 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MambaMIL: Enhancing Long Sequence Modeling with Sequence Reordering in Computational Pathology
Mar 11, 2024
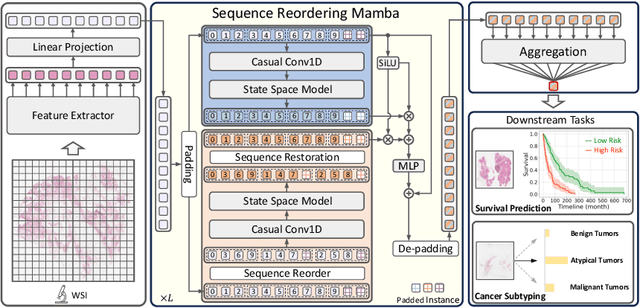
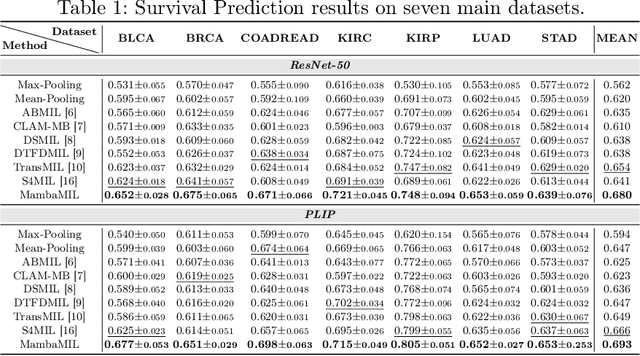
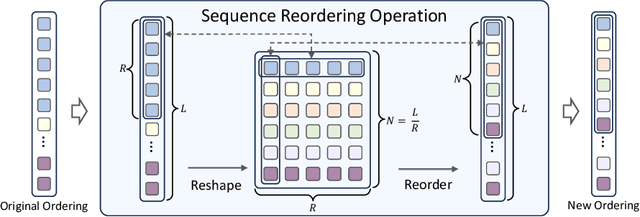
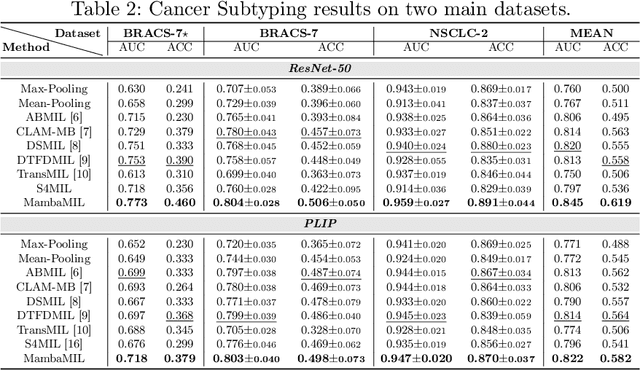
Multiple Instance Learning (MIL) has emerged as a dominant paradigm to extract discriminative feature representations within Whole Slide Images (WSIs) in computational pathology. Despite driving notable progress, existing MIL approaches suffer from limitations in facilitating comprehensive and efficient interactions among instances, as well as challenges related to time-consuming computations and overfitting. In this paper, we incorporate the Selective Scan Space State Sequential Model (Mamba) in Multiple Instance Learning (MIL) for long sequence modeling with linear complexity, termed as MambaMIL. By inheriting the capability of vanilla Mamba, MambaMIL demonstrates the ability to comprehensively understand and perceive long sequences of instances. Furthermore, we propose the Sequence Reordering Mamba (SR-Mamba) aware of the order and distribution of instances, which exploits the inherent valuable information embedded within the long sequences. With the SR-Mamba as the core component, MambaMIL can effectively capture more discriminative features and mitigate the challenges associated with overfitting and high computational overhead. Extensive experiments on two public challenging tasks across nine diverse datasets demonstrate that our proposed framework performs favorably against state-of-the-art MIL methods. The code is released at https://github.com/isyangshu/MambaMIL.
