 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Melody Infilling with User-Provided Structural Context
Oct 06, 2022
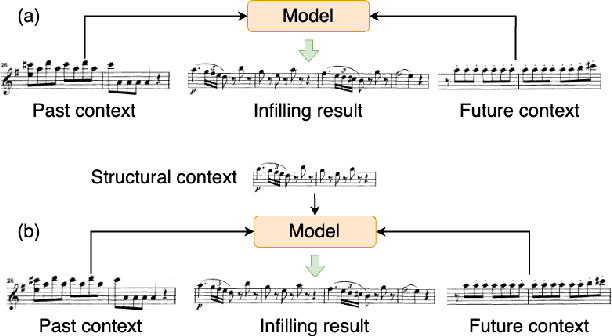
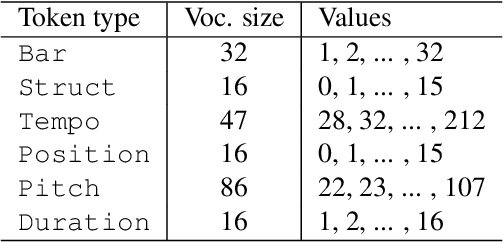
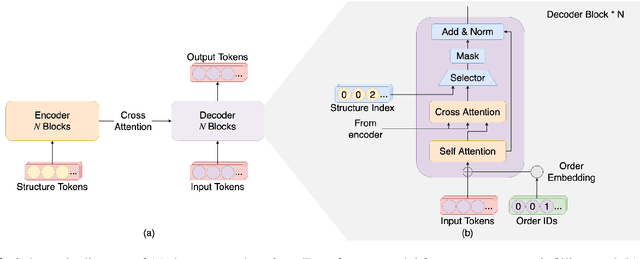
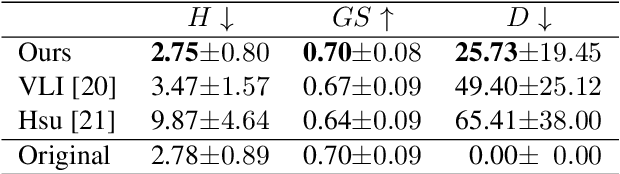
This paper proposes a novel Transformer-based model for music score infilling, to generate a music passage that fills in the gap between given past and future contexts. While existing infilling approaches can generate a passage that connects smoothly locally with the given contexts, they do not take into account the musical form or structure of the music and may therefore generate overly smooth results. To address this issue, we propose a structure-aware conditioning approach that employs a novel attention-selecting module to supply user-provided structure-related information to the Transformer for infilling. With both objective and subjective evaluations, we show that the proposed model can harness the structural information effectively and generate melodies in the style of pop of higher quality than the two existing structure-agnostic infilling models.
Music Mixing Style Transfer: A Contrastive Learning Approach to Disentangle Audio Effects
Nov 04, 2022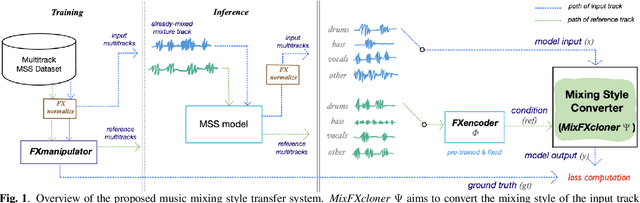
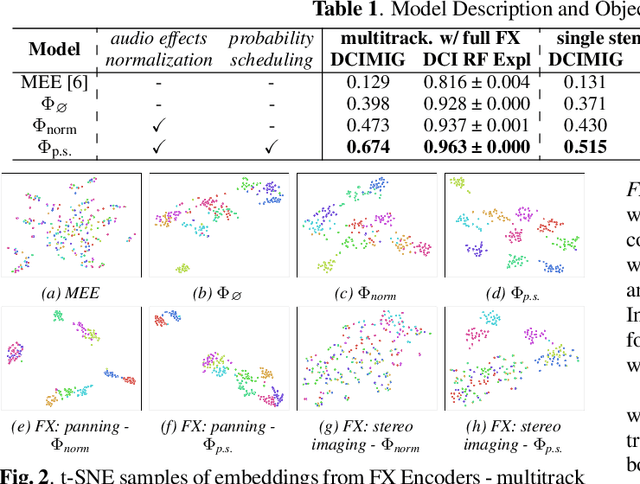
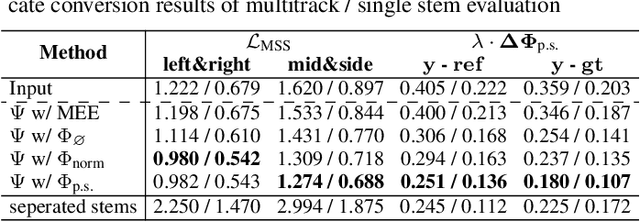
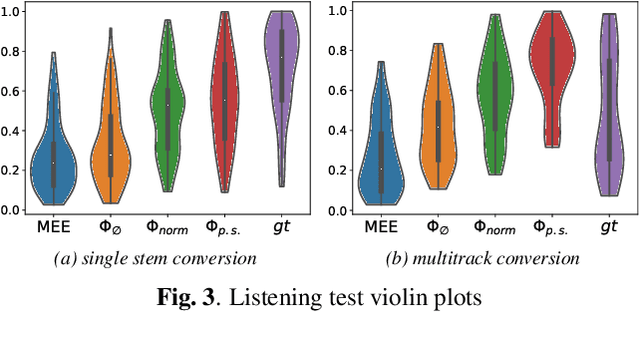
We propose an end-to-end music mixing style transfer system that converts the mixing style of an input multitrack to that of a reference song. This is achieved with an encoder pre-trained with a contrastive objective to extract only audio effects related information from a reference music recording. All our models are trained in a self-supervised manner from an already-processed wet multitrack dataset with an effective data preprocessing method that alleviates the data scarcity of obtaining