 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dense Text Retrieval based on Pretrained Language Models: A Survey
Nov 27, 2022
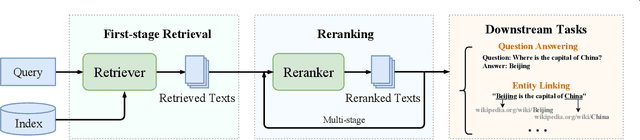
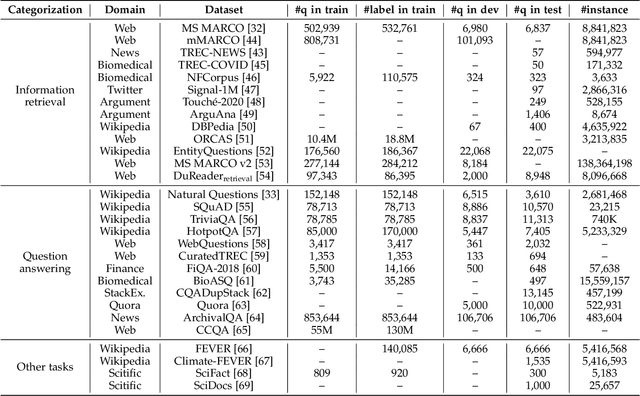
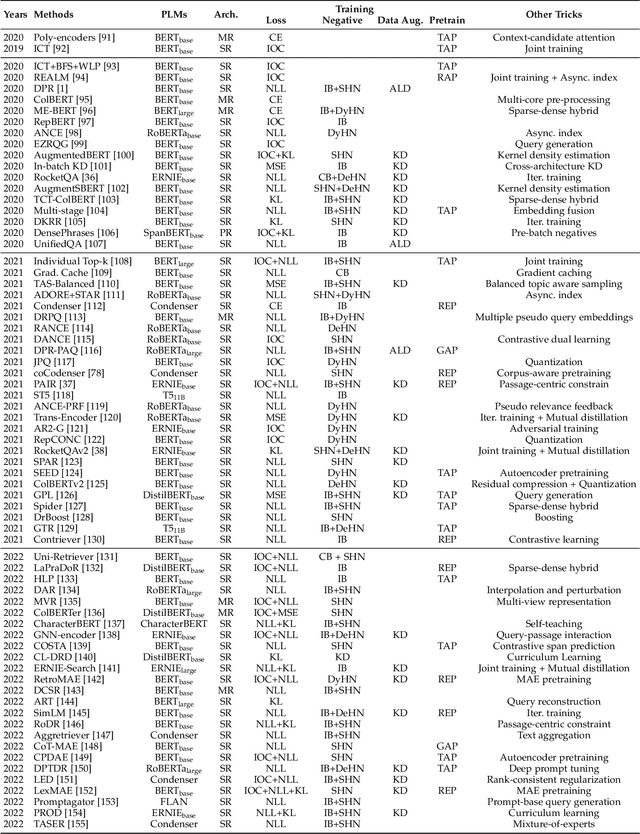
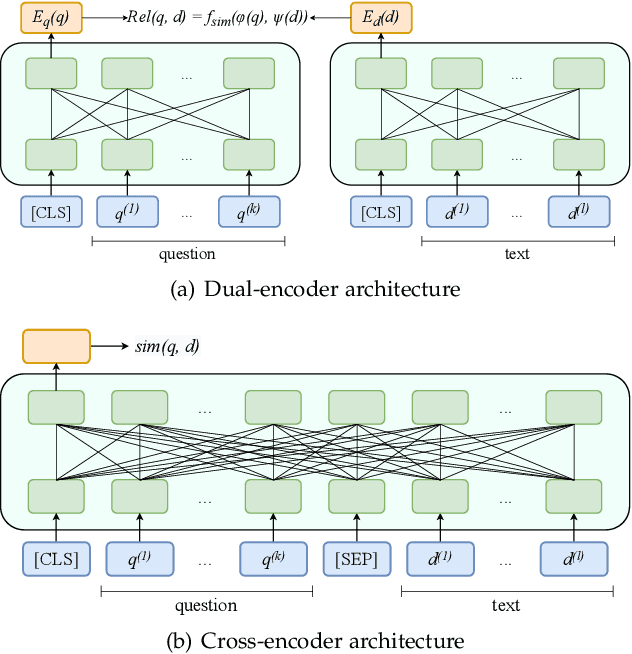
Text retrieval is a long-standing research topic on information seeking, where a system is required to return relevant information resources to user's queries in natural language. From classic retrieval methods to learning-based ranking functions, the underlying retrieval models have been continually evolved with the ever-lasting technical innovation. To design effective retrieval models, a key point lies in how to learn the text representation and model the relevance matching. The recent success of pretrained language models (PLMs) sheds light on developing more capable text retrieval approaches by leveraging the excellent modeling capacity of PLMs. With powerful PLMs, we can effectively learn the representations of queries and texts in the latent representation space, and further construct the semantic matching function between the dense vectors for relevance modeling. Such a retrieval approach is referred to as dense retrieval, since it employs dense vectors (a.k.a., embeddings) to represent the texts. Considering the rapid progress on dense retrieval, in this survey, we systematically review the recent advances on PLM-based dense retrieval. Different from previous surveys on dense retrieval, we take a new perspective to organize the related work by four major aspects, including architecture, training, indexing and integration, and summarize the mainstream techniques for each aspect. We thoroughly survey the literature, and include 300+ related reference papers on dense retrieval. To support our survey, we create a website for providing useful resources, and release a code repertory and toolkit for implementing dense retrieval models. This survey aims to provide a comprehensive, practical reference focused on the major progress for dense text retrieval.
Bridging the visual gap in VLN via semantically richer instructions
Oct 27, 2022The Visual-and-Language Navigation (VLN) task requires understanding a textual instruction to navigate a natural indoor environment using only visual information. While this is a trivial task for most humans, it is still an open problem for AI models. In this work, we hypothesize that poor use of the visual information available is at the core of the low performance of current models. To support this hypothesis, we provide experimental evidence showing that state-of-the-art models are not severely affected when they receive just limited or even no visual data, indicating a strong overfitting to the textual instructions. To encourage a more suitable use of the visual information, we propose a new data augmentation method that fosters the inclusion of more explicit visual information in the generation of textual navigational instructions. Our main intuition is that current VLN datasets include textual instructions that are intended to inform an expert navigator, such as a human, but not a beginner visual navigational agent, such as a randomly initialized DL model. Specifically, to bridge the visual semantic gap of current VLN datasets, we take advantage of metadata available for the Matterport3D dataset that, among others, includes information about object labels that are present in the scenes. Training a state-of-the-art model with the new set of instructions increase its performance by 8% in terms of success rate on unseen environments, demonstrating the advantages of the proposed data augmentation method.
