. CNNs are the dominant architecture in computer vision tasks because convolutional filters can effectively model local dependencies and reduce drastically the parameters required. However, convolutional filters cannot handle more complex interactions, which are beyond a small neighbour of pixels. Furthermore, their weights are fixed after training and thus they do not take into consideration changes in the visual input. Inspired by recent work on hybrid visual transformers with convolutions and hierarchical transformers, we propose Convolutional Swin-Unet (CS-Unet) transformer blocks and optimise their settings with relation to patch embedding, projection, the feed-forward network, up sampling and skip connections. CS-Unet can be trained from scratch and inherits the superiority of convolutions in each feature process phase. It helps to encode precise spatial information and produce hierarchical representations that contribute to object concepts at various scales. Experiments show that CS-Unet without pre-training surpasses other state-of-the-art counterparts by large margins on two medical CT and MRI datasets with fewer parameters. In addition, two domain-adaptation experiments on optic disc and polyp image segmentation further prove that our method is highly generalizable and effectively bridges the domain gap between images from different sources.
Grounding Scene Graphs on Natural Images via Visio-Lingual Message Passing
Nov 03, 2022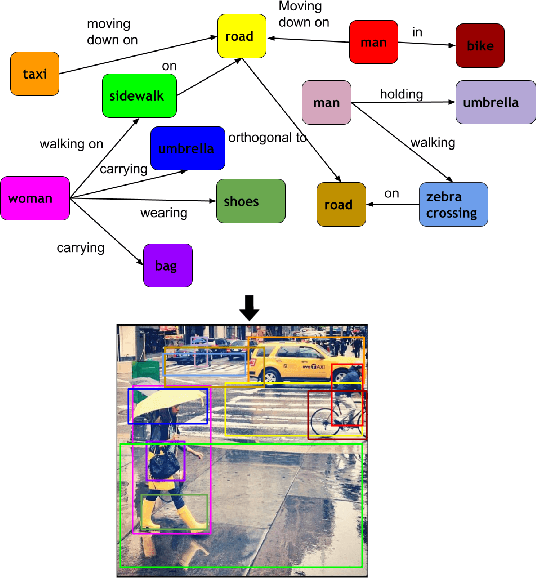
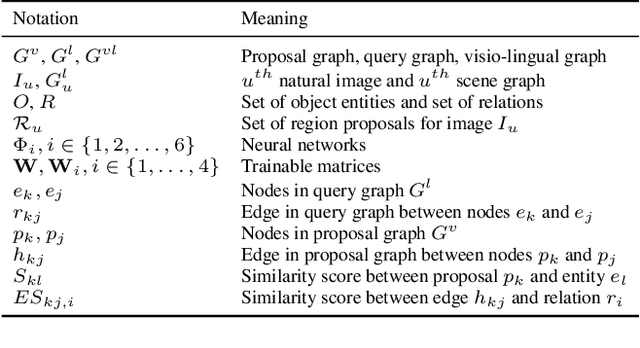
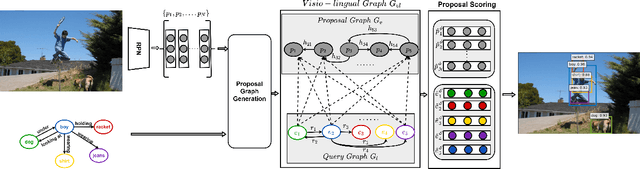
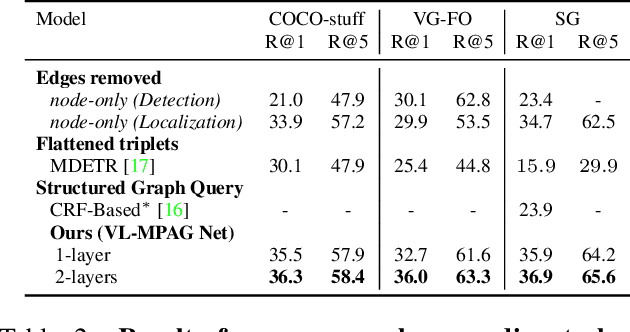
This paper presents a framework for jointly grounding objects that follow certain semantic relationship constraints given in a scene graph. A typical natural scene contains several objects, often exhibiting visual relationships of varied complexities between them. These inter-object relationships provide strong contextual cues toward improving grounding performance compared to a traditional object query-only-based localization task. A scene graph is an efficient and structured way to represent all the objects and their semantic relationships in the image. In an attempt towards bridging these two modalities representing scenes and utilizing contextual information for improving object localization, we rigorously study the problem of grounding scene graphs on natural images. To this end, we propose a novel graph neural network-based approach referred to as Visio-Lingual Message PAssing Graph Neural Network (VL-MPAG Net). In VL-MPAG Net, we first construct a directed graph with object proposals as nodes and an edge between a pair of nodes representing a plausible relation between them. Then a three-step inter-graph and intra-graph message passing is performed to learn the context-dependent representation of the proposals and query objects. These object representations are used to score the proposals to generate object localization. The proposed method significantly outperforms the baselines on four public datasets.