AuG-KD: Anchor-Based Mixup Generation for Out-of-Domain Knowledge Distillation
Mar 11, 2024
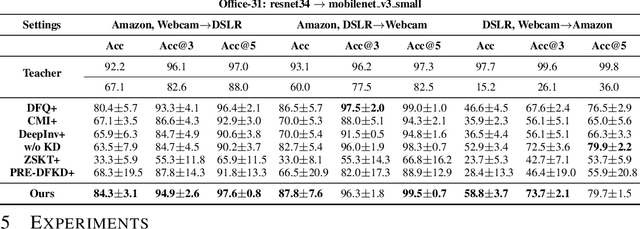
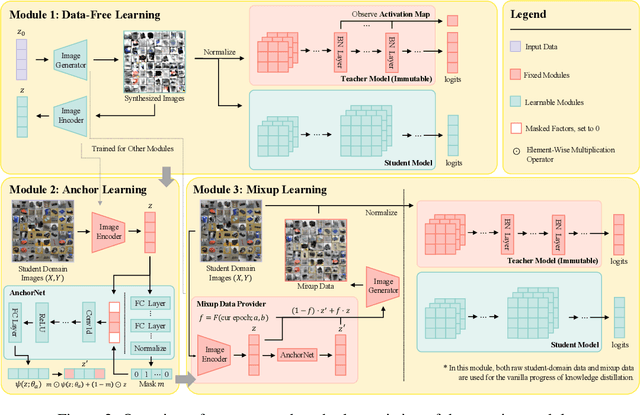
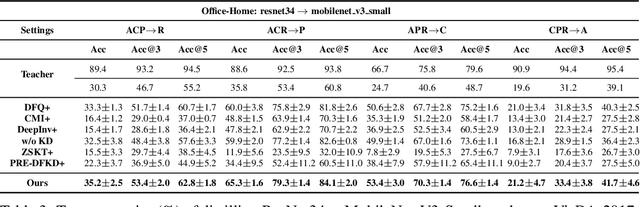
Due to privacy or patent concerns, a growing number of large models are released without granting access to their training data, making transferring their knowledge inefficient and problematic. In response, Data-Free Knowledge Distillation (DFKD) methods have emerged as direct solutions. However, simply adopting models derived from DFKD for real-world applications suffers significant performance degradation, due to the discrepancy between teachers' training data and real-world scenarios (student domain). The degradation stems from the portions of teachers' knowledge that are not applicable to the student domain. They are specific to the teacher domain and would undermine students' performance. Hence, selectively transferring teachers' appropriate knowledge becomes the primary challenge in DFKD. In this work, we propose a simple but effective method AuG-KD. It utilizes an uncertainty-guided and sample-specific anchor to align student-domain data with the teacher domain and leverages a generative method to progressively trade off the learning process between OOD knowledge distillation and domain-specific information learning via mixup learning. Extensive experiments in 3 datasets and 8 settings demonstrate the stability and superiority of our approach. Code available at https://github.com/IshiKura-a/AuG-KD .
Multiobject Tracking for Thresholded Cell Measurements
Mar 11, 2024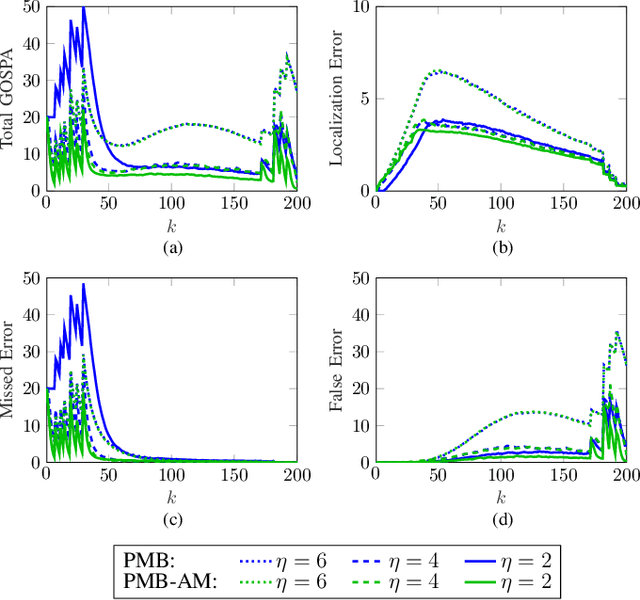
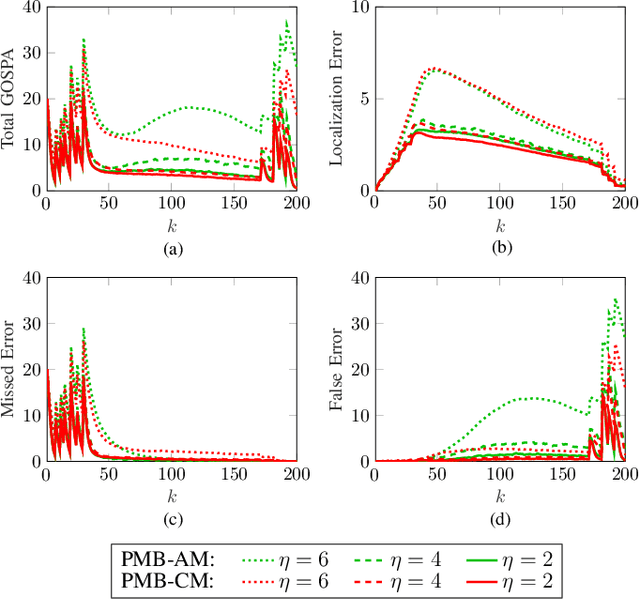
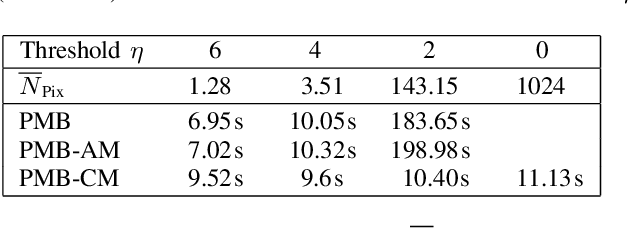
In many multiobject tracking applications, including radar and sonar tracking, after prefiltering the received signal, measurement data is typically structured in cells. The cells, e.g., represent different range and bearing values. However, conventional multiobject tracking methods use so-called point measurements. Point measurements are provided by a preprocessing stage that applies a threshold or detector and breaks up the cell's structure by converting cell indexes into, e.g., range and bearing measurements. We here propose a Bayesian multiobject tracking method that processes measurements that have been thresholded but are still cell-structured. We first derive a likelihood function that systematically incorporates an adjustable detection threshold which makes it possible