 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Synthetic Pre-Training Tasks for Neural Machine Translation
Dec 19, 2022
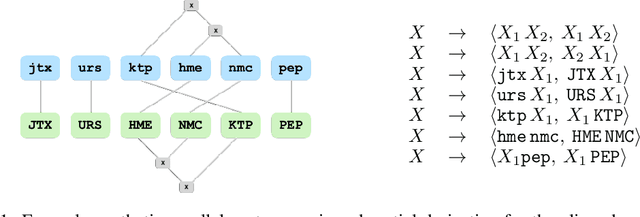
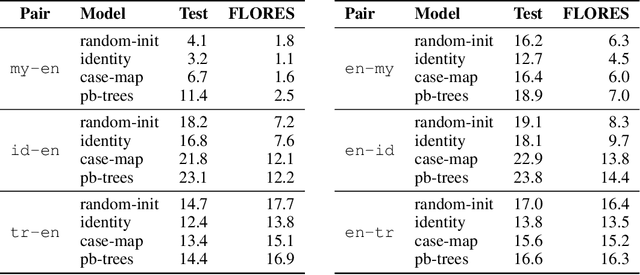
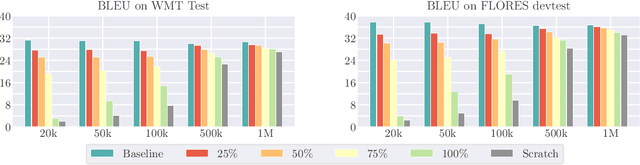
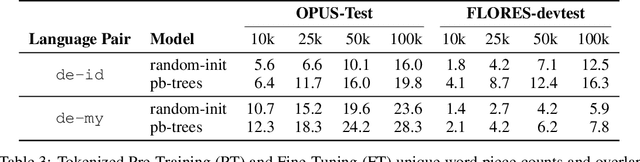
Pre-training is an effective technique for ensuring robust performance on a variety of machine learning tasks. It typically depends on large-scale crawled corpora that can result in toxic or biased models. Such data can also be problematic with respect to copyright, attribution, and privacy. Pre-training with synthetic tasks and data is a promising way of alleviating such concerns since no real-world information is ingested by the model. Our goal in this paper is to understand what makes for a good pre-trained model when using synthetic resources. We answer this question in the context of neural machine translation by considering two novel approaches to translation model pre-training. Our first approach studies the effect of pre-training on obfuscated data derived from a parallel corpus by mapping words to a vocabulary of 'nonsense' tokens. Our second approach explores the effect of pre-training on procedurally generated synthetic parallel data that does not depend on any real human language corpus. Our empirical evaluation on multiple language pairs shows that, to a surprising degree, the benefits of pre-training can be realized even with obfuscated or purely synthetic parallel data. In our analysis, we consider the extent to which obfuscated and synthetic pre-training techniques can be used to mitigate the issue of hallucinated model toxicity.
Spectral Regularized Kernel Two-Sample Tests
Dec 19, 2022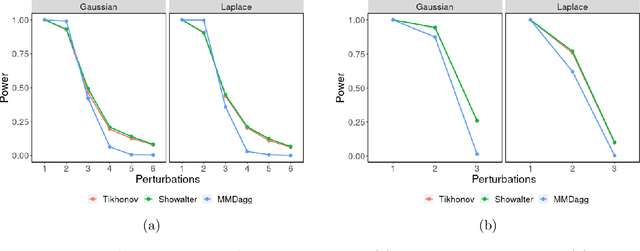
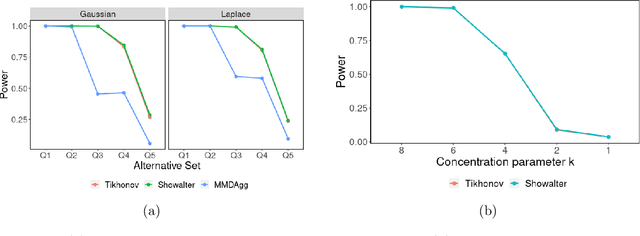
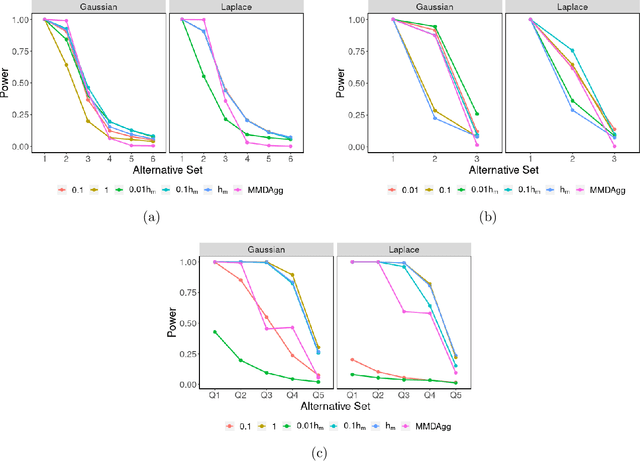
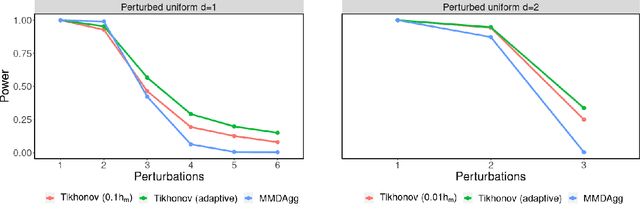