Could Giant Pretrained Image Models Extract Universal Representations?
Nov 03, 2022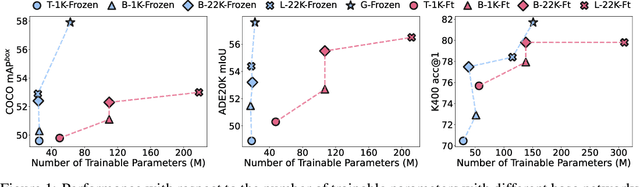
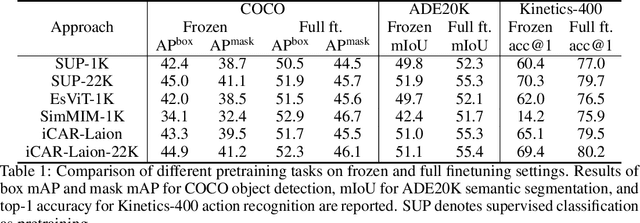
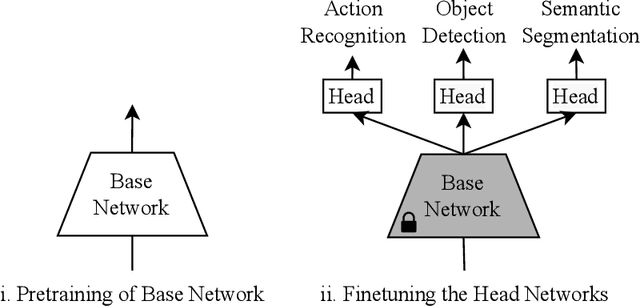
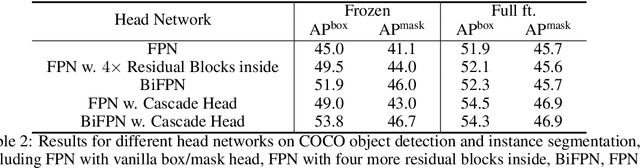
Frozen pretrained models have become a viable alternative to the pretraining-then-finetuning paradigm for transfer learning. However, with frozen models there are relatively few parameters available for adapting to downstream tasks, which is problematic in computer vision where tasks vary significantly in input/output format and the type of information that is of value. In this paper, we present a study of frozen pretrained models when applied to diverse and representative computer vision tasks, including object detection, semantic segmentation and video action recognition. From this empirical analysis, our work answers the questions of what pretraining task fits best with this frozen setting, how to make the frozen setting more flexible to various downstream tasks, and the effect of larger model sizes. We additionally examine the upper bound of performance using a giant frozen pretrained model with 3 billion parameters (SwinV2-G) and find that it reaches competitive performance on a varied set of major benchmarks with only one shared frozen base network: 60.0 box mAP and 52.2 mask mAP on COCO object detection test-dev, 57.6 val mIoU on ADE20K semantic segmentation, and 81.7 top-1 accuracy on Kinetics-400 action recognition. With this work, we hope to bring greater attention to this promising path of freezing pretrained image models.
