 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Covariance-Based Hybrid Beamforming for Spectrally Efficient Joint Radar-Communications
Nov 15, 2022
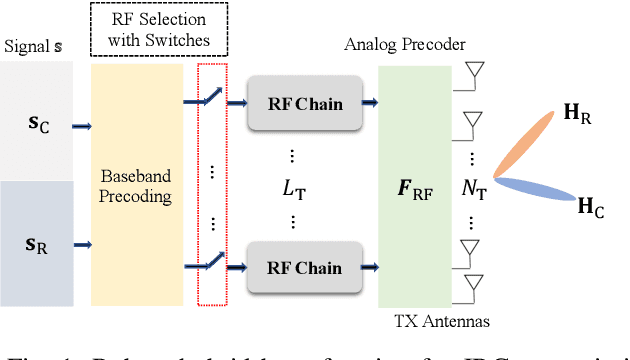
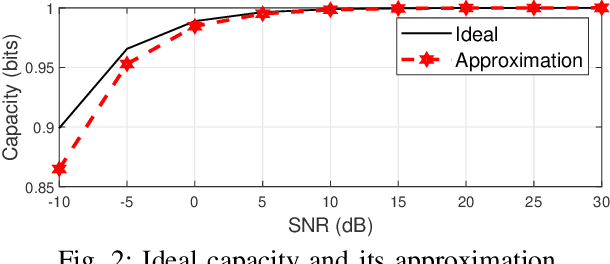
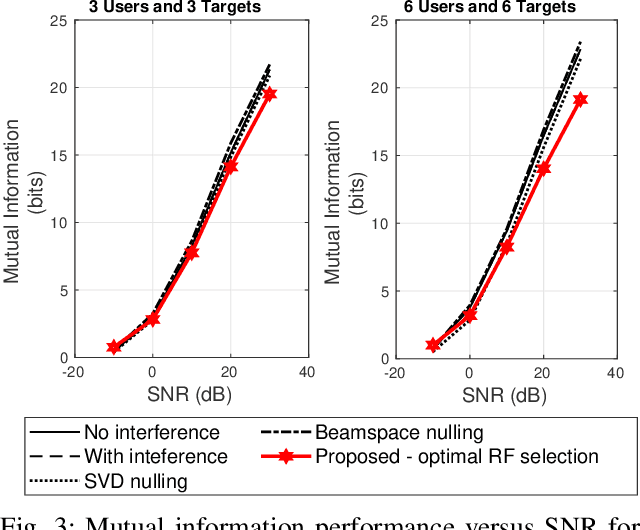
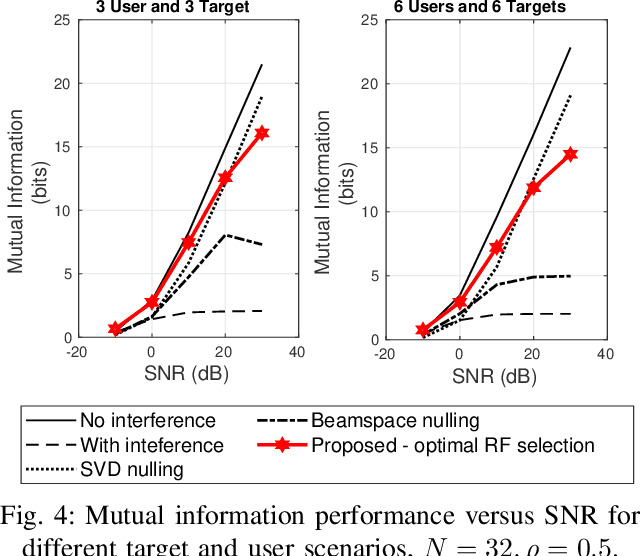
Joint radar-communications (JRC) is considered to be a vital technology in deploying the next generation systems, since its useful in decongestion of the radio frequency (RF) spectrum and utilising the same hardware resources for dual functions. Using JRC systems for dual function generates interference between both the operations which needs to be addressed in future standardization. Furthermore, JRC systems can be advanced by deploying hybrid beamforming which implements fewer number of RF chains than the number of transmit antennas. This paper designs a robust hybrid beamformer for minimizing the interference of a JRC transmitter via RF chain selection resulting into mutual information maximization. We consider a weighted mutual information for the dual function JRC system and implement a common analog beamformer for both the operations. The mutual information maximization problem is formulated which is non-convex and difficult to solve. The problem is simplified to convex form and solved using Dinkelbach approximation abased fractional programming. The performance of the optimal RF selection based proposed approach is evaluated, compared with baselines and its effectiveness is inferred via numerical results.
