 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Vision Transformers for Medical Image Segmentation and Few-Shot Domain Adaptation
Paper and Code
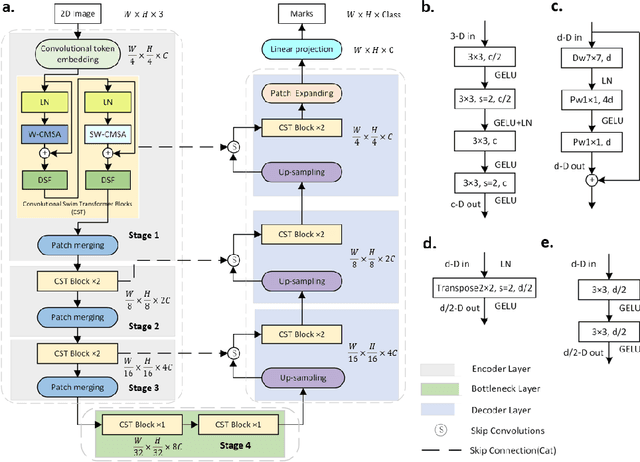
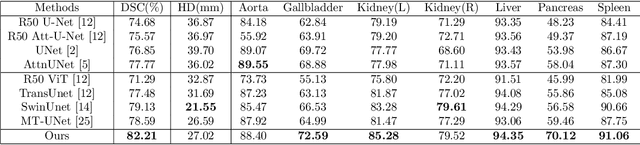
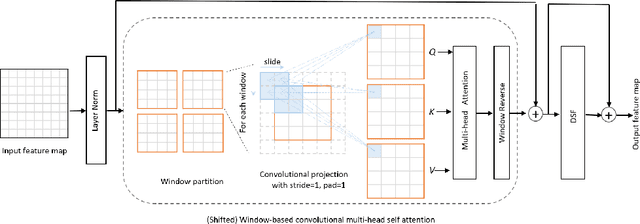
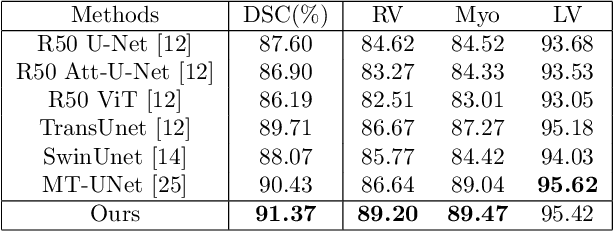
The adaptation of transformers to computer vision is not straightforward because the modelling of image contextual information results in quadratic computational complexity with relation to the input features. Most of existing methods require extensive pre-training on massive datasets such as ImageNet and therefore their application to fields such as healthcare is less effective. CNNs are the dominant architecture in computer vision tasks because convolutional filters can effectively model local dependencies and reduce drastically the parameters required. However, convolutional filters cannot handle more complex interactions, which are beyond a small neighbour of pixels. Furthermore, their weights are fixed after training and thus they do not take into consideration changes in the visual input. Inspired by recent work on hybrid visual transformers with convolutions and hierarchical transformers, we propose Convolutional Swin-Unet (CS-Unet) transformer blocks and optimise their settings with relation to patch embedding, projection, the feed-forward network, up sampling and skip connections. CS-Unet can be trained from scratch and inherits the superiority of convolutions in each feature process phase. It helps to encode precise spatial information and produce hierarchical representations that contribute to object concepts at various scales. Experiments show that CS-Unet without pre-training surpasses other state-of-the-art counterparts by large margins on two medical CT and MRI datasets with fewer parameters. In addition, two domain-adaptation experiments on optic disc and polyp image segmentation further prove that our method is highly generalizable and effectively bridges the domain gap between images from different sources.