 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integral Continual Learning Along the Tangent Vector Field of Tasks
Nov 23, 2022
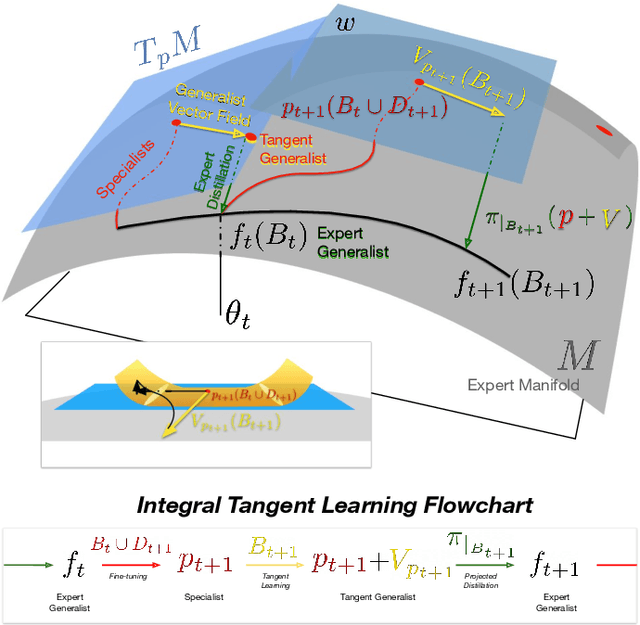
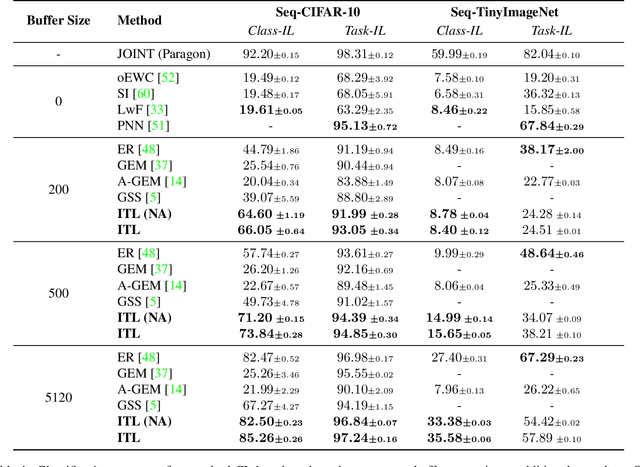
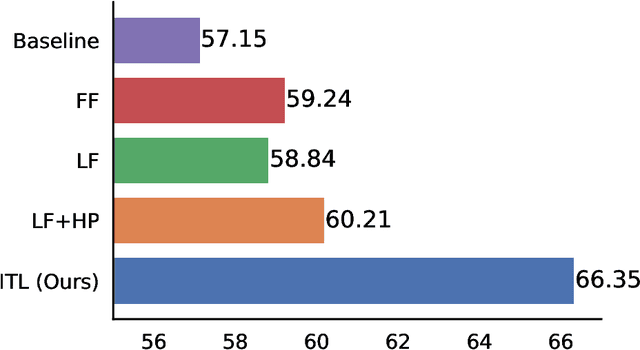
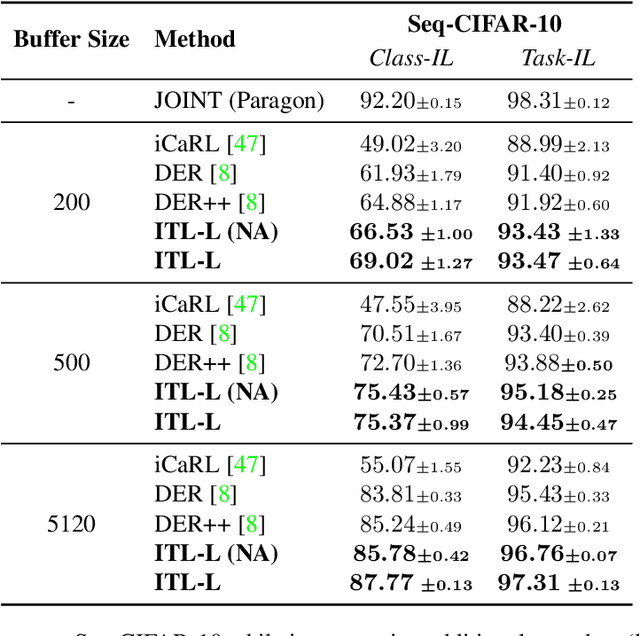
We propose a continual learning method which incorporates information from specialized datasets incrementally, by integrating it along the vector field of "generalist" models. The tangent plane to the specialist model acts as a generalist guide and avoids the kind of over-fitting that leads to catastrophic forgetting, while exploiting the convexity of the optimization landscape in the tangent plane. It maintains a small fixed-size memory buffer, as low as 0.4% of the source datasets, which is updated by simple resampling. Our method achieves state-of-the-art across various buffer sizes for different datasets. Specifically, in the class-incremental setting we outperform the existing methods by an average of 26.24% and 28.48%, for Seq-CIFAR-10 and Seq-TinyImageNet respectively. Our method can easily be combined with existing replay-based continual learning methods. When memory buffer constraints are relaxed to allow storage of other metadata such as logits, we attain state-of-the-art accuracy with an error reduction of 36% towards the paragon performance on Seq-CIFAR-10.
Hardness-guided domain adaptation to recognise biomedical named entities under low-resource scenarios
Nov 11, 2022
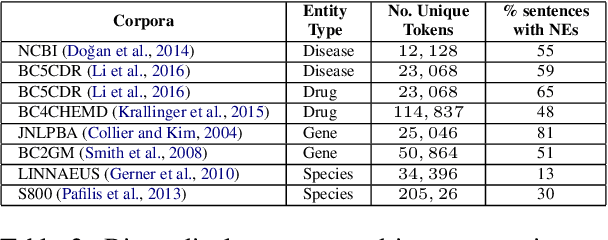
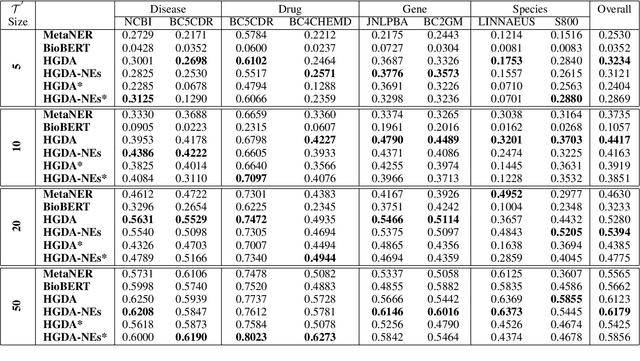
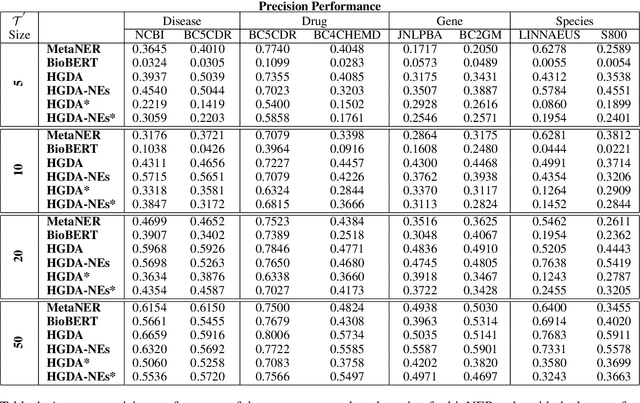
