 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DINF: Dynamic Instance Noise Filter for Occluded Pedestrian Detection
Jan 13, 2023

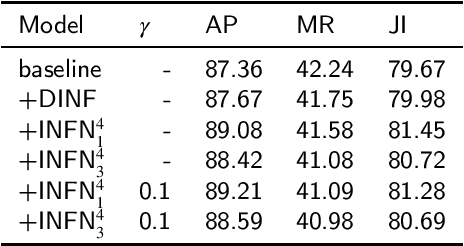
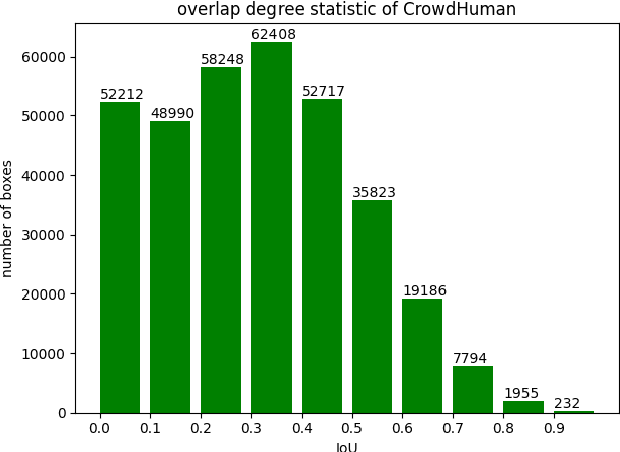
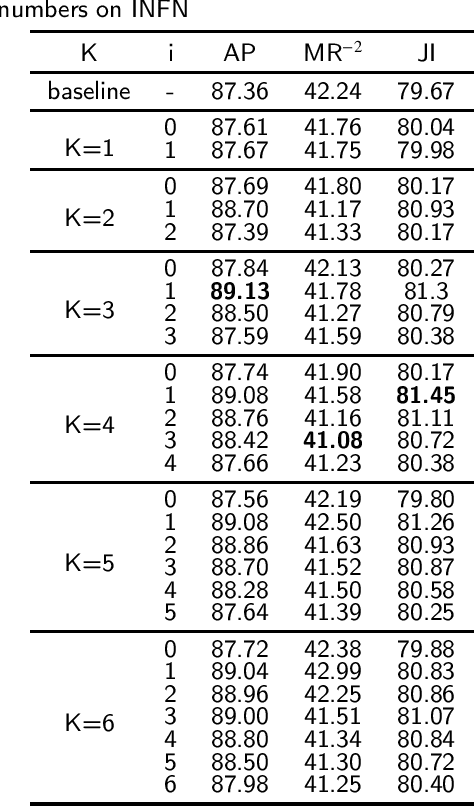
Occlusion issue is the biggest challenge in pedestrian detection. RCNN-based detectors extract instance features by cropping rectangle regions of interest in the feature maps. However, the visible pixels of the occluded objects are limited, making the rectangle instance feature mixed with a lot of instance-irrelevant noise information. Besides, by counting the number of instances with different degrees of overlap of CrowdHuman dataset, we find that the number of severely overlapping objects and the number of slightly overlapping objects are unbalanced, which may exacerbate the challenges posed by occlusion issues. Regarding to the noise issue, from the perspective of denoising, an iterable dynamic instance noise filter (DINF) is proposed for the RCNN-based pedestrian detectors to improve the signal-noise ratio of the instance feature. Simulating the wavelet denoising process, we use the instance feature vector to generate dynamic convolutional kernels to transform the RoIs features to a domain in which the near-zero values represent the noise information. Then, soft thresholding with channel-wise adaptive thresholds is applied to convert the near-zero values to zero to filter out noise information. For the imbalance issue, we propose an IoU-Focal factor (IFF) to modulate the contributions of the well-regressed boxes and the bad-regressed boxes to the loss in the training process, paying more attention to the minority severely overlapping objects. Extensive experiments conducted on CrowdHuman and CityPersons demonstrate that our methods can help RCNN-based pedestrian detectors achieve state-of-the-art performance.
