 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
F2SD: A dataset for end-to-end group detection algorithms
Nov 20, 2022

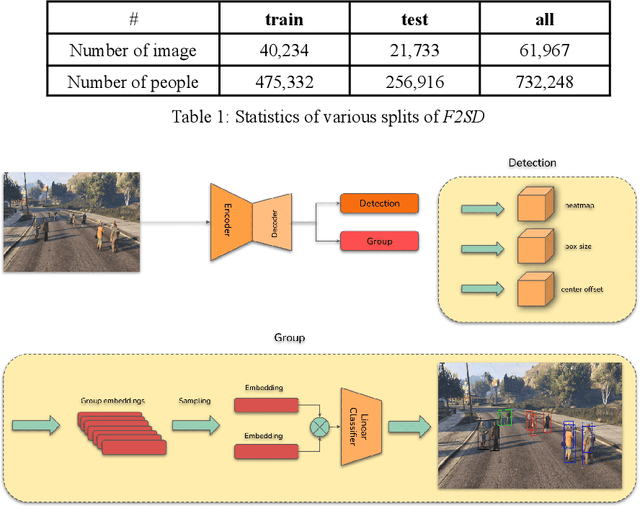
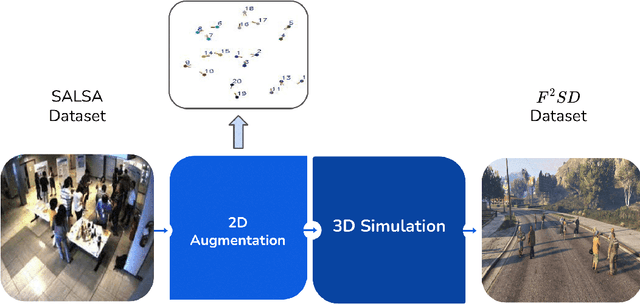
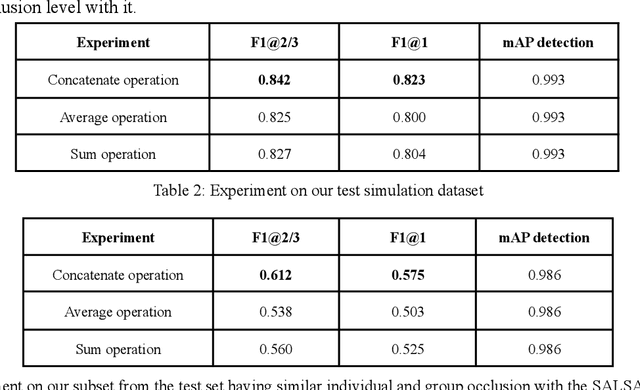
The lack of large-scale datasets has been impeding the advance of deep learning approaches to the problem of F-formation detection. Moreover, most research works on this problem rely on input sensor signals of object location and orientation rather than image signals. To address this, we develop a new, large-scale dataset of simulated images for F-formation detection, called F-formation Simulation Dataset (F2SD). F2SD contains nearly 60,000 images simulated from GTA-5, with bounding boxes and orientation information on images, making it useful for a wide variety of modelling approaches. It is also closer to practical scenarios, where three-dimensional location and orientation information are costly to record. It is challenging to construct such a large-scale simulated dataset while keeping it realistic. Furthermore, the available research utilizes conventional methods to detect groups. They do not detect groups directly from the image. In this work, we propose (1) a large-scale simulation dataset F2SD and a pipeline for F-formation simulation, (2) a first-ever end-to-end baseline model for the task, and experiments on our simulation dataset.