Over the last decade, an approach that has gained a lot of popularity to tackle non-parametric testing problems on general (i.e., non-Euclidean) domains is based on the notion of reproducing kernel Hilbert space (RKHS) embedding of probability distributions. The main goal of our work is to understand the optimality of two-sample tests constructed based on this approach. First, we show that the popular MMD (maximum mean discrepancy) two-sample test is not optimal in terms of the separation boundary measured in Hellinger distance. Second, we propose a modification to the MMD test based on spectral regularization by taking into account the covariance information (which is not captured by the MMD test) and prove the proposed test to be minimax optimal with a smaller separation boundary than that achieved by the MMD test. Third, we propose an adaptive version of the above test which involves a data-driven strategy to choose the regularization parameter and show the adaptive test to be almost minimax optimal up to a logarithmic factor. Moreover, our results hold for the permutation variant of the test where the test threshold is chosen elegantly through the permutation of the samples. Through numerical experiments on synthetic and real-world data, we demonstrate the superior performance of the proposed test in comparison to the MMD test.
Semi-Supervised Clustering of Sparse Graphs: Crossing the Information-Theoretic Threshold
May 24, 2022
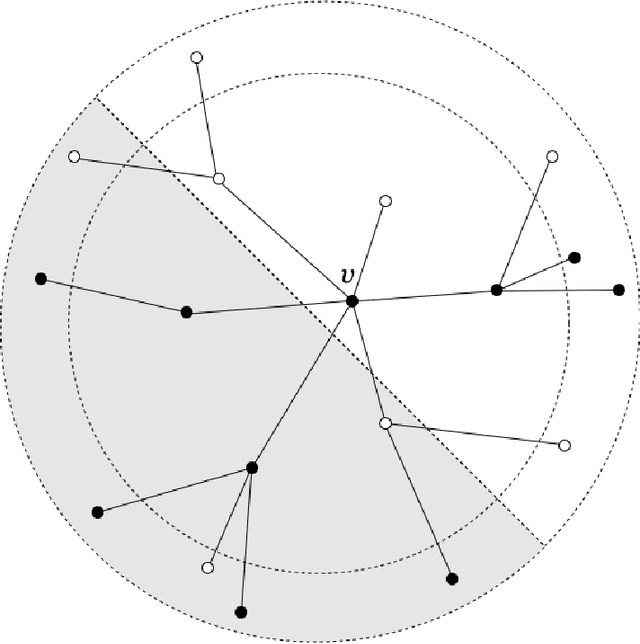
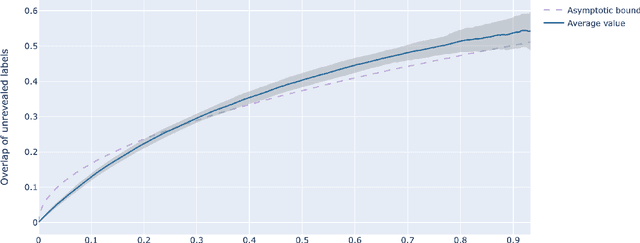
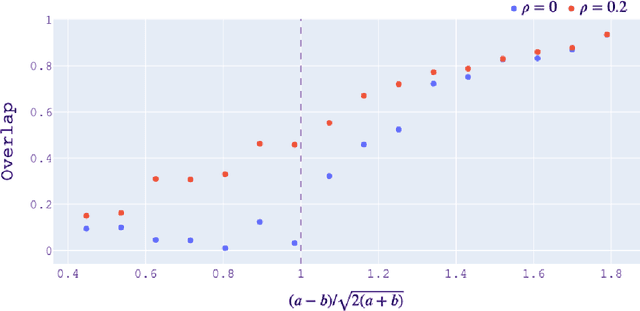
The stochastic block model is a canonical random graph model for clustering and community detection on network-structured data. Decades of extensive study on the problem have established many profound results, among which the phase transition at the Kesten-Stigum threshold is particularly interesting both from a mathematical and an applied standpoint. It states that no estimator based on the network topology can perform substantially better than chance on sparse graphs if the model parameter is below certain threshold. Nevertheless, if we slightly extend the horizon to the ubiquitous semi-supervised setting, such a fundamental limitation will disappear completely. We prove that with arbitrary fraction of the labels revealed, the detection problem is feasible throughout the parameter domain. Moreover, we introduce two efficient algorithms, one combinatorial and one based on optimization, to integrate label information with graph structures. Our work brings a new perspective to stochastic model of networks and semidefinite program research.
