 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding generalization error with input compression: An empirical study with infinite-width networks
Jul 19, 2022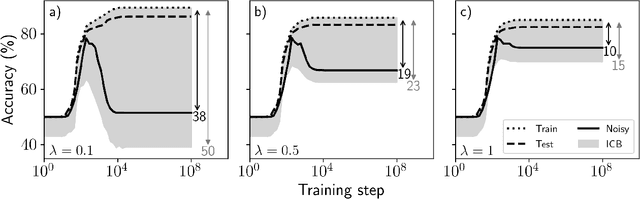

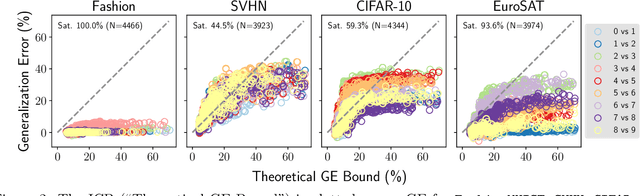
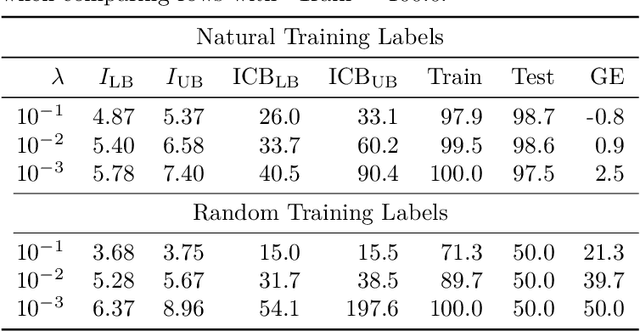
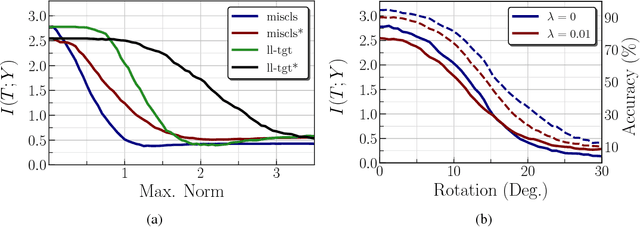
Estimating the Generalization Error (GE) of Deep Neural Networks (DNNs) is an important task that often relies on availability of held-out data. The ability to better predict GE based on a single training set may yield overarching DNN design principles to reduce a reliance on trial-and-error, along with other performance assessment advantages. In search of a quantity relevant to GE, we investigate the Mutual Information (MI) between the input and final layer representations, using the infinite-width DNN limit to bound MI. An existing input compression-based GE bound is used to link MI and GE. To the best of our knowledge, this represents the first empirical study of this bound. In our attempt to empirically falsify the theoretical bound, we find that it is often tight for best-performing models. Furthermore, it detects randomization of training labels in many cases, reflects test-time perturbation robustness, and works well given only few training samples. These results are promising given that input compression is broadly applicable where MI can be estimated with confidence.