Modeling Non-deterministic Human Behaviors in Discrete Food Choices
Jan 23, 2023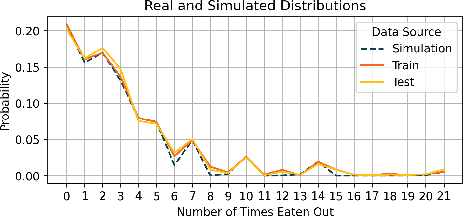
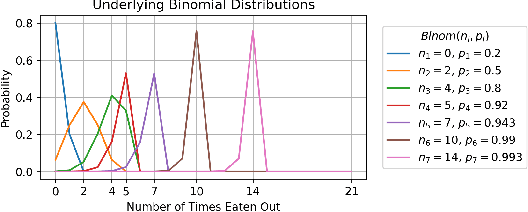
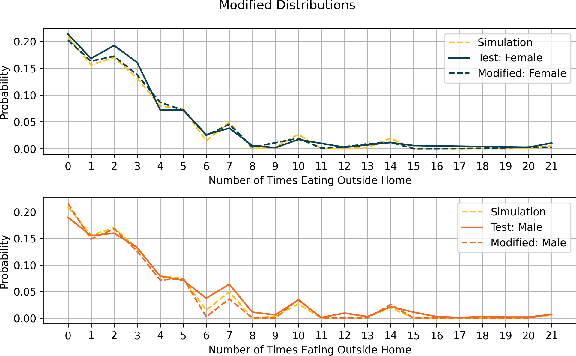
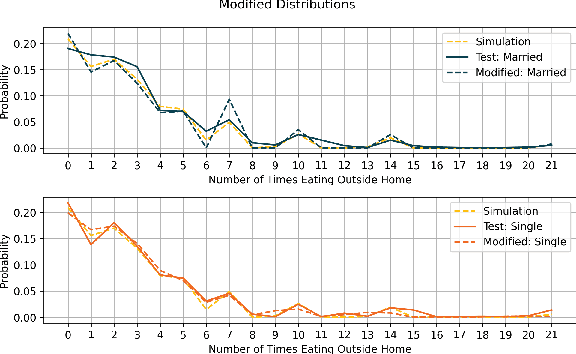
We establish a non-deterministic model that predicts a user's food preferences from their demographic information. Our simulator is based on NHANES dataset and domain expert knowledge in the form of established behavioral studies. Our model can be used to generate an arbitrary amount of synthetic datapoints that are similar in distribution to the original dataset and align with behavioral science expectations. Such a simulator can be used in a variety of machine learning tasks and especially in applications requiring human behavior prediction.
Average Communication Rate for Event-Triggered Stochastic Control Systems
Jan 13, 2023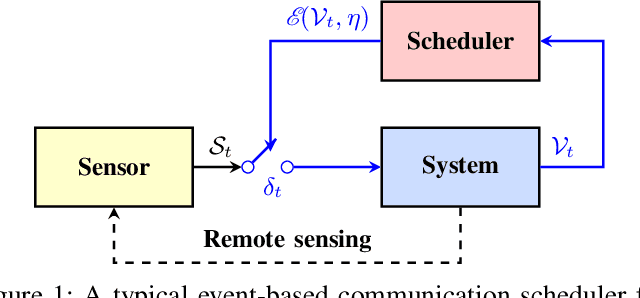
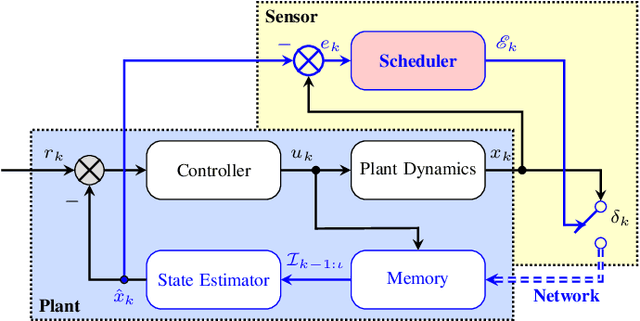
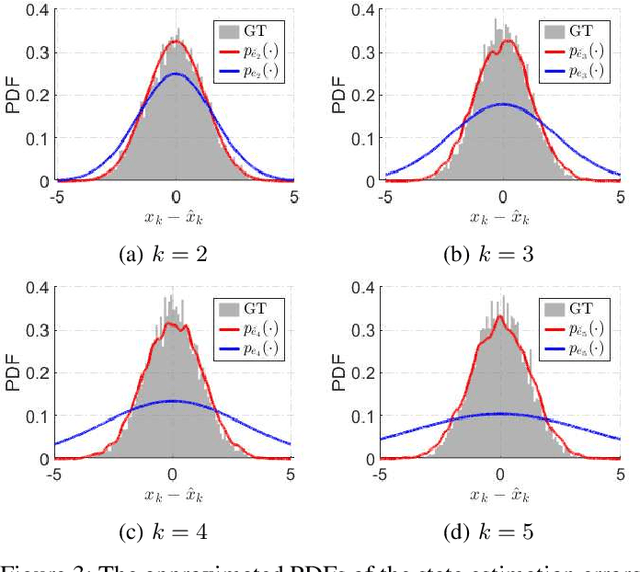
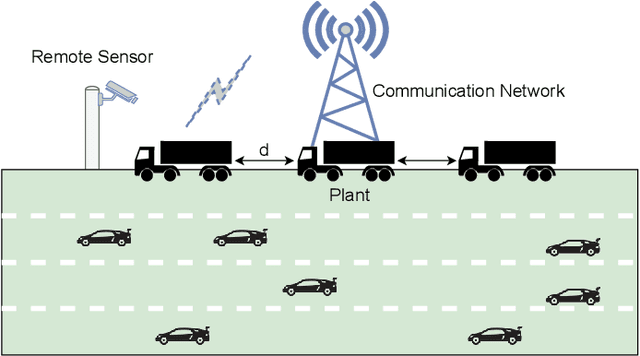
Quantification of the triggering rates of an event-triggered stochastic system with deterministic thresholds is a challenging problem due to the non-stationary nature of the system's stochastic processes. A typical example is the computation of the average communication rate (ACR) of the networked event-triggered stochastic control systems (ET-SCS) of which the communication of the sensor network is scheduled by whether a system variable of interest exceeds predefined constant thresholds. For such a system, a closed-loop effect emerges due to the interdependence between the system variable and the trigger of communication. This effect, commonly referred to as \textit{side information} by related work, distorts the stochastic distribution of the system variables and makes the ACR computation non-trivial. Previous