MURPHY: Relations Matter in Surgical Workflow Analysis
Dec 24, 2022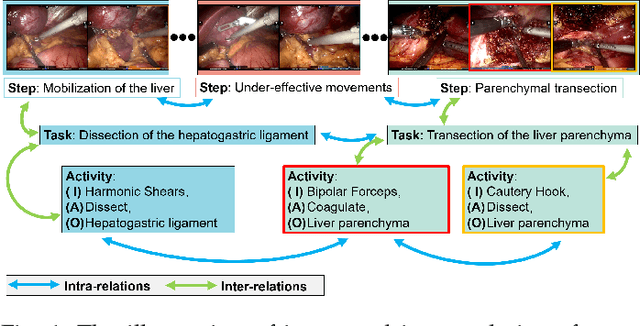

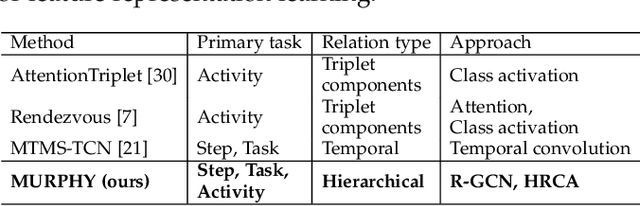
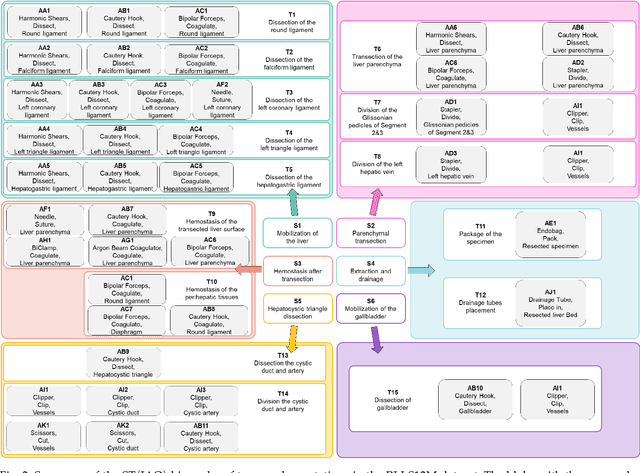
Autonomous robotic surgery has advanced significantly based on analysis of visual and temporal cues in surgical workflow, but relational cues from domain knowledge remain under investigation. Complex relations in surgical annotations can be divided into intra- and inter-relations, both valuable to autonomous systems to comprehend surgical workflows. Intra- and inter-relations describe the relevance of various categories within a particular annotation type and the relevance of different annotation types, respectively. This paper aims to systematically investigate the importance of relational cues in surgery. First, we contribute the RLLS12M dataset, a large-scale collection of robotic left lateral sectionectomy (RLLS), by curating 50 videos of 50 patients operated by 5 surgeons and annotating a hierarchical workflow, which consists of 3 inter- and 6 intra-relations, 6 steps, 15 tasks, and 38 activities represented as the triplet of 11 instruments, 8 actions, and 16 objects, totaling 2,113,510 video frames and 12,681,060 annotation entities. Correspondingly, we propose a multi-relation purification hybrid network (MURPHY), which aptly incorporates novel relation modules to augment the feature representation by purifying relational features using the intra- and inter-relations embodied in annotations. The intra-relation module leverages a R-GCN to implant visual features in different graph relations, which are aggregated using a targeted relation purification with affinity information measuring label consistency and feature similarity. The inter-relation module is motivated by attention mechanisms to regularize the influence of relational features based on the hierarchy of annotation types from the domain knowledge. Extensive experimental results on the curated RLLS dataset confirm the effectiveness of our approach, demonstrating that relations matter in surgical workflow analysis.
