 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Approach to Constrained Machine Learning: A Case Study on Conway's Game of Life
Aug 23, 2024This paper focuses on a data-centric approach to machine learning applications in the context of Conway's Game of Life. Specifically, we consider the task of training a minimal architecture network to learn the transition rules of Game of Life for a given number of steps ahead, which is known to be challenging due to restrictions on the allowed number of trainable parameters. An extensive quantitative analysis showcases the benefits of utilizing a strategically designed training dataset, with its advantages persisting regardless of other parameters of the learning configuration, such as network initialization weights or optimization algorithm. Importantly, our findings highlight the integral role of domain expert insights in creating effective machine learning applications for constrained real-world scenarios.
An Empirical Categorization of Prompting Techniques for Large Language Models: A Practitioner's Guide
Feb 18, 2024


Due to rapid advancements in the development of Large Language Models (LLMs), programming these models with prompts has recently gained significant attention. However, the sheer number of available prompt engineering techniques creates an overwhelming landscape for practitioners looking to utilize these tools. For the most efficient and effective use of LLMs, it is important to compile a comprehensive list of prompting techniques and establish a standardized, interdisciplinary categorization framework. In this survey, we examine some of the most well-known prompting techniques from both academic and practical viewpoints and classify them into seven distinct categories. We present an overview of each category, aiming to clarify their unique contributions and showcase their practical applications in real-world examples in order to equip fellow practitioners with a structured framework for understanding and categorizing prompting techniques tailored to their specific domains. We believe that this approach will help simplify the complex landscape of prompt engineering and enable more effective utilization of LLMs in various applications. By providing practitioners with a systematic approach to prompt categorization, we aim to assist in navigating the intricacies of effective prompt design for conversational pre-trained LLMs and inspire new possibilities in their respective fields.
Increasing Entropy to Boost Policy Gradient Performance on Personalization Tasks
Oct 09, 2023



In this effort, we consider the impact of regularization on the diversity of actions taken by policies generated from reinforcement learning agents trained using a policy gradient. Policy gradient agents are prone to entropy collapse, which means certain actions are seldomly, if ever, selected. We augment the optimization objective function for the policy with terms constructed from various $\varphi$-divergences and Maximum Mean Discrepancy which encourages current policies to follow different state visitation and/or action choice distribution than previously computed policies. We provide numerical experiments using MNIST, CIFAR10, and Spotify datasets. The results demonstrate the advantage of diversity-promoting policy regularization and that its use on gradient-based approaches have significantly improved performance on a variety of personalization tasks. Furthermore, numerical evidence is given to show that policy regularization increases performance without losing accuracy.
Zero-Shot Recommendations with Pre-Trained Large Language Models for Multimodal Nudging
Sep 02, 2023



We present a method for zero-shot recommendation of multimodal non-stationary content that leverages recent advancements in the field of generative AI. We propose rendering inputs of different modalities as textual descriptions and to utilize pre-trained LLMs to obtain their numerical representations by computing semantic embeddings. Once unified representations of all content items are obtained, the recommendation can be performed by computing an appropriate similarity metric between them without any additional learning. We demonstrate our approach on a synthetic multimodal nudging environment, where the inputs consist of tabular, textual, and visual data.
Modeling Non-deterministic Human Behaviors in Discrete Food Choices
Jan 23, 2023We establish a non-deterministic model that predicts a user's food preferences from their demographic information. Our simulator is based on NHANES dataset and domain expert knowledge in the form of established behavioral studies. Our model can be used to generate an arbitrary amount of synthetic datapoints that are similar in distribution to the original dataset and align with behavioral science expectations. Such a simulator can be used in a variety of machine learning tasks and especially in applications requiring human behavior prediction.
