 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a statistical theory of data selection under weak supervision
Sep 25, 2023



Given a sample of size $N$, it is often useful to select a subsample of smaller size $n<N$ to be used for statistical estimation or learning. Such a data selection step is useful to reduce the requirements of data labeling and the computational complexity of learning. We assume to be given $N$ unlabeled samples $\{{\boldsymbol x}_i\}_{i\le N}$, and to be given access to a `surrogate model' that can predict labels $y_i$ better than random guessing. Our goal is to select a subset of the samples, to be denoted by $\{{\boldsymbol x}_i\}_{i\in G}$, of size $|G|=n<N$. We then acquire labels for this set and we use them to train a model via regularized empirical risk minimization. By using a mixture of numerical experiments on real and synthetic data, and mathematical derivations under low- and high- dimensional asymptotics, we show that: $(i)$~Data selection can be very effective, in particular beating training on the full sample in some cases; $(ii)$~Certain popular choices in data selection methods (e.g. unbiased reweighted subsampling, or influence function-based subsampling) can be substantially suboptimal.
PIM: Video Coding using Perceptual Importance Maps
Dec 20, 2022Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred $2.1 \times$ over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, $2 \times$ preferred over the baseline at the same bitrate.
An Interactive Annotation Tool for Perceptual Video Compression
May 08, 2022


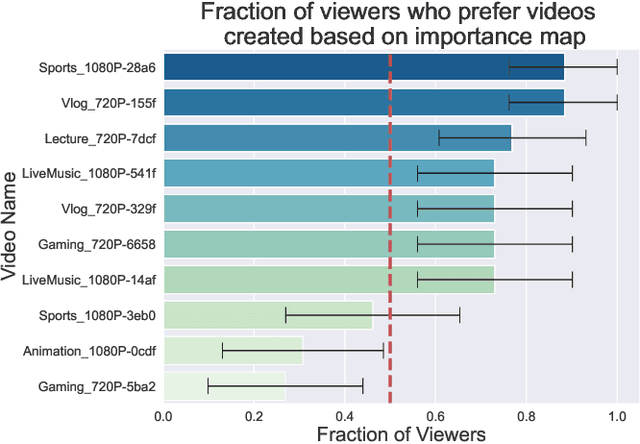
Human perception is at the core of lossy video compression and yet, it is challenging to collect data that is sufficiently dense to drive compression. In perceptual quality assessment, human feedback is typically collected as a single scalar quality score indicating preference of one distorted video over another. In reality, some videos may be better in some parts but not in others. We propose an approach to collecting finer-grained feedback by asking users to use an interactive tool to directly optimize for perceptual quality given a fixed bitrate. To this end, we built a novel web-tool which allows users to paint these spatio-temporal importance maps over videos. The tool allows for interactive successive refinement: we iteratively re-encode the original video according to the painted importance maps, while maintaining the same bitrate, thus allowing the user to visually see the trade-off of assigning higher importance to one spatio-temporal part of the video at the cost of others. We use this tool to collect data in-the-wild (10 videos, 17 users) and utilize the obtained importance maps in the context of x264 coding to demonstrate that the tool can indeed be used to generate videos which, at the same bitrate, look perceptually better through a subjective study - and are 1.9 times more likely to be preferred by viewers. The code for the tool and dataset can be found at https://github.com/jenyap/video-annotation-tool.git