Monitoring Shortcut Learning using Mutual Information
Jun 27, 2022
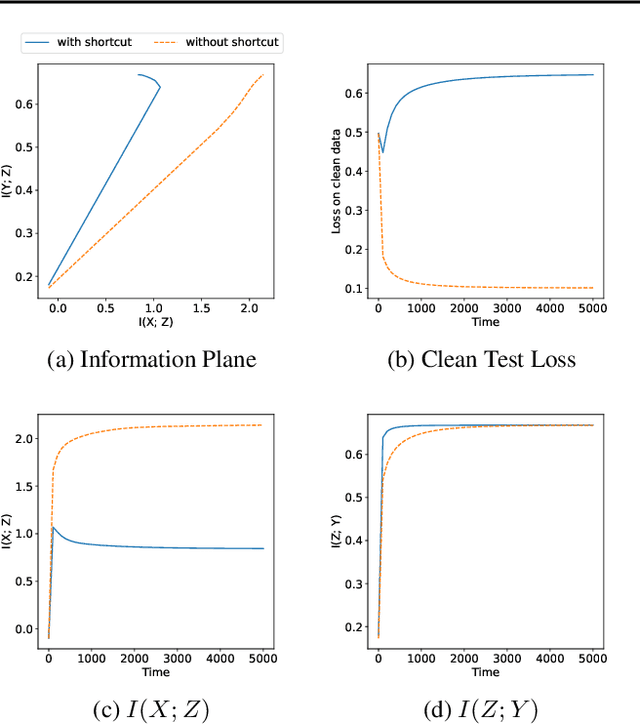
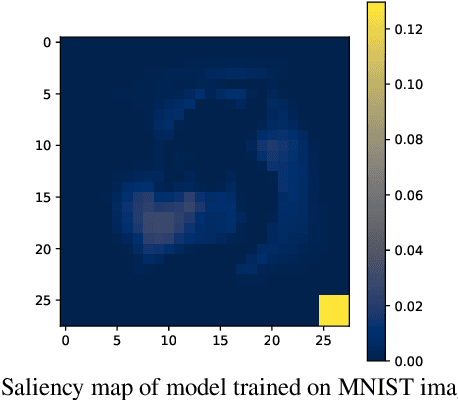
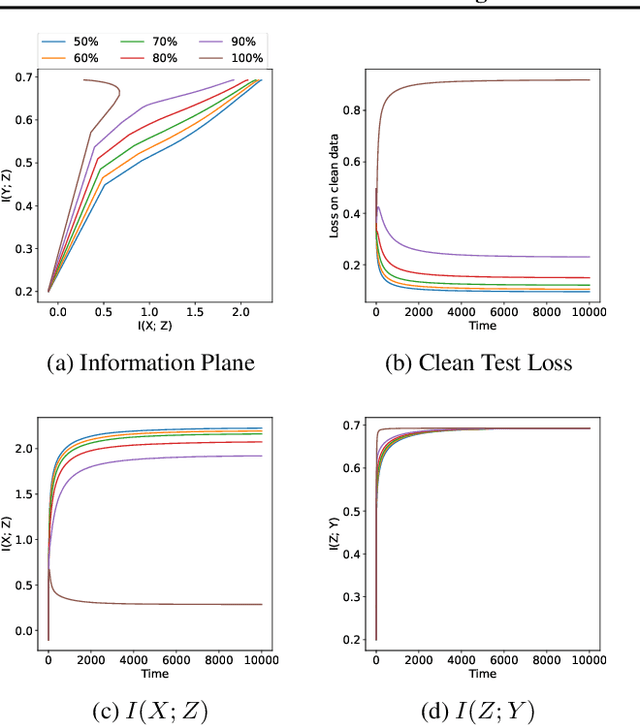
The failure of deep neural networks to generalize to out-of-distribution data is a well-known problem and raises concerns about the deployment of trained networks in safety-critical domains such as healthcare, finance and autonomous vehicles. We study a particular kind of distribution shift $\unicode{x2013}$ shortcuts or spurious correlations in the training data. Shortcut learning is often only exposed when models are evaluated on real-world data that does not contain the same spurious correlations, posing a serious dilemma for AI practitioners to properly assess the effectiveness of a trained model for real-world applications. In this work, we propose to use the mutual information (MI) between the learned representation and the input as a metric to find where in training, the network latches onto shortcuts. Experiments demonstrate that MI can be used as a domain-agnostic metric for monitoring shortcut learning.