work in this area used to over-simplify the computation by ignoring the side information and misusing a Gaussian distribution, which leads to approximated results. This paper proposes both analytical and numerical approaches to predict the exact ACR for an ET-SCS using a recursive model. Furthermore, we use theoretical analysis and a numerical study to qualitatively evaluate the deviation gap of the conventional approach that ignores the side information. The accuracy of our proposed method, alongside its comparison with the simplified results of the conventional approach, is validated by experimental studies. Our work is promising to benefit the efficient resource planning of networked control systems with limited communication resources by providing accurate ACR computation.
Lexical Simplification using multi level and modular approach
Feb 03, 2023
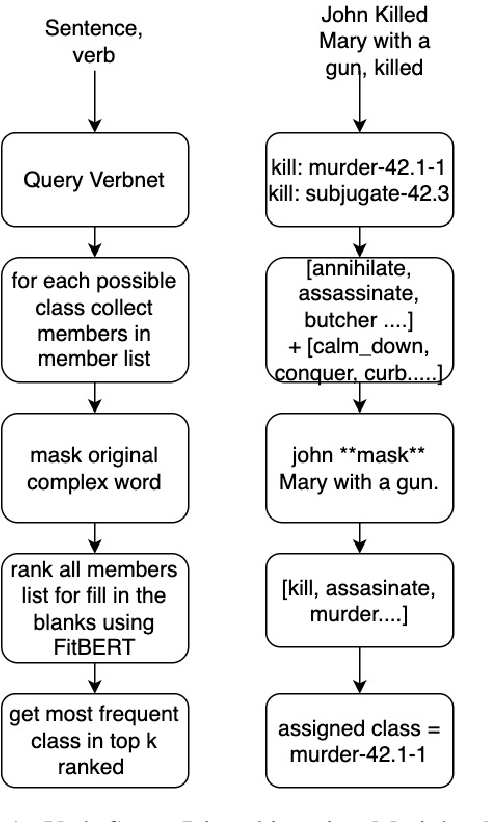

Text Simplification is an ongoing problem in Natural Language Processing, solution to which has varied implications. In conjunction with the TSAR-2022 Workshop @EMNLP2022 Lexical Simplification is the process of reducing the lexical complexity of a text by replacing difficult words with easier to read (or understand) expressions while preserving the original information and meaning. This paper explains the work done by our team "teamPN" for English sub task. We created a modular pipeline which combines modern day transformers based models with traditional NLP methods like paraphrasing and verb sense disambiguation. We created a multi level and modular pipeline where the target text is treated according to its semantics(Part of Speech Tag). Pipeline is multi level as we utilize multiple source models to find potential candidates for replacement, It is modular as we can switch the source models and their weight-age in the final re-ranking.