unprocessed dry data. We analyze the proposed encoder for the disentanglement capability of audio effects and also validate its performance for mixing style transfer through both objective and subjective evaluations. From the results, we show the proposed system not only converts the mixing style of multitrack audio close to a reference but is also robust with mixture-wise style transfer upon using a music source separation model.
Emergent Quantized Communication
Nov 04, 2022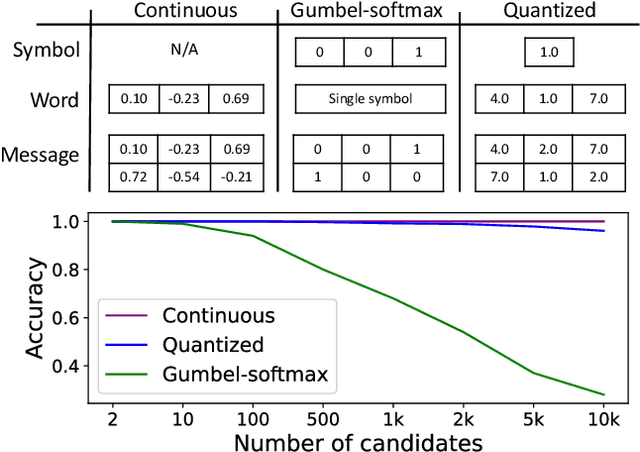
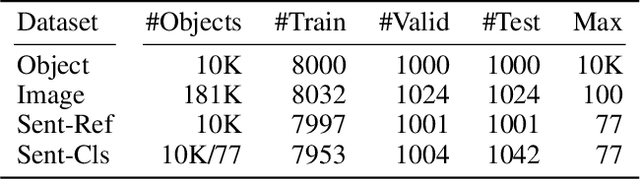
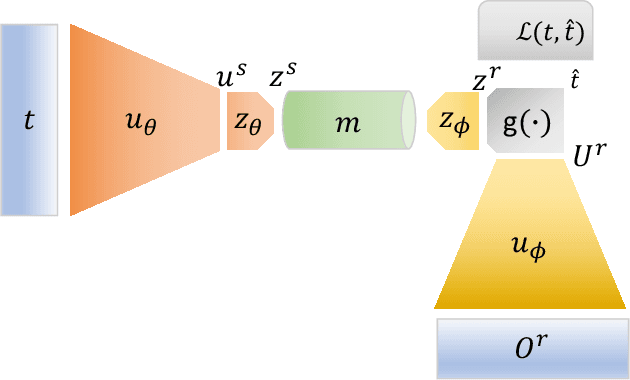
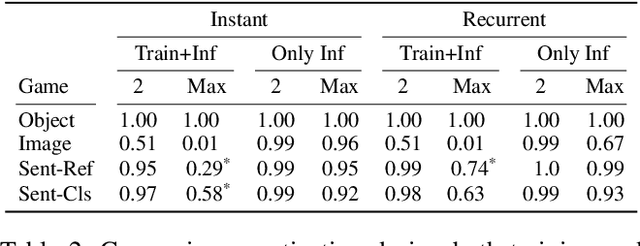
The field of emergent communication aims to understand the characteristics of communication as it emerges from artificial agents solving tasks that require information exchange. Communication with discrete messages is considered a desired characteristic, for both scientific and applied reasons. However, training a multi-agent system with discrete communication is not straightforward, requiring either reinforcement learning algorithms or relaxing the discreteness requirement via a continuous approximation such as the Gumbel-softmax. Both these solutions result in poor performance compared to fully continuous communication. In this work, we propose an alternative approach to achieve discrete communication -- quantization of communicated messages. Using message quantization allows us to train the model end-to-end, achieving superior performance in multiple setups. Moreover, quantization is a natural framework that runs the gamut from continuous to discrete communication. Thus, it sets the ground for a broader view of multi-agent communication in the deep learning era.
Beyond the density operator and Tr(ρA): Exploiting the higher-order statistics of random-coefficient pure states for quantum information processing
Apr 21, 2022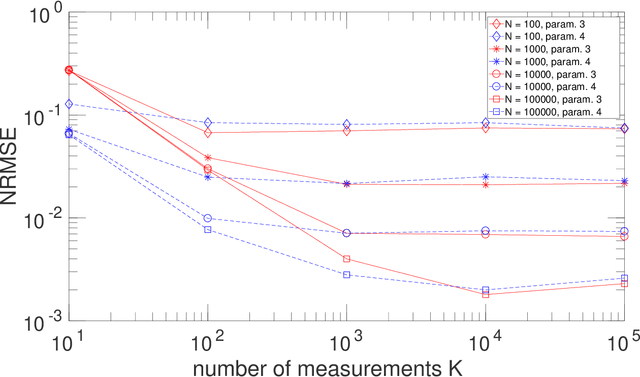