A Hyperspectral and RGB Dataset for Building Facade Segmentation
Dec 06, 2022
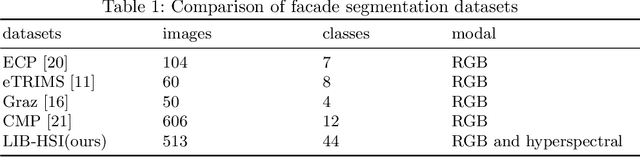
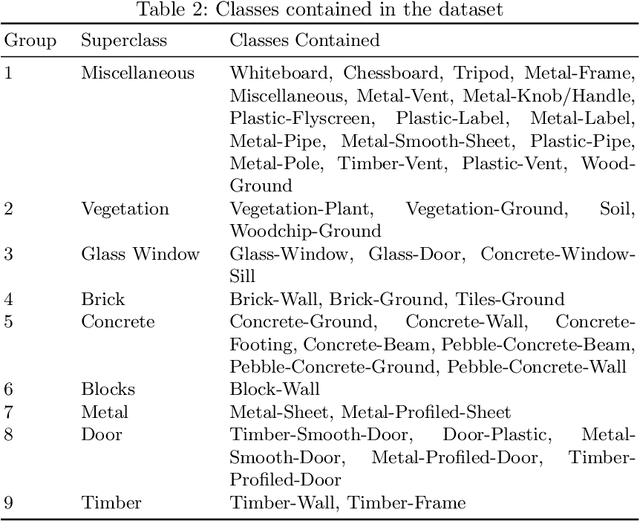

Hyperspectral Imaging (HSI) provides detailed spectral information and has been utilised in many real-world applications. This work introduces an HSI dataset of building facades in a light industry environment with the aim of classifying different building materials in a scene. The dataset is called the Light Industrial Building HSI (LIB-HSI) dataset. This dataset consists of nine categories and 44 classes. In this study, we investigated deep learning based semantic segmentation algorithms on RGB and hyperspectral images to classify various building materials, such as timber, brick and concrete.
DRG-Net: Interactive Joint Learning of Multi-lesion Segmentation and Classification for Diabetic Retinopathy Grading
Dec 30, 2022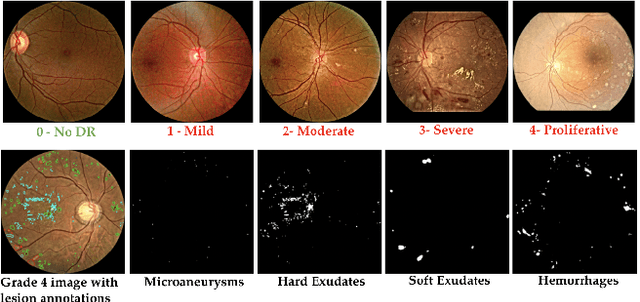
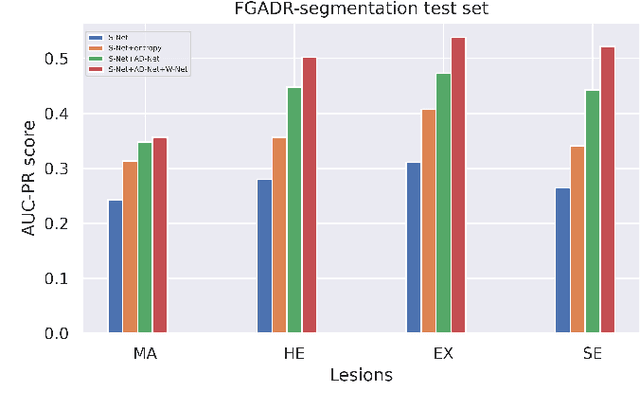
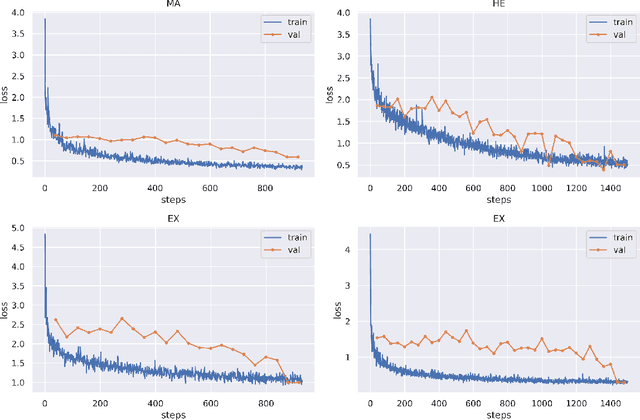
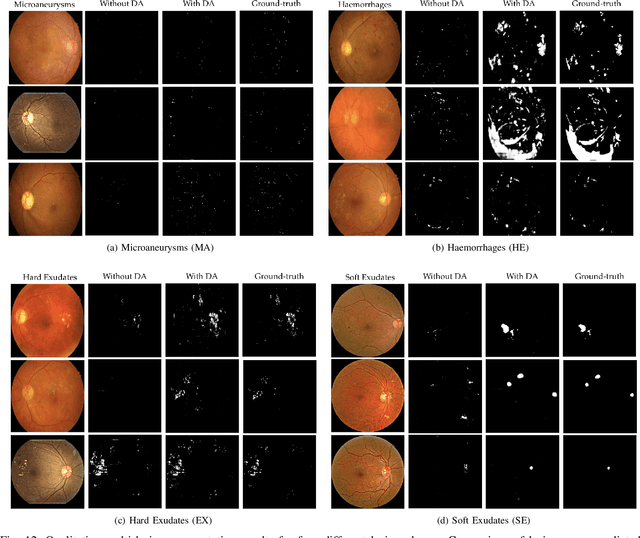
Diabetic Retinopathy (DR) is a leading cause of vision loss in the world, and early DR detection is necessary to prevent vision loss and support an appropriate treatment. In this work, we leverage interactive machine learning and introduce a joint learning framework, termed DRG-Net, to effectively learn both disease grading and multi-lesion segmentation. Our DRG-Net consists of two modules: (i) DRG-AI-System to classify DR Grading, localize lesion areas, and provide visual explanations; (ii) DRG-Expert-Interaction to receive feedback from user-expert and improve the DRG-AI-System. To deal with sparse data, we utilize transfer learning mechanisms to extract invariant feature representations by using Wasserstein distance and adversarial learning-based entropy minimization. Besides, we propose a novel attention strategy at both low- and high-level features to automatically select the most significant lesion information and provide explainable properties. In terms of human interaction, we further develop DRG-Net as a tool that enables expert users to correct the system's predictions, which may then be used to update the system as a whole. Moreover, thanks to the attention mechanism and loss functions constraint between lesion features and classification features, our approach can be robust given a certain level of noise in the feedback of users. We have benchmarked DRG-Net on the two largest DR datasets, i.e., IDRID and FGADR, and compared it to various state-of-the-art deep learning networks. In addition to outperforming other SOTA approaches, DRG-Net is effectively updated using user feedback, even in a weakly-supervised manner.