Domain adaptation is an effective solution to data scarcity in low-resource scenarios. However, when applied to token-level tasks such as bioNER, domain adaptation methods often suffer from the challenging linguistic characteristics that clinical narratives possess, which leads to unsatisfactory performance. In this paper, we present a simple yet effective hardness-guided domain adaptation (HGDA) framework for bioNER tasks that can effectively leverage the domain hardness information to improve the adaptability of the learnt model in low-resource scenarios. Experimental results on biomedical datasets show that our model can achieve significant performance improvement over the recently published state-of-the-art (SOTA) MetaNER model
Rich Knowledge Sources Bring Complex Knowledge Conflicts: Recalibrating Models to Reflect Conflicting Evidence
Oct 25, 2022

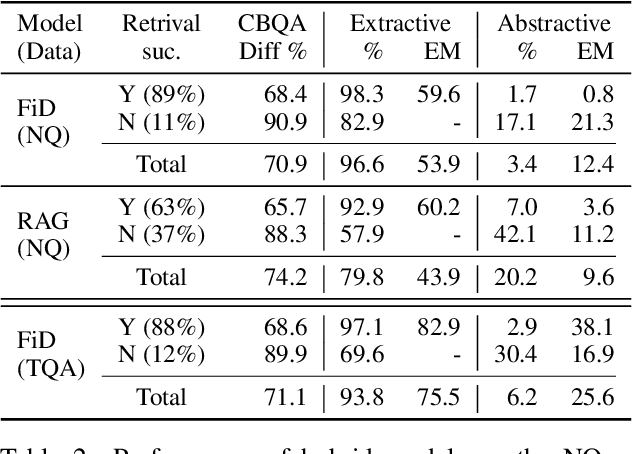
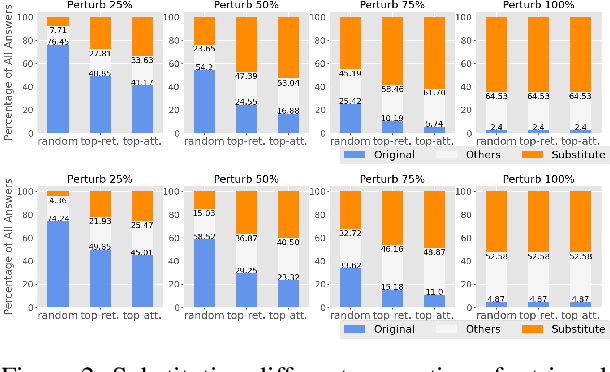
Question answering models can use rich knowledge sources -- up to one hundred retrieved passages and parametric knowledge in the large-scale language model (LM). Prior work assumes information in such knowledge sources is consistent with each other, paying little attention to how models blend information stored in their LM parameters with that from retrieved evidence documents. In this paper, we simulate knowledge conflicts (i.e., where parametric knowledge suggests one answer and different passages suggest different answers) and examine model behaviors. We find retrieval performance heavily impacts which sources models rely on, and current models mostly rely on non-parametric knowledge in their best-performing settings. We discover a troubling trend