Two types of states are widely used in quantum mechanics, namely (deterministic-coefficient) pure states and statistical mixtures. A density operator can be associated with each of them. We here address a third type of states, that we previously introduced in a more restricted framework. These states generalize pure ones by replacing each of their deterministic ket coefficients by a random variable. We therefore call them Random-Coefficient Pure States, or RCPS. We analyze their properties and their relationships with both types of usual states. We show that RCPS contain much richer information than the density operator and mean of observables that we associate with them. This occurs because the latter operator only exploits the second-order statistics of the random state coefficients, whereas their higher-order statistics contain additional information. That information can be accessed in practice with the multiple-preparation procedure that we propose for RCPS, by using second-order and higher-order statistics of associated random probabilities of measurement outcomes. Exploiting these higher-order statistics opens the way to a very general approach for performing advanced quantum information processing tasks. We illustrate the relevance of this approach with a generic example, dealing with the estimation of parameters of a quantum process and thus related to quantum process tomography. This parameter estimation is performed in the non-blind (i.e. supervised) or blind (i.e. unsupervised) mode. We show that this problem cannot be solved by using only the density operator \rho of an RCPS and the associated mean value Tr(\rho A) of the operator A that corresponds to the considered physical quantity. We succeed in solving this problem by exploiting a fourth-order statistical parameter of state coefficients, in addition to second-order statistics. Numerical tests validate this result.