to control the number of cell measurements. We then propose a Poisson Multi-Bernoulli (PMB) filter based on the likelihood function for cell measurements. Furthermore, we establish a link to the conventional point measurement model by deriving the likelihood function for point measurements with amplitude information (AM) and discuss the PMB filter that uses point measurements with AM. Our numerical results demonstrate the advantages of the proposed method that relies on thresholded cell measurements compared to the conventional multiobject tracking based on point measurements with and without AM.
Utilization of Reconfigurable Intelligent Surfaces with Context Information: Use Cases
Feb 28, 2024In terms of complex radio environments especially in dense urban areas, a very interesting topic is considered - the utilization of reconfigurable intelligent surfaces. Basically, based on simple controls of the angle of reflection of the signal from the surface, it is possible to achieve different effects in a radio communication system. Maximizing or minimizing the received power at specific locations near the reflecting surface is the most important effect. Thanks to this, it is possible to: receive a signal in a place where it was not possible, detect spectrum occupancy in a place where the sensor could not make a correct detection, or minimize interference in a specific receiver. In this paper, all three concepts are presented, and, using a simple ray tracing simulation, the potential profit in each scenario is shown. In addition, a scenario was analyzed in which several of the aforementioned situations are combined.
Combining Language and Graph Models for Semi-structured Information Extraction on the Web
Feb 21, 2024Relation extraction is an efficient way of mining the extraordinary wealth of human knowledge on the Web. Existing methods rely on domain-specific training data or produce noisy outputs. We focus here on extracting targeted relations from semi-structured web pages given only a short description of the relation. We present GraphScholarBERT, an open-domain information extraction method based on a joint graph and language model structure. GraphScholarBERT can generalize to previously unseen domains without additional data or training and produces only clean extraction results matched to the search keyword. Experiments show that GraphScholarBERT can improve extraction F1 scores by as much as 34.8\% compared to previous work in a zero-shot domain and zero-shot website setting.