Models for information propagation on graphs
Jan 19, 2022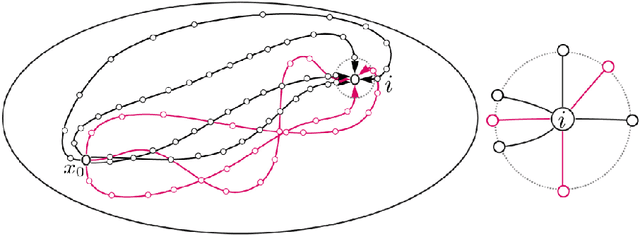

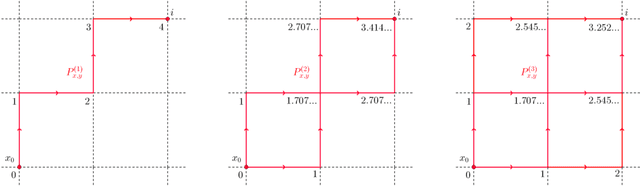
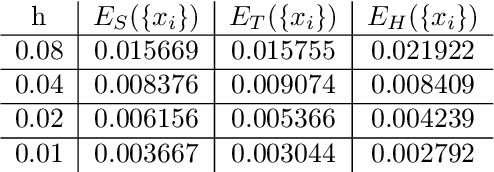
In this work we propose and unify classes of different models for information propagation over graphs. In a first class, propagation is modeled as a wave which emanates from a set of known nodes at an initial time, to all other unknown nodes at later times with an ordering determined by the time at which the information wave front reaches nodes. A second class of models is based on the notion of a travel time along paths between nodes. The time of information propagation from an initial known set of nodes to a node is defined as the minimum of a generalized travel time over subsets of all admissible paths. A final class is given by imposing a local equation of an eikonal form at each unknown node, with boundary conditions at the known nodes. The solution value of the local equation at a node is coupled the neighbouring nodes with smaller solution values. We provide precise formulations of the model classes in this graph setting, and prove equivalences between them. Motivated by the connection between first arrival time model and the eikonal equation in the continuum setting, we demonstrate that for graphs in the particular form of grids in Euclidean space mean field limits under grid refinement of certain graph models lead to Hamilton-Jacobi PDEs. For a specific parameter setting, we demonstrate that the solution on the grid approximates the Euclidean distance.
LISA: Localized Image Stylization with Audio via Implicit Neural Representation
Nov 21, 2022
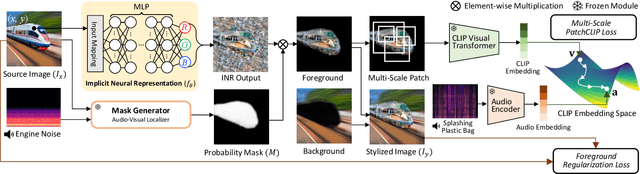
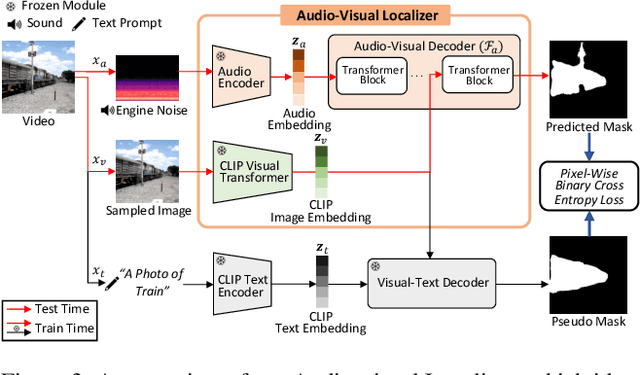
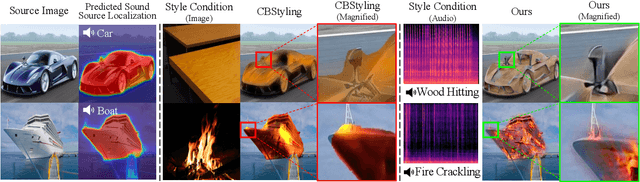
We present a novel framework, Localized Image Stylization with Audio (LISA) which performs audio-driven localized image stylization. Sound often provides information about the specific context of the scene and is closely related to a certain part of the scene or object. However, existing image stylization works have focused on stylizing the entire image using an image or text input. Stylizing a particular part of the image based on audio input is natural but challenging. In this work, we propose a framework that a user provides an audio input to localize the sound source in the input image and another for locally stylizing the target object or scene. LISA first produces a delicate localization map with an audio-visual localization network by leveraging CLIP embedding space. We then utilize implicit neural representation (INR) along with the predicted localization map to stylize the target object or scene based on sound information. The proposed INR can manipulate the localized pixel values to be semantically consistent with the provided audio input. Through a series of experiments, we show that the proposed framework outperforms the other audio-guided stylization methods. Moreover, LISA constructs concise localization maps and naturally manipulates the target object or scene in accordance with the given audio input.