Batch Normalization is a Cause of Adversarial Vulnerability
May 29, 2019

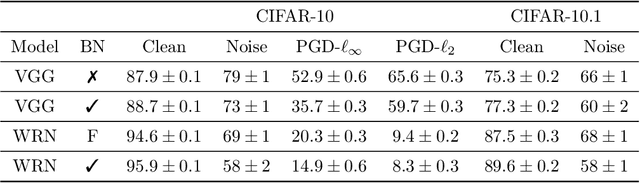
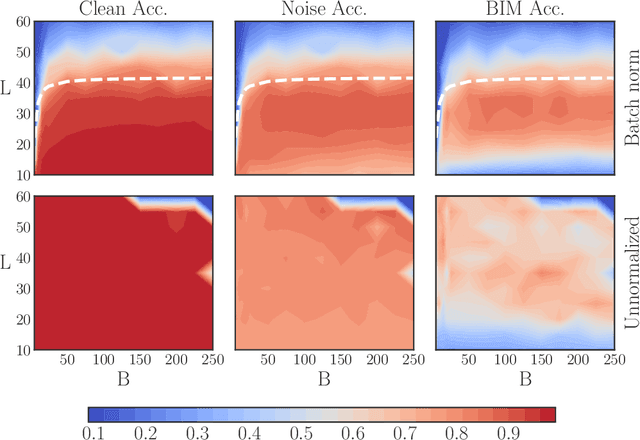
Batch normalization (batch norm) is often used in an attempt to stabilize and accelerate training in deep neural networks. In many cases it indeed decreases the number of parameter updates required to achieve low training error. However, it also reduces robustness to small adversarial input perturbations and noise by double-digit percentages, as we show on five standard datasets. Furthermore, substituting weight decay for batch norm is sufficient to nullify the relationship between adversarial vulnerability and the input dimension. Our work is consistent with a mean-field analysis that found that batch norm causes exploding gradients.
Adversarial Examples as an Input-Fault Tolerance Problem
Nov 30, 2018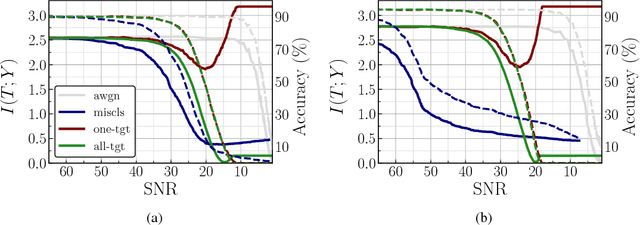
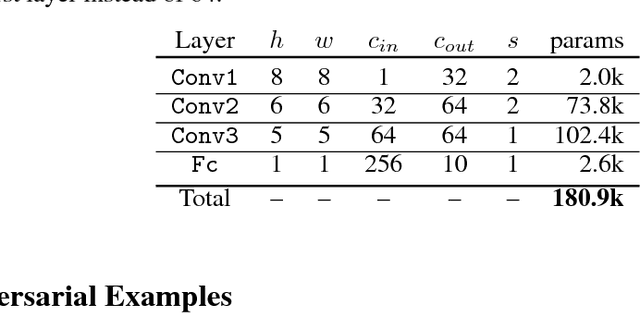

We analyze the adversarial examples problem in terms of a model's fault tolerance with respect to its input. Whereas previous work focuses on arbitrarily strict threat models, i.e., $\epsilon$-perturbations, we consider arbitrary valid inputs and propose an information-based characteristic for evaluating tolerance to diverse input faults.
Adversarial Training Versus Weight Decay
Jul 23, 2018



Performance-critical machine learning models should be robust to input perturbations not seen during training. Adversarial training is a method for improving a model's robustness to some perturbations by including them in the training process, but this tends to exacerbate other vulnerabilities of the model. The adversarial training framework has the effect of translating the data with respect to the cost function, while weight decay has a scaling effect. Although weight decay could be considered a crude regularization technique, it appears superior to adversarial training as it remains stable over a broader range of regimes and reduces all generalization errors. Equipped with these abstractions, we provide key baseline results and methodology for characterizing robustness. The two approaches can be combined to yield one small model that demonstrates good robustness to several white-box attacks associated with different metrics.
