 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
KGLM: Integrating Knowledge Graph Structure in Language Models for Link Prediction
Nov 04, 2022
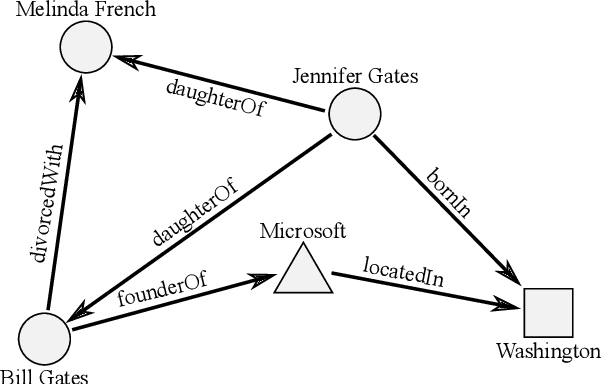
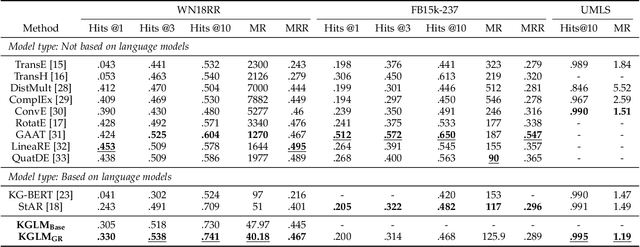
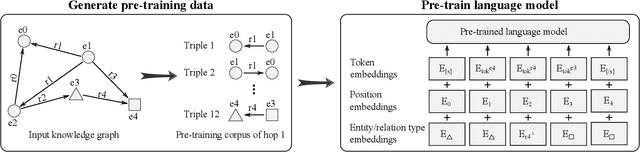
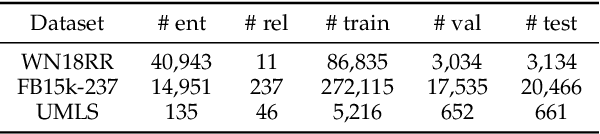
The ability of knowledge graphs to represent complex relationships at scale has led to their adoption for various needs including knowledge representation, question-answering, fraud detection, and recommendation systems. Knowledge graphs are often incomplete in the information they represent, necessitating the need for knowledge graph completion tasks, such as link and relation prediction. Pre-trained and fine-tuned language models have shown promise in these tasks although these models ignore the intrinsic information encoded in the knowledge graph, namely the entity and relation types. In this work, we propose the Knowledge Graph Language Model (KGLM) architecture, where we introduce a new entity/relation embedding layer that learns to differentiate distinctive entity and relation types, therefore allowing the model to learn the structure of the knowledge graph. In this work, we show that further pre-training the language models with this additional embedding layer using the triples extracted from the knowledge graph, followed by the standard fine-tuning phase sets a new state-of-the-art performance for the link prediction task on the benchmark datasets.
