 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CHGNet: Pretrained universal neural network potential for charge-informed atomistic modeling
Feb 28, 2023
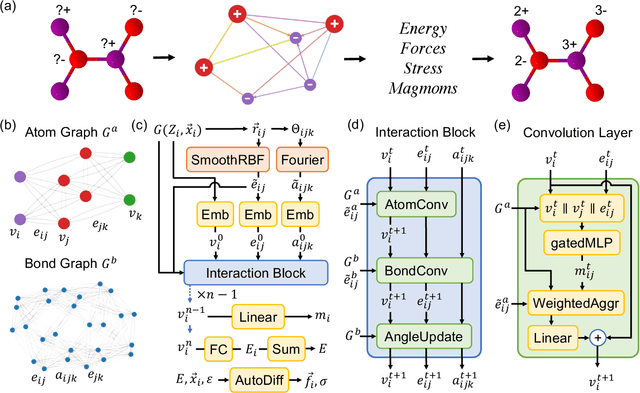
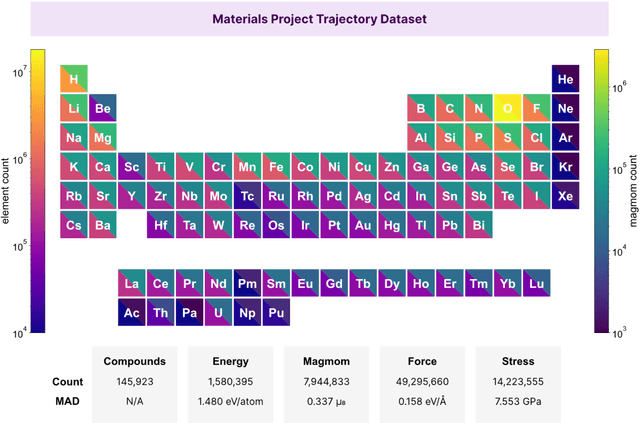
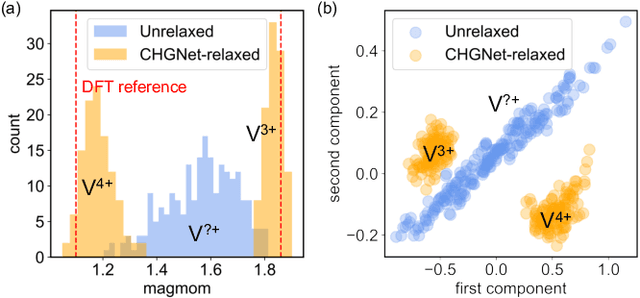
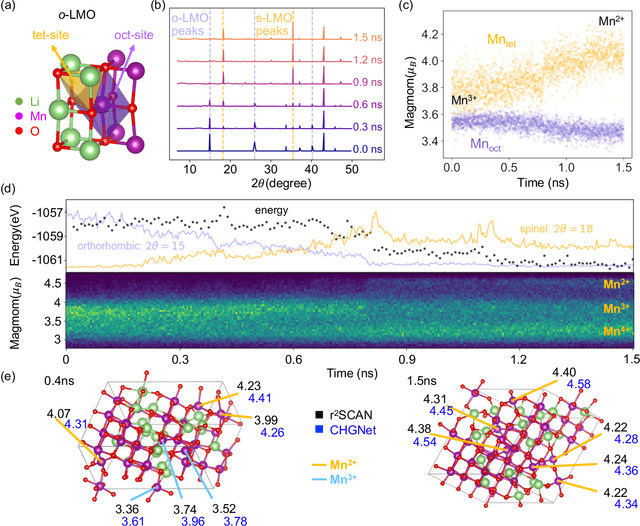
The simulation of large-scale systems with complex electron interactions remains one of the greatest challenges for the atomistic modeling of materials. Although classical force-fields often fail to describe the coupling between electronic states and ionic rearrangements, the more accurate \textit{ab-initio} molecular dynamics suffers from computational complexity that prevents long-time and large-scale simulations, which are essential to study many technologically relevant phenomena, such as reactions, ion migrations, phase transformations, and degradation. In this work, we present the Crystal Hamiltonian Graph neural Network (CHGNet) as a novel machine-learning interatomic potential (MLIP), using a graph-neural-network-based force-field to model a universal potential energy surface. CHGNet is pretrained on the energies, forces, stresses, and magnetic moments from the Materials Project Trajectory Dataset, which consists of over 10 years of density functional theory static and relaxation trajectories of $\sim 1.5$ million inorganic structures. The explicit inclusion of magnetic moments enables CHGNet to learn and accurately represent the orbital occupancy of electrons, enhancing its capability to describe both atomic and electronic degrees of freedom. We demonstrate several applications of CHGNet in solid-state materials, including charge-informed molecular dynamics in Li$_x$MnO$_2$, the finite temperature phase diagram for Li$_x$FePO$_4$ and Li diffusion in garnet conductors. We critically analyze the significance of including charge information for capturing appropriate chemistry, and we provide new insights into ionic systems with additional electronic degrees of freedom that can not be observed by previous MLIPs.