Predicting Adversarial Examples with High Confidence
Feb 13, 2018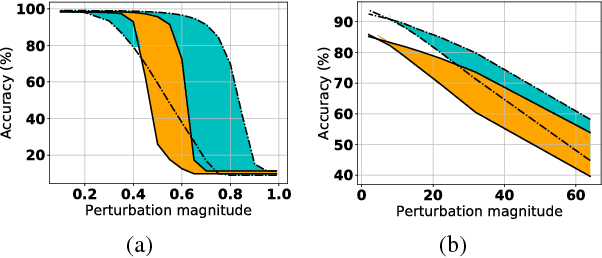

It has been suggested that adversarial examples cause deep learning models to make incorrect predictions with high confidence. In this work, we take the opposite stance: an overly confident model is more likely to be vulnerable to adversarial examples. This work is one of the most proactive approaches taken to date, as we link robustness with non-calibrated model confidence on noisy images, providing a data-augmentation-free path forward. The adversarial examples phenomenon is most easily explained by the trend of increasing non-regularized model capacity, while the diversity and number of samples in common datasets has remained flat. Test accuracy has incorrectly been associated with true generalization performance, ignoring that training and test splits are often extremely similar in terms of the overall representation space. The transferability property of adversarial examples was previously used as evidence against overfitting arguments, a perceived random effect, but overfitting is not always random.
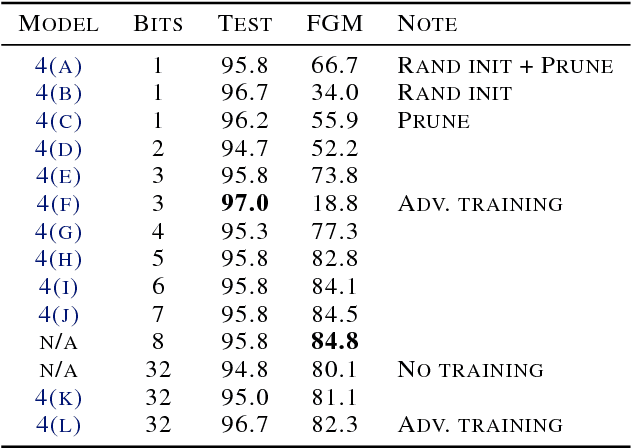
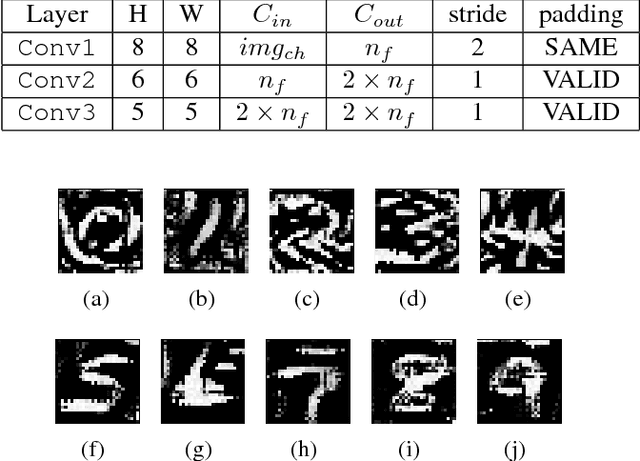
Attacking Binarized Neural Networks
Jan 31, 2018
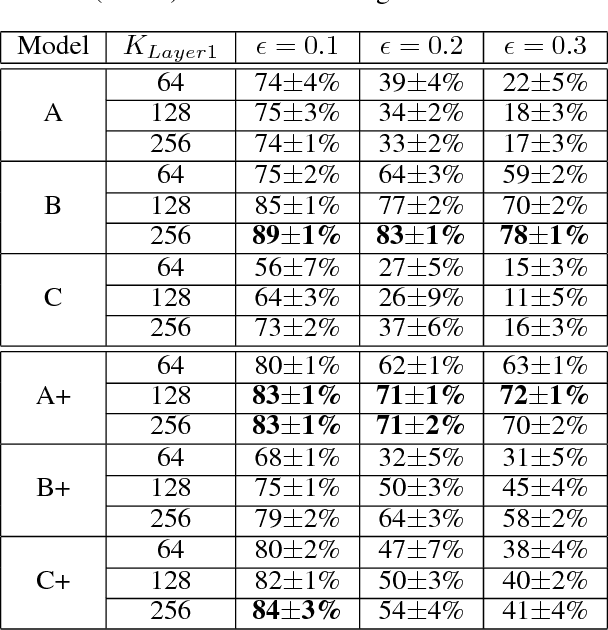
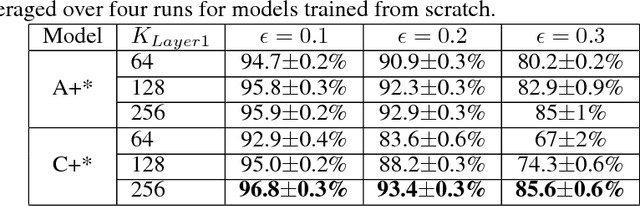
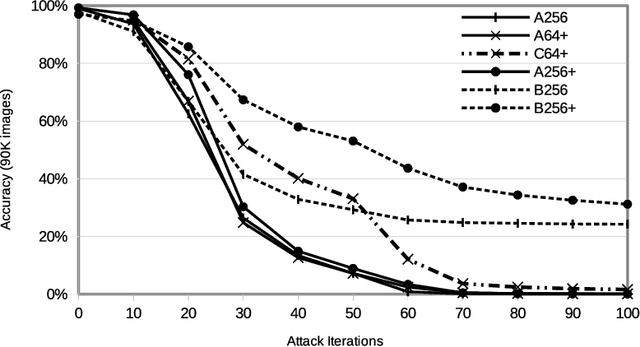