DroneAttention: Sparse Weighted Temporal Attention for Drone-Camera Based Activity Recognition
Dec 07, 2022
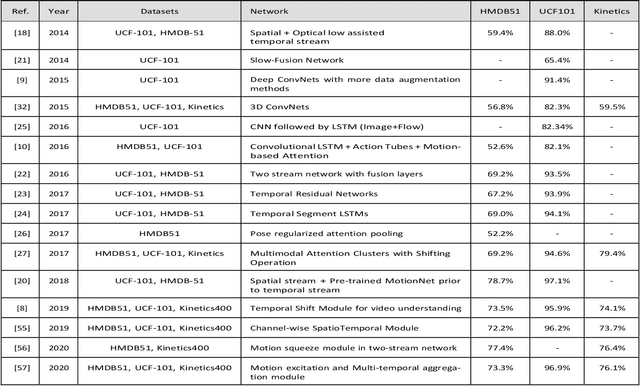
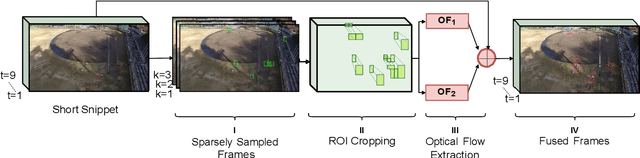
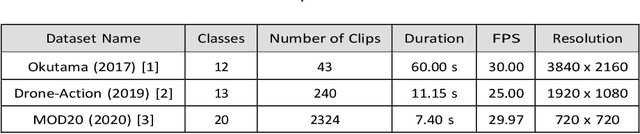
Human activity recognition (HAR) using drone-mounted cameras has attracted considerable interest from the computer vision research community in recent years. A robust and efficient HAR system has a pivotal role in fields like video surveillance, crowd behavior analysis, sports analysis, and human-computer interaction. What makes it challenging are the complex poses, understanding different viewpoints, and the environmental scenarios where the action is taking place. To address such complexities, in this paper, we propose a novel Sparse Weighted Temporal Attention (SWTA) module to utilize sparsely sampled video frames for obtaining global weighted temporal attention. The proposed SWTA is comprised of two parts. First, temporal segment network that sparsely samples a given set of frames. Second, weighted temporal attention, which incorporates a fusion of attention maps derived from optical flow, with raw RGB images. This is followed by a basenet network, which comprises a convolutional neural network (CNN) module along with fully connected layers that provide us with activity recognition. The SWTA network can be used as a plug-in module to the existing deep CNN architectures, for optimizing them to learn temporal information by eliminating the need for a separate temporal stream. It has been evaluated on three publicly available benchmark datasets, namely Okutama, MOD20, and Drone-Action. The proposed model has received an accuracy of 72.76%, 92.56%, and 78.86% on the respective datasets thereby surpassing the previous state-of-the-art performances by a margin of 25.26%, 18.56%, and 2.94%, respectively.
LWSIS: LiDAR-guided Weakly Supervised Instance Segmentation for Autonomous Driving
Dec 07, 2022
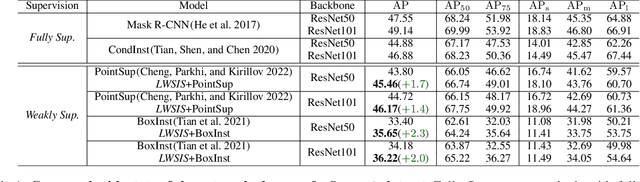
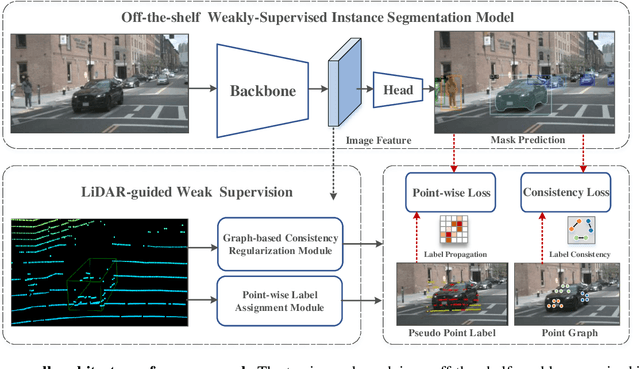
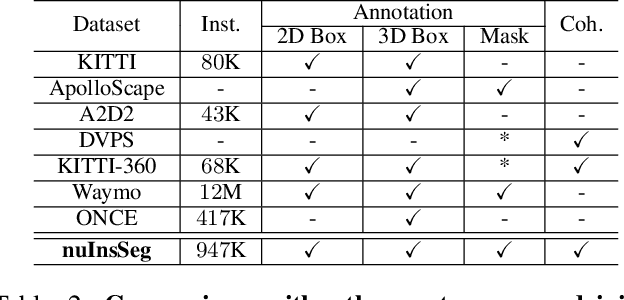
Image instance segmentation is a fundamental research topic in autonomous driving, which is crucial for scene understanding and road safety. Advanced learning-based approaches often rely on the costly 2D mask annotations for training. In this paper, we present a more artful framework, LiDAR-guided Weakly Supervised Instance Segmentation (LWSIS), which leverages the off-the-shelf 3D data, i.e., Point Cloud, together with the 3D boxes, as natural weak supervisions for training the 2D image instance segmentation models. Our LWSIS not only exploits the complementary information in multimodal data during training, but also significantly reduces the annotation cost of the dense 2D masks. In detail, LWSIS consists of two crucial modules, Point Label Assignment (PLA) and Graph-based Consistency Regularization (GCR). The former module aims to automatically assign the 3D point cloud as 2D point-wise labels, while the latter further refines the predictions by enforcing geometry and appearance consistency of the multimodal data. Moreover, we conduct a secondary instance segmentation annotation on the nuScenes, named nuInsSeg, to encourage further research on multimodal perception tasks. Extensive experiments on the nuInsSeg, as well as the large-scale Waymo, show that LWSIS can substantially improve existing weakly supervised segmentation models by only involving 3D data during training. Additionally, LWSIS can also be incorporated into 3D object detectors like PointPainting to boost the 3D detection performance for free. The code and dataset are available at https://github.com/Serenos/LWSIS.