SA-MLP: Distilling Graph Knowledge from GNNs into Structure-Aware MLP
Oct 18, 2022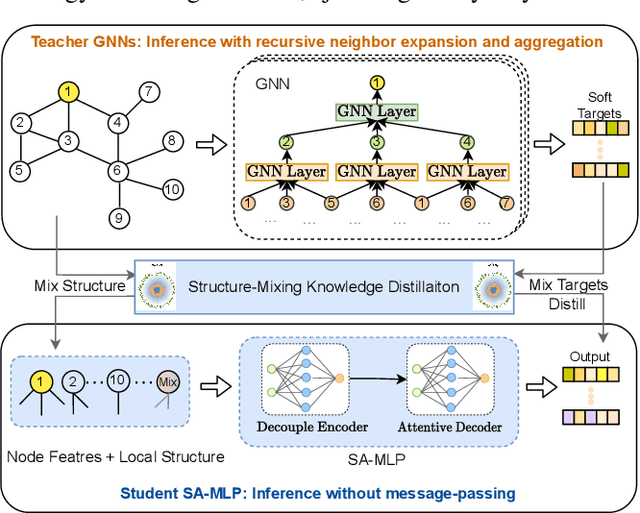
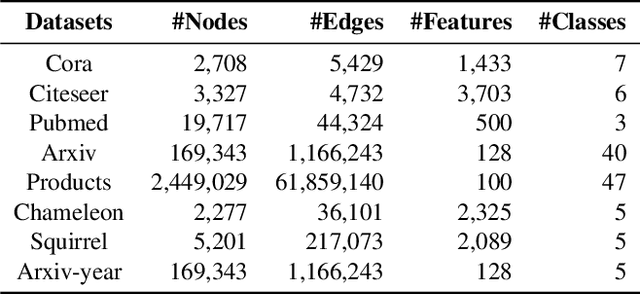

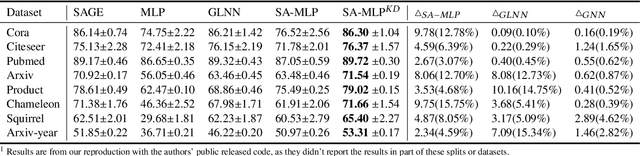
The message-passing mechanism helps Graph Neural Networks (GNNs) achieve remarkable results on various node classification tasks. Nevertheless, the recursive nodes fetching and aggregation in message-passing cause inference latency when deploying GNNs to large-scale graphs. One promising inference acceleration direction is to distill the GNNs into message-passing-free student multi-layer perceptrons (MLPs). However, the MLP student cannot fully learn the structure knowledge due to the lack of structure inputs, which causes inferior performance in the heterophily and inductive scenarios. To address this, we intend to inject structure information into MLP-like students in low-latency and interpretable ways. Specifically, we first design a Structure-Aware MLP (SA-MLP) student that encodes both features and structures without message-passing. Then, we introduce a novel structure-mixing knowledge distillation strategy to enhance the learning ability of MLPs for structure information. Furthermore, we design a latent structure embedding approximation technique with two-stage distillation for inductive scenarios. Extensive experiments on eight benchmark datasets under both transductive and inductive settings show that our SA-MLP can consistently outperform the teacher GNNs, while maintaining faster inference as MLPs. The source code of our work can be found in https://github.com/JC-202/SA-MLP.