DGFont++: Robust Deformable Generative Networks for Unsupervised Font Generation
Dec 30, 2022
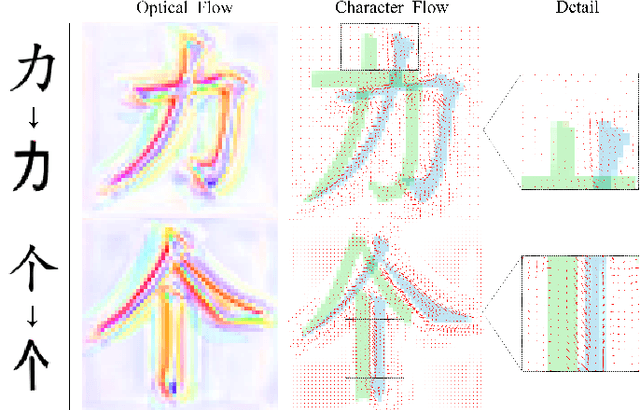


Automatic font generation without human experts is a practical and significant problem, especially for some languages that consist of a large number of characters. Existing methods for font generation are often in supervised learning. They require a large number of paired data, which are labor-intensive and expensive to collect. In contrast, common unsupervised image-to-image translation methods are not applicable to font generation, as they often define style as the set of textures and colors. In this work, we propose a robust deformable generative network for unsupervised font generation (abbreviated as DGFont++). We introduce a feature deformation skip connection (FDSC) to learn local patterns and geometric transformations between fonts. The FDSC predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level content feature maps. The outputs of FDSC are fed into a mixer to generate final results. Moreover, we introduce contrastive self-supervised learning to learn a robust style representation for fonts by understanding the similarity and dissimilarities of fonts. To distinguish different styles, we train our model with a multi-task discriminator, which ensures that each style can be discriminated independently. In addition to adversarial loss, another two reconstruction losses are adopted to constrain the domain-invariant characteristics between generated images and content images. Taking advantage of FDSC and the adopted loss functions, our model is able to maintain spatial information and generates high-quality character images in an unsupervised manner. Experiments demonstrate that our model is able to generate character images of higher quality than state-of-the-art methods.
DSNet: a simple yet efficient network with dual-stream attention for lesion segmentation
Dec 14, 2022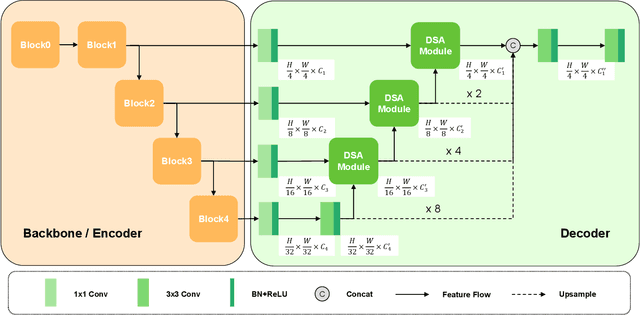
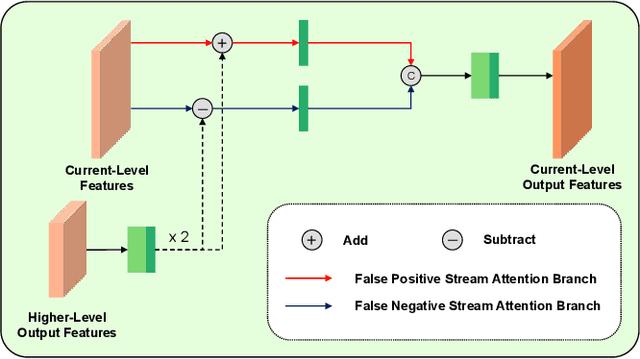
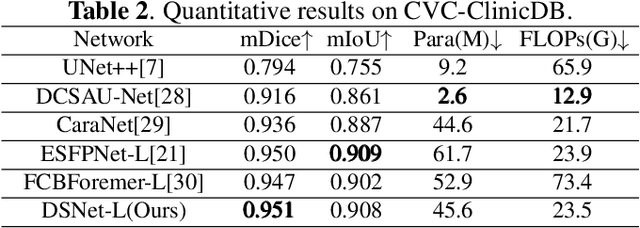
Lesion segmentation requires both speed and accuracy. In this paper, we propose a simple yet efficient network DSNet, which consists of a encoder based on Transformer and a convolutional neural network(CNN)-based distinct pyramid decoder containing three dual-stream attention (DSA) modules. Specifically, the DSA module fuses features from two adjacent levels through the false positive stream attention (FPSA) branch and the false negative stream attention (FNSA) branch to obtain features with diversified contextual information. We compare our method with various state-of-the-art (SOTA) lesion segmentation methods with several public datasets, including CVC-ClinicDB, Kvasir-SEG, and ISIC-2018 Task 1. The experimental results show that our method achieves SOTA performance in terms of mean Dice coefficient (mDice) and mean Intersection over Union (mIoU) with low model complexity and memory consumption.
