 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-MLP: Distilling Graph Knowledge from GNNs into Structure-Aware MLP
Paper and Code
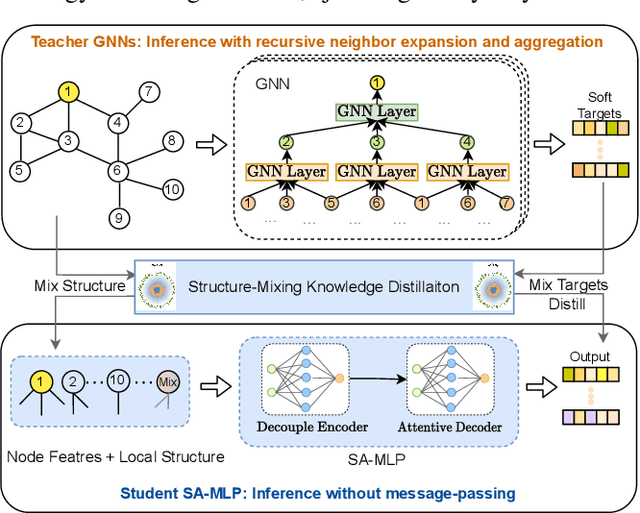
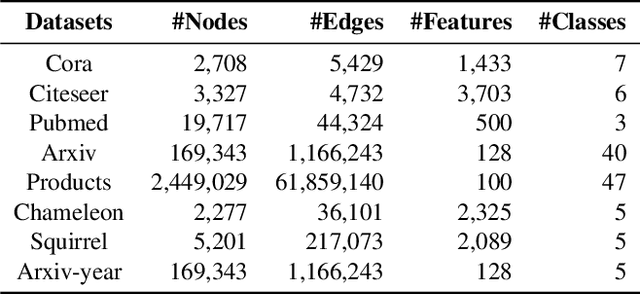

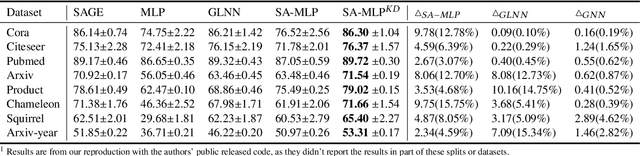
The message-passing mechanism helps Graph Neural Networks (GNNs) achieve remarkable results on various node classification tasks. Nevertheless, the recursive nodes fetching and aggregation in message-passing cause inference latency when deploying GNNs to large-scale graphs. One promising inference acceleration direction is to distill the GNNs into message-passing-free student multi-layer perceptrons (MLPs). However, the MLP student cannot fully learn the structure knowledge due to the lack of structure inputs, which causes inferior performance in the heterophily and inductive scenarios. To address this, we intend to inject structure information into MLP-like students in low-latency and interpretable ways. Specifically, we first design a Structure-Aware MLP (SA-MLP) student that encodes both features and structures without message-passing. Then, we introduce a novel structure-mixing knowledge distillation strategy to enhance the learning ability of MLPs for structure information. Furthermore, we design a latent structure embedding approximation technique with two-stage distillation for inductive scenarios. Extensive experiments on eight benchmark datasets under both transductive and inductive settings show that our SA-MLP can consistently outperform the teacher GNNs, while maintaining faster inference as MLPs. The source code of our work can be found in https://github.com/JC-202/SA-MLP.