that contradictions among knowledge sources affect model confidence only marginally. To address this issue, we present a new calibration study, where models are discouraged from presenting any single answer when presented with multiple conflicting answer candidates in retrieved evidences.
Short Paper: Static and Microarchitectural ML-Based Approaches For Detecting Spectre Vulnerabilities and Attacks
Oct 26, 2022Spectre intrusions exploit speculative execution design vulnerabilities in modern processors. The attacks violate the principles of isolation in programs to gain unauthorized private user information. Current state-of-the-art detection techniques utilize micro-architectural features or vulnerable speculative code to detect these threats. However, these techniques are insufficient as Spectre attacks have proven to be more stealthy with recently discovered variants that bypass current mitigation mechanisms. Side-channels generate distinct patterns in processor cache, and sensitive information leakage is dependent on source code vulnerable to Spectre attacks, where an adversary uses these vulnerabilities, such as branch prediction, which causes a data breach. Previous studies predominantly approach the detection of Spectre attacks using the microarchitectural analysis, a reactive approach. Hence, in this paper, we present the first comprehensive evaluation of static and microarchitectural analysis-assisted machine learning approaches to detect Spectre vulnerable code snippets (preventive) and Spectre attacks (reactive). We evaluate the performance trade-offs in employing classifiers for detecting Spectre vulnerabilities and attacks.
