 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIBOOT: A New Data-Driven Expert for Improved Driving Simulations
Jun 12, 2024



The development of Autonomous Driving (AD) systems in simulated environments like CARLA is crucial for advancing real-world automotive technologies. To drive innovation, CARLA introduced Leaderboard 2.0, significantly more challenging than its predecessor. However, current AD methods have struggled to achieve satisfactory outcomes due to a lack of sufficient ground truth data. Human driving logs provided by CARLA are insufficient, and previously successful expert agents like Autopilot and Roach, used for collecting datasets, have seen reduced effectiveness under these more demanding conditions. To overcome these data limitations, we introduce PRIBOOT, an expert agent that leverages limited human logs with privileged information. We have developed a novel BEV representation specifically tailored to meet the demands of this new benchmark and processed it as an RGB image to facilitate the application of transfer learning techniques, instead of using a set of masks. Additionally, we propose the Infraction Rate Score (IRS), a new evaluation metric designed to provide a more balanced assessment of driving performance over extended routes. PRIBOOT is the first model to achieve a Route Completion (RC) of 75% in Leaderboard 2.0, along with a Driving Score (DS) and IRS of 20% and 45%, respectively. With PRIBOOT, researchers can now generate extensive datasets, potentially solving the data availability issues that have hindered progress in this benchmark.
Synthetic Data Generation Framework, Dataset, and Efficient Deep Model for Pedestrian Intention Prediction
Jan 12, 2024



Pedestrian intention prediction is crucial for autonomous driving. In particular, knowing if pedestrians are going to cross in front of the ego-vehicle is core to performing safe and comfortable maneuvers. Creating accurate and fast models that predict such intentions from sequential images is challenging. A factor contributing to this is the lack of datasets with diverse crossing and non-crossing (C/NC) scenarios. We address this scarceness by introducing a framework, named ARCANE, which allows programmatically generating synthetic datasets consisting of C/NC video clip samples. As an example, we use ARCANE to generate a large and diverse dataset named PedSynth. We will show how PedSynth complements widely used real-world datasets such as JAAD and PIE, so enabling more accurate models for C/NC prediction. Considering the onboard deployment of C/NC prediction models, we also propose a deep model named PedGNN, which is fast and has a very low memory footprint. PedGNN is based on a GNN-GRU architecture that takes a sequence of pedestrian skeletons as input to predict crossing intentions.
On the Metrics for Evaluating Monocular Depth Estimation
Feb 20, 2023



Monocular Depth Estimation (MDE) is performed to produce 3D information that can be used in downstream tasks such as those related to on-board perception for Autonomous Vehicles (AVs) or driver assistance. Therefore, a relevant arising question is whether the standard metrics for MDE assessment are a good indicator of the accuracy of future MDE-based driving-related perception tasks. We address this question in this paper. In particular, we take the task of 3D object detection on point clouds as a proxy of on-board perception. We train and test state-of-the-art 3D object detectors using 3D point clouds coming from MDE models. We confront the ranking of object detection results with the ranking given by the depth estimation metrics of the MDE models. We conclude that, indeed, MDE evaluation metrics give rise to a ranking of methods that reflects relatively well the 3D object detection results we may expect. Among the different metrics, the absolute relative (abs-rel) error seems to be the best for that purpose.
Scaling Self-Supervised End-to-End Driving with Multi-View Attention Learning
Feb 09, 2023



On end-to-end driving, a large amount of expert driving demonstrations is used to train an agent that mimics the expert by predicting its control actions. This process is self-supervised on vehicle signals (e.g., steering angle, acceleration) and does not require extra costly supervision (human labeling). Yet, the improvement of existing self-supervised end-to-end driving models has mostly given room to modular end-to-end models where labeling data intensive format such as semantic segmentation are required during training time. However, we argue that the latest self-supervised end-to-end models were developed in sub-optimal conditions with low-resolution images and no attention mechanisms. Further, those models are confined with limited field of view and far from the human visual cognition which can quickly attend far-apart scene features, a trait that provides an useful inductive bias. In this context, we present a new end-to-end model, trained by self-supervised imitation learning, leveraging a large field of view and a self-attention mechanism. These settings are more contributing to the agent's understanding of the driving scene, which brings a better imitation of human drivers. With only self-supervised training data, our model yields almost expert performance in CARLA's Nocrash metrics and could be rival to the SOTA models requiring large amounts of human labeled data. To facilitate further research, our code will be released.
Unstructured Road Segmentation using Hypercolumn based Random Forests of Local experts
Jul 23, 2022