Examining Policy Entropy of Reinforcement Learning Agents for Personalization Tasks
Nov 21, 2022



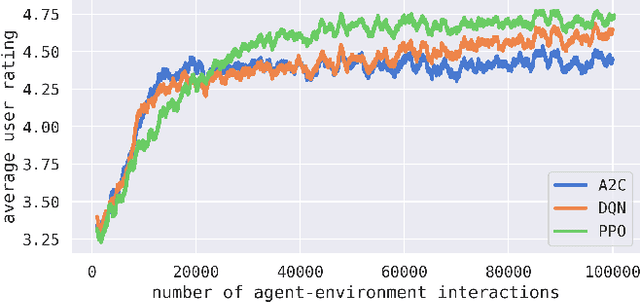
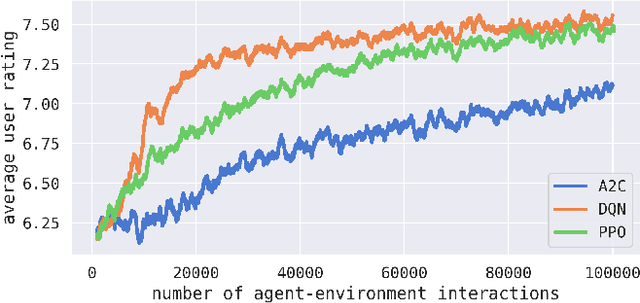
This effort is focused on examining the behavior of reinforcement learning systems in personalization environments and detailing the differences in policy entropy associated with the type of learning algorithm utilized. We demonstrate that Policy Optimization agents often possess low-entropy policies during training, which in practice results in agents prioritizing certain actions and avoiding others. Conversely, we also show that Q-Learning agents are far less susceptible to such behavior and generally maintain high-entropy policies throughout training, which is often preferable in real-world applications. We provide a wide range of numerical experiments as well as theoretical justification to show that these differences in entropy are due to the type of learning being employed.
Simulated Contextual Bandits for Personalization Tasks from Recommendation Datasets
Oct 12, 2022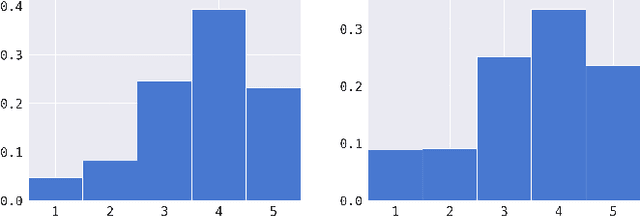
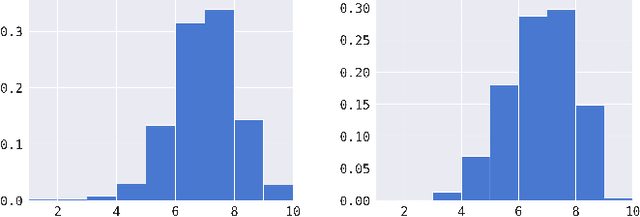
We propose a method for generating simulated contextual bandit environments for personalization tasks from recommendation datasets like MovieLens, Netflix, Last.fm, Million Song, etc. This allows for personalization environments to be developed based on real-life data to reflect the nuanced nature of real-world user interactions. The obtained environments can be used to develop methods for solving personalization tasks, algorithm benchmarking, model simulation, and more. We demonstrate our approach with numerical examples on MovieLens and IMDb datasets.