SceneComposer: Any-Level Semantic Image Synthesis
Nov 21, 2022
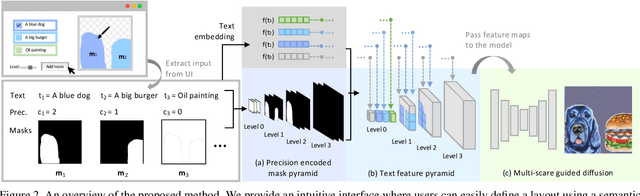
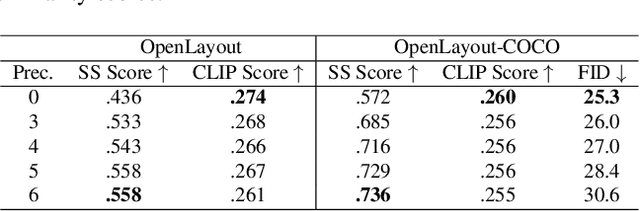
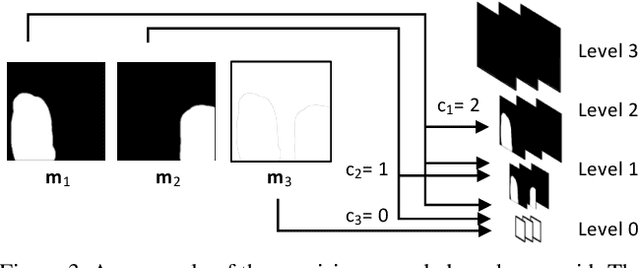
We propose a new framework for conditional image synthesis from semantic layouts of any precision levels, ranging from pure text to a 2D semantic canvas with precise shapes. More specifically, the input layout consists of one or more semantic regions with free-form text descriptions and adjustable precision levels, which can be set based on the desired controllability. The framework naturally reduces to text-to-image (T2I) at the lowest level with no shape information, and it becomes segmentation-to-image (S2I) at the highest level. By supporting the levels in-between, our framework is flexible in assisting users of different drawing expertise and at different stages of their creative workflow. We introduce several novel techniques to address the challenges coming with this new setup, including a pipeline for collecting training data; a precision-encoded mask pyramid and a text feature map representation to jointly encode precision level, semantics, and composition information; and a multi-scale guided diffusion model to synthesize images. To evaluate the proposed method, we collect a test dataset containing user-drawn layouts with diverse scenes and styles. Experimental results show that the proposed method can generate high-quality images following the layout at given precision, and compares favorably against existing methods. Project page \url{https://zengxianyu.github.io/scenec/}
Compositional Scene Modeling with Global Object-Centric Representations
Nov 21, 2022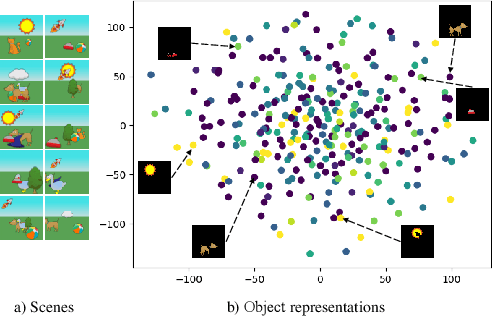
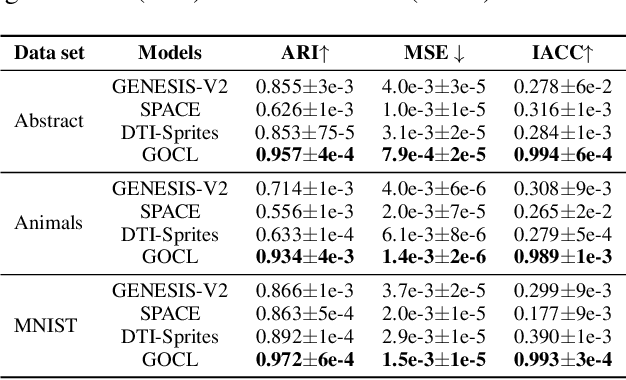
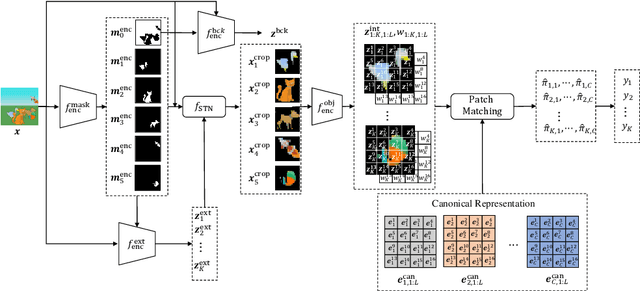
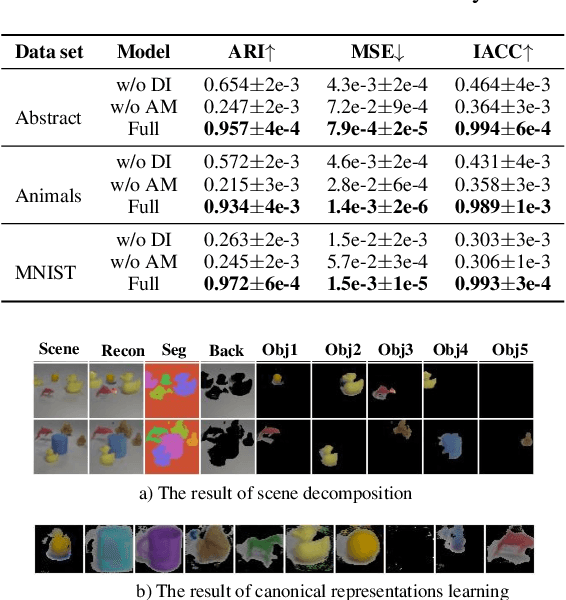
The appearance of the same object may vary in different scene images due to perspectives and occlusions between objects. Humans can easily identify the same object, even if occlusions exist, by completing the occluded parts based on its canonical image in the memory. Achieving this ability is still a challenge for machine learning, especially under the unsupervised learning setting. Inspired by such an ability of humans, this paper