Prediction of drug effectiveness in rheumatoid arthritis patients based on machine learning algorithms
Oct 18, 2022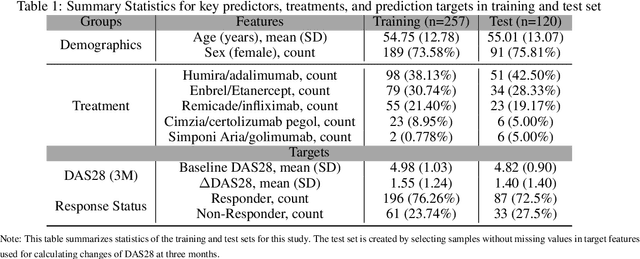
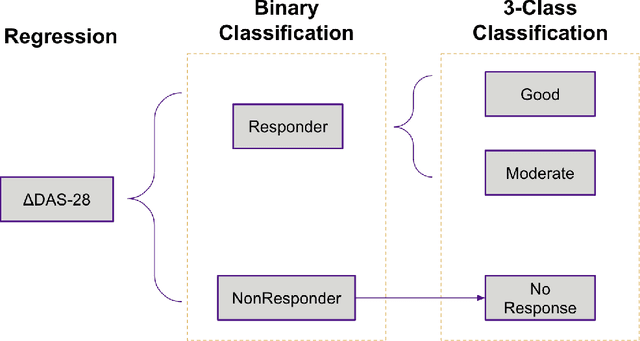

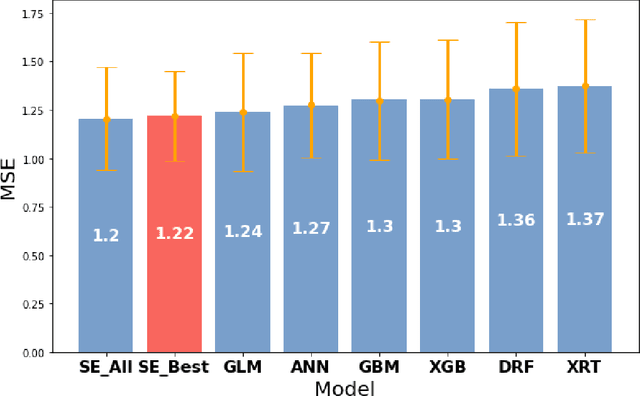
Rheumatoid arthritis (RA) is an autoimmune condition caused when patients' immune system mistakenly targets their own tissue. Machine learning (ML) has the potential to identify patterns in patient electronic health records (EHR) to forecast the best clinical treatment to improve patient outcomes. This study introduced a Drug Response Prediction (DRP) framework with two main goals: 1) design a data processing pipeline to extract information from tabular clinical data, and then preprocess it for functional use, and 2) predict RA patient's responses to drugs and evaluate classification models' performance. We propose a novel two-stage ML framework based on European Alliance of Associations for Rheumatology (EULAR) criteria cutoffs to model drug effectiveness. Our model Stacked-Ensemble DRP was developed and cross-validated using data from 425 RA patients. The evaluation used a subset of 124 patients (30%) from the same data source. In the evaluation of the test set, two-stage DRP leads to improved classification accuracy over other end-to-end classification models for binary classification. Our proposed method provides a complete pipeline to predict disease activity scores and identify the group that does not respond well to anti-TNF treatments, thus showing promise in supporting clinical decisions based on EHR information.
Contextualized Generative Retrieval
Oct 05, 2022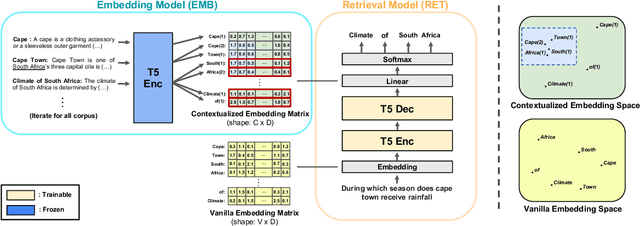
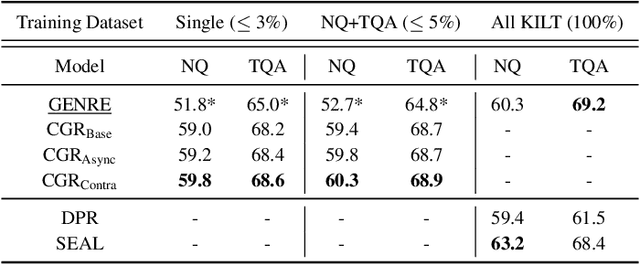
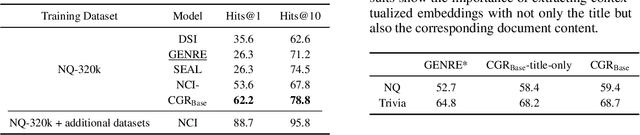
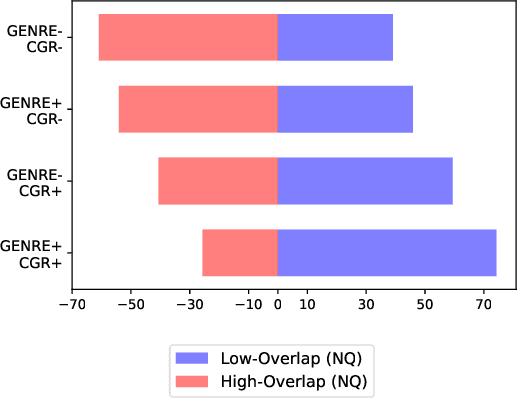
The text retrieval task is mainly performed in two ways: the bi-encoder approach and the generative approach. The bi-encoder approach maps the document and query embeddings to common vector space and performs a nearest neighbor search. It stably shows high performance and efficiency across different domains but has an embedding space bottleneck as it interacts in L2 or inner product space. The generative retrieval model retrieves by generating a target sequence and overcomes the embedding space bottleneck by interacting in the parametric space. However, it fails to retrieve the information it has not seen during the training process as it depends solely on the information encoded in its own model parameters. To leverage the advantages of both approaches, we propose Contextualized Generative Retrieval model, which uses contextualized embeddings (output embeddings of a language model encoder) as vocab embeddings at the decoding step of generative retrieval. The model uses information