Enhancing Patent Retrieval using Text and Knowledge Graph Embeddings: A Technical Note
Nov 03, 2022
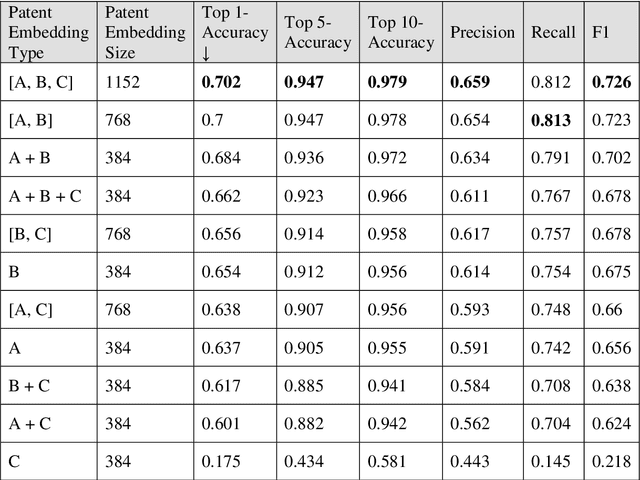
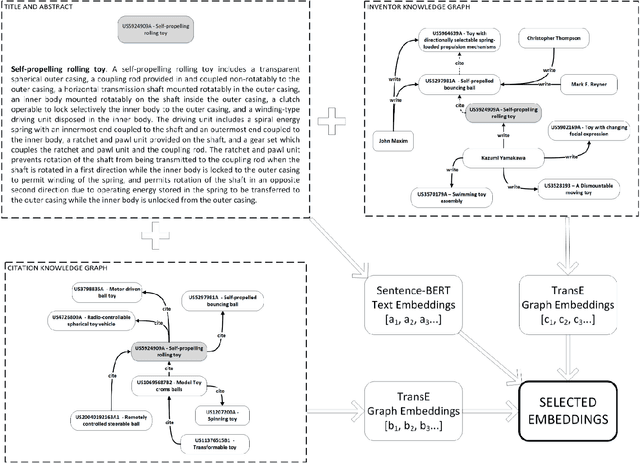
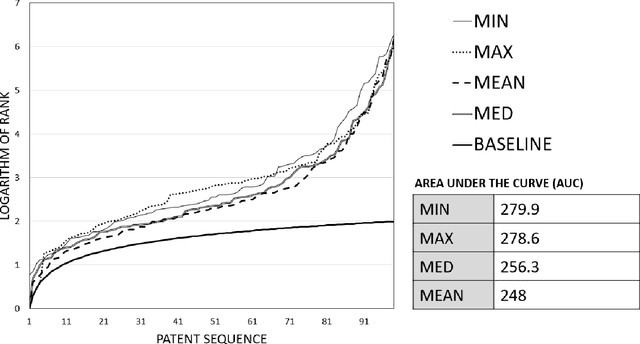
Patent retrieval influences several applications within engineering design research, education, and practice as well as applications that concern innovation, intellectual property, and knowledge management etc. In this article, we propose a method to retrieve patents relevant to an initial set of patents, by synthesizing state-of-the-art techniques among natural language processing and knowledge graph embedding. Our method involves a patent embedding that captures text, citation, and inventor information, which individually represent different facets of knowledge communicated through a patent document. We obtain text embeddings using Sentence-BERT applied to titles and abstracts. We obtain citation and inventor embeddings through TransE that is trained using the corresponding knowledge graphs. We identify using a classification task that the concatenation of text, citation, and inventor embeddings offers a plausible representation of a patent. While the proposed patent embedding could be used to associate a pair of patents, we observe using a recall task that multiple initial patents could be associated with a target patent using mean cosine similarity, which could then be utilized to rank all target patents and retrieve the most relevant ones. We apply the proposed patent retrieval method to a set of patents corresponding to a product family and an inventor's portfolio.