A Transformer-based Framework for POI-level Social Post Geolocation
Oct 26, 2022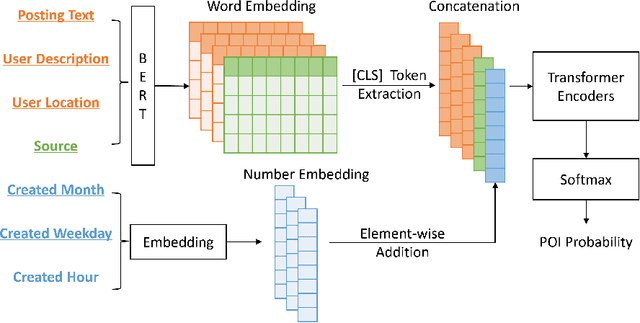
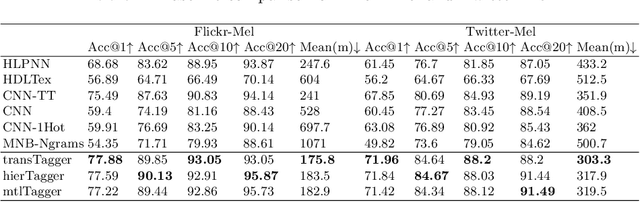

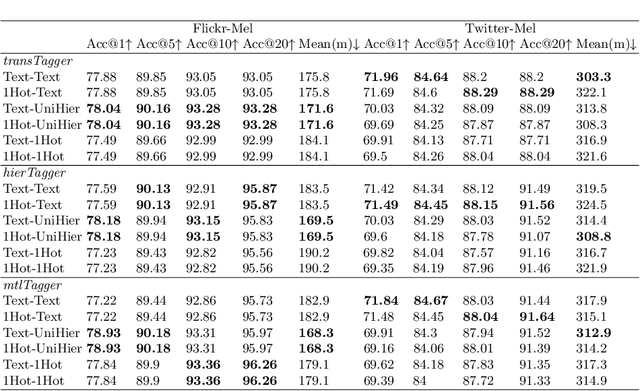
POI-level geo-information of social posts is critical to many location-based applications and services. However, the multi-modality, complexity and diverse nature of social media data and their platforms limit the performance of inferring such fine-grained locations and their subsequent applications. To address this issue, we present a transformer-based general framework, which builds upon pre-trained language models and considers non-textual data, for social post geolocation at the POI level. To this end, inputs are categorized to handle different social data, and an optimal combination strategy is provided for feature representations. Moreover, a uniform representation of hierarchy is proposed to learn temporal information, and a concatenated version of encodings is employed to capture feature-wise positions better. Experimental results on various social datasets demonstrate that three variants of our proposed framework outperform multiple state-of-art baselines by a large margin in terms of accuracy and distance error metrics.