Policy Learning for Active Target Tracking over Continuous SE(3) Trajectories
Dec 03, 2022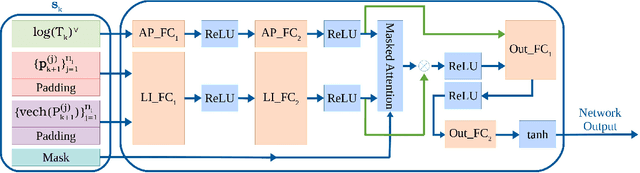

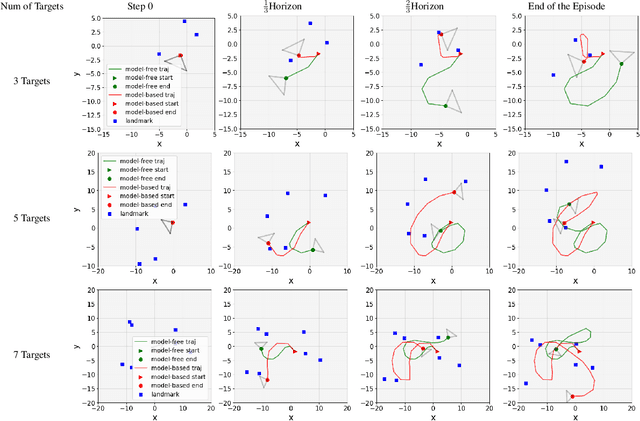
This paper proposes a novel model-based policy gradient algorithm for tracking dynamic targets using a mobile robot, equipped with an onboard sensor with limited field of view. The task is to obtain a continuous control policy for the mobile robot to collect sensor measurements that reduce uncertainty in the target states, measured by the target distribution entropy. We design a neural network control policy with the robot $SE(3)$ pose and the mean vector and information matrix of the joint target distribution as inputs and attention layers to handle variable numbers of targets. We also derive the gradient of the target entropy with respect to the network parameters explicitly, allowing efficient model-based policy gradient optimization.
