 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Pre-Training Tasks for Neural Machine Translation
Dec 19, 2022



Pre-training is an effective technique for ensuring robust performance on a variety of machine learning tasks. It typically depends on large-scale crawled corpora that can result in toxic or biased models. Such data can also be problematic with respect to copyright, attribution, and privacy. Pre-training with synthetic tasks and data is a promising way of alleviating such concerns since no real-world information is ingested by the model. Our goal in this paper is to understand what makes for a good pre-trained model when using synthetic resources. We answer this question in the context of neural machine translation by considering two novel approaches to translation model pre-training. Our first approach studies the effect of pre-training on obfuscated data derived from a parallel corpus by mapping words to a vocabulary of 'nonsense' tokens. Our second approach explores the effect of pre-training on procedurally generated synthetic parallel data that does not depend on any real human language corpus. Our empirical evaluation on multiple language pairs shows that, to a surprising degree, the benefits of pre-training can be realized even with obfuscated or purely synthetic parallel data. In our analysis, we consider the extent to which obfuscated and synthetic pre-training techniques can be used to mitigate the issue of hallucinated model toxicity.
Multilingual Neural Machine Translation with Task-Specific Attention
Jun 08, 2018
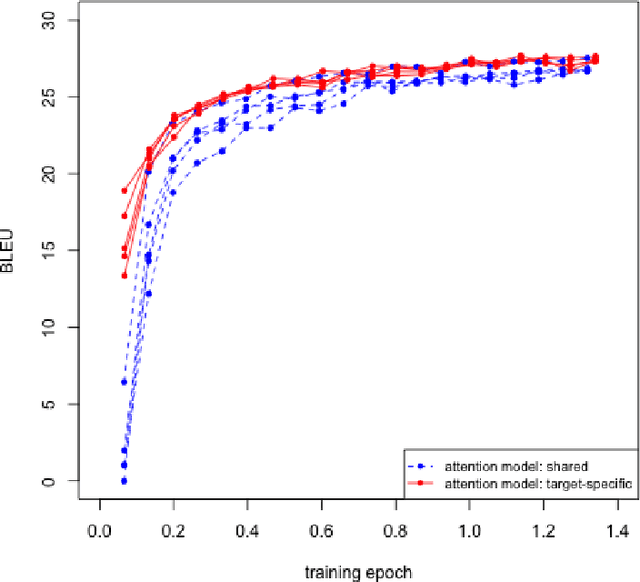
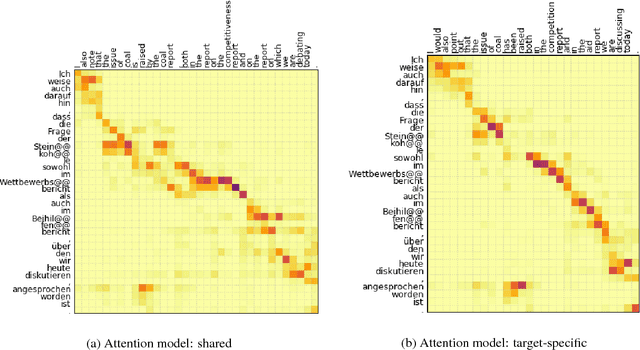
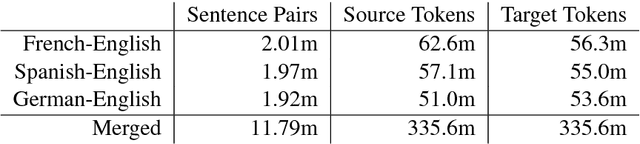
Multilingual machine translation addresses the task of translating between multiple source and target languages. We propose task-specific attention models, a simple but effective technique for improving the quality of sequence-to-sequence neural multilingual translation. Our approach seeks to retain as much of the parameter sharing generalization of NMT models as possible, while still allowing for language-specific specialization of the attention model to a particular language-pair or task. Our experiments on four languages of the Europarl corpus show that using a target-specific model of attention provides consistent gains in translation quality for all possible translation directions, compared to a model in which all parameters are shared. We observe improved translation quality even in the (extreme) low-resource zero-shot translation directions for which the model never saw explicitly paired parallel data.