Multiverse: Multilingual Evidence for Fake News Detection
Nov 25, 2022
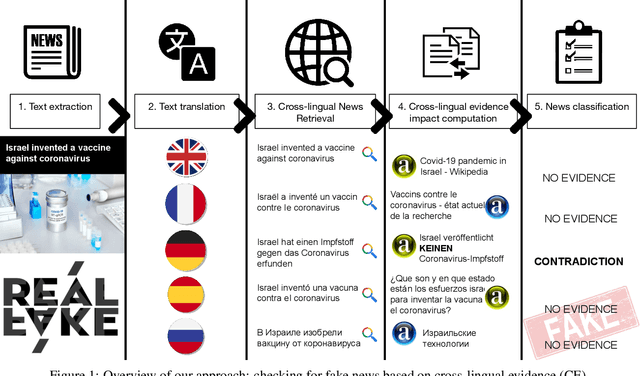
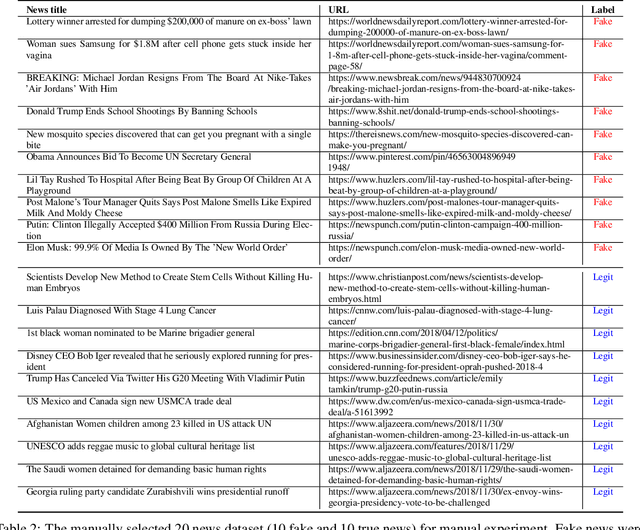
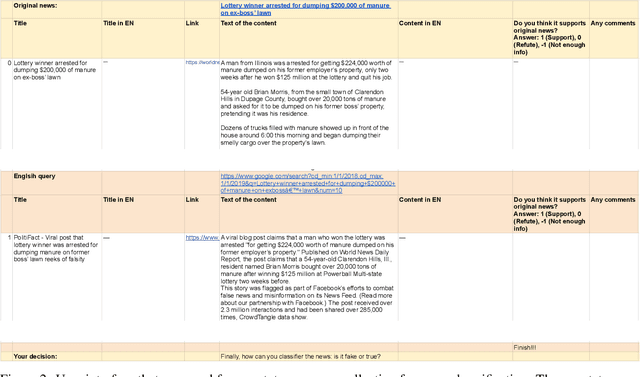
Misleading information spreads on the Internet at an incredible speed, which can lead to irreparable consequences in some cases. It is becoming essential to develop fake news detection technologies. While substantial work has been done in this direction, one of the limitations of the current approaches is that these models are focused only on one language and do not use multilingual information. In this work, we propose Multiverse -- a new feature based on multilingual evidence that can be used for fake news detection and improve existing approaches. The hypothesis of the usage of cross-lingual evidence as a feature for fake news detection is confirmed, firstly, by manual experiment based on a set of known true and fake news. After that, we compared our fake news classification system based on the proposed feature with several baselines on two multi-domain datasets of general-topic news and one fake COVID-19 news dataset showing that in additional combination with linguistic features it yields significant improvements.