Increasing Physical Layer Security through Hyperchaos in VLC Systems
Dec 17, 2022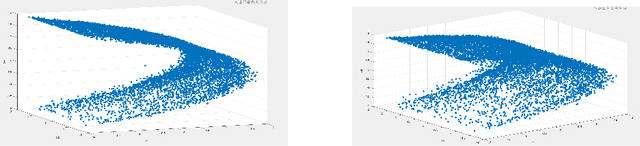
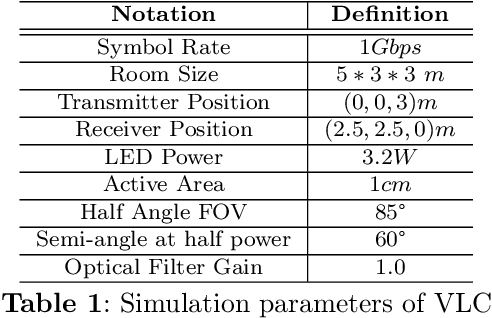
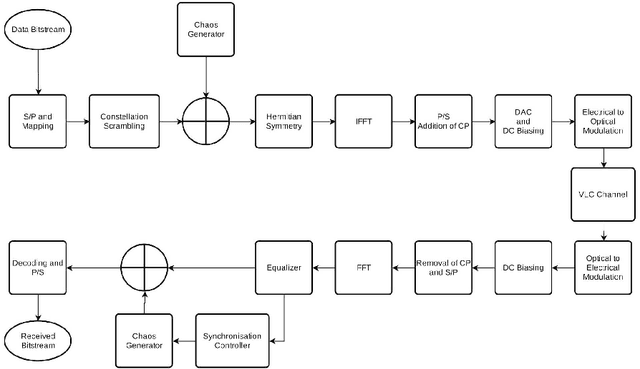
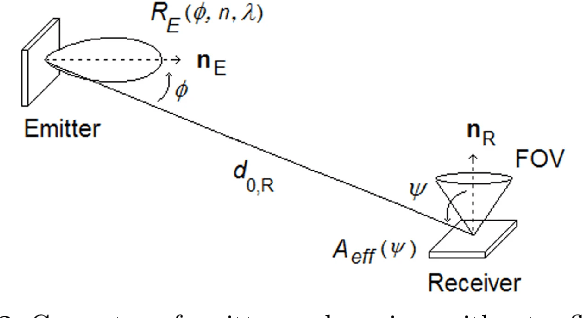
Visible Light Communication (VLC) systems have relatively higher security compared with traditional Radio Frequency (RF) channels due to line-of-sight (LOS) propagation. However, they still are susceptible to eavesdropping. The proposed solution of the papers have been built on existing work on hyperchaos-based security measure to increase physical layer security from eavesdroppers. A fourth-order Henon map is used to scramble the constellation diagrams of the transmitted signals. The scramblers change the constellation symbol of the system using a key. That key on the receiver side de-scrambles the received data. The presented modulation scheme takes advantage of a higher degree of the map to isolate the data transmission to a single dimension, allowing for better scrambling and synchronization. A sliding mode controller is used at the receiver in a master-slave configuration for projective synchronization of the two Henon maps, which helps de-scramble the received data. The data is only isolated for the users aware of the key for synchronization, providing security against eavesdroppers. The proposed VLC system is compared against various existing approaches based on various metrics. An improved Bit Error Rate and a lower information leakage are achieved for a variety of modulation schemes at an acceptable Signal-to-Noise Ratio.