Transfer learning with high-dimensional quantile regression
Nov 26, 2022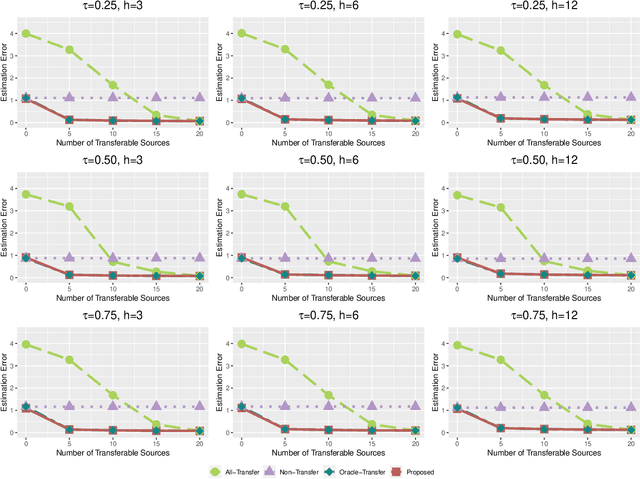
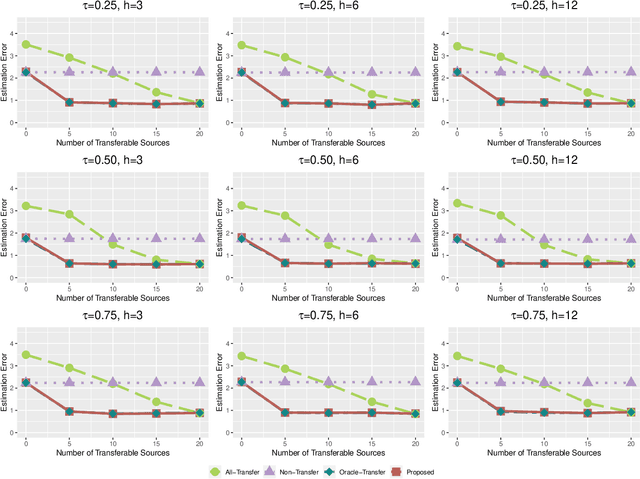
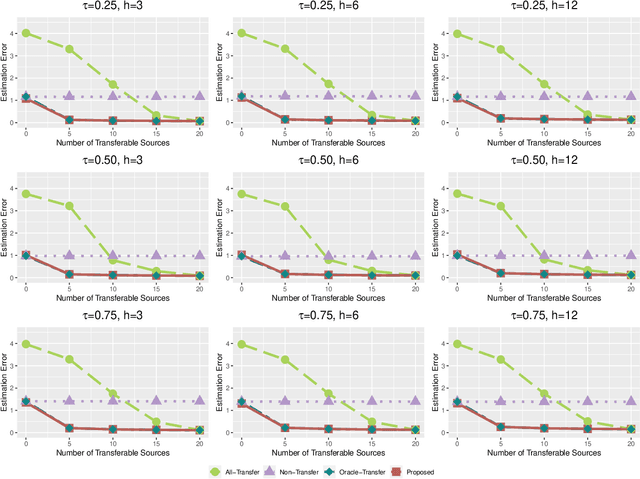
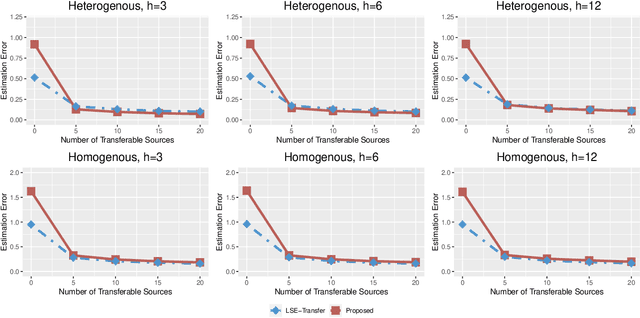
Transfer learning has become an essential technique to exploit information from the source domain to boost performance of the target task. Despite the prevalence in high-dimensional data, heterogeneity and/or heavy tails tend to be discounted in current transfer learning approaches and thus may undermine the resulting performance. We propose a transfer learning procedure in the framework of high-dimensional quantile regression models to accommodate the heterogeneity and heavy tails in the source and target domains. We establish error bounds of the transfer learning estimator based on delicately selected transferable source domains, showing that lower error bounds can be achieved for critical selection criterion and larger sample size of source tasks. We further propose valid confidence interval and hypothesis test procedures for individual component of quantile regression coefficients by advocating a one-step debiased estimator of transfer learning estimator wherein the consistent variance estimation is proposed via the technique of transfer learning again. Simulation results demonstrate that the proposed method exhibits some favorable performances.
Scientific and Technological News Recommendation Based on Knowledge Graph with User Perception
Oct 07, 2022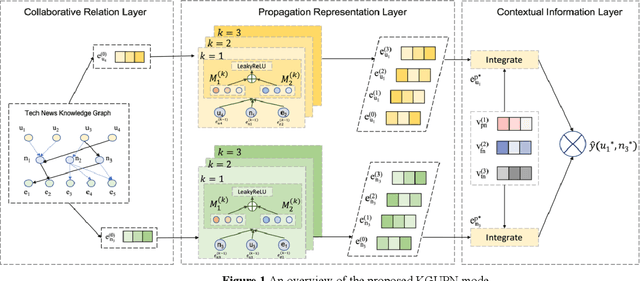