SAP-DETR: Bridging the Gap Between Salient Points and Queries-Based Transformer Detector for Fast Model Convergency
Nov 03, 2022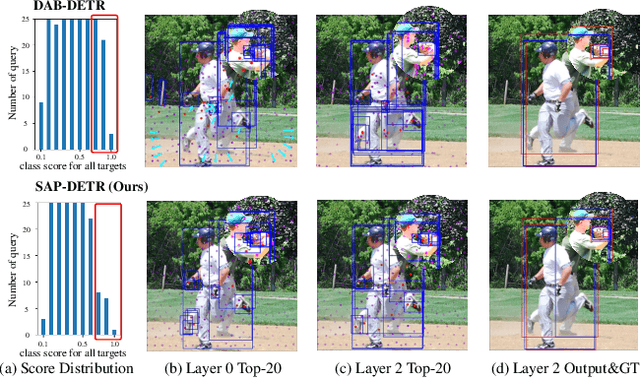
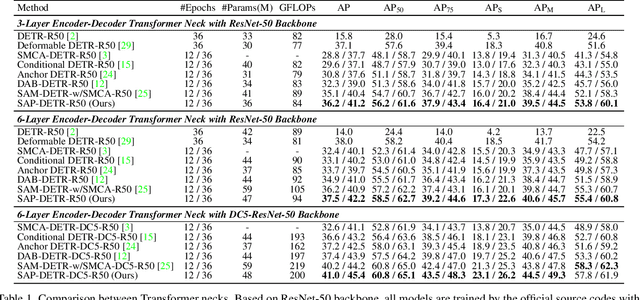
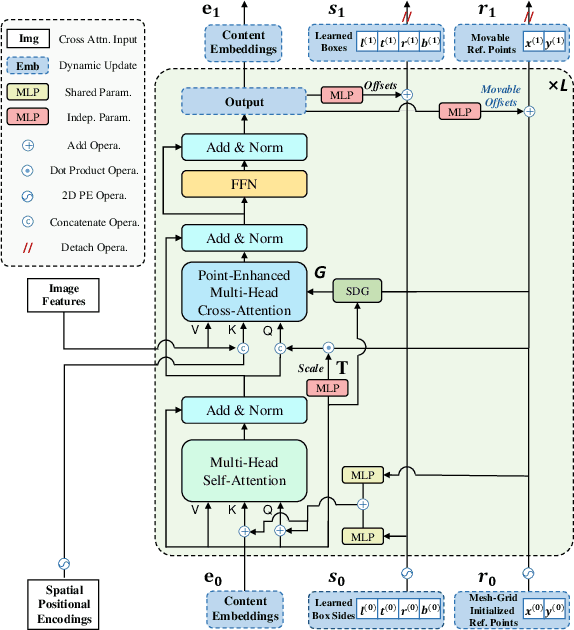

Recently, the dominant DETR-based approaches apply central-concept spatial prior to accelerate Transformer detector convergency. These methods gradually refine the reference points to the center of target objects and imbue object queries with the updated central reference information for spatially conditional attention. However, centralizing reference points may severely deteriorate queries' saliency and confuse detectors due to the indiscriminative spatial prior. To bridge the gap between the reference points of salient queries and Transformer detectors, we propose SAlient Point-based DETR (SAP-DETR) by treating object detection as a transformation from salient points to instance objects. In SAP-DETR, we explicitly initialize a query-specific reference point for each object query, gradually aggregate them into an instance object, and then predict the distance from each side of the bounding box to these points. By rapidly attending to query-specific reference region and other conditional extreme regions from the image features, SAP-DETR can effectively bridge the gap between the salient point and the query-based Transformer detector with a significant convergency speed. Our extensive experiments have demonstrated that SAP-DETR achieves 1.4 times convergency speed with competitive performance. Under the standard training scheme, SAP-DETR stably promotes the SOTA approaches by 1.0 AP. Based on ResNet-DC-101, SAP-DETR achieves 46.9 AP.