On the Unreasonable Efficiency of State Space Clustering in Personalization Tasks
Dec 24, 2021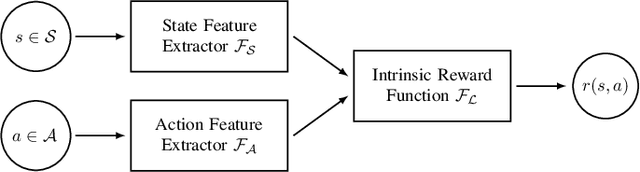
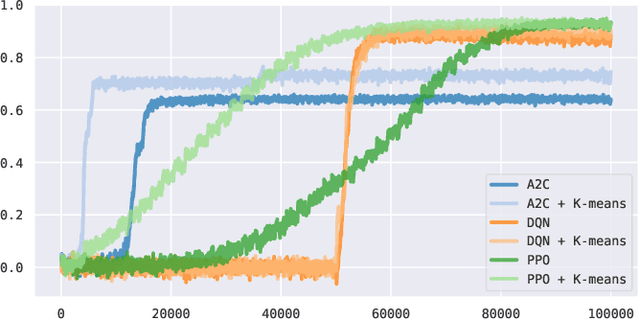
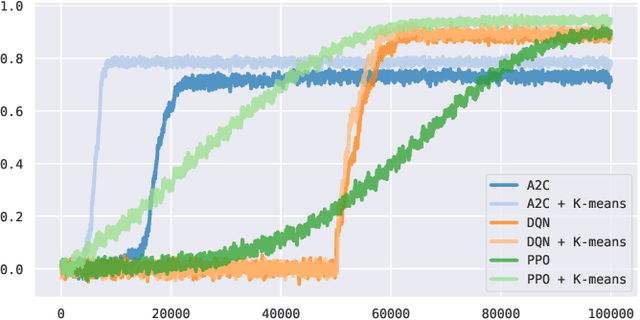
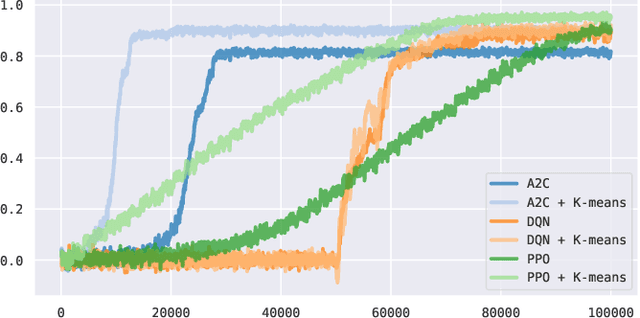
In this effort we consider a reinforcement learning (RL) technique for solving personalization tasks with complex reward signals. In particular, our approach is based on state space clustering with the use of a simplistic $k$-means algorithm as well as conventional choices of the network architectures and optimization algorithms. Numerical examples demonstrate the efficiency of different RL procedures and are used to illustrate that this technique accelerates the agent's ability to learn and does not restrict the agent's performance.
Offline Policy Comparison under Limited Historical Agent-Environment Interactions
Jun 07, 2021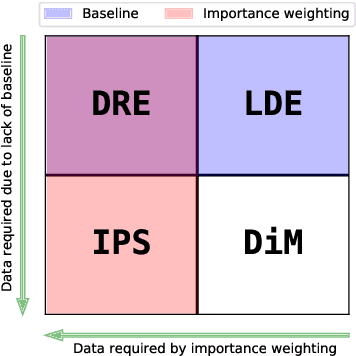
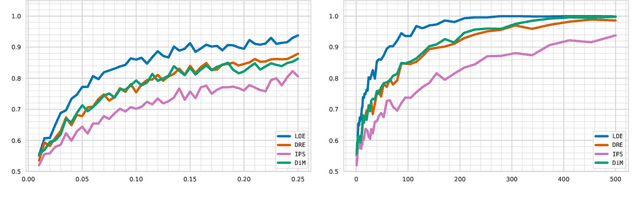
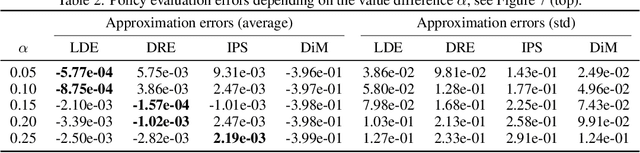
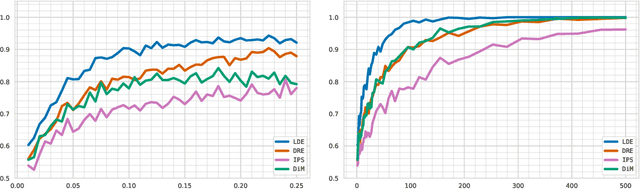
We address the challenge of policy evaluation in real-world applications of reinforcement learning systems where the available historical data is limited due to ethical, practical, or security considerations. This constrained distribution of data samples often leads to biased policy evaluation estimates. To remedy this, we propose that instead of policy evaluation, one should perform policy comparison, i.e. to rank the policies of interest in terms of their value based on available historical data. In addition we present the Limited Data Estimator (LDE) as a simple method for evaluating and comparing policies from a small number of interactions with the environment. According to our theoretical analysis, the LDE is shown to be statistically reliable on policy comparison tasks under mild assumptions on the distribution of the historical data. Additionally, our numerical experiments compare the LDE to other policy evaluation methods on the task of policy ranking and demonstrate its advantage in various settings.