Robust Semantic Communications for Speech-to-Text Translation
Mar 08, 2024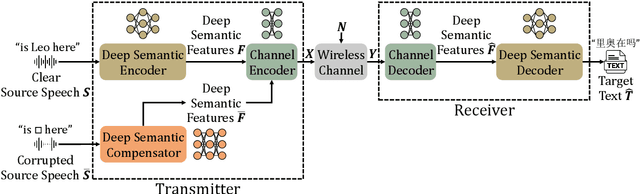
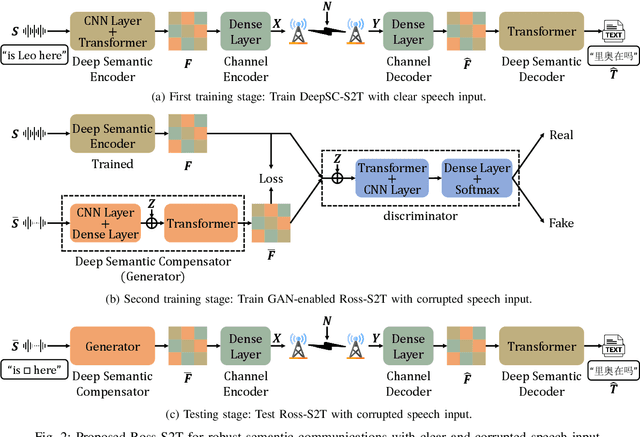
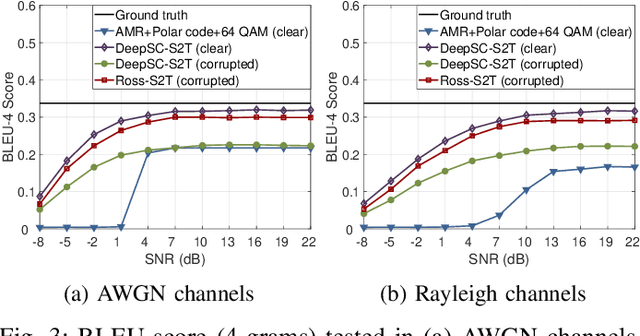
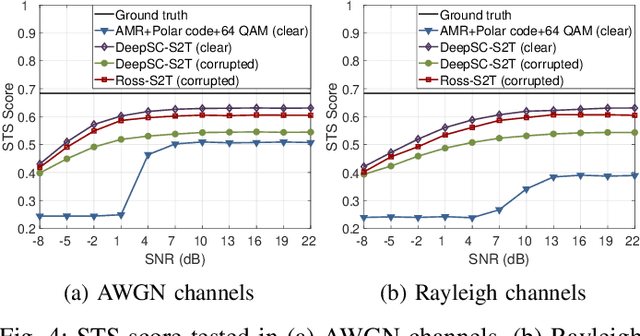
In this paper, we propose a robust semantic communication system to achieve the speech-to-text translation task, named Ross-S2T, by delivering the essential semantic information. Particularly, a deep semantic encoder is developed to directly condense and convert the speech in the source language to the textual semantic features associated with the target language, thus encouraging the design of a deep learning-enabled semantic communication system for speech-to-text translation that can be jointly trained in an end-to-end manner. Moreover, to cope with the practical communication scenario when the input speech is corrupted, a novel generative adversarial network (GAN)-enabled deep semantic compensator is proposed to predict the lost semantic information in the source speech and produce the textual semantic features in the target language simultaneously, which establishes a robust semantic transmission mechanism for dynamic speech input. According to the simulation results, the proposed Ross-S2T achieves significant speech-to-text translation performance compared to the conventional approach and exhibits high robustness against the corrupted speech input.