Few-shot 3D LiDAR Semantic Segmentation for Autonomous Driving
Feb 17, 2023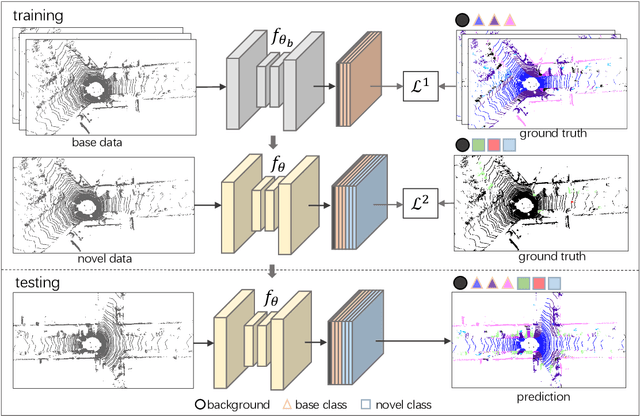
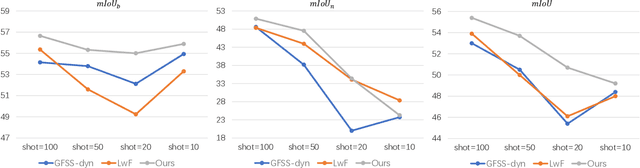
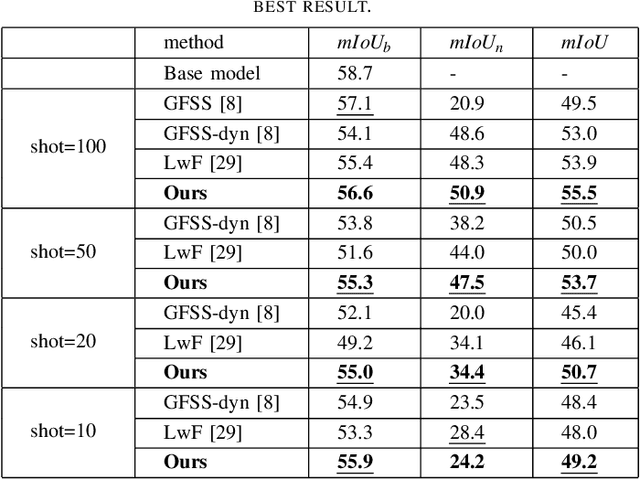
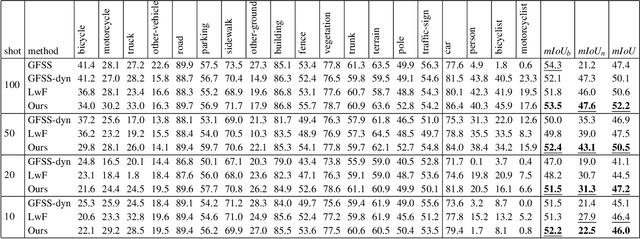
In autonomous driving, the novel objects and lack of annotations challenge the traditional 3D LiDAR semantic segmentation based on deep learning. Few-shot learning is a feasible way to solve these issues. However, currently few-shot semantic segmentation methods focus on camera data, and most of them only predict the novel classes without considering the base classes. This setting cannot be directly applied to autonomous driving due to safety concerns. Thus, we propose a few-shot 3D LiDAR semantic segmentation method that predicts both novel classes and base classes simultaneously. Our method tries to solve the background ambiguity problem in generalized few-shot semantic segmentation. We first review the original cross-entropy and knowledge distillation losses, then propose a new loss function that incorporates the background information to achieve 3D LiDAR few-shot semantic segmentation. Extensive experiments on SemanticKITTI demonstrate the effectiveness of our method.