Neural networks with low-precision weights and activations offer compelling efficiency advantages over their full-precision equivalents. The two most frequently discussed benefits of quantization are reduced memory consumption, and a faster forward pass when implemented with efficient bitwise operations. We propose a third benefit of very low-precision neural networks: improved robustness against some adversarial attacks, and in the worst case, performance that is on par with full-precision models. We focus on the very low-precision case where weights and activations are both quantized to $\pm$1, and note that stochastically quantizing weights in just one layer can sharply reduce the impact of iterative attacks. We observe that non-scaled binary neural networks exhibit a similar effect to the original defensive distillation procedure that led to gradient masking, and a false notion of security. We address this by conducting both black-box and white-box experiments with binary models that do not artificially mask gradients.
The Ciona17 Dataset for Semantic Segmentation of Invasive Species in a Marine Aquaculture Environment
Feb 18, 2017
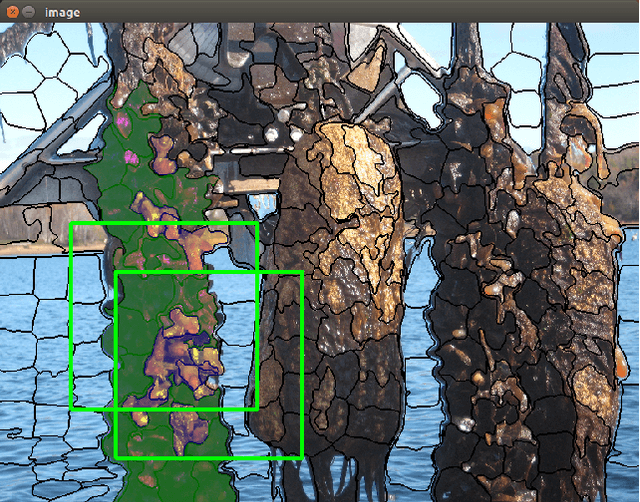


An original dataset for semantic segmentation, Ciona17, is introduced, which to the best of the authors' knowledge, is the first dataset of its kind with pixel-level annotations pertaining to invasive species in a marine environment. Diverse outdoor illumination, a range of object shapes, colour, and severe occlusion provide a significant real world challenge for the computer vision community. An accompanying ground-truthing tool for superpixel labeling, Truth and Crop, is also introduced. Finally, we provide a baseline using a variant of Fully Convolutional Networks, and report results in terms of the standard mean intersection over union (mIoU) metric.