Degradation Resilient LiDAR-Radar-Inertial Odometry
Mar 08, 2024
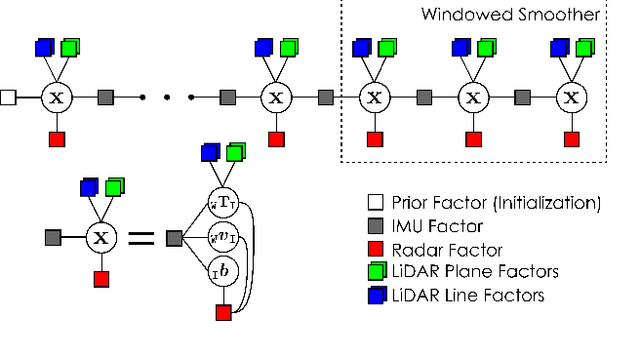
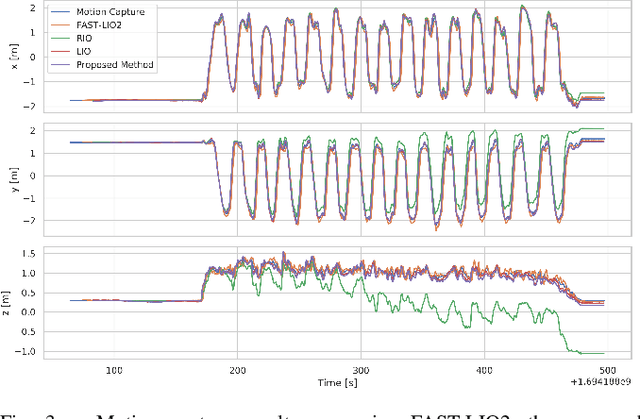

Enabling autonomous robots to operate robustly in challenging environments is necessary in a future with increased autonomy. For many autonomous systems, estimation and odometry remains a single point of failure, from which it can often be difficult, if not impossible, to recover. As such robust odometry solutions are of key importance. In this work a method for tightly-coupled LiDAR-Radar-Inertial fusion for odometry is proposed, enabling the mitigation of the effects of LiDAR degeneracy by leveraging a complementary perception modality while preserving the accuracy of LiDAR in well-conditioned environments. The proposed approach combines modalities in a factor graph-based windowed smoother with sensor information-specific factor formulations which enable, in the case of degeneracy, partial information to be conveyed to the graph along the non-degenerate axes. The proposed method is evaluated in real-world tests on a flying robot experiencing degraded conditions including geometric self-similarity as well as obscurant occlusion. For the benefit of the community we release the datasets presented: https://github.com/ntnu-arl/lidar_degeneracy_datasets.
Face2Diffusion for Fast and Editable Face Personalization
Mar 08, 2024
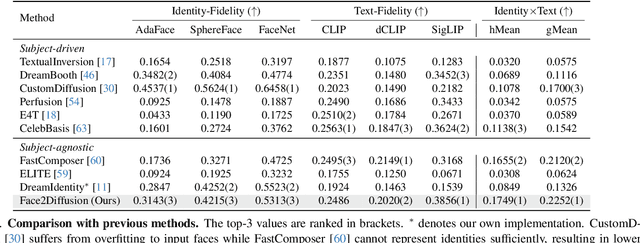


Face personalization aims to insert specific faces, taken from images, into pretrained text-to-image diffusion models. However, it is still challenging for previous methods to preserve both the identity similarity and editability due to overfitting to training samples. In this paper, we propose Face2Diffusion (F2D) for high-editability face personalization. The core idea behind F2D is that removing identity-irrelevant information from the training pipeline prevents the overfitting problem and improves editability of encoded faces. F2D consists of the following three novel components: 1) Multi-scale identity encoder provides well-disentangled identity features while keeping the benefits of multi-scale information, which improves the diversity of camera poses. 2) Expression guidance disentangles face expressions from identities and improves the controllability of face expressions. 3) Class-guided denoising regularization encourages models to learn how faces should be denoised, which boosts the text-alignment of backgrounds. Extensive experiments on the FaceForensics++ dataset and diverse prompts demonstrate our method greatly improves the trade-off between the identity- and text-fidelity compared to previous state-of-the-art methods.