Semantic Feature Integration network for Fine-grained Visual Classification
Feb 13, 2023
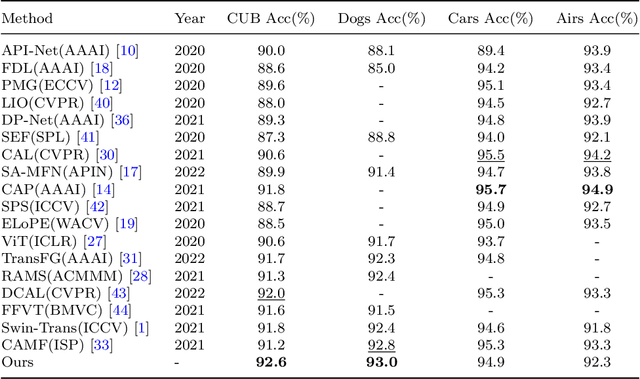
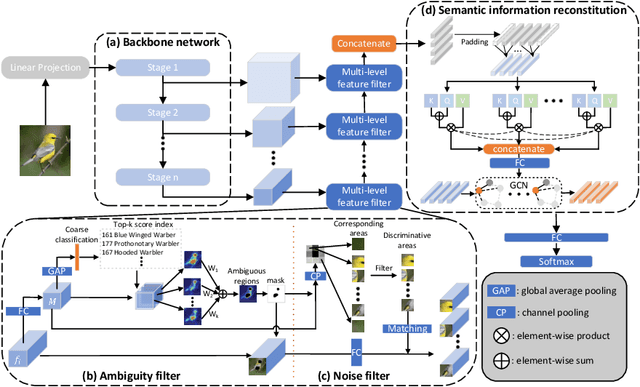
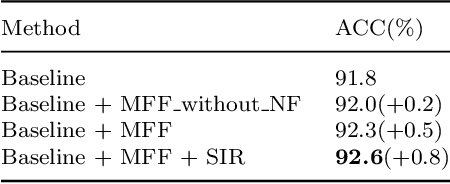
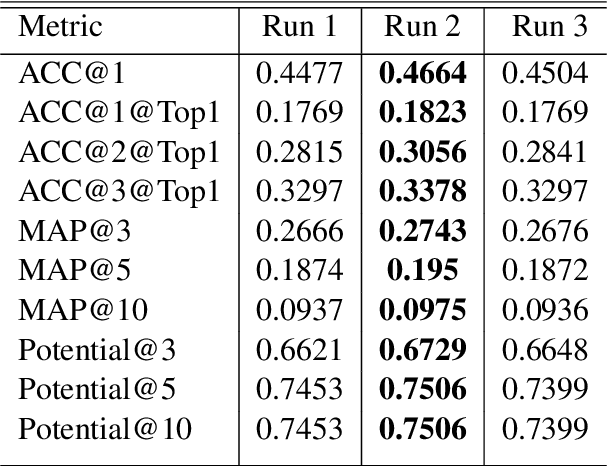
Fine-Grained Visual Classification (FGVC) is known as a challenging task due to subtle differences among subordinate categories. Many current FGVC approaches focus on identifying and locating discriminative regions by using the attention mechanism, but neglect the presence of unnecessary features that hinder the understanding of object structure. These unnecessary features, including 1) ambiguous parts resulting from the visual similarity in object appearances and 2) noninformative parts (e.g., background noise), can have a significant adverse impact on classification results. In this paper, we propose the Semantic Feature Integration network (SFI-Net) to address the above difficulties. By eliminating unnecessary features and reconstructing the semantic relations among discriminative features, our SFI-Net has achieved satisfying performance. The network consists of two modules: 1) the multi-level feature filter (MFF) module is proposed to remove unnecessary features with different receptive field, and then concatenate the preserved features on pixel level for subsequent disposal; 2) the semantic information reconstitution (SIR) module is presented to further establish semantic relations among discriminative features obtained from the MFF module. These two modules are carefully designed to be light-weighted and can be trained end-to-end in a weakly-supervised way. Extensive experiments on four challenging fine-grained benchmarks demonstrate that our proposed SFI-Net achieves the state-of-the-arts performance. Especially, the classification accuracy of our model on CUB-200-2011 and Stanford Dogs reaches 92.64% and 93.03%, respectively.