C3SASR: Cheap Causal Convolutions for Self-Attentive Sequential Recommendation
Nov 07, 2022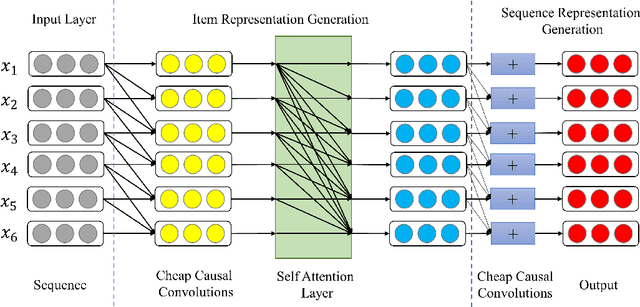

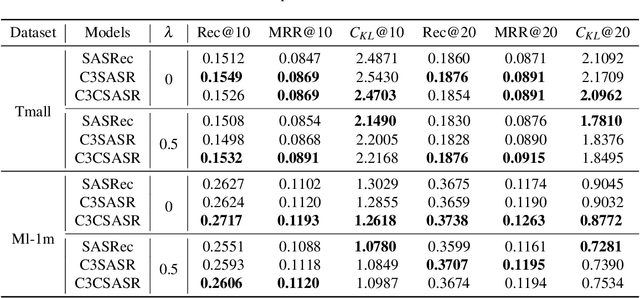
Sequential Recommendation is a prominent topic in current research, which uses user behavior sequence as an input to predict future behavior. By assessing the correlation strength of historical behavior through the dot product, the model based on the self-attention mechanism can capture the long-term preference of the sequence. However, it has two limitations. On the one hand, it does not effectively utilize the items' local context information when determining the attention and creating the sequence representation. On the other hand, the convolution and linear layers often contain redundant information, which limits the ability to encode sequences. In this paper, we propose a self-attentive sequential recommendation model based on cheap causal convolution. It utilizes causal convolutions to capture items' local information for calculating attention and generating sequence embedding. It also uses cheap convolutions to improve the representations by lightweight structure. We evaluate the effectiveness of the proposed model in terms of both accurate and calibrated sequential recommendation. Experiments on benchmark datasets show that the proposed model can perform better in single- and multi-objective recommendation scenarios.
Interactive Context-Aware Network for RGB-T Salient Object Detection
Nov 11, 2022
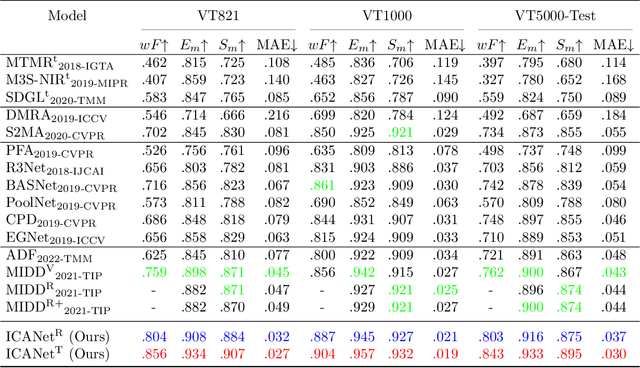
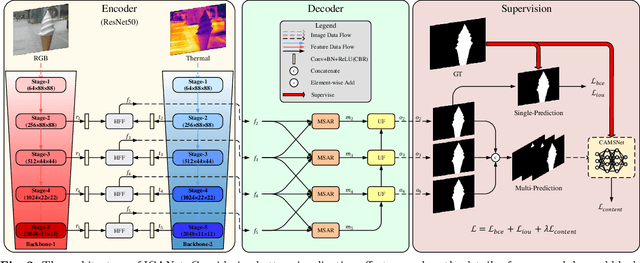
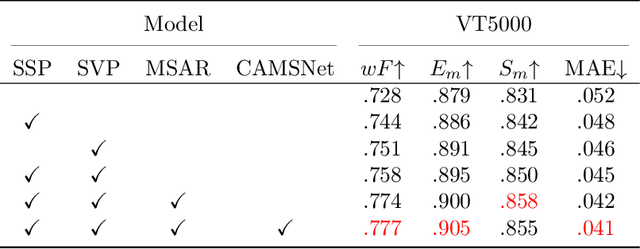
Salient object detection (SOD) focuses on distinguishing the most conspicuous objects in the scene. However, most related works are based on RGB images, which lose massive useful information. Accordingly, with the maturity of thermal technology, RGB-T (RGB-Thermal) multi-modality tasks attain more and more attention. Thermal infrared images carry important information which can be used to improve the accuracy of SOD prediction. To accomplish it, the methods to integrate multi-modal information and suppress noises are critical. In this paper, we propose a novel network called Interactive Context-Aware Network (ICANet). It contains three modules that can effectively perform the cross-modal and cross-scale fusions. We design a Hybrid Feature Fusion (HFF) module to integrate the features of two modalities, which utilizes two types of feature extraction. The Multi-Scale Attention Reinforcement (MSAR) and Upper Fusion (UF) blocks are responsible for the cross-scale fusion that converges different levels of features and generate the prediction maps. We also raise a novel Context-Aware Multi-Supervised Network (CAMSNet) to calculate the content loss between the prediction and the ground truth (GT). Experiments prove that our network performs favorably against the state-of-the-art RGB-T SOD methods.