Automated Driving Systems Data Acquisition and Processing Platform
Nov 24, 2022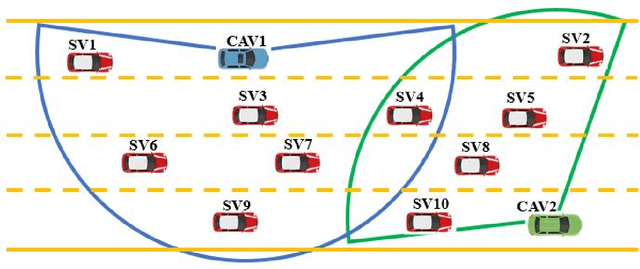
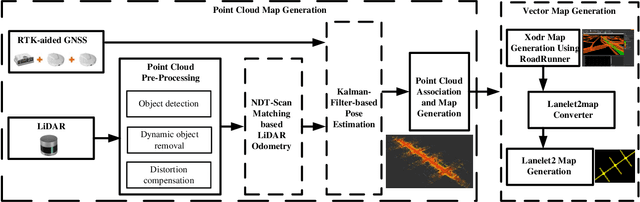
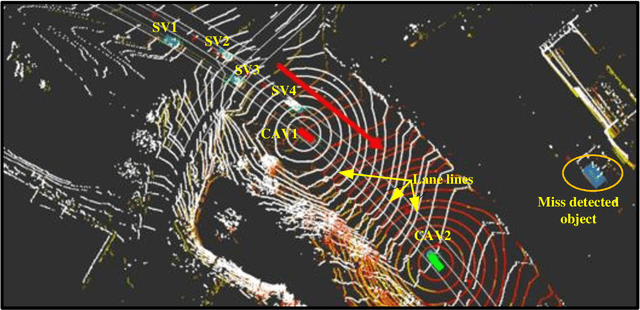
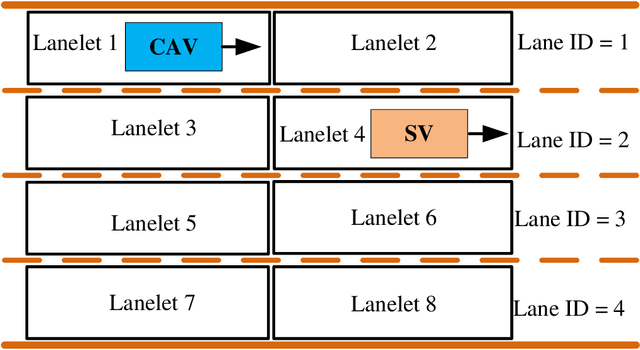
This paper presents an automated driving system (ADS) data acquisition and processing platform for vehicle trajectory extraction, reconstruction, and evaluation based on connected automated vehicle (CAV) cooperative perception. This platform presents a holistic pipeline from the raw advanced sensory data collection to data processing, which can process the sensor data from multiple CAVs and extract the objects' Identity (ID) number, position, speed, and orientation information in the map and Frenet coordinates. First, the ADS data acquisition and analytics platform are presented. Specifically, the experimental CAVs platform and sensor configuration are shown, and the processing software, including a deep-learning-based object detection algorithm using LiDAR information, a late fusion scheme to leverage cooperative perception to fuse the detected objects from multiple CAVs, and a multi-object tracking method is introduced. To further enhance the object detection and tracking results, high definition maps consisting of point cloud and vector maps are generated and forwarded to a world model to filter out the objects off the road and extract the objects' coordinates in Frenet coordinates and the lane information. In addition, a post-processing method is proposed to refine trajectories from the object tracking algorithms. Aiming to tackle the ID switch issue of the object tracking algorithm, a fuzzy-logic-based approach is proposed to detect the discontinuous trajectories of the same object. Finally, results, including object detection and tracking and a late fusion scheme, are presented, and the post-processing algorithm's improvements in noise level and outlier removal are discussed, confirming the functionality and effectiveness of the proposed holistic data collection and processing platform.