An adaptive stochastic gradient-free approach for high-dimensional blackbox optimization
Jun 18, 2020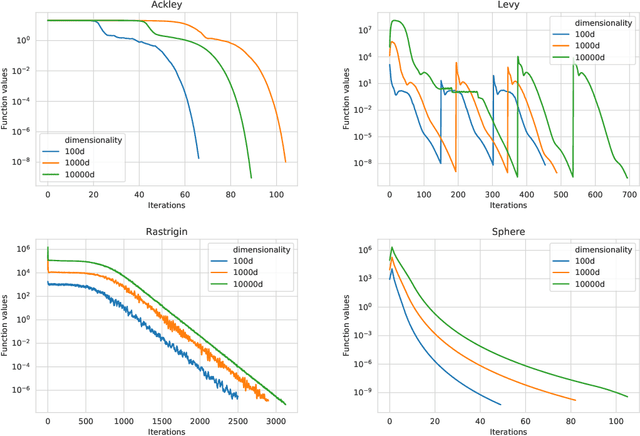
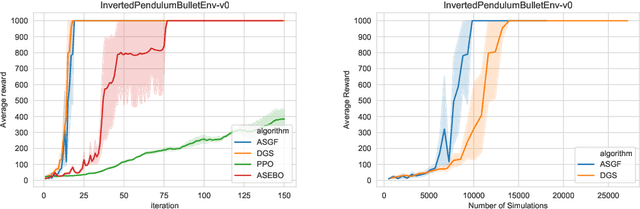
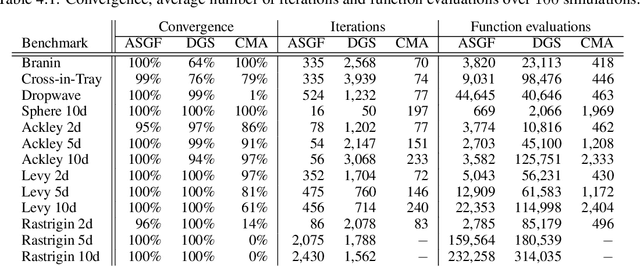
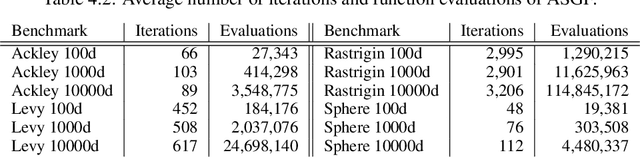
In this work, we propose a novel adaptive stochastic gradient-free (ASGF) approach for solving high-dimensional nonconvex optimization problems based on function evaluations. We employ a directional Gaussian smoothing of the target function that generates a surrogate of the gradient and assists in avoiding bad local optima by utilizing nonlocal information of the loss landscape. Applying a deterministic quadrature scheme results in a massively scalable technique that is sample-efficient and achieves spectral accuracy. At each step we randomly generate the search directions while primarily following the surrogate of the smoothed gradient. This enables exploitation of the gradient direction while maintaining sufficient space exploration, and accelerates convergence towards the global extrema. In addition, we make use of a local approximation of the Lipschitz constant in order to adaptively adjust the values of all hyperparameters, thus removing the careful fine-tuning of current algorithms that is often necessary to be successful when applied to a large class of learning tasks. As such, the ASGF strategy offers significant improvements when solving high-dimensional nonconvex optimization problems when compared to other gradient-free methods (including the so called "evolutionary strategies") as well as iterative approaches that rely on the gradient information of the objective function. We illustrate the improved performance of this method by providing several comparative numerical studies on benchmark global optimization problems and reinforcement learning tasks.