A Novel Collaborative Self-Supervised Learning Method for Radiomic Data
Feb 20, 2023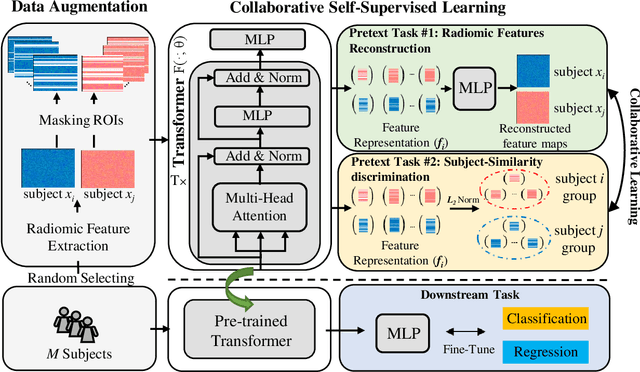
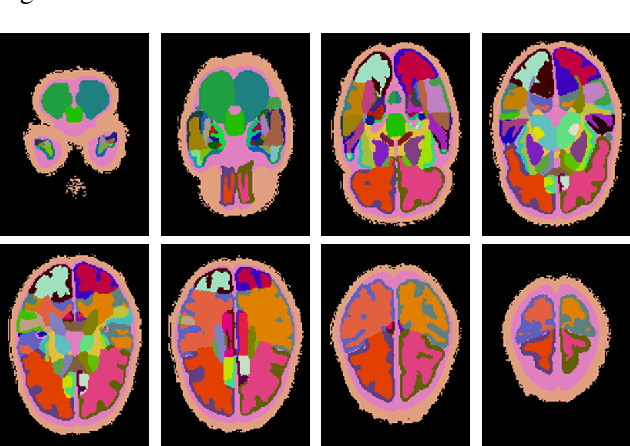
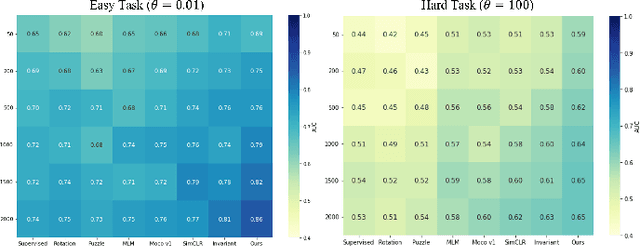
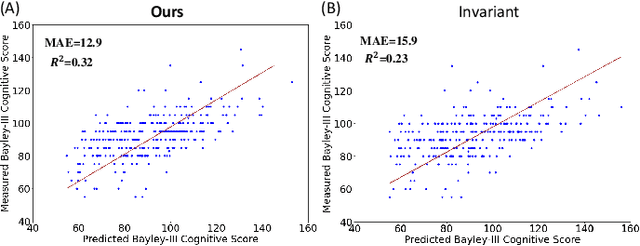
The computer-aided disease diagnosis from radiomic data is important in many medical applications. However, developing such a technique relies on annotating radiological images, which is a time-consuming, labor-intensive, and expensive process. In this work, we present the first novel collaborative self-supervised learning method to solve the challenge of insufficient labeled radiomic data, whose characteristics are different from text and image data. To achieve this, we present two collaborative pretext tasks that explore the latent pathological or biological relationships between regions of interest and the similarity and dissimilarity information between subjects. Our method collaboratively learns the robust latent feature representations from radiomic data in a self-supervised manner to reduce human annotation efforts, which benefits the disease diagnosis. We compared our proposed method with other state-of-the-art self-supervised learning methods on a simulation study and two independent datasets. Extensive experimental results demonstrated that our method outperforms other self-supervised learning methods on both classification and regression tasks. With further refinement, our method shows the potential advantage in automatic disease diagnosis with large-scale unlabeled data available.
Synergy between human and machine approaches to sound/scene recognition and processing: An overview of ICASSP special session
Feb 20, 2023Machine Listening, as usually formalized, attempts to perform a task that is, from our perspective, fundamentally human-performable, and performed by humans. Current automated models of Machine Listening vary from purely data-driven approaches to approaches imitating human systems. In recent years, the most promising approaches have been hybrid in that they have used data-driven approaches informed by models of the perceptual, cognitive, and semantic processes of the human system. Not only does the guidance provided by models of human perception and domain knowledge enable better, and more generalizable Machine Listening, in the converse, the lessons learned from these models may be used to verify or improve our models of human perception themselves. This paper summarizes advances in the development of such hybrid approaches, ranging from Machine Listening models that are informed by models of peripheral (human) auditory processes, to those that employ or derive semantic information encoded in relations between sounds. The research described herein was presented in a special session on ``Synergy between human and machine approaches to sound/scene recognition and processing'' at the 2023 ICASSP meeting.