proposes a compositional scene modeling method to infer global representations of canonical images of objects without any supervision. The representation of each object is divided into an intrinsic part, which characterizes globally invariant information (i.e. canonical representation of an object), and an extrinsic part, which characterizes scene-dependent information (e.g., position and size). To infer the intrinsic representation of each object, we employ a patch-matching strategy to align the representation of a potentially occluded object with the canonical representations of objects, and sample the most probable canonical representation based on the category of object determined by amortized variational inference. Extensive experiments are conducted on four object-centric learning benchmarks, and experimental results demonstrate that the proposed method not only outperforms state-of-the-arts in terms of segmentation and reconstruction, but also achieves good global object identification performance.
ALBERT with Knowledge Graph Encoder Utilizing Semantic Similarity for Commonsense Question Answering
Nov 14, 2022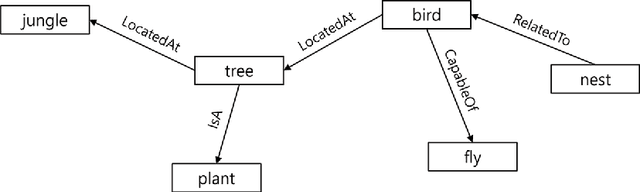

Recently, pre-trained language representation models such as bidirectional encoder representations from transformers (BERT) have been performing well in commonsense question answering (CSQA). However, there is a problem that the models do not directly use explicit information of knowledge sources existing outside. To augment this, additional methods such as knowledge-aware graph network (KagNet) and multi-hop graph relation network (MHGRN) have been proposed. In this study, we propose to use the latest pre-trained language model a lite bidirectional encoder representations from transformers (ALBERT) with knowledge graph information extraction technique. We also propose to applying the novel method, schema graph expansion to recent language models. Then, we analyze the effect of applying knowledge graph-based knowledge extraction techniques to recent pre-trained language models and confirm that schema graph expansion is effective in some extent. Furthermore, we show that our proposed model can achieve better performance than existing KagNet and MHGRN models in CommonsenseQA dataset.