3D Face Reconstruction Using A Spectral-Based Graph Convolution Encoder
Mar 08, 2024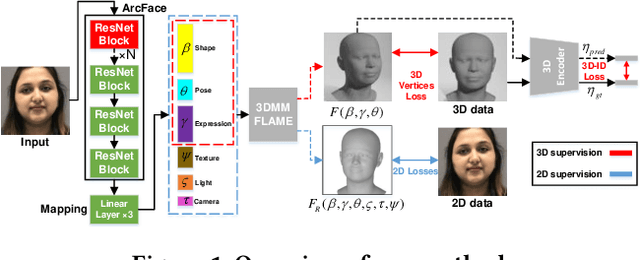
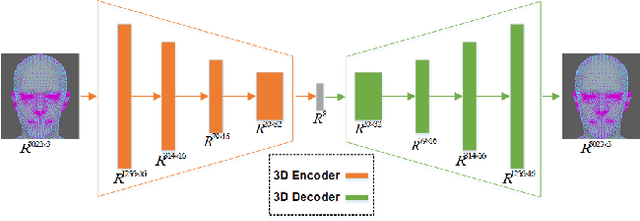
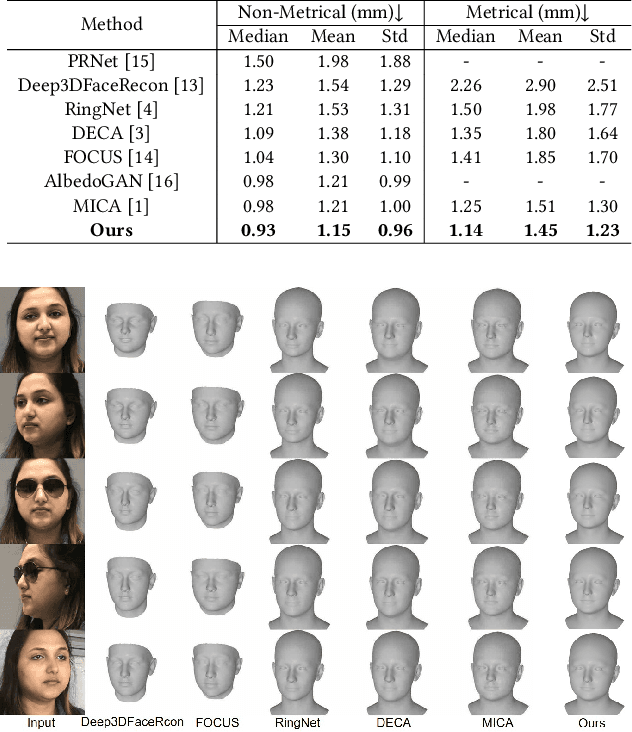
Monocular 3D face reconstruction plays a crucial role in avatar generation, with significant demand in web-related applications such as generating virtual financial advisors in FinTech. Current reconstruction methods predominantly rely on deep learning techniques and employ 2D self-supervision as a means to guide model learning. However, these methods encounter challenges in capturing the comprehensive 3D structural information of the face due to the utilization of 2D images for model training purposes. To overcome this limitation and enhance the reconstruction of 3D structural features, we propose an innovative approach that integrates existing 2D features with 3D features to guide the model learning process. Specifically, we introduce the 3D-ID Loss, which leverages the high-dimensional structure features extracted from a Spectral-Based Graph Convolution Encoder applied to the facial mesh. This approach surpasses the sole reliance on the 3D information provided by the facial mesh vertices coordinates. Our model is trained using 2D-3D data pairs from a combination of datasets and achieves state-of-the-art performance on the NoW benchmark.