Leveraging Wikidata's edit history in knowledge graph refinement tasks
Oct 27, 2022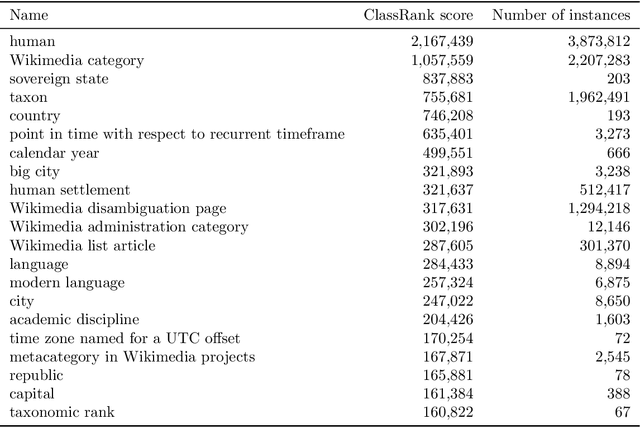
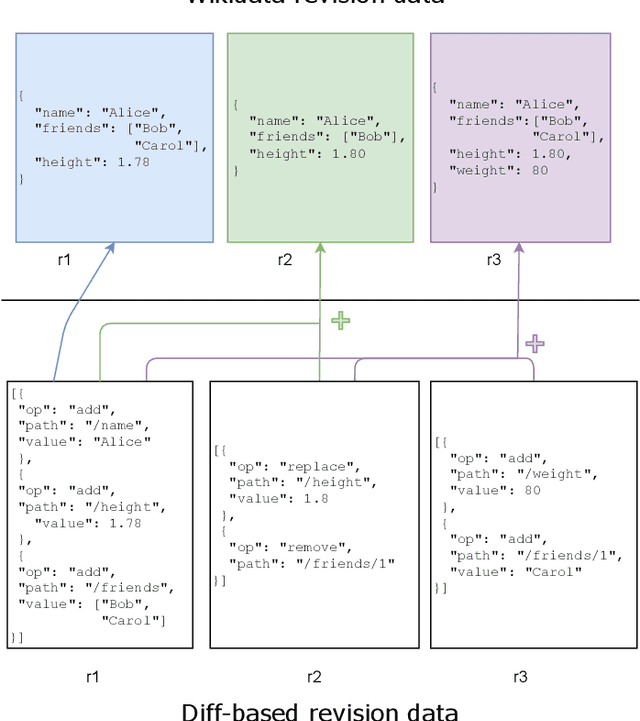

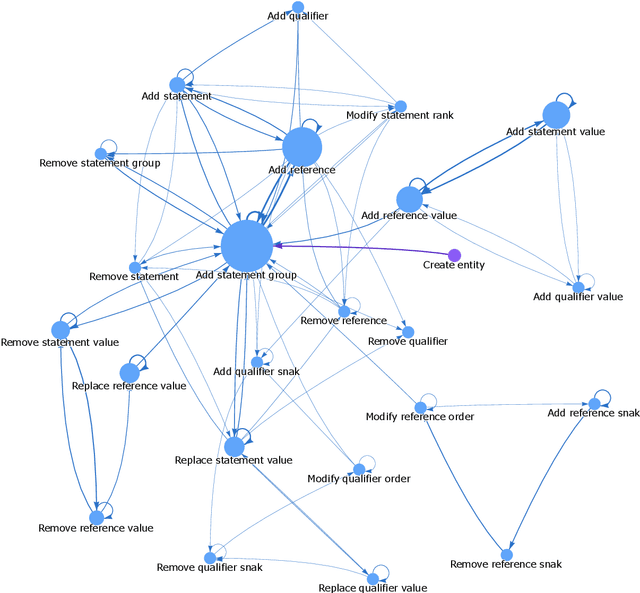
Knowledge graphs have been adopted in many diverse fields for a variety of purposes. Most of those applications rely on valid and complete data to deliver their results, pressing the need to improve the quality of knowledge graphs. A number of solutions have been proposed to that end, ranging from rule-based approaches to the use of probabilistic methods, but there is an element that has not been considered yet: the edit history of the graph. In the case of collaborative knowledge graphs (e.g., Wikidata), those edits represent the process in which the community reaches some kind of fuzzy and distributed consensus over the information that best represents each entity, and can hold potentially interesting information to be used by knowledge graph refinement methods. In this paper, we explore the use of edit history information from Wikidata to improve the performance of type prediction methods. To do that, we have first built a JSON dataset containing the edit history of every instance from the 100 most important classes in Wikidata. This edit history information is then explored and analyzed, with a focus on its potential applicability in knowledge graph refinement tasks. Finally, we propose and evaluate two new methods to leverage this edit history information in knowledge graph