Composer: Creative and Controllable Image Synthesis with Composable Conditions
Feb 20, 2023
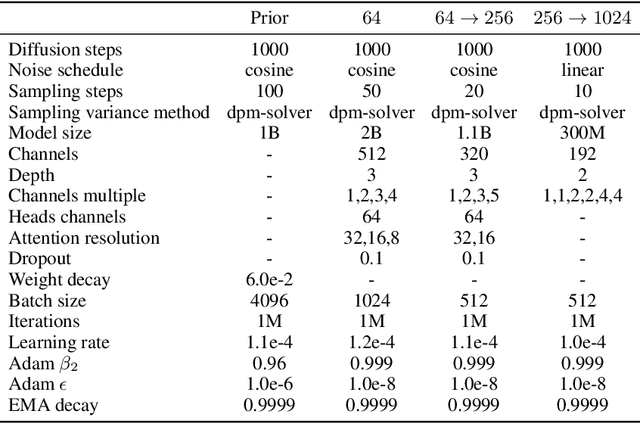


Recent large-scale generative models learned on big data are capable of synthesizing incredible images yet suffer from limited controllability. This work offers a new generation paradigm that allows flexible control of the output image, such as spatial layout and palette, while maintaining the synthesis quality and model creativity. With compositionality as the core idea, we first decompose an image into representative factors, and then train a diffusion model with all these factors as the conditions to recompose the input. At the inference stage, the rich intermediate representations work as composable elements, leading to a huge design space (i.e., exponentially proportional to the number of decomposed factors) for customizable content creation. It is noteworthy that our approach, which we call Composer, supports various levels of conditions, such as text description as the global information, depth map and sketch as the local guidance, color histogram for low-level details, etc. Besides improving controllability, we confirm that Composer serves as a general framework and facilitates a wide range of classical generative tasks without retraining. Code and models will be made available.
On the Metrics for Evaluating Monocular Depth Estimation
Feb 20, 2023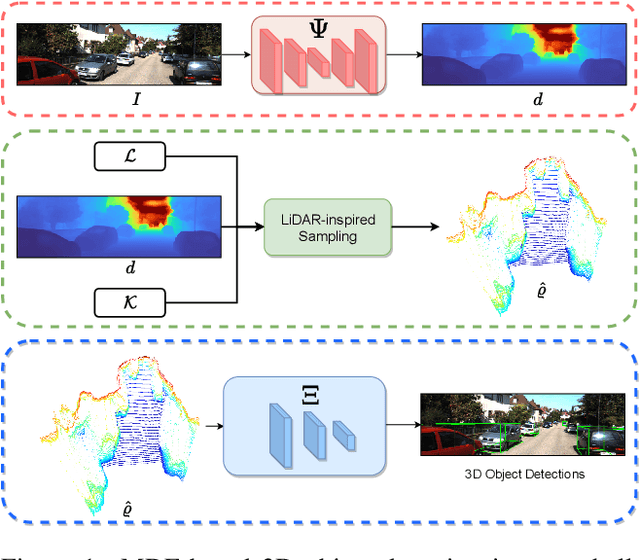

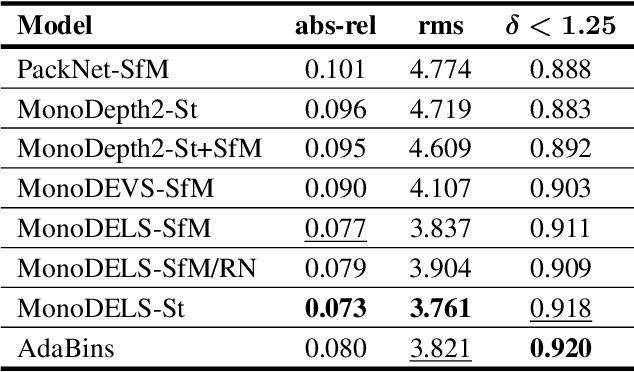
Monocular Depth Estimation (MDE) is performed to produce 3D information that can be used in downstream tasks such as those related to on-board perception for Autonomous Vehicles (AVs) or driver assistance. Therefore, a relevant arising question is whether the standard metrics for MDE assessment are a good indicator of the accuracy of future MDE-based driving-related perception tasks. We address