The Best of Both Worlds: Accurate Global and Personalized Models through Federated Learning with Data-Free Hyper-Knowledge Distillation
Jan 21, 2023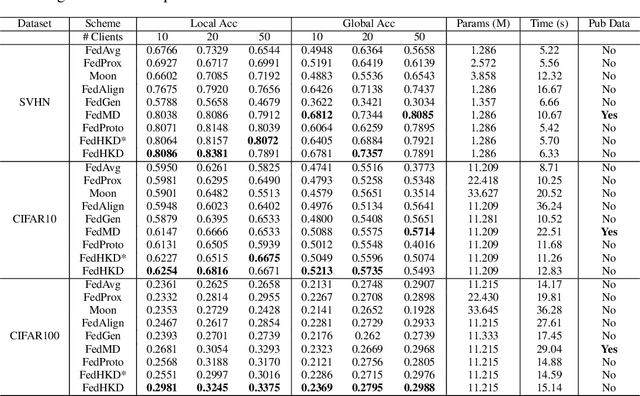
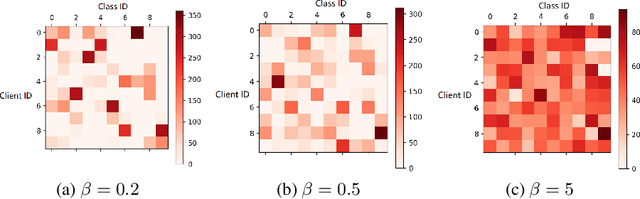
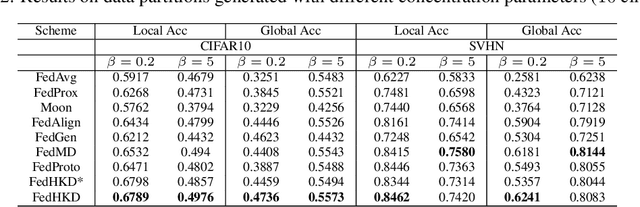
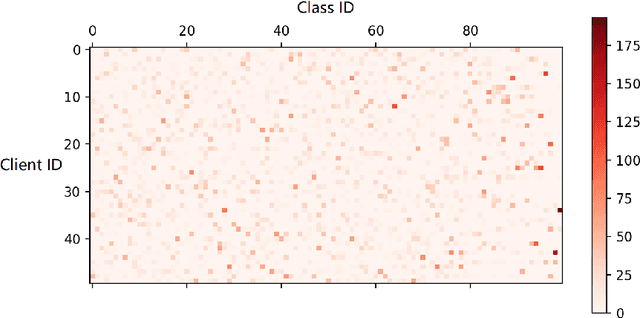
Heterogeneity of data distributed across clients limits the performance of global models trained through federated learning, especially in the settings with highly imbalanced class distributions of local datasets. In recent years, personalized federated learning (pFL) has emerged as a potential solution to the challenges presented by heterogeneous data. However, existing pFL methods typically enhance performance of local models at the expense of the global model's accuracy. We propose FedHKD (Federated Hyper-Knowledge Distillation), a novel FL algorithm in which clients rely on knowledge distillation (KD) to train local models. In particular, each client extracts and sends to the server the means of local data representations and the corresponding soft predictions -- information that we refer to as ``hyper-knowledge". The server aggregates this information and broadcasts it to the clients in support of local training. Notably, unlike other KD-based pFL methods, FedHKD does not rely on a public dataset nor it deploys a generative model at the server. We analyze convergence of FedHKD and conduct extensive experiments on visual datasets in a variety of scenarios, demonstrating that FedHKD provides significant improvement in both personalized as well as global model performance compared to state-of-the-art FL methods designed for heterogeneous data settings.