Pilot Reuse in Cell-Free Massive MIMO Systems: A Diverse Clustering Approach
Dec 17, 2022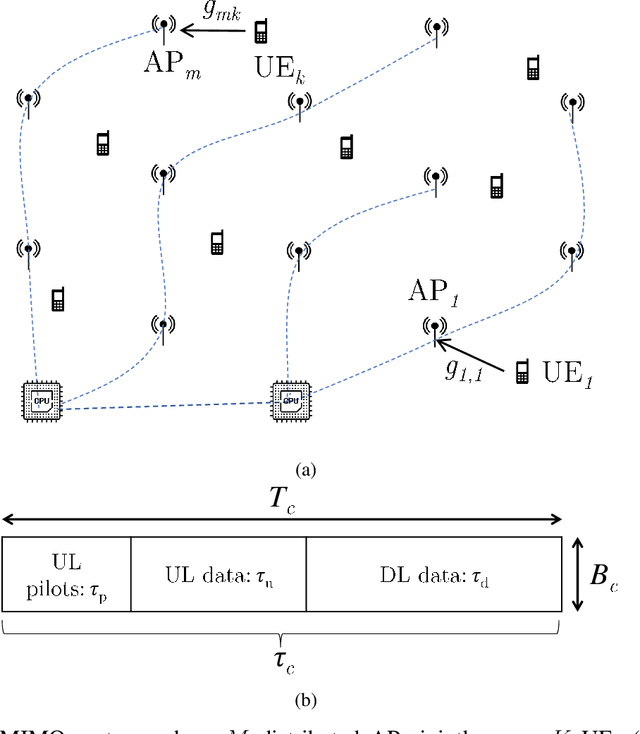
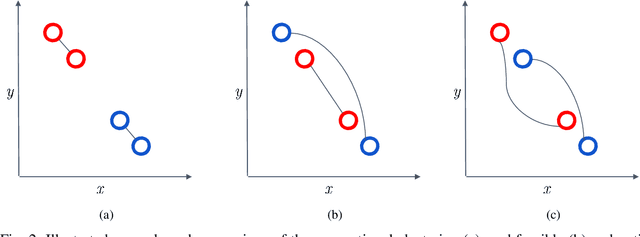
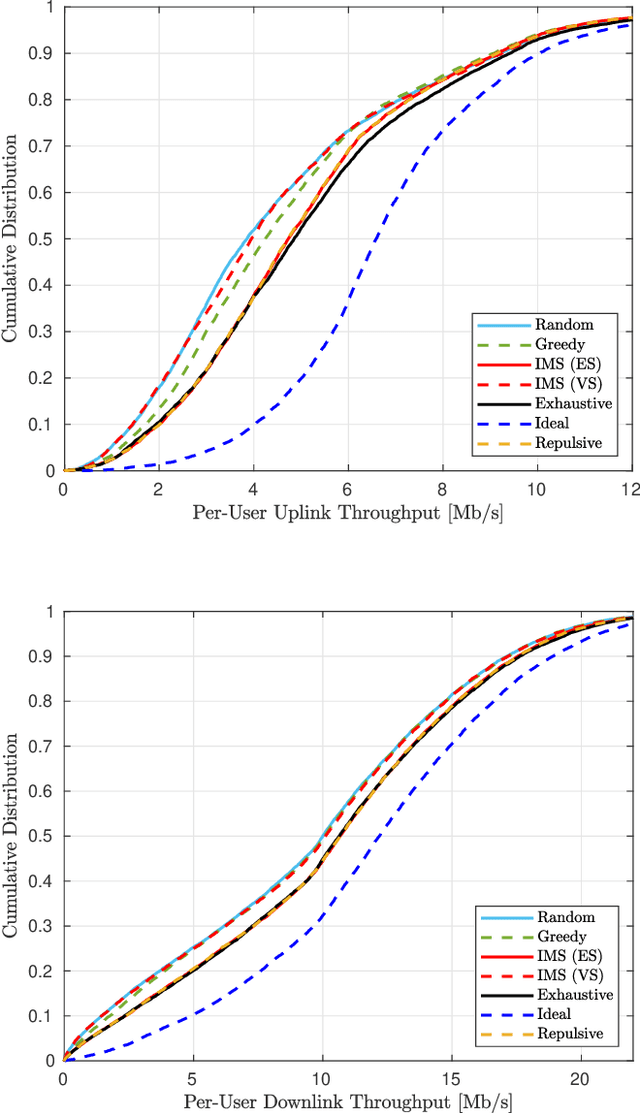
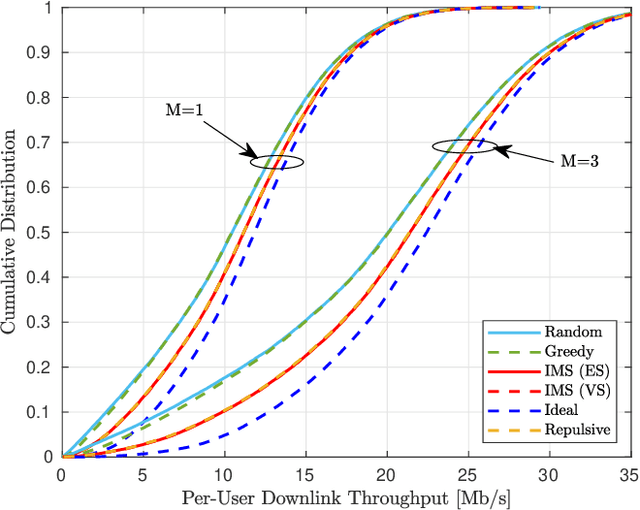
Distributed or Cell-free (CF) massive Multiple-Input, Multiple-Output (mMIMO), has been recently proposed as an answer to the limitations of the current network-centric systems in providing high-rate ubiquitous transmission. The capability of providing uniform service level makes CF mMIMO a potential technology for beyond-5G and 6G networks. The acquisition of accurate Channel State Information (CSI) is critical for different CF mMIMO operations. Hence, an uplink pilot training phase is used to efficiently estimate transmission channels. The number of available orthogonal pilot signals is limited, and reusing these pilots will increase co-pilot interference. This causes an undesirable effect known as pilot contamination that could reduce the system performance. Hence, a proper pilot reuse strategy is needed to mitigate the effects of pilot contamination. In this paper, we formulate pilot assignment in CF mMIMO as a diverse clustering problem and propose an iterative maxima search scheme to solve it. In this approach, we first form the clusters of User Equipments (UEs) so that the intra-cluster diversity maximizes and then assign the same pilots for all UEs in the same cluster. The numerical results show the proposed techniques' superiority over other methods concerning the achieved uplink and downlink average and per-user data rate.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Dec 17, 2022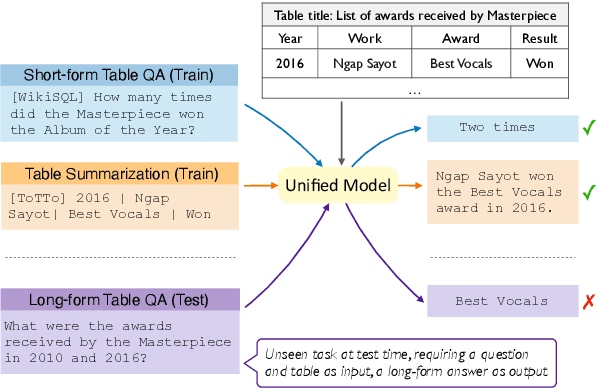