embedding models for type prediction tasks. Our results show an improvement in one of the proposed methods against current approaches, showing the potential of using edit information in knowledge graph refinement tasks and opening new promising research lines within the field.
ChartParser: Automatic Chart Parsing for Print-Impaired
Nov 16, 2022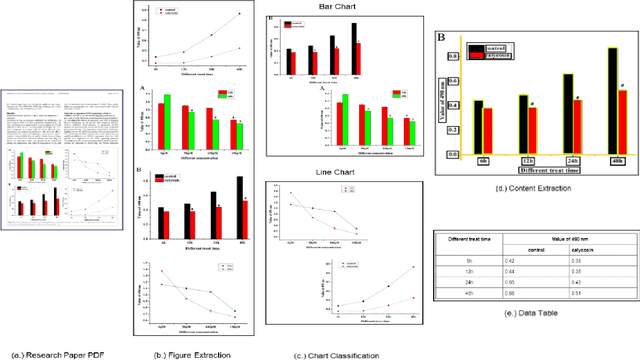
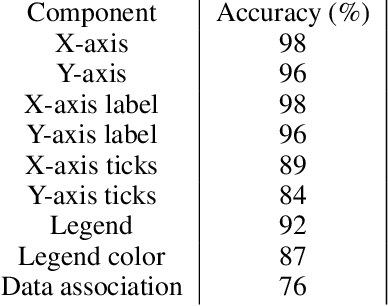
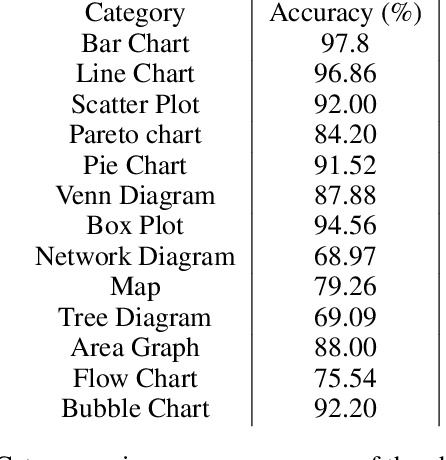
Infographics are often an integral component of scientific documents for reporting qualitative or quantitative findings as they make it much simpler to comprehend the underlying complex information. However, their interpretation continues to be a challenge for the blind, low-vision, and other print-impaired (BLV) individuals. In this paper, we propose ChartParser, a fully automated pipeline that leverages deep learning, OCR, and image processing techniques to extract all figures from a research paper, classify them into various chart categories (bar chart, line chart, etc.) and obtain relevant information from them, specifically bar charts (including horizontal, vertical, stacked horizontal and stacked vertical charts) which already have several exciting challenges. Finally, we present the retrieved content in a tabular format that is screen-reader friendly and accessible to the BLV users. We present a thorough evaluation of our approach by applying our pipeline to sample real-world annotated bar charts from research papers.