Monitoring Shortcut Learning using Mutual Information
Jun 27, 2022
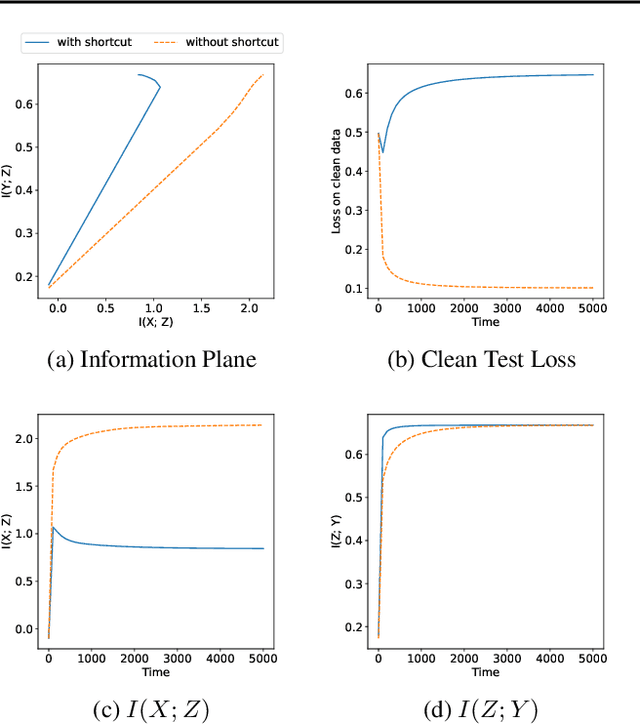
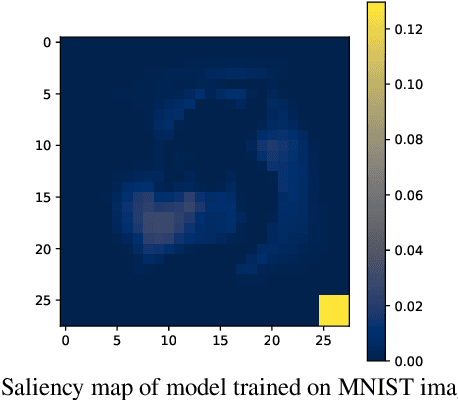
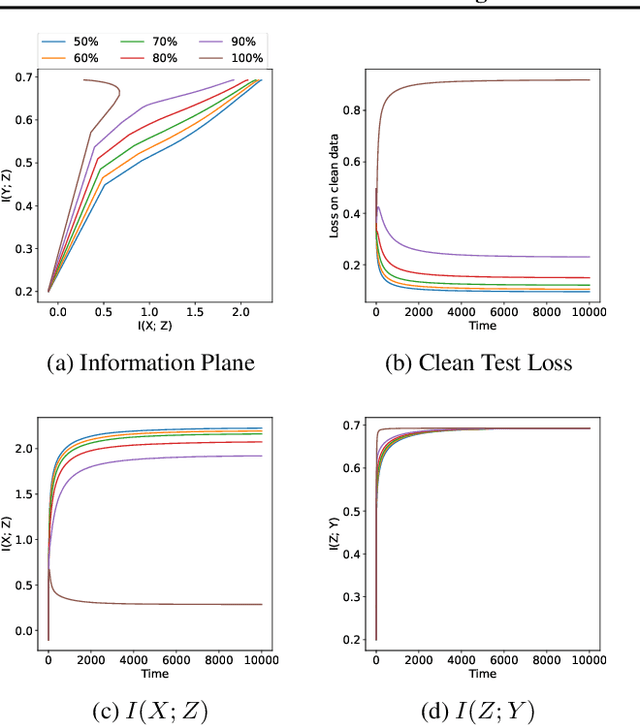
The failure of deep neural networks to generalize to out-of-distribution data is a well-known problem and raises concerns about the deployment of trained networks in safety-critical domains such as healthcare, finance and autonomous vehicles. We study a particular kind of distribution shift $\unicode{x2013}$ shortcuts or spurious correlations in the training data. Shortcut learning is often only exposed when models are evaluated on real-world data that does not contain the same spurious correlations, posing a serious dilemma for AI practitioners to properly assess the effectiveness of a trained model for real-world applications. In this work, we propose to use the mutual information (MI) between the learned representation and the input as a metric to find where in training, the network latches onto shortcuts. Experiments demonstrate that MI can be used as a domain-agnostic metric for monitoring shortcut learning.