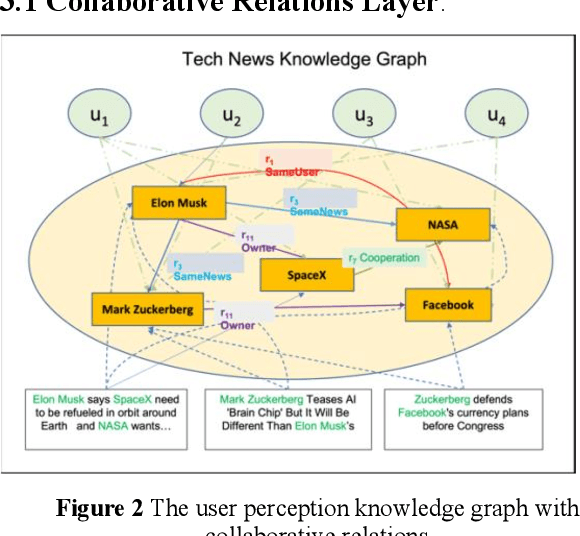
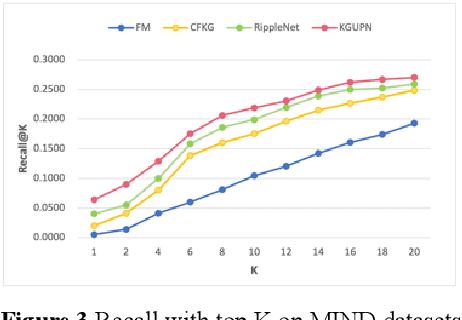
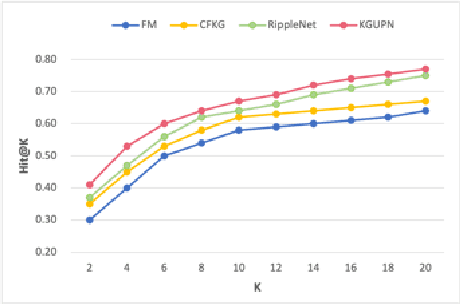
Existing research usually utilizes side information such as social network or item attributes to improve the performance of collaborative filtering-based recommender systems. In this paper, the knowledge graph with user perception is used to acquire the source of side information. We proposed KGUPN to address the limitations of existing embedding-based and path-based knowledge graph-aware recommendation methods, an end-to-end framework that integrates knowledge graph and user awareness into scientific and technological news recommendation systems. KGUPN contains three main layers, which are the propagation representation layer, the contextual information layer and collaborative relation layer. The propagation representation layer improves the representation of an entity by recursively propagating embeddings from its neighbors (which can be users, news, or relationships) in the knowledge graph. The contextual information layer improves the representation of entities by encoding the behavioral information of entities appearing in the news. The collaborative relation layer complements the relationship between entities in the news knowledge graph. Experimental results on real-world datasets show that KGUPN significantly outperforms state-of-the-art baselines in scientific and technological news recommendation.
The Cause of Causal Emergence: Redistribution of Uncertainty