Txt2Vid: Ultra-Low Bitrate Compression of Talking-Head Videos via Text
Jun 26, 2021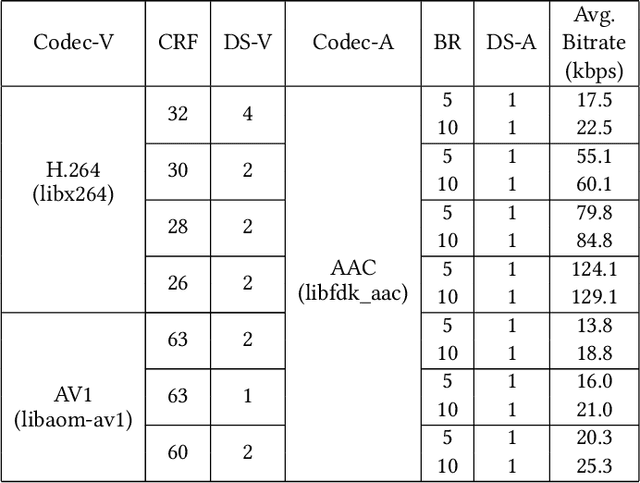
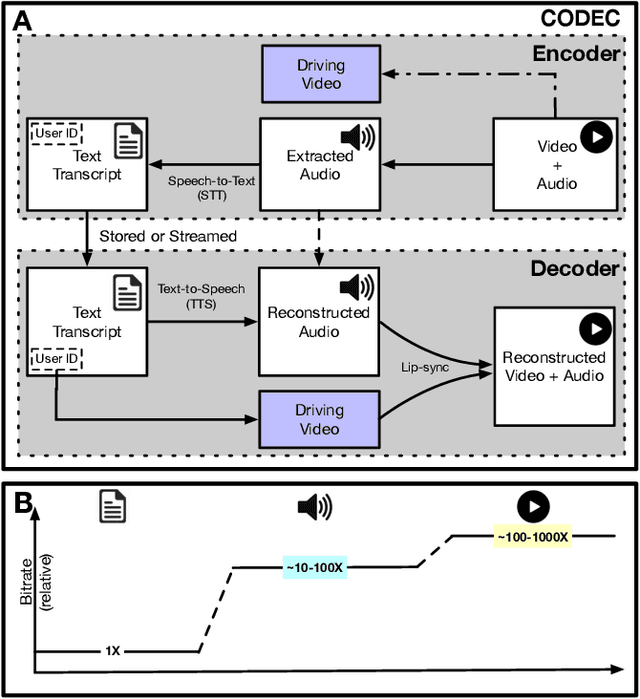
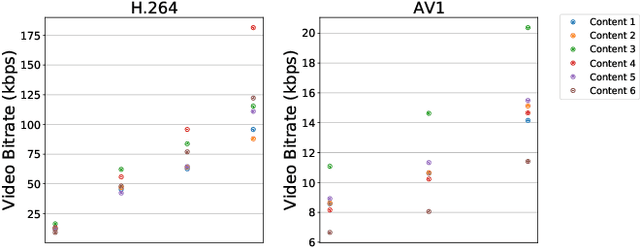
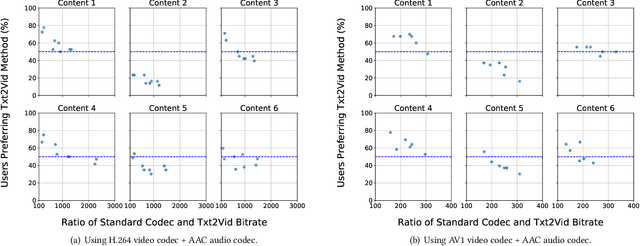
Video represents the majority of internet traffic today leading to a continuous technological arms race between generating higher quality content, transmitting larger file sizes and supporting network infrastructure. Adding to this is the recent COVID-19 pandemic fueled surge in the use of video conferencing tools. Since videos take up substantial bandwidth (~100 Kbps to few Mbps), improved video compression can have a substantial impact on network performance for live and pre-recorded content, providing broader access to multimedia content worldwide. In this work, we present a novel video compression pipeline, called Txt2Vid, which substantially reduces data transmission rates by compressing webcam videos ("talking-head videos") to a text transcript. The text is transmitted and decoded into a realistic reconstruction of the original video using recent advances in deep learning based voice cloning and lip syncing models. Our generative pipeline achieves two to three orders of magnitude reduction in the bitrate as compared to the standard audio-video codecs (encoders-decoders), while maintaining equivalent Quality-of-Experience based on a subjective evaluation by users (n=242) in an online study. The code for this work is available at https://github.com/tpulkit/txt2vid.git.
CAMBI: Contrast-aware Multiscale Banding Index
Jan 29, 2021
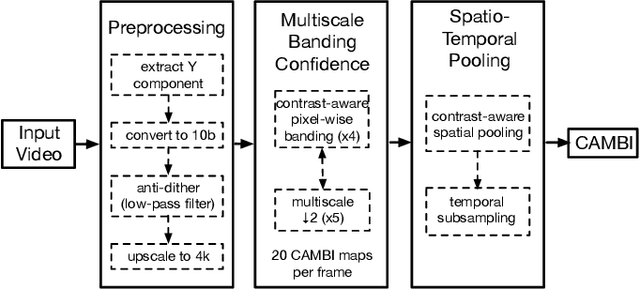
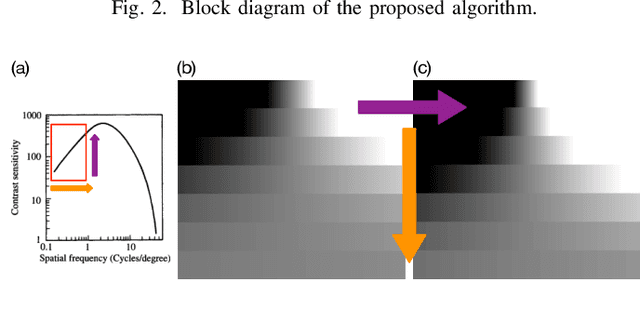
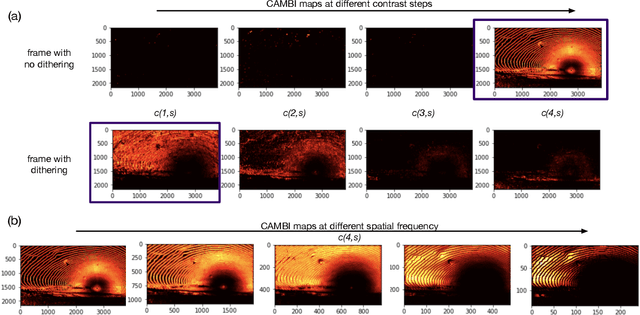
Banding artifacts are artificially-introduced contours arising from the quantization of a smooth region in a video. Despite the advent of recent higher quality video systems with more efficient codecs, these artifacts remain conspicuous, especially on larger displays. In this work, a comprehensive subjective study is performed to understand the dependence of the banding visibility on encoding parameters and dithering. We subsequently develop a simple and intuitive no-reference banding index called CAMBI (Contrast-aware Multiscale Banding Index) which uses insights from Contrast Sensitivity Function in the Human Visual System to predict banding visibility. CAMBI correlates well with subjective perception of banding while using only a few visually-motivated hyperparameters.