A Perceptual Quality Metric for Video Frame Interpolation
Oct 04, 2022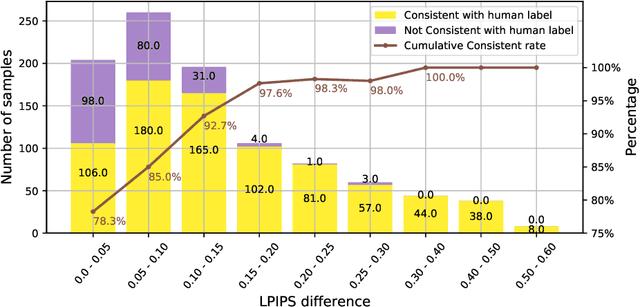
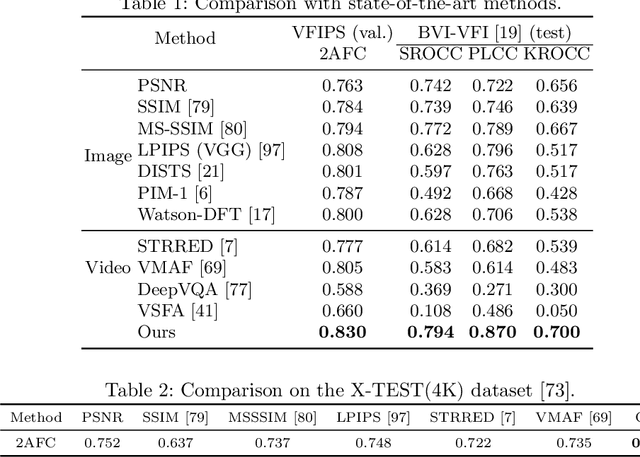

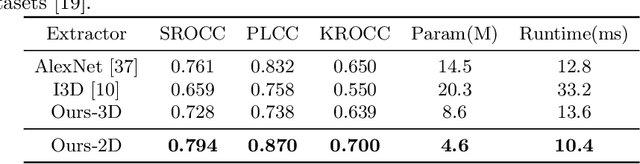
Research on video frame interpolation has made significant progress in recent years. However, existing methods mostly use off-the-shelf metrics to measure the quality of interpolation results with the exception of a few methods that employ user studies, which is time-consuming. As video frame interpolation results often exhibit unique artifacts, existing quality metrics sometimes are not consistent with human perception when measuring the interpolation results. Some recent deep learning-based perceptual quality metrics are shown more consistent with human judgments, but their performance on videos is compromised since they do not consider temporal information. In this paper, we present a dedicated perceptual quality metric for measuring video frame interpolation results. Our method learns perceptual features directly from videos instead of individual frames. It compares pyramid features extracted from video frames and employs Swin Transformer blocks-based spatio-temporal modules to extract spatio-temporal information. To train our metric, we collected a new video frame interpolation quality assessment dataset. Our experiments show that our dedicated quality metric outperforms state-of-the-art methods when measuring video frame interpolation results. Our code and model are made publicly available at \url{https://github.com/hqqxyy/VFIPS}.