Dec 03, 2022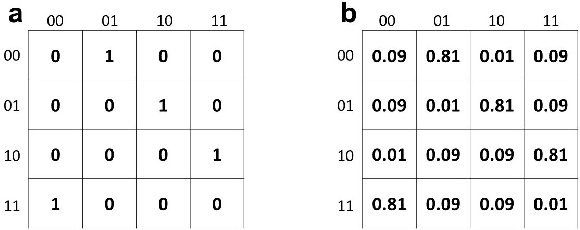
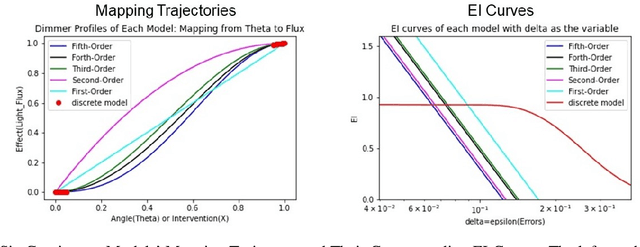

It is crucial to choose the appropriate scale in order to build an effective and informational representation of a complex system. Scientists carefully choose the scales for their experiments to extract the variables that describe the causalities in the system. They found that the coarse scale(macro) is sometimes more causal and informative than the numerous-parameter observations(micro). The phenomenon that the causality emerges by coarse-graining is called Causal Emergence(CE). Based on information theory, a number of recent works quantitatively showed that CE indeed happens while coarse-graining a micro model to the macro. However, the existing works have not discussed the question of why and when the CE happens. We quantitatively analyze the redistribution of uncertainties for coarse-graining and suggest that the redistribution of uncertainties is the cause of causal emergence. We further analyze the thresholds that determine if CE happens or not. From the regularity of the transition probability matrix(TPM) of discrete systems, the mathematical expressions of the model properties are derived. The values of thresholds for different operations are computed. The results provide the critical and specific conditions of CE as helpful suggestions for choosing the proper coarse-graining operation. The results also provided a new way to better understand the nature of causality and causal emergence.