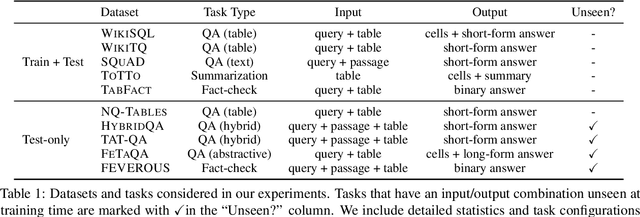
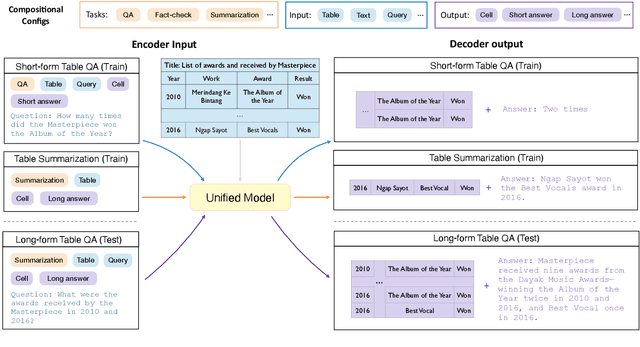
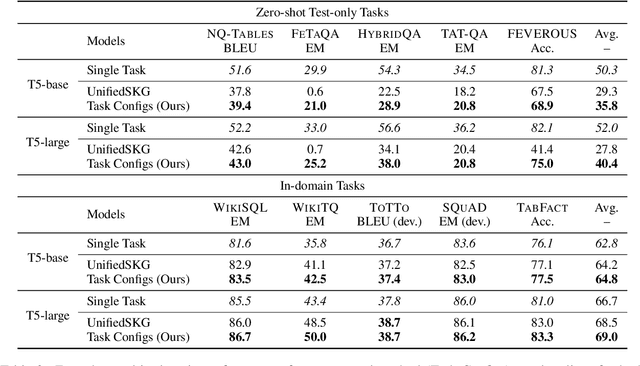
There has been great progress in unifying various table-to-text tasks using a single encoder-decoder model trained via multi-task learning (Xie et al., 2022). However, existing methods typically encode task information with a simple dataset name as a prefix to the encoder. This not only limits the effectiveness of multi-task learning, but also hinders the model's ability to generalize to new domains or tasks that were not seen during training, which is crucial for real-world applications. In this paper, we propose compositional task configurations, a set of prompts prepended to the encoder to improve cross-task generalization of unified models. We design the task configurations to explicitly specify the task type, as well as its input and output types. We show that this not only allows the model to better learn shared knowledge across different tasks at training, but also allows us to control the model by composing new configurations that apply novel input-output combinations in a zero-shot manner. We demonstrate via experiments over ten table-to-text tasks that our method outperforms the UnifiedSKG baseline by noticeable margins in both in-domain and zero-shot settings, with average improvements of +0.5 and +12.6 from using a T5-large backbone, respectively.