Multi-agent Searching System for Medical Information
Mar 23, 2022
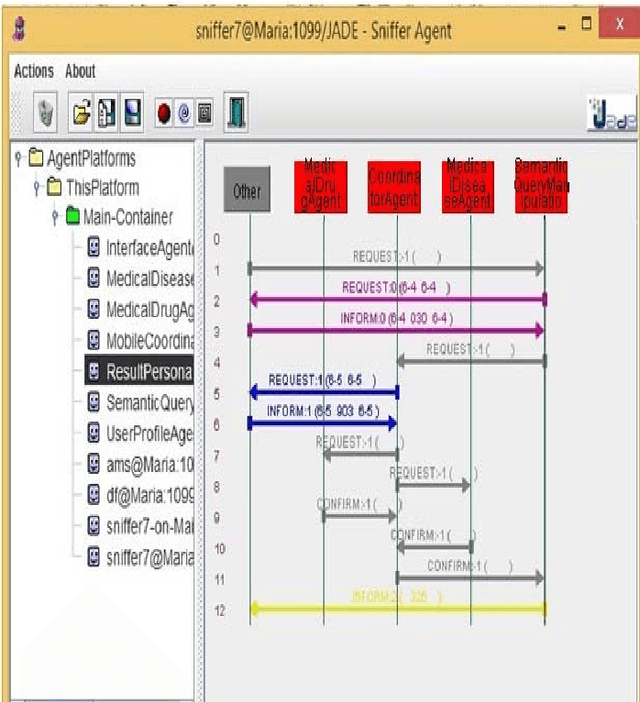
In the paper is proposed a model of multi-agent security system for searching a medical information in Internet. The advantages when using mobile agent are described, so that to perform searching in Internet. Nowadays, multi-agent systems found their application into distribution of decisions. For modeling the proposed multi-agent medical system is used JADE. Finally, the results when using mobile agent are generated that could reflect performance when working with BIG DATA. The proposed system is having also relatively high precision 96%.
* Volume 16, 2019, pp.140-145
A Recursively Recurrent Neural Network (R2N2) Architecture for Learning Iterative Algorithms
Nov 22, 2022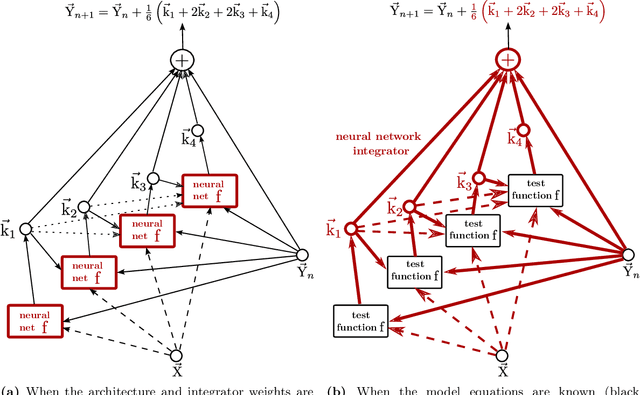
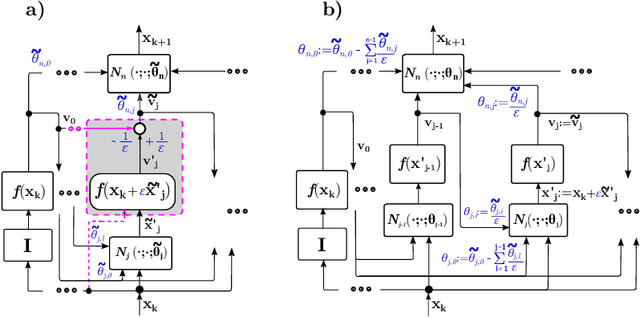
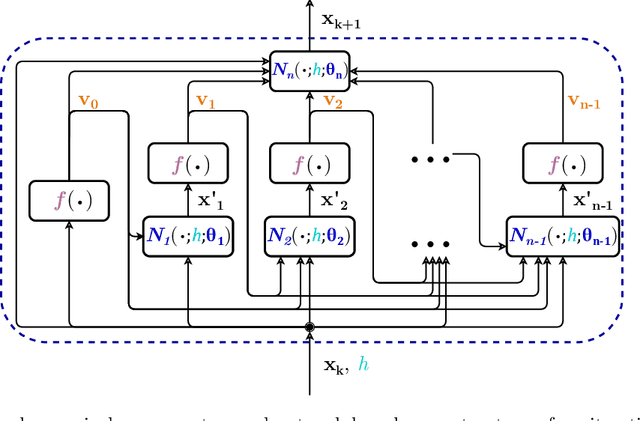
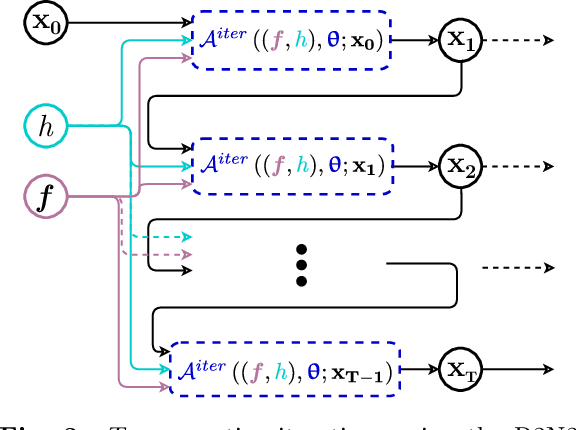
Meta-learning of numerical algorithms for a given task consist of the data-driven identification and adaptation of an algorithmic structure and the associated hyperparameters. To limit the complexity of the meta-learning problem, neural architectures with a certain inductive bias towards favorable algorithmic structures can, and should, be used. We generalize our previously introduced Runge-Kutta neural network to a recursively recurrent neural network (R2N2) superstructure