Global Optimization of Energy Efficiency in IRS-Aided Communication Systems via Robust IRS-Element Activation
Oct 29, 2022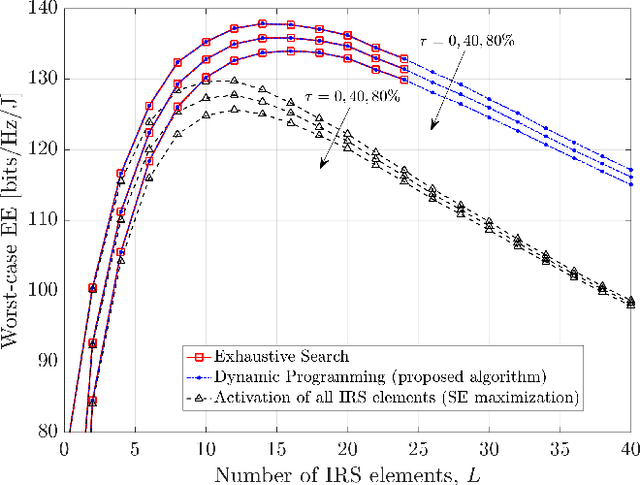
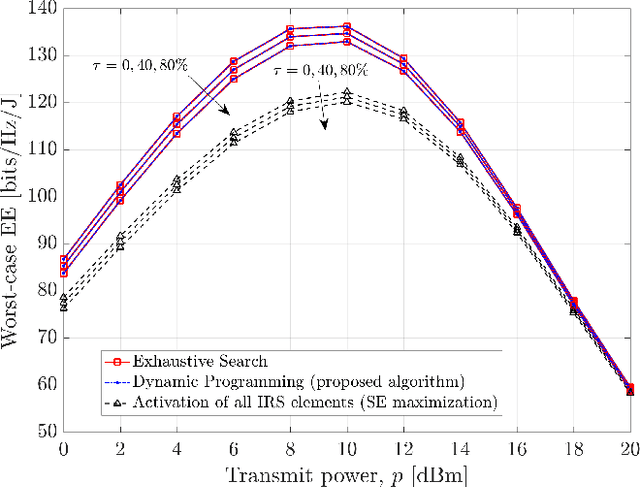
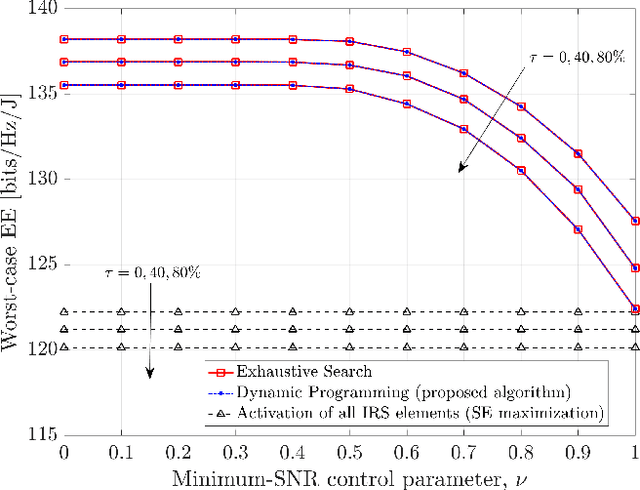
In this paper, we study an intelligent reflecting surface (IRS) assisted communication system with single-antenna transmitter and receiver, under imperfect channel state information (CSI). More specifically, we deal with the robust selection of binary (on/off) states of the IRS elements in order to maximize the worst-case energy efficiency (EE), given a bounded CSI uncertainty, while satisfying a minimum signal-to-noise ratio (SNR). The IRS phase shifts are adjusted so as to maximize the ideal SNR (i.e., without CSI error), based only on the estimated channels. First, we derive a closed-form expression of the worst-case SNR, and then formulate the robust (discrete) optimization problem. Moreover, we design and analyze a dynamic programming (DP) algorithm that is theoretically guaranteed to achieve the global maximum with polynomial complexity $O(L \log L)$, where $L$ is the number of IRS elements. Finally, numerical simulations confirm the theoretical results. In particular, the proposed algorithm shows identical performance with the exhaustive search, and significantly outperforms a baseline scheme, namely, the activation of all IRS elements.