Visual Information Guided Zero-Shot Paraphrase Generation
Jan 22, 2022

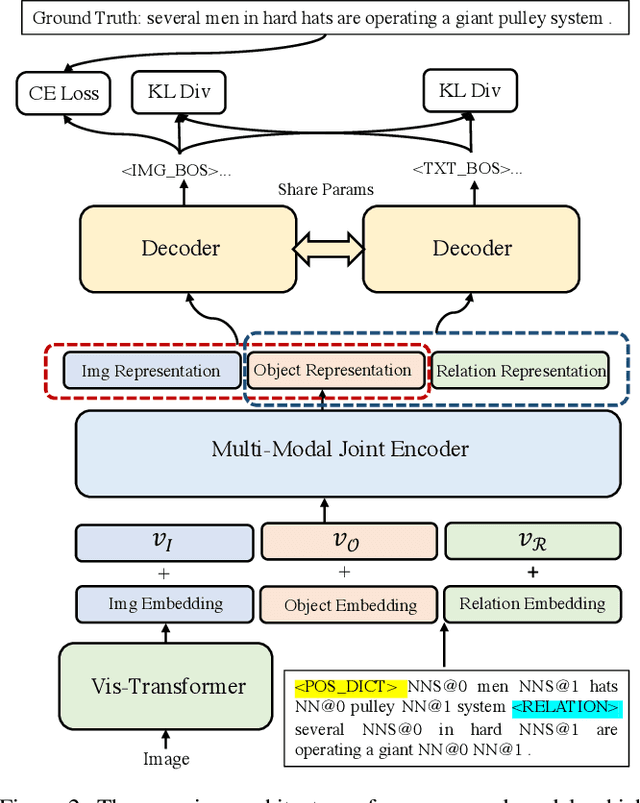
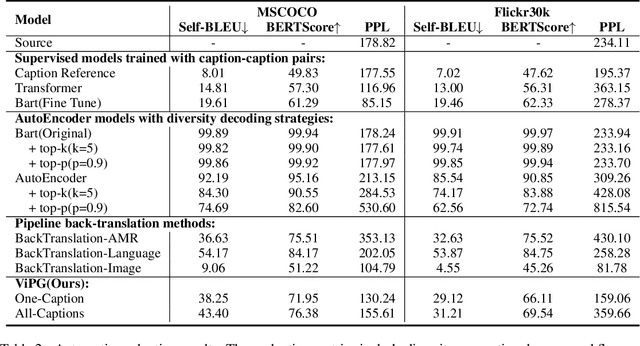
Zero-shot paraphrase generation has drawn much attention as the large-scale high-quality paraphrase corpus is limited. Back-translation, also known as the pivot-based method, is typical to this end. Several works leverage different information as "pivot" such as language, semantic representation and so on. In this paper, we explore using visual information such as image as the "pivot" of back-translation. Different with the pipeline back-translation method, we propose visual information guided zero-shot paraphrase generation (ViPG) based only on paired image-caption data. It jointly trains an image captioning model and a paraphrasing model and leverage the image captioning model to guide the training of the paraphrasing model. Both automatic evaluation and human evaluation show our model can generate paraphrase with good relevancy, fluency and diversity, and image is a promising kind of pivot for zero-shot paraphrase generation.