this question in this paper. In particular, we take the task of 3D object detection on point clouds as a proxy of on-board perception. We train and test state-of-the-art 3D object detectors using 3D point clouds coming from MDE models. We confront the ranking of object detection results with the ranking given by the depth estimation metrics of the MDE models. We conclude that, indeed, MDE evaluation metrics give rise to a ranking of methods that reflects relatively well the 3D object detection results we may expect. Among the different metrics, the absolute relative (abs-rel) error seems to be the best for that purpose.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Feb 20, 2023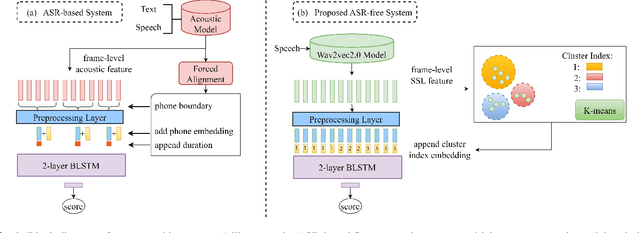
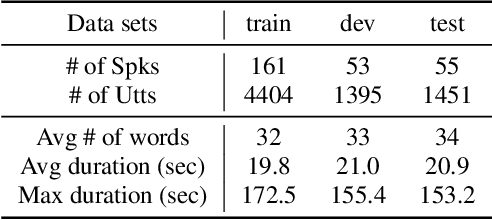
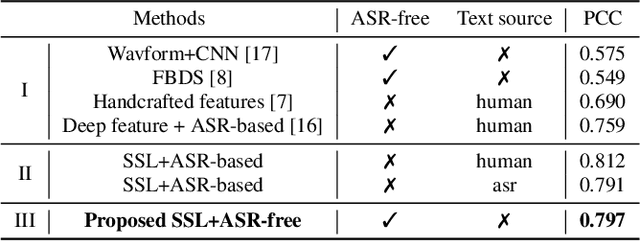
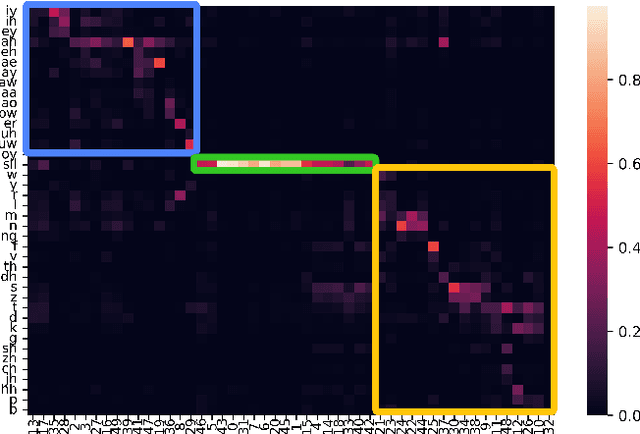
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
Nyström $M$-Hilbert-Schmidt Independence Criterion
Feb 20, 2023
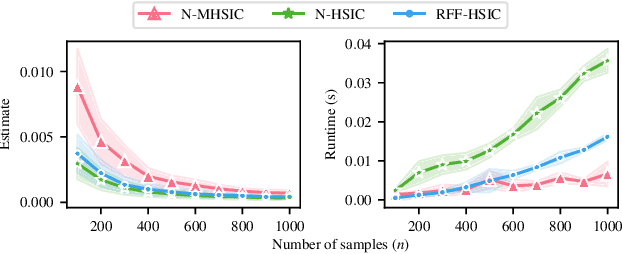
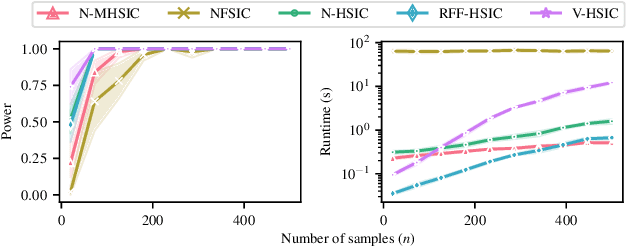
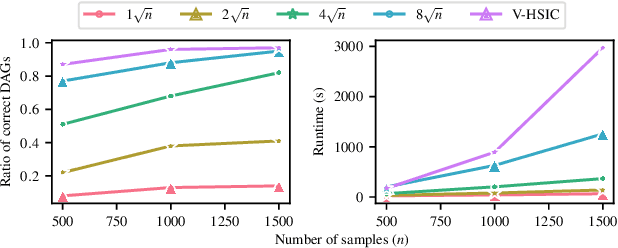
Kernel techniques are among the most popular and powerful approaches of data science. Among the key features that make kernels ubiquitous are (i) the number of domains they have been designed for, (ii) the Hilbert structure of the function class associated to kernels facilitating their statistical analysis, and (iii) their ability to represent probability distributions without loss of information. These properties give rise to the immense success of Hilbert-Schmidt independence criterion (HSIC) which is able to capture joint independence of random variables under mild conditions, and permits closed-form estimators with quadratic computational complexity (w.r.t. the sample size). In order to alleviate the quadratic computational bottleneck in large-scale applications, multiple