MaRF: Representing Mars as Neural Radiance Fields
Dec 03, 2022
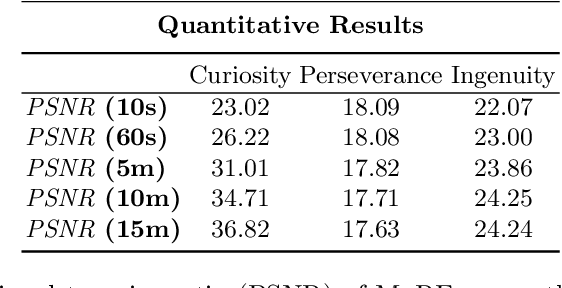

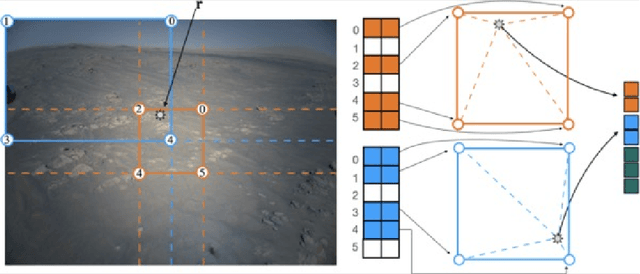
The aim of this work is to introduce MaRF, a novel framework able to synthesize the Martian environment using several collections of images from rover cameras. The idea is to generate a 3D scene of Mars' surface to address key challenges in planetary surface exploration such as: planetary geology, simulated navigation and shape analysis. Although there exist different methods to enable a 3D reconstruction of Mars' surface, they rely on classical computer graphics techniques that incur high amounts of computational resources during the reconstruction process, and have limitations with generalizing reconstructions to unseen scenes and adapting to new images coming from rover cameras. The proposed framework solves the aforementioned limitations by exploiting Neural Radiance Fields (NeRFs), a method that synthesize complex scenes by optimizing a continuous volumetric scene function using a sparse set of images. To speed up the learning process, we replaced the sparse set of rover images with their neural graphics primitives (NGPs), a set of vectors of fixed length that are learned to preserve the information of the original images in a significantly smaller size. In the experimental section, we demonstrate the environments created from actual Mars datasets captured by Curiosity rover, Perseverance rover and Ingenuity helicopter, all of which are available on the Planetary Data System (PDS).
Exploring Stochastic Autoregressive Image Modeling for Visual Representation
Dec 03, 2022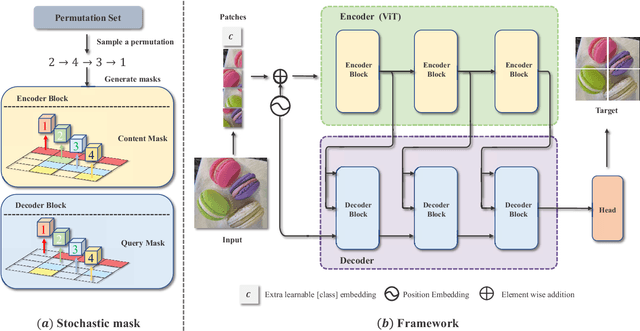
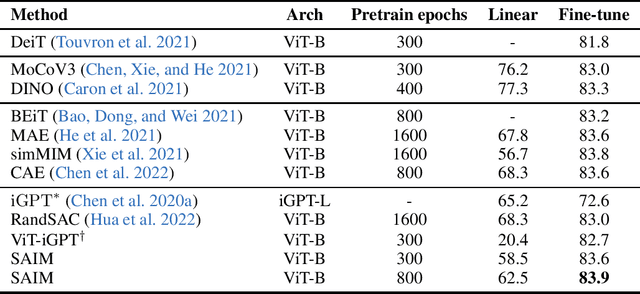
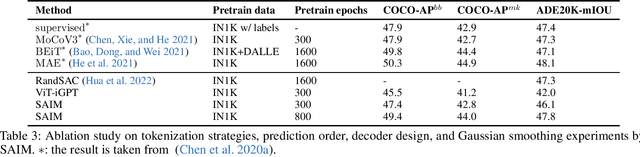
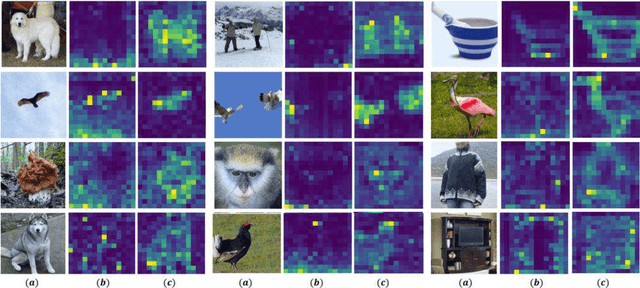
Autoregressive language modeling (ALM) have been successfully used in self-supervised pre-training in Natural language processing (NLP). However, this paradigm has not achieved comparable results with other self-supervised approach in computer vision (e.g., contrastive learning, mask image modeling). In this paper, we try to find the reason why autoregressive modeling does not work well on vision tasks. To tackle this problem, we fully analyze the limitation of visual autoregressive methods and proposed a novel stochastic autoregressive image modeling (named SAIM) by the two simple designs. First, we employ stochastic permutation strategy to generate