Monocular vision based road detection methods are mostly based on machine learning methods, relying on classification and feature extraction accuracy, and suffer from appearance, illumination and weather changes. Traditional methods introduce the predictions into conditional random fields or markov random fields models to improve the intermediate predictions based on structure. These methods are optimization based and therefore resource heavy and slow, making it unsuitable for real time applications. We propose a method to detect and segment roads with a random forest classifier of local experts with superpixel based machine-learned features. The random forest takes in machine learnt descriptors from a pre-trained convolutional neural network - VGG-16. The features are also pooled into their respective superpixels, allowing for local structure to be continuous. We compare our algorithm against Nueral Network based methods and Traditional approaches (based on Hand-crafted features), on both Structured Road (CamVid and Kitti) and Unstructured Road Datasets. Finally, we introduce a Road Scene Dataset with 1000 annotated images, and verify that our algorithm works well in non-urban and rural road scenarios.
Action-Based Representation Learning for Autonomous Driving
Aug 21, 2020
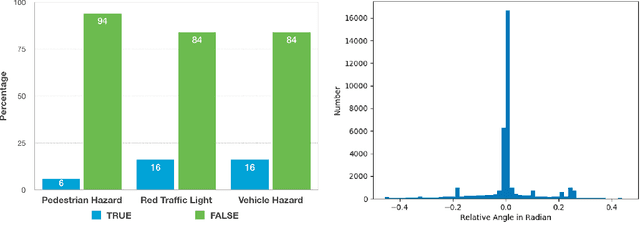
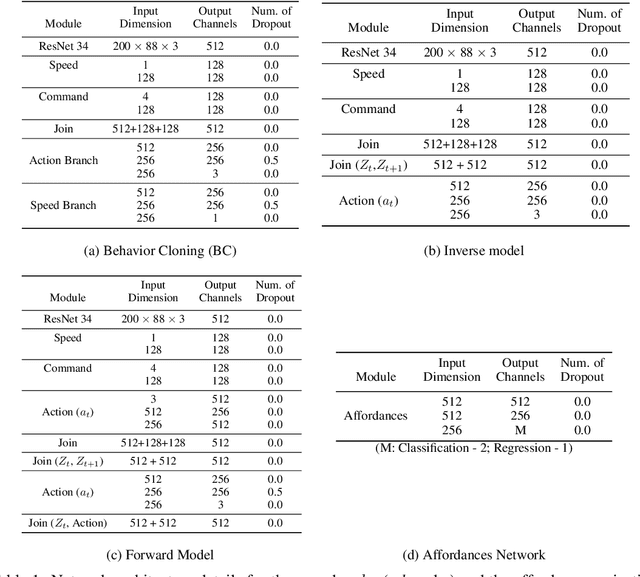
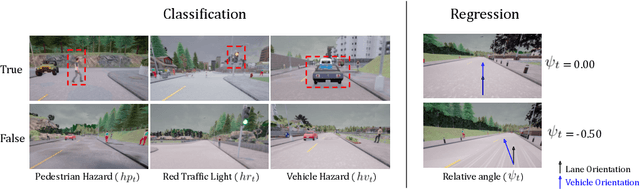
Human drivers produce a vast amount of data which could, in principle, be used to improve autonomous driving systems. Unfortunately, seemingly straightforward approaches for creating end-to-end driving models that map sensor data directly into driving actions are problematic in terms of interpretability, and typically have significant difficulty dealing with spurious correlations. Alternatively, we propose to use this kind of action-based driving data for learning representations. Our experiments show that an affordance-based driving model pre-trained with this approach can leverage a relatively small amount of weakly annotated imagery and outperform pure end-to-end driving models, while being more interpretable. Further, we demonstrate how this strategy outperforms previous methods based on learning inverse dynamics models as well as other methods based on heavy human supervision (ImageNet).
Co-training for On-board Deep Object Detection
Aug 12, 2020