Weakly-supervised Pre-training for 3D Human Pose Estimation via Perspective Knowledge
Nov 22, 2022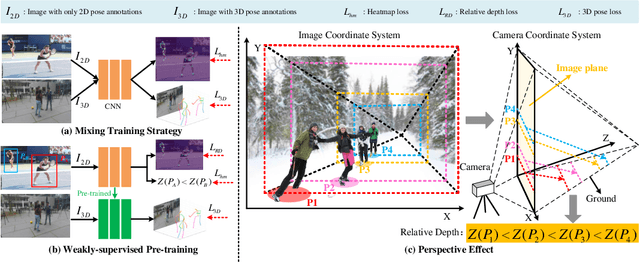
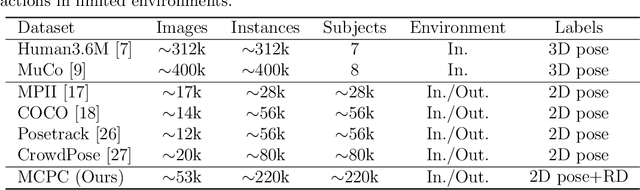
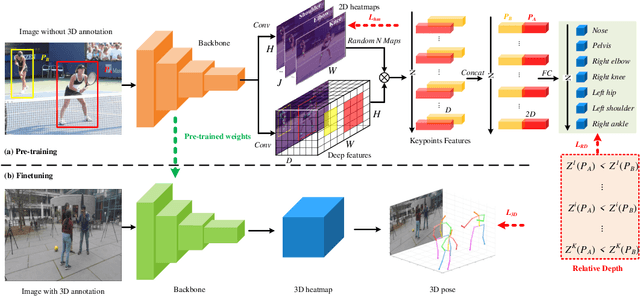

Modern deep learning-based 3D pose estimation approaches require plenty of 3D pose annotations. However, existing 3D datasets lack diversity, which limits the performance of current methods and their generalization ability. Although existing methods utilize 2D pose annotations to help 3D pose estimation, they mainly focus on extracting 2D structural constraints from 2D poses, ignoring the 3D information hidden in the images. In this paper, we propose a novel method to extract weak 3D information directly from 2D images without 3D pose supervision. Firstly, we utilize 2D pose annotations and perspective prior knowledge to generate the relationship of that keypoint is closer or farther from the camera, called relative depth. We collect a 2D pose dataset (MCPC) and generate relative depth labels. Based on MCPC, we propose a weakly-supervised pre-training (WSP) strategy to distinguish the depth relationship between two points in an image. WSP enables the learning of the relative depth of two keypoints on lots of in-the-wild images, which is more capable of predicting depth and generalization ability for 3D human pose estimation. After fine-tuning on 3D pose datasets, WSP achieves state-of-the-art results on two widely-used benchmarks.
Ontology-aware Learning and Evaluation for Audio Tagging
Nov 22, 2022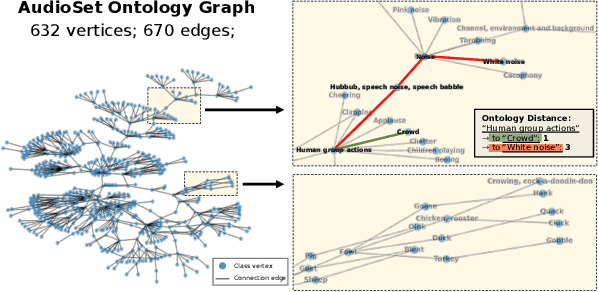
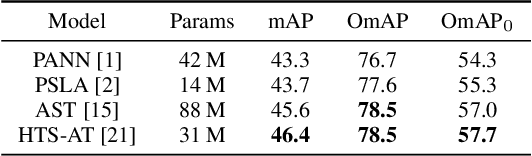
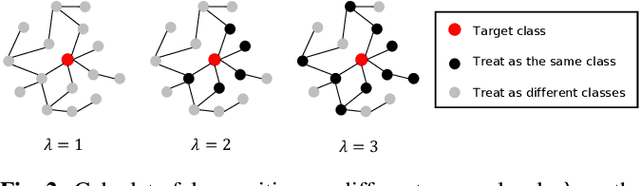

This study defines a new evaluation metric for audio tagging tasks to overcome the limitation of the conventional mean average precision (mAP) metric, which treats different kinds of sound as independent classes without considering their relations. Also, due to the ambiguities in sound labeling, the labels in the training and evaluation set are not guaranteed to be accurate and exhaustive, which poses challenges for robust evaluation with mAP. The proposed metric, ontology-aware mean average precision (OmAP) addresses the weaknesses of mAP by utilizing the AudioSet ontology information during the evaluation. Specifically, we reweight the false positive events in the model prediction based on the ontology graph distance to the target classes. The OmAP measure also provides more insights into model performance by evaluations with different coarse-grained levels in the ontology graph. We conduct human evaluations and demonstrate that OmAP is more consistent with human perception than mAP. To further verify the importance of utilizing the ontology information, we also propose a novel loss function (OBCE) that reweights binary cross entropy (BCE) loss based on the ontology distance. Our experiment shows that OBCE can improve both mAP and OmAP metrics on the AudioSet tagging task.