encoded in both the non-parametric space of contextualized token embeddings and the parametric space of the generative retrieval model. Our approach of generative retrieval with contextualized vocab embeddings shows higher performance than generative retrieval with only vanilla vocab embeddings in the document retrieval task, an average of 6% higher performance in KILT (NQ, TQA) and 2X higher in NQ-320k, suggesting the benefits of using contextualized embedding in generative retrieval models.
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Nov 17, 2022


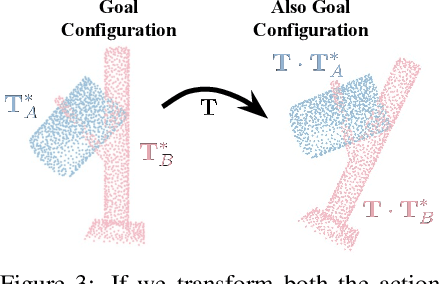
How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship ``cross-pose" and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method's capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks. Supplementary information and videos can be found at https://sites.google.com/view/tax-pose/home.
Problem Behaviors Recognition in Videos using Language-Assisted Deep Learning Model for Children with Autism
Nov 17, 2022

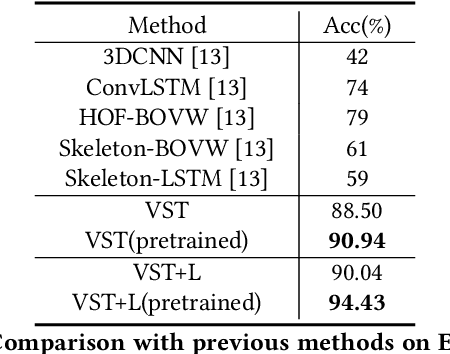
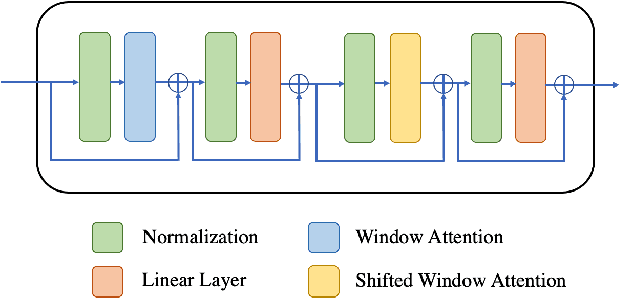
Correctly recognizing the behaviors of children with Autism Spectrum Disorder (ASD) is of vital importance for the diagnosis of Autism and timely early intervention. However, the observation and recording during the treatment from the parents of autistic children may not be accurate and objective. In such cases, automatic recognition systems based on computer vision and machine learning (in particular deep learning) technology can alleviate this issue to a large extent. Existing human action recognition models can now achieve persuasive performance on challenging activity datasets, e.g. daily activity, and sports activity. However, problem behaviors in children with ASD are very different from these general activities, and recognizing these problem behaviors via computer vision is less studied. In this paper, we first evaluate a strong baseline for action recognition, i.e. Video Swin Transformer, on two autism behaviors datasets (SSBD and ESBD) and show that it can achieve high accuracy and outperform the previous methods by a large margin, demonstrating the feasibility of vision-based problem behaviors recognition. Moreover, we propose language-assisted training to further enhance the action recognition performance. Specifically, we develop a two-branch multimodal deep learning framework by incorporating the "freely available" language description for each type of problem behavior. Experimental results demonstrate that incorporating additional language supervision can bring an obvious performance boost for the autism problem behaviors recognition task as compared to using the video information only (i.e. 3.49% improvement on ESBD and 1.46% on SSBD).