SEMRes-DDPM: Residual Network Based Diffusion Modelling Applied to Imbalanced Data
Mar 12, 2024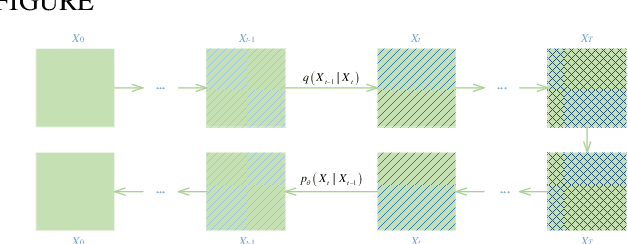
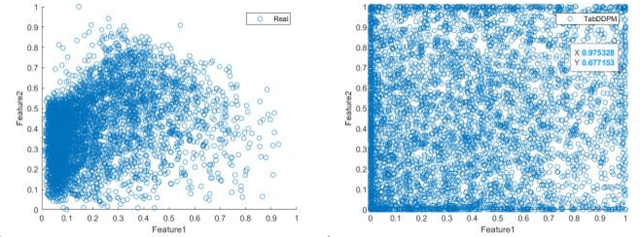
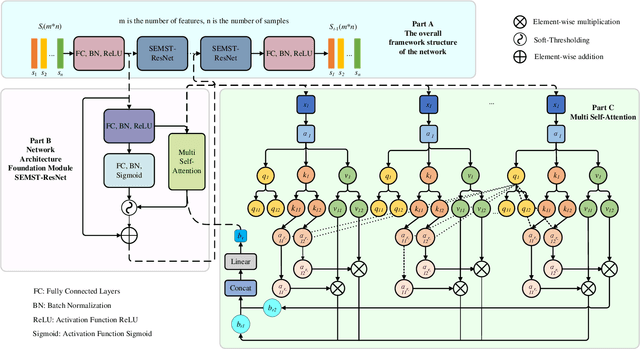
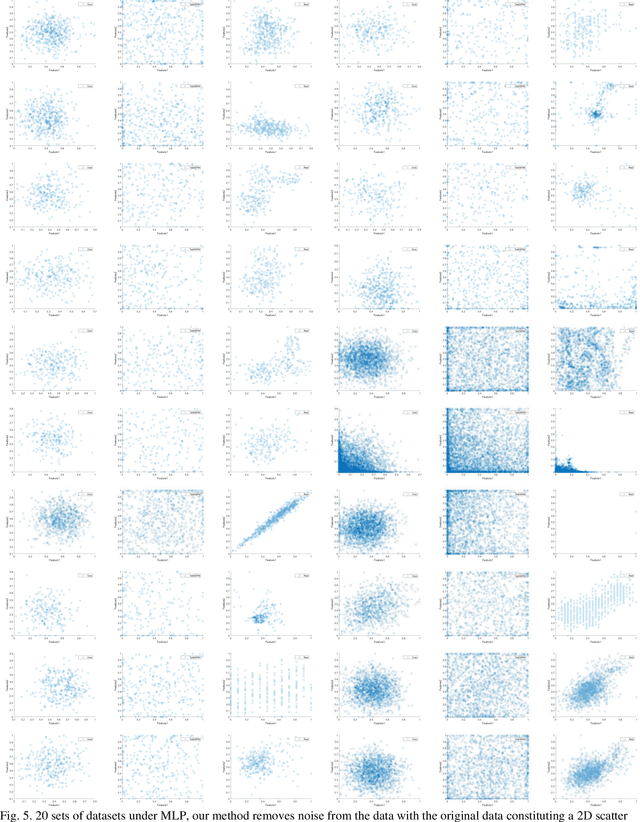
In the field of data mining and machine learning, commonly used classification models cannot effectively learn in unbalanced data. In order to balance the data distribution before model training, oversampling methods are often used to generate data for a small number of classes to solve the problem of classifying unbalanced data. Most of the classical oversampling methods are based on the SMOTE technique, which only focuses on the local information of the data, and therefore the generated data may have the problem of not being realistic enough. In the current oversampling methods based on generative networks, the methods based on GANs can capture the true distribution of data, but there is the problem of pattern collapse and training instability in training; in the oversampling methods based on denoising diffusion probability models, the neural network of the inverse diffusion process using the U-Net is not applicable to tabular data, and although the MLP can be used to replace the U-Net, the problem exists due to the simplicity of the structure and the poor effect of removing noise. problem of poor noise removal. In order to overcome the above problems, we propose a novel oversampling method SEMRes-DDPM.In the SEMRes-DDPM backward diffusion process, a new neural network structure SEMST-ResNet is used, which is suitable for tabular data and has good noise removal effect, and it can generate tabular data with higher quality. Experiments show that the SEMResNet network removes noise better than MLP; SEMRes-DDPM generates data distributions that are closer to the real data distributions than TabDDPM with CWGAN-GP; on 20 real unbalanced tabular datasets with 9 classification models, SEMRes-DDPM improves the quality of the generated tabular data in terms of three evaluation metrics (F1, G-mean, AUC) with better classification performance than other SOTA oversampling methods.