Capturing long-range interaction with reciprocal space neural network
Nov 30, 2022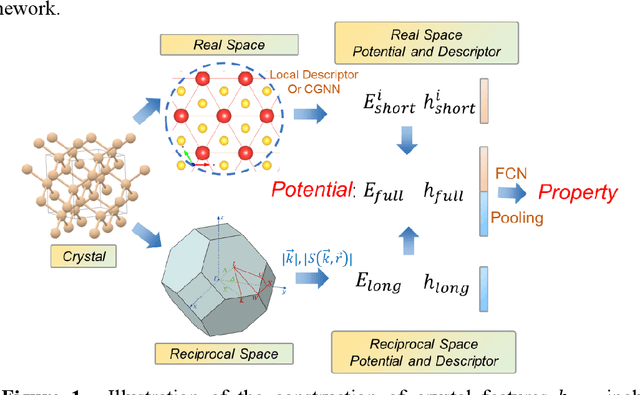
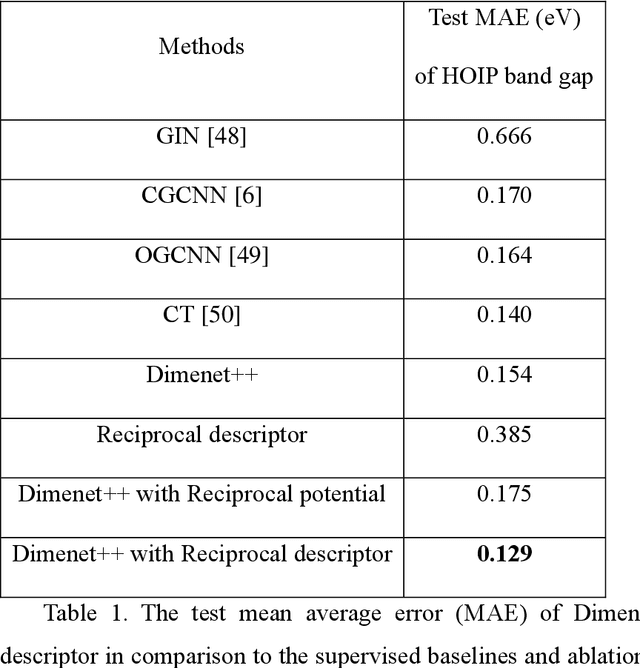
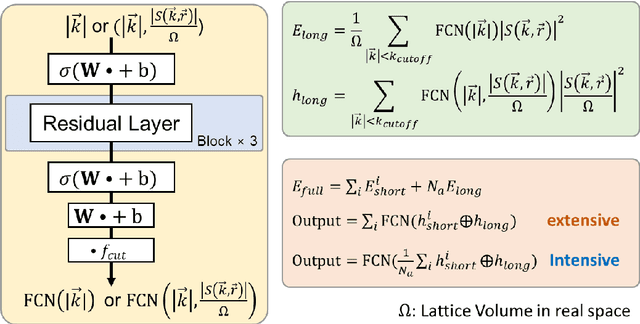
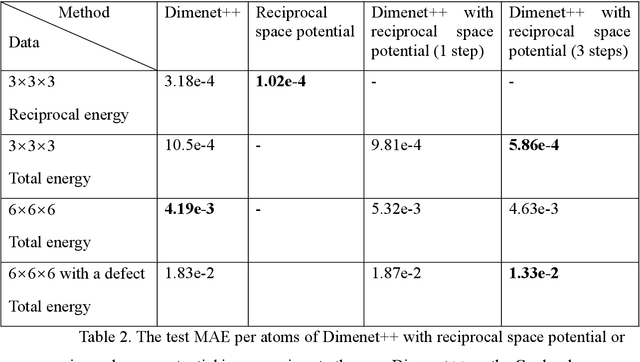
Machine Learning (ML) interatomic models and potentials have been widely employed in simulations of materials. Long-range interactions often dominate in some ionic systems whose dynamics behavior is significantly influenced. However, the long-range effect such as Coulomb and Van der Wales potential is not considered in most ML interatomic potentials. To address this issue, we put forward a method that can take long-range effects into account for most ML local interatomic models with the reciprocal space neural network. The structure information in real space is firstly transformed into reciprocal space and then encoded into a reciprocal space potential or a global descriptor with full atomic interactions. The reciprocal space potential and descriptor keep full invariance of Euclidean symmetry and choice of the cell. Benefiting from the reciprocal-space information, ML interatomic models can be extended to describe the long-range potential including not only Coulomb but any other long-range interaction. A model NaCl system considering Coulomb interaction and