FAF: A novel multimodal emotion recognition approach integrating face, body and text
Nov 20, 2022

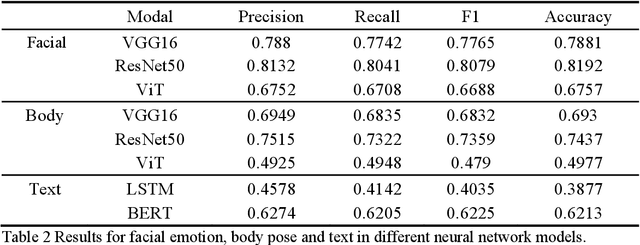
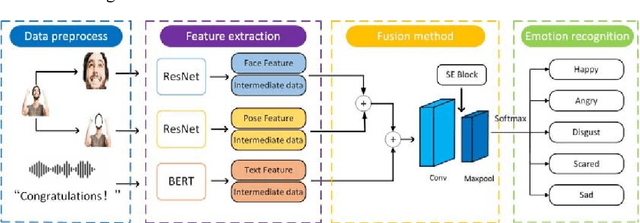
Multimodal emotion analysis performed better in emotion recognition depending on more comprehensive emotional clues and multimodal emotion dataset. In this paper, we developed a large multimodal emotion dataset, named "HED" dataset, to facilitate the emotion recognition task, and accordingly propose a multimodal emotion recognition method. To promote recognition accuracy, "Feature After Feature" framework was used to explore crucial emotional information from the aligned face, body and text samples. We employ various benchmarks to evaluate the "HED" dataset and compare the performance with our method. The results show that the five classification accuracy of the proposed multimodal fusion method is about 83.75%, and the performance is improved by 1.83%, 9.38%, and 21.62% respectively compared with that of individual modalities. The complementarity between each channel is effectively used to improve the performance of emotion recognition. We had also established a multimodal online emotion prediction platform, aiming to provide free emotion prediction to more users.
RHCO: A Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning for Large-scale Graphs
Nov 20, 2022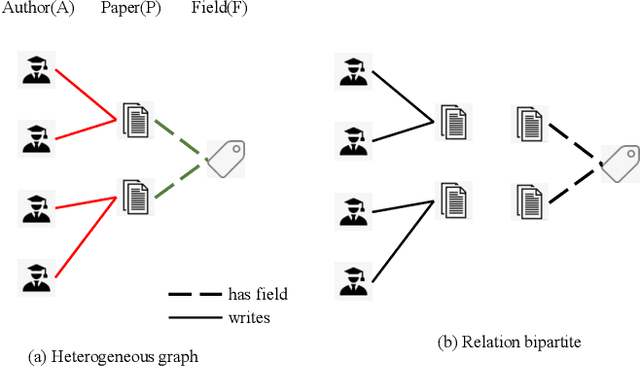
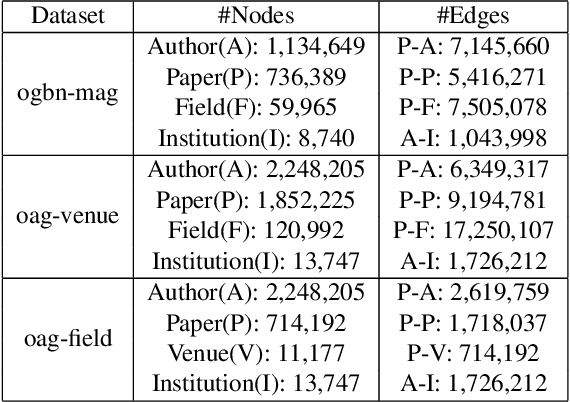
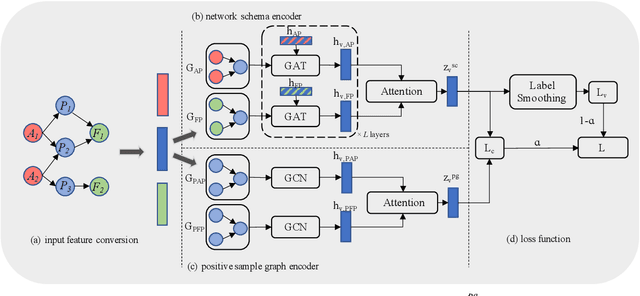
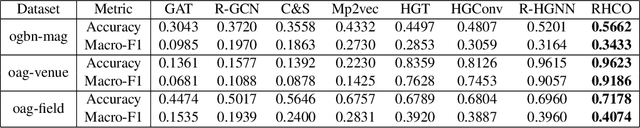
Heterogeneous graph neural networks (HGNNs) have been widely applied in heterogeneous information network tasks, while most HGNNs suffer from poor scalability or weak representation when they are applied to large-scale heterogeneous graphs. To address these problems, we propose a novel Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning (RHCO) for large-scale heterogeneous graph representation learning. Unlike traditional heterogeneous graph neural networks, we adopt the contrastive learning mechanism to deal with the complex heterogeneity of large-scale heterogeneous graphs. We first learn relation-aware node embeddings under the network schema view. Then we propose a novel positive sample selection strategy to choose meaningful positive samples. After learning node embeddings under the positive sample graph view, we perform a cross-view contrastive learning to obtain the final node representations. Moreover, we adopt the label smoothing technique to boost the performance of RHCO. Extensive experiments on three large-scale academic heterogeneous graph datasets show that RHCO achieves best performance over the state-of-the-art models.