GLFF: Global and Local Feature Fusion for Face Forgery Detection
Nov 17, 2022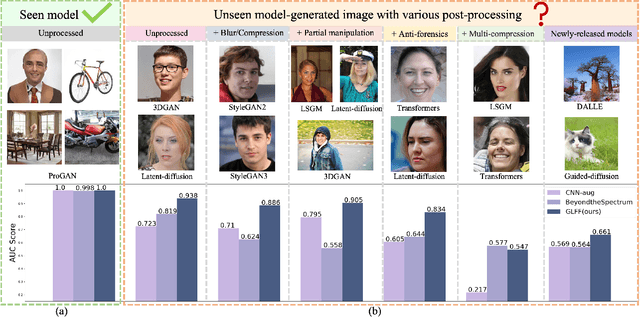
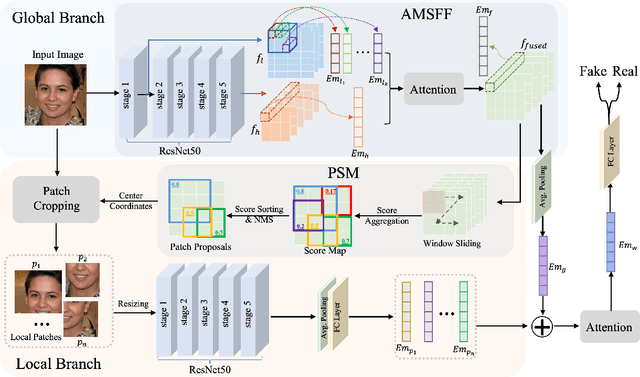
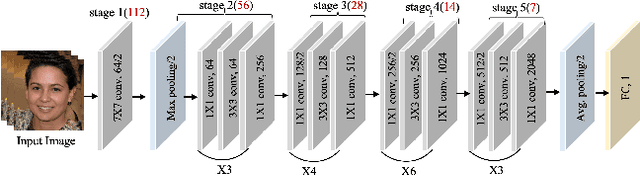

With the rapid development of deep generative models (such as Generative Adversarial Networks and Auto-encoders), AI-synthesized images of the human face are now of such high quality that humans can hardly distinguish them from pristine ones. Although existing detection methods have shown high performance in specific evaluation settings, e.g., on images from seen models or on images without real-world post-processings, they tend to suffer serious performance degradation in real-world scenarios where testing images can be generated by more powerful generation models or combined with various post-processing operations. To address this issue, we propose a Global and Local Feature Fusion (GLFF) to learn rich and discriminative representations by combining multi-scale global features from the whole image with refined local features from informative patches for face forgery detection. GLFF fuses information from two branches: the global branch to extract multi-scale semantic features and the local branch to select informative patches for detailed local artifacts extraction. Due to the lack of a face forgery dataset simulating real-world applications for evaluation, we further create a challenging face forgery dataset, named DeepFakeFaceForensics (DF^3), which contains 6 state-of-the-art generation models and a variety of post-processing techniques to approach the real-world scenarios. Experimental results demonstrate the superiority of our method to the state-of-the-art methods on the proposed DF^3 dataset and three other open-source datasets.