Relating Human Perception of Musicality to Prediction in a Predictive Coding Model
Oct 29, 2022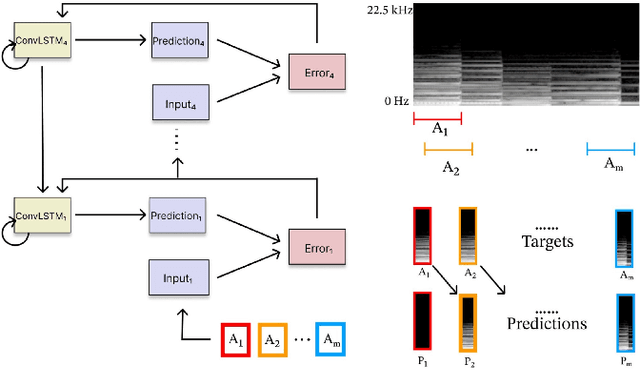
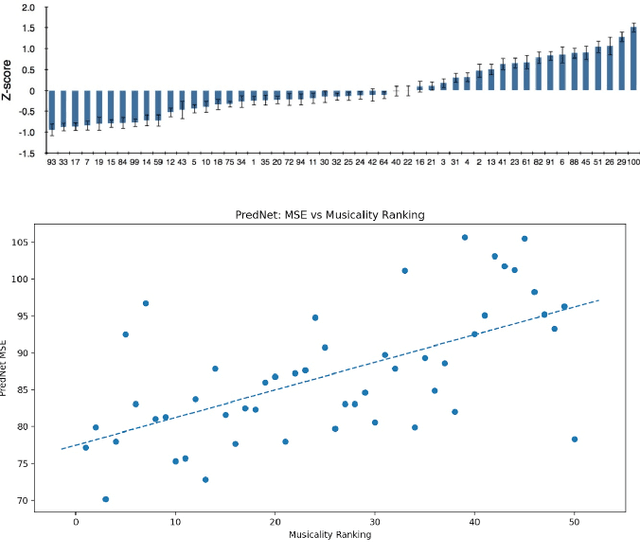
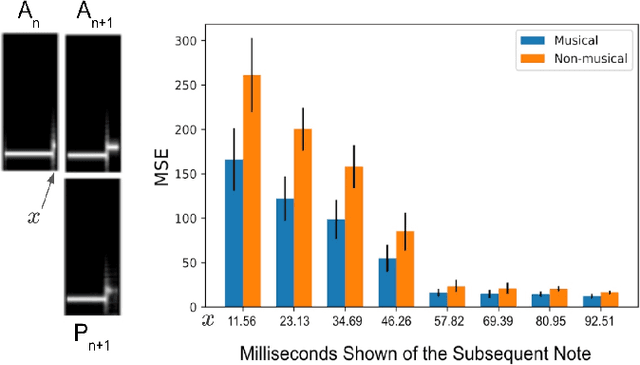
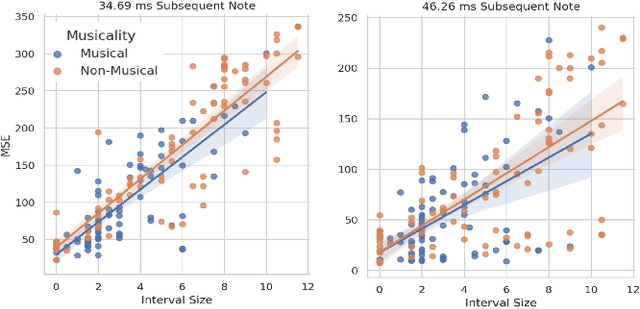
We explore the use of a neural network inspired by predictive coding for modeling human music perception. This network was developed based on the computational neuroscience theory of recurrent interactions in the hierarchical visual cortex. When trained with video data using self-supervised learning, the model manifests behaviors consistent with human visual illusions. Here, we adapt this network to model the hierarchical auditory system and investigate whether it will make similar choices to humans regarding the musicality of a set of random pitch sequences. When the model is trained with a large corpus of instrumental classical music and popular melodies rendered as mel spectrograms, it exhibits greater prediction errors for random pitch sequences that are rated less musical by human subjects. We found that the prediction error depends on the amount of information regarding the subsequent note, the pitch interval, and the temporal context. Our findings suggest that predictability is correlated with human perception of musicality and that a predictive coding neural network trained on music can be used to characterize the features and motifs contributing to human perception of music.