ThreshNet: Segmentation Refinement Inspired by Region-Specific Thresholding
Nov 20, 2022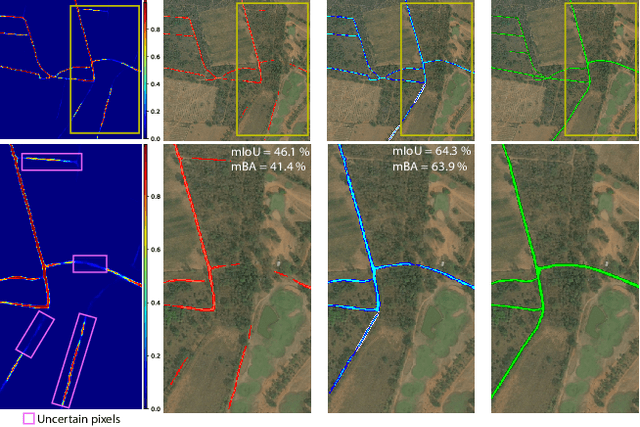
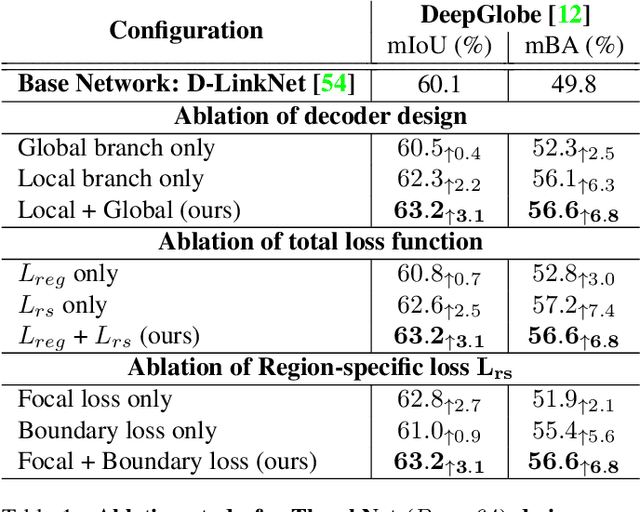
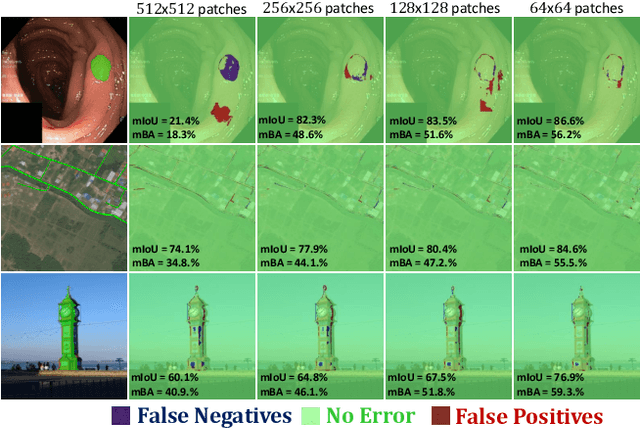
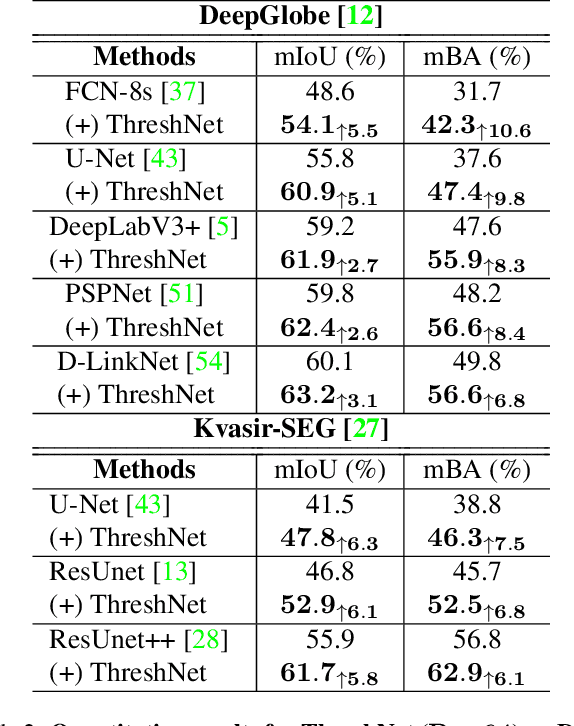
We present ThreshNet, a post-processing method to refine the output of neural networks designed for binary segmentation tasks. ThreshNet uses the confidence map produced by a base network along with global and local patch information to significantly improve the performance of even state-of-the-art methods. Binary segmentation models typically convert confidence maps into predictions by thresholding the confidence scores at 0.5 (or some other fixed number). However, we observe that the best threshold is image-dependent and often even region-specific -- different parts of the image benefit from using different thresholds. Thus ThreshNet takes a trained segmentation model and learns to correct its predictions by using a memory-efficient post-processing architecture that incorporates region-specific thresholds as part of the training mechanism. Our experiments show that ThreshNet consistently improves over current the state-of-the-art methods in binary segmentation and saliency detection, typically by 3 to 5% in mIoU and mBA.
ECM-OPCC: Efficient Context Model for Octree-based Point Cloud Compression
Nov 20, 2022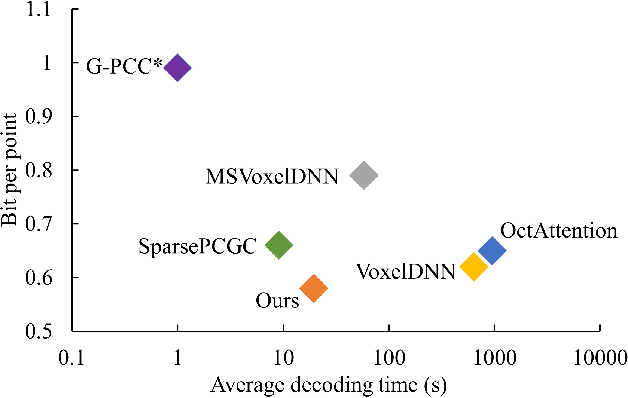