Perspective Fields for Single Image Camera Calibration
Dec 06, 2022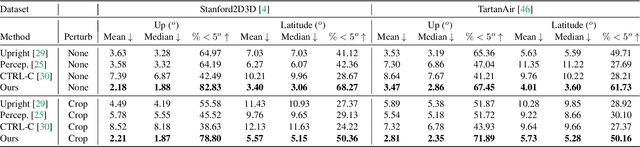
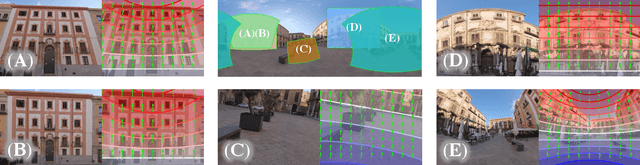


Geometric camera calibration is often required for applications that understand the perspective of the image. We propose perspective fields as a representation that models the local perspective properties of an image. Perspective Fields contain per-pixel information about the camera view, parameterized as an up vector and a latitude value. This representation has a number of advantages as it makes minimal assumptions about the camera model and is invariant or equivariant to common image editing operations like cropping, warping, and rotation. It is also more interpretable and aligned with human perception. We train a neural network to predict Perspective Fields and the predicted Perspective Fields can be converted to calibration parameters easily. We demonstrate the robustness of our approach under various scenarios compared with camera calibration-based methods and show example applications in image compositing.
Observable Perfect Equilibrium
Nov 12, 2022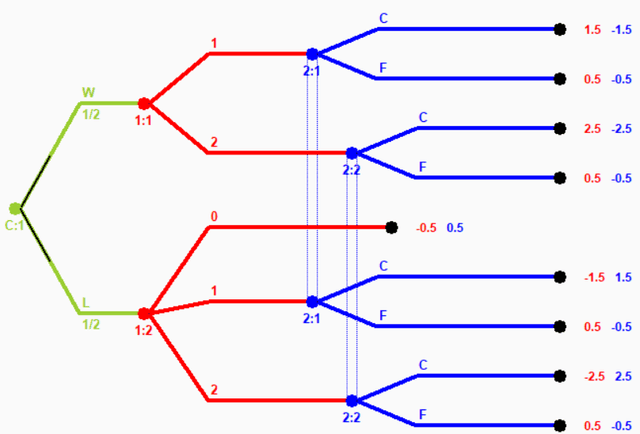
While Nash equilibrium has emerged as the central game-theoretic solution concept, many important games contain several Nash equilibria and we must determine how to select between them in order to create real strategic agents. Several Nash equilibrium refinement concepts have been proposed and studied for sequential imperfect-information games, the most prominent being trembling-hand perfect equilibrium, quasi-perfect equilibrium, and recently one-sided quasi-perfect equilibrium. These concepts are robust to certain arbitrarily small mistakes, and are guaranteed to always exist; however, we argue that neither of these is the correct concept for developing strong agents in sequential games of imperfect information. We define a new equilibrium refinement concept for extensive-form games called observable perfect equilibrium in which the solution is robust over trembles in publicly-observable action probabilities (not necessarily over all action probabilities that may not be observable by opposing players). Observable perfect equilibrium correctly captures the assumption that the opponent is playing as rationally as possible given mistakes that have been observed (while previous solution concepts do not). We prove that observable perfect equilibrium is always guaranteed to exist, and demonstrate that it leads to a different solution than the prior extensive-form refinements in no-limit poker. We expect observable perfect equilibrium to be a useful equilibrium refinement concept for modeling many important imperfect-information games of interest in artificial intelligence.