effective and robust image context which is critical for vision tasks. Second, we create a parallel encoder-decoder training process in which the encoder serves a similar role to the standard vision transformer focus on learning the whole contextual information, and meanwhile the decoder predicts the content of the current position, so that the encoder and decoder can reinforce each other. By introducing stochastic prediction and the parallel encoder-decoder, SAIM significantly improve the performance of autoregressive image modeling. Our method achieves the best accuracy (83.9%) on the vanilla ViT-Base model among methods using only ImageNet-1K data. Transfer performance in downstream tasks also show that our model achieves competitive performance.
A Mobility-Aware Deep Learning Model for Long-Term COVID-19 Pandemic Prediction and Policy Impact Analysis
Dec 05, 2022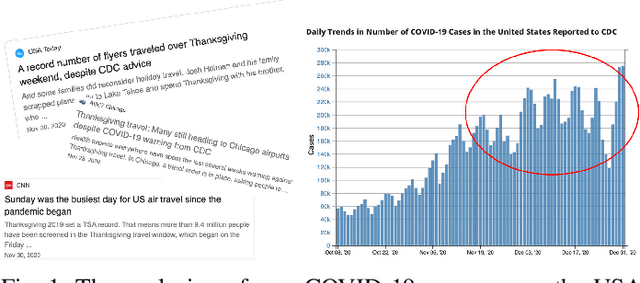
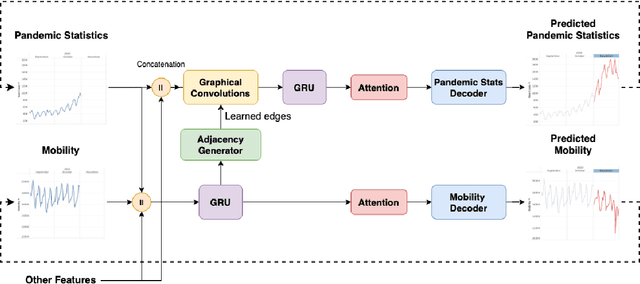
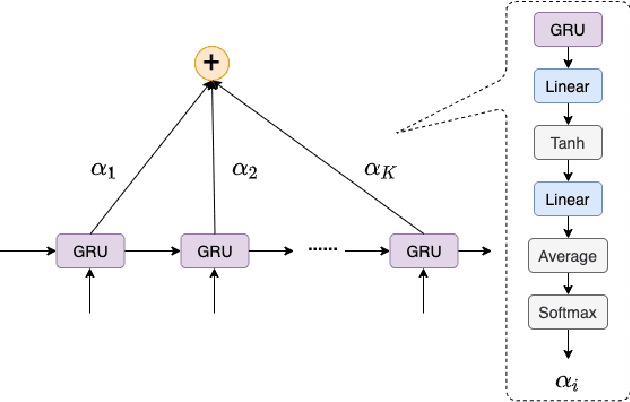

Pandemic(epidemic) modeling, aiming at disease spreading analysis, has always been a popular research topic especially following the outbreak of COVID-19 in 2019. Some representative models including SIR-based deep learning prediction models have shown satisfactory performance. However, one major drawback for them is that they fall short in their long-term predictive ability. Although graph convolutional networks (GCN) also perform well, their edge representations do not contain complete information and it can lead to biases. Another drawback is that they usually use input features which they are unable to predict. Hence, those models are unable to predict further future. We propose a model that can propagate predictions further into the future and it has better edge representations. In particular, we model the pandemic as a spatial-temporal graph whose edges represent the transition of infections and are learned by our model. We use a two-stream framework that contains GCN and recursive structures (GRU) with an attention mechanism. Our model enables mobility analysis that provides an effective toolbox for public health researchers and policy makers to predict how different lock-down strategies that actively control mobility can influence the spread of pandemics. Experiments show that our model outperforms others in its long-term predictive power. Moreover, we simulate the effects of certain policies and predict their impacts on infection control.