HSIC approximations have been proposed, however these estimators are restricted to $M=2$ random variables, do not extend naturally to the $M\ge 2$ case, and lack theoretical guarantees. In this work, we propose an alternative Nystr\"om-based HSIC estimator which handles the $M\ge 2$ case, prove its consistency, and demonstrate its applicability in multiple contexts, including synthetic examples, dependency testing of media annotations, and causal discovery.
Self-Supervised Monocular Depth Estimation with Self-Reference Distillation and Disparity Offset Refinement
Feb 20, 2023
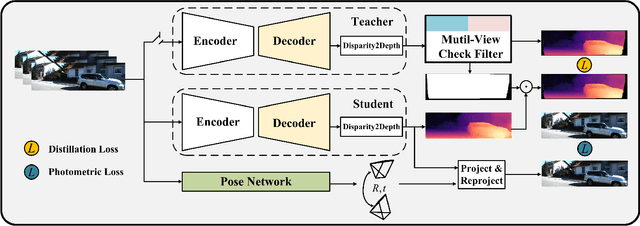
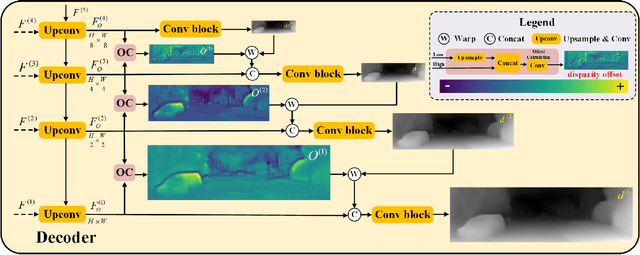
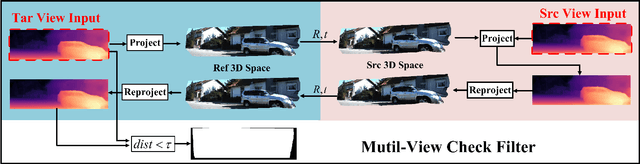
Monocular depth estimation plays a fundamental role in computer vision. Due to the costly acquisition of depth ground truth, self-supervised methods that leverage adjacent frames to establish a supervisory signal have emerged as the most promising paradigms. In this work, we propose two novel ideas to improve self-supervised monocular depth estimation: 1) self-reference distillation and 2) disparity offset refinement. Specifically, we use a parameter-optimized model as the teacher updated as the training epochs to provide additional supervision during the training process. The teacher model has the same structure as the student model, with weights inherited from the historical student model. In addition, a multiview check is introduced to filter out the outliers produced by the teacher model. Furthermore, we leverage the contextual consistency between high-scale and low-scale features to obtain multiscale disparity offsets, which are used to refine the disparity output incrementally by aligning disparity information at different scales. The experimental results on the KITTI and Make3D datasets show that our method outperforms previous state-of-the-art competitors.