Efficient Adversarial Contrastive Learning via Robustness-Aware Coreset Selection
Feb 08, 2023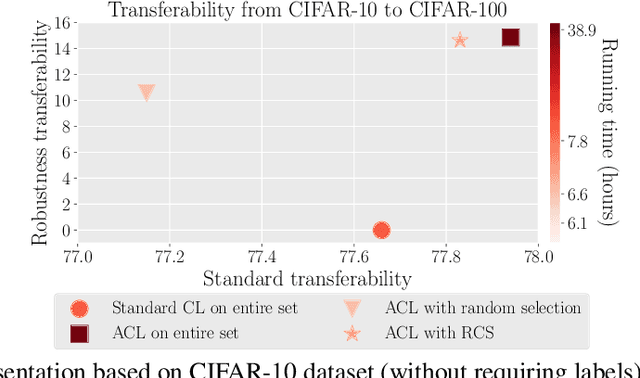

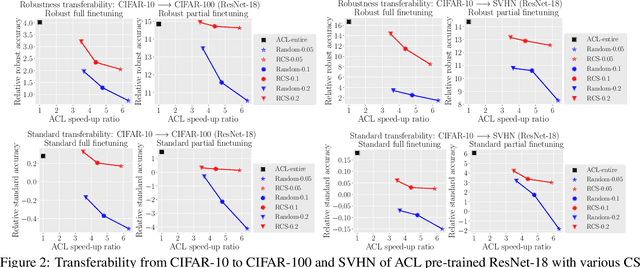

Adversarial contrastive learning (ACL) does not require expensive data annotations but outputs a robust representation that withstands adversarial attacks and also generalizes to a wide range of downstream tasks. However, ACL needs tremendous running time to generate the adversarial variants of all training data, which limits its scalability to large datasets. To speed up ACL, this paper proposes a robustness-aware coreset selection (RCS) method. RCS does not require label information and searches for an informative subset that minimizes a representational divergence, which is the distance of the representation between natural data and their virtual adversarial variants. The vanilla solution of RCS via traversing all possible subsets is computationally prohibitive. Therefore, we theoretically transform RCS into a surrogate problem of submodular maximization, of which the greedy search is an efficient solution with an optimality guarantee for the original problem. Empirically, our comprehensive results corroborate that RCS can speed up ACL by a large margin without significantly hurting the robustness and standard transferability. Notably, to the best of our knowledge, we are the first to conduct ACL efficiently on the large-scale ImageNet-1K dataset to obtain an effective robust representation via RCS.
STAIR: Learning Sparse Text and Image Representation in Grounded Tokens
Feb 08, 2023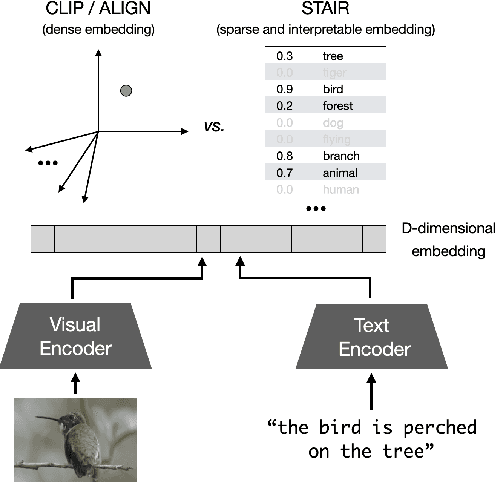

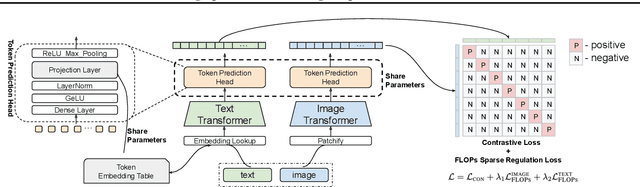

Image and text retrieval is one of the foundational tasks in the vision and language domain with multiple real-world applications. State-of-the-art approaches, e.g. CLIP, ALIGN, represent images and texts as dense embeddings and calculate the similarity in the dense embedding space as the matching score. On the other hand, sparse semantic features like bag-of-words models are more interpretable, but believed to suffer from inferior accuracy than dense representations. In this work, we show that it is possible to build a sparse semantic representation that is as powerful as, or even better than, dense presentations. We extend the CLIP model and build a sparse text and image representation (STAIR), where the image and text are mapped to a sparse token space. Each token in the space is a (sub-)word in the vocabulary, which is not only interpretable but also easy to integrate with existing information retrieval systems. STAIR model significantly outperforms a CLIP model with +$4.9\%$ and +$4.3\%$ absolute Recall@1 improvement on COCO-5k text$\rightarrow$image and image$\rightarrow$text retrieval respectively. It also achieved better performance on both of ImageNet zero-shot and linear probing compared to CLIP.