for the design of customized iterative algorithms. In contrast to off-the-shelf deep learning approaches, it features a distinct division into modules for generation of information and for the subsequent assembly of this information towards a solution. Local information in the form of a subspace is generated by subordinate, inner, iterations of recurrent function evaluations starting at the current outer iterate. The update to the next outer iterate is computed as a linear combination of these evaluations, reducing the residual in this space, and constitutes the output of the network. We demonstrate that regular training of the weight parameters inside the proposed superstructure on input/output data of various computational problem classes yields iterations similar to Krylov solvers for linear equation systems, Newton-Krylov solvers for nonlinear equation systems, and Runge-Kutta integrators for ordinary differential equations. Due to its modularity, the superstructure can be readily extended with functionalities needed to represent more general classes of iterative algorithms traditionally based on Taylor series expansions.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022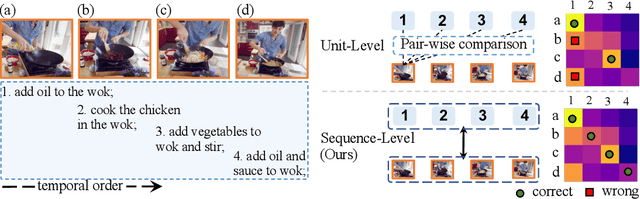
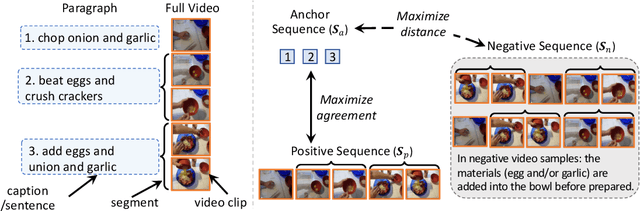
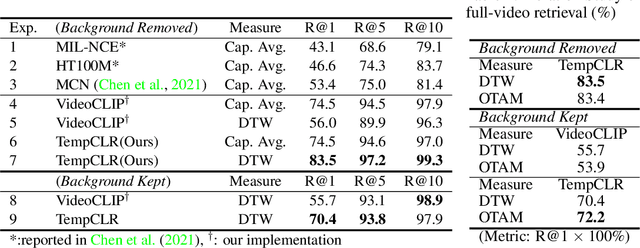
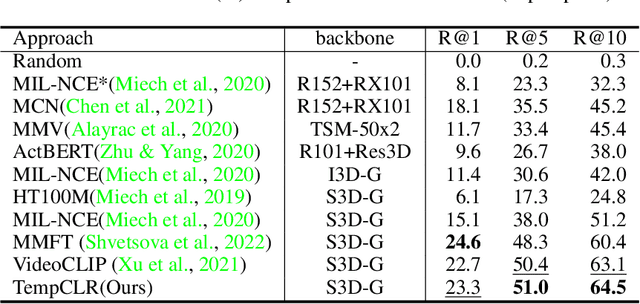
Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.