A Review of Codebooks for CSI Feedback in 5G New Radio and Beyond
Feb 18, 2023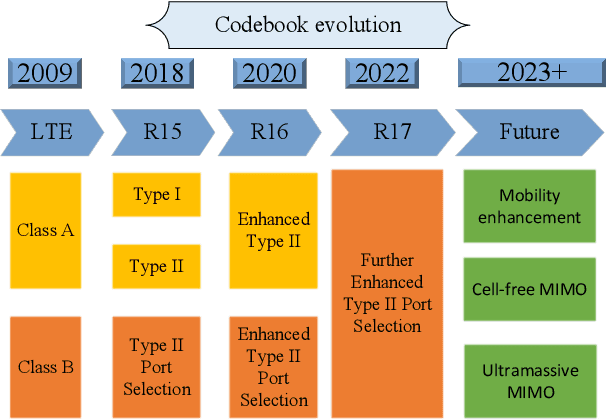
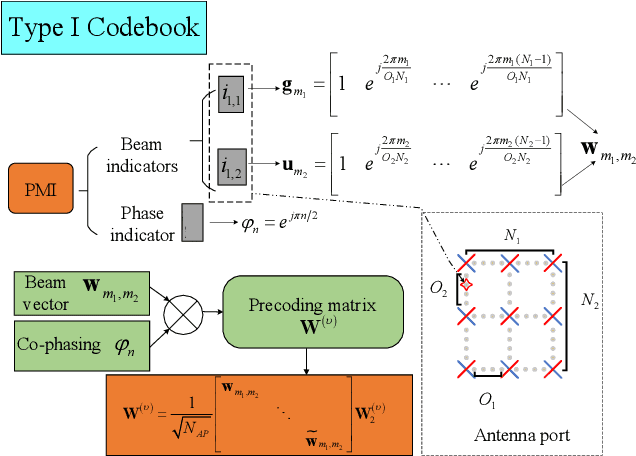
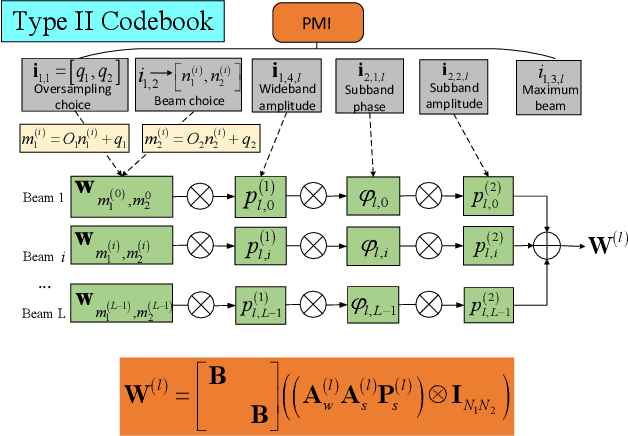
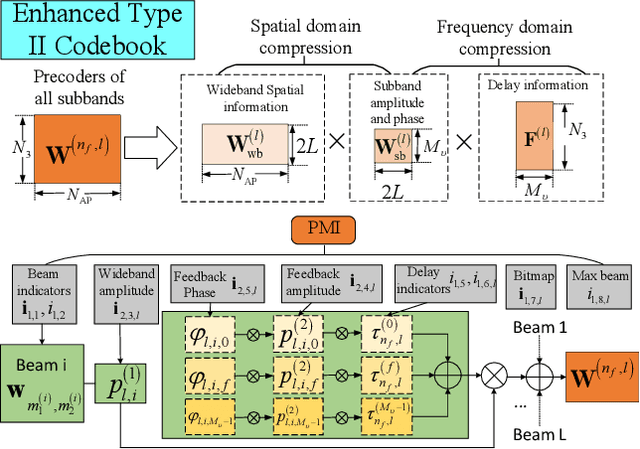
Codebooks have been indispensable for wireless communication standard since the first release of the Long-Term Evolution in 2009. They offer an efficient way to acquire the channel state information (CSI) for multiple antenna systems. Nowadays, a codebook is not limited to a set of pre-defined precoders, it refers to a CSI feedback framework, which is more and more sophisticated. In this paper, we review the codebooks in 5G New Radio (NR) standards. The codebook timeline and the evolution trend are shown. Each codebook is elaborated with its motivation, the corresponding feedback mechanism, and the format of the precoding matrix indicator. Some insights are given to help grasp the underlying reasons and intuitions of these codebooks. Finally, we point out some unresolved challenges of the codebooks for future evolution of the standards. In general, this paper provides a comprehensive review of the codebooks in 5G NR and aims to help researchers understand the CSI feedback schemes from a standard and industrial perspective.