Understanding the Relationship between Over-smoothing and Over-squashing in Graph Neural Networks
Dec 05, 2022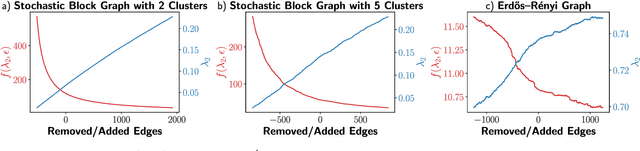
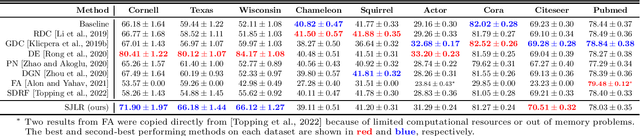
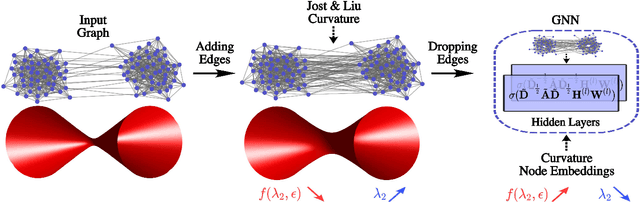
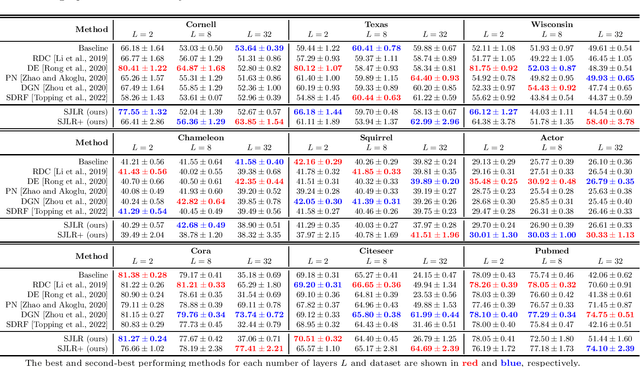
Graph Neural Networks (GNNs) have been successfully applied in many applications in computer sciences. Despite the success of deep learning architectures in other domains, deep GNNs still underperform their shallow counterparts. There are many open questions about deep GNNs, but over-smoothing and over-squashing are perhaps the most intriguing issues. When stacking multiple graph convolutional layers, the over-smoothing and over-squashing problems arise and have been defined as the inability of GNNs to learn deep representations and propagate information from distant nodes, respectively. Even though the widespread definitions of both problems are similar, these phenomena have been studied independently. This work strives to understand the underlying relationship between over-smoothing and over-squashing from a topological perspective. We show that both problems are intrinsically related to the spectral gap of the Laplacian of the graph. Therefore, there is a trade-off between these two problems, i.e., we cannot simultaneously alleviate both over-smoothing and over-squashing. We also propose a Stochastic Jost and Liu curvature Rewiring (SJLR) algorithm based on a bound of the Ollivier's Ricci curvature. SJLR is less expensive than previous curvature-based rewiring methods while retaining fundamental properties. Finally, we perform a thorough comparison of SJLR with previous techniques to alleviate over-smoothing or over-squashing, seeking to gain a better understanding of both problems.