* 12 pages, 9 figures
Row Conditional-TGAN for generating synthetic relational databases
Nov 14, 2022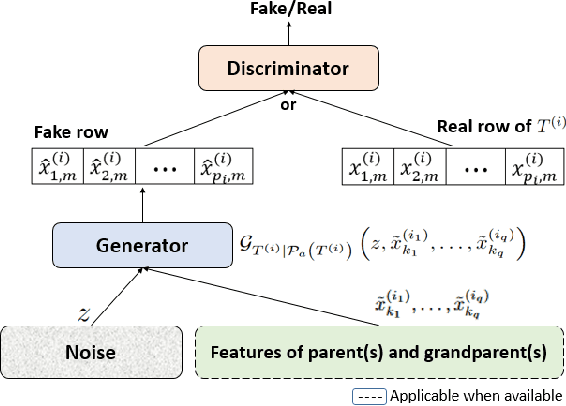
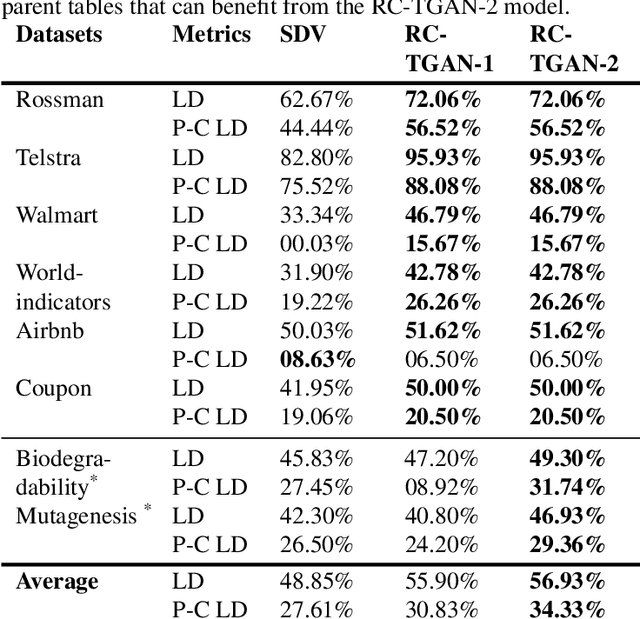
Besides reproducing tabular data properties of standalone tables, synthetic relational databases also require modeling the relationships between related tables. In this paper, we propose the Row Conditional-Tabular Generative Adversarial Network (RC-TGAN), a novel generative adversarial network (GAN) model that extends the tabular GAN to support modeling and synthesizing relational databases. The RC-TGAN models relationship information between tables by incorporating conditional data of parent rows into the design of the child table's GAN. We further extend the RC-TGAN to model the influence that grandparent table rows may have on their grandchild rows, in order to prevent the loss of this connection when the rows of the parent table fail to transfer this relationship information. The experimental results, using eight real relational databases, show significant improvements in the quality of the synthesized relational databases when compared to the benchmark system, demonstrating the effectiveness of the RC-TGAN in preserving relationships between tables of the original database.
PIM: Video Coding using Perceptual Importance Maps
Dec 20, 2022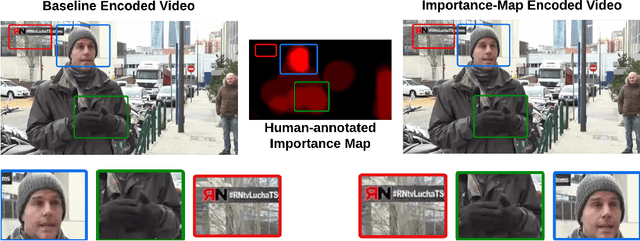
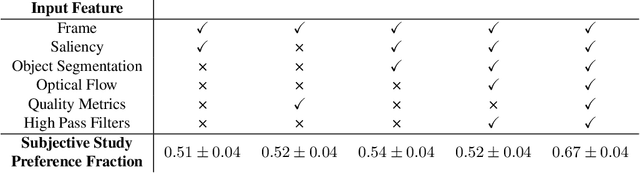
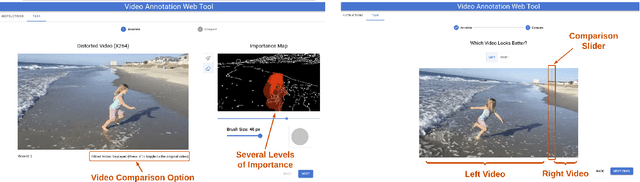
Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred $2.1 \times$ over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, $2 \times$ preferred over the baseline at the same bitrate.