the GaxNy system with defects are applied to illustrate the advantage of our approach. At the same time, our approach helps to improve the prediction accuracy of some global properties such as the band gap where the full atomic interaction beyond local atomic environments plays a very important role. In summary, our work has expanded the ability of current ML interatomic models and potentials when dealing with the long-range effect, hence paving a new way for accurate prediction of global properties and large-scale dynamic simulations of systems with defects.
Differentiable Neural Computers with Memory Demon
Nov 05, 2022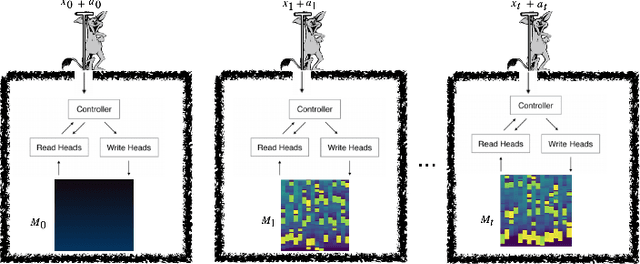
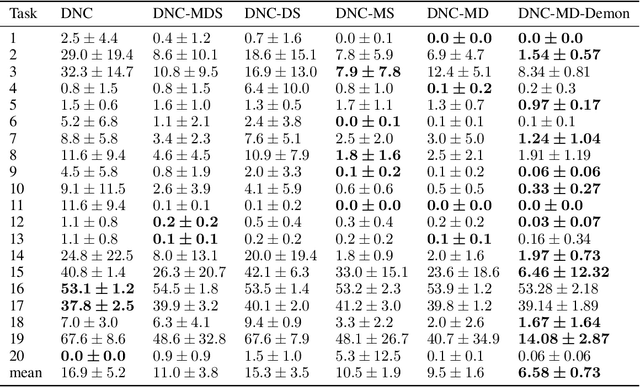

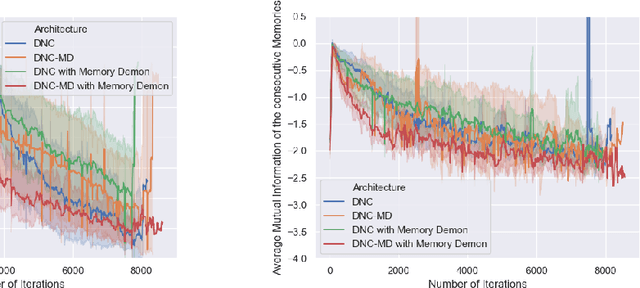
A Differentiable Neural Computer (DNC) is a neural network with an external memory which allows for iterative content modification via read, write and delete operations. We show that information theoretic properties of the memory contents play an important role in the performance of such architectures. We introduce a novel concept of memory demon to DNC architectures which modifies the memory contents implicitly via additive input encoding. The goal of the memory demon is to maximize the expected sum of mutual information of the consecutive external memory contents.