HeroNet: A Hybrid Retrieval-Generation Network for Conversational Bots
Feb 08, 2023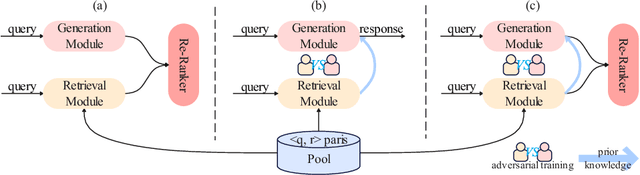

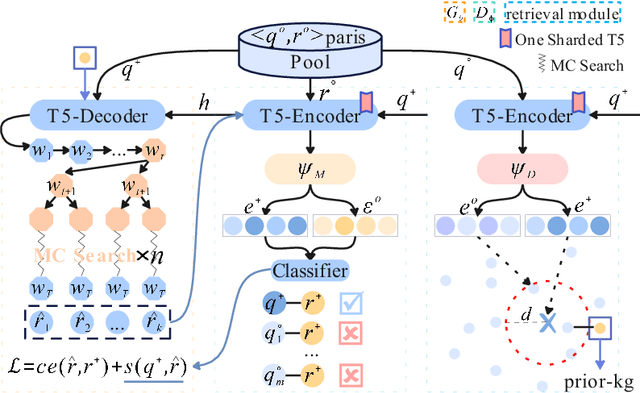
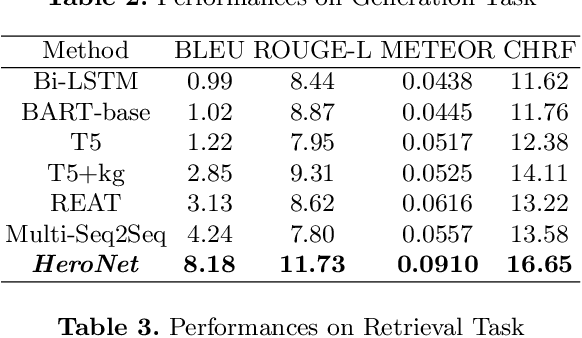
Using natural language, Conversational Bot offers unprecedented ways to many challenges in areas such as information searching, item recommendation, and question answering. Existing bots are usually developed through retrieval-based or generative-based approaches, yet both of them have their own advantages and disadvantages. To assemble this two approaches, we propose a hybrid retrieval-generation network (HeroNet) with the three-fold ideas: 1). To produce high-quality sentence representations, HeroNet performs multi-task learning on two subtasks: Similar Queries Discovery and Query-Response Matching. Specifically, the retrieval performance is improved while the model size is reduced by training two lightweight, task-specific adapter modules that share only one underlying T5-Encoder model. 2). By introducing adversarial training, HeroNet is able to solve both retrieval\&generation tasks simultaneously while maximizing performance of each other. 3). The retrieval results are used as prior knowledge to improve the generation performance while the generative result are scored by the discriminator and their scores are integrated into the generator's cross-entropy loss function. The experimental results on a open dataset demonstrate the effectiveness of the HeroNet and our code is available at https://github.com/TempHero/HeroNet.git