An ensemble neural network approach to forecast Dengue outbreak based on climatic condition
Dec 20, 2022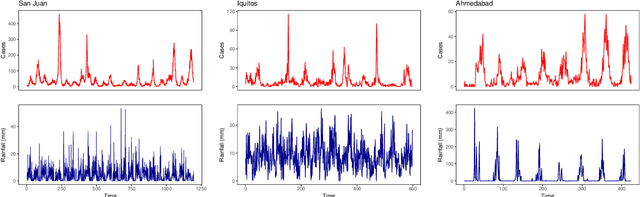
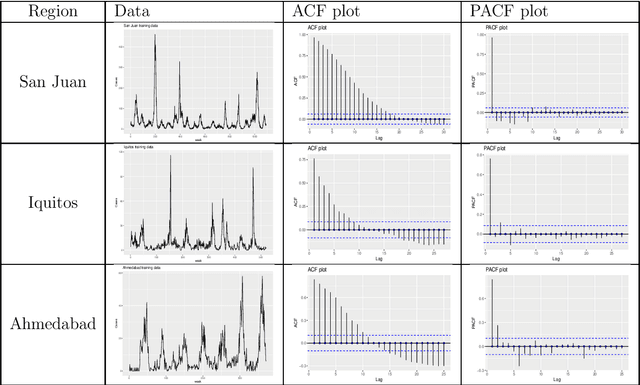
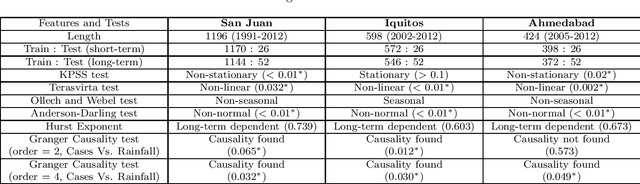

Dengue fever is a virulent disease spreading over 100 tropical and subtropical countries in Africa, the Americas, and Asia. This arboviral disease affects around 400 million people globally, severely distressing the healthcare systems. The unavailability of a specific drug and ready-to-use vaccine makes the situation worse. Hence, policymakers must rely on early warning systems to control intervention-related decisions. Forecasts routinely provide critical information for dangerous epidemic events. However, the available forecasting models (e.g., weather-driven mechanistic, statistical time series, and machine learning models) lack a clear understanding of different components to improve prediction accuracy and often provide unstable and unreliable forecasts. This study proposes an ensemble wavelet neural network with exogenous factor(s) (XEWNet) model that can produce reliable estimates for dengue outbreak prediction for three geographical regions, namely San Juan, Iquitos, and Ahmedabad. The proposed XEWNet model is flexible and can easily incorporate exogenous climate variable(s) confirmed by statistical causality tests in its scalable framework. The proposed model is an integrated approach that uses wavelet transformation into an ensemble neural network framework that helps in generating more reliable long-term forecasts. The proposed XEWNet allows complex non-linear relationships between the dengue incidence cases and rainfall; however, mathematically interpretable, fast in execution, and easily comprehensible. The proposal's competitiveness is measured using computational experiments based on various statistical metrics and several statistical comparison tests. In comparison with statistical, machine learning, and deep learning methods, our proposed XEWNet performs better in 75% of the cases for short-term and long-term forecasting of dengue incidence.