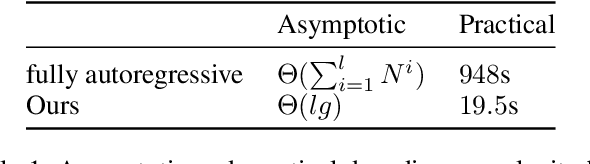
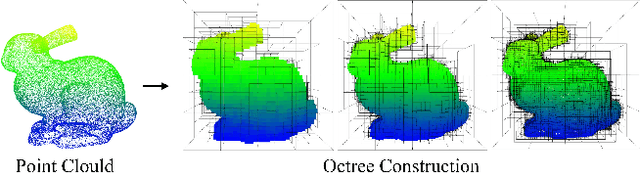
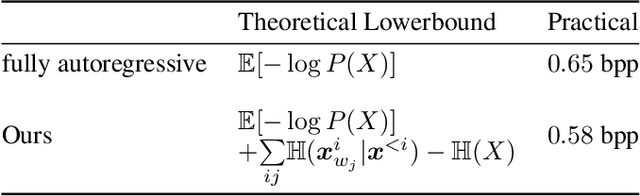
Recently, deep learning methods have shown promising results in point cloud compression. For octree-based point cloud compression, previous works show that the information of ancestor nodes and sibling nodes are equally important for predicting current node. However, those works either adopt insufficient context or bring intolerable decoding complexity (e.g. >600s). To address this problem, we propose a sufficient yet efficient context model and design an efficient deep learning codec for point clouds. Specifically, we first propose a window-constrained multi-group coding strategy to exploit the autoregressive context while maintaining decoding efficiency. Then, we propose a dual transformer architecture to utilize the dependency of current node on its ancestors and siblings. We also propose a random-masking pre-train method to enhance our model. Experimental results show that our approach achieves state-of-the-art performance for both lossy and lossless point cloud compression. Moreover, our multi-group coding strategy saves 98% decoding time compared with previous octree-based compression method.
Relational Symmetry based Knowledge Graph Contrastive Learning
Nov 25, 2022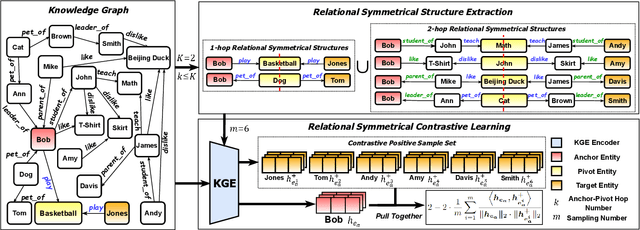

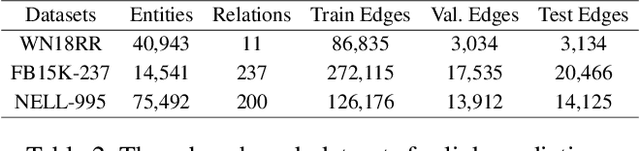
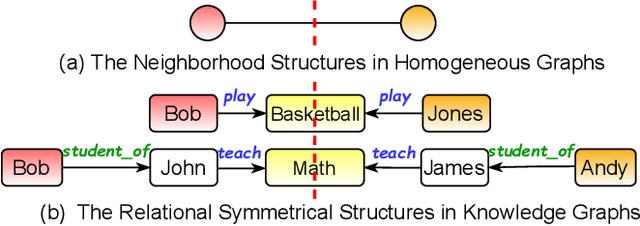
Knowledge graph embedding (KGE) aims to learn powerful representations to benefit various artificial intelligence applications, such as question answering and recommendations. Meanwhile, contrastive learning (CL), as an effective mechanism to enhance the discriminative capacity of the learned representations, has been leveraged in different fields, especially graph-based models. However, since the structures of knowledge graphs (KGs) are usually more complicated compared to homogeneous graphs, it is hard to construct appropriate contrastive sample pairs. In this paper, we find that the entities within a symmetrical structure are usually more similar and correlated. This key property can be utilized to construct contrastive positive pairs for contrastive learning. Following the ideas above, we propose a relational symmetrical structure based knowledge graph contrastive learning framework, termed KGE-SymCL, which leverages the symmetrical structure information in KGs to enhance the discriminative ability of KGE models. Concretely, a plug-and-play approach is designed by taking the entities in the relational symmetrical positions as the positive samples. Besides, a self-supervised alignment loss is used to pull together the constructed positive sample pairs for contrastive learning. Extensive experimental results on benchmark datasets have verified the good generalization and superiority of the proposed framework.