Providing ground truth supervision to train visual models has been a bottleneck over the years, exacerbated by domain shifts which degenerate the performance of such models. This was the case when visual tasks relied on handcrafted features and shallow machine learning and, despite its unprecedented performance gains, the problem remains open within the deep learning paradigm due to its data-hungry nature. Best performing deep vision-based object detectors are trained in a supervised manner by relying on human-labeled bounding boxes which localize class instances (i.e.objects) within the training images.Thus, object detection is one of such tasks for which human labeling is a major bottleneck. In this paper, we assess co-training as a semi-supervised learning method for self-labeling objects in unlabeled images, so reducing the human-labeling effort for developing deep object detectors. Our study pays special attention to a scenario involving domain shift; in particular, when we have automatically generated virtual-world images with object bounding boxes and we have real-world images which are unlabeled. Moreover, we are particularly interested in using co-training for deep object detection in the context of driver assistance systems and/or self-driving vehicles. Thus, using well-established datasets and protocols for object detection in these application contexts, we will show how co-training is a paradigm worth to pursue for alleviating object labeling, working both alone and together with task-agnostic domain adaptation.
Distributed Learning and Inference with Compressed Images
Apr 22, 2020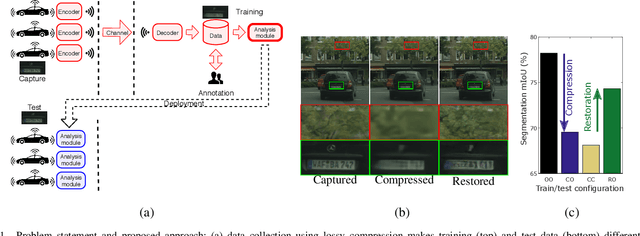
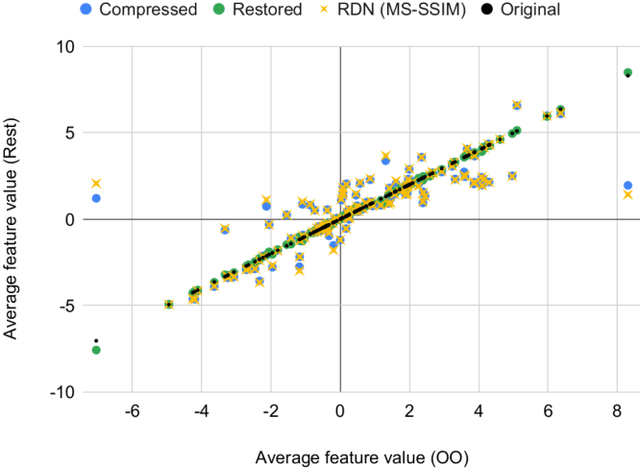

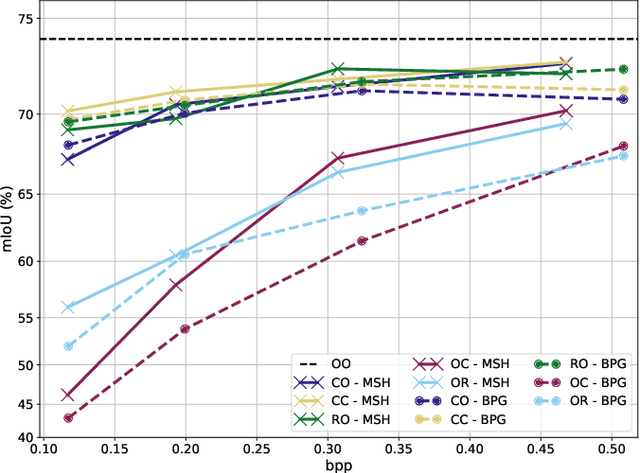
Modern computer vision requires processing large amounts of data, both while training the model and/or during inference, once the model is deployed. Scenarios where images are captured and processed in physically separated locations are increasingly common (e.g. autonomous vehicles, cloud computing). In addition, many devices suffer from limited resources to store or transmit data (e.g. storage space, channel capacity). In these scenarios, lossy image compression plays a crucial role to effectively increase the number of images collected under such constraints. However, lossy compression entails some undesired degradation of the data that may harm the performance of the downstream analysis task at hand, since important semantic information may be lost in the process. Moreover, we may only have compressed images at training time but are able to use original images at inference time, or vice versa, and in such a case, the downstream model suffers from covariate shift. In this paper, we analyze this phenomenon, with a special focus on vision-based perception for autonomous driving as a paradigmatic scenario. We see that loss of semantic information and covariate shift do indeed exist, resulting in a drop in performance that depends on the compression rate. In order to address the problem, we propose dataset restoration, based on image restoration with generative adversarial networks (GANs). Our method is agnostic to both the particular image compression method and the downstream task; and has the advantage of not adding additional cost to the deployed models, which is particularly important in resource-limited devices. The presented experiments focus on semantic segmentation as a challenging use case, cover a broad range of compression rates and diverse datasets, and show how our method is able to significantly alleviate the negative effects of compression on the downstream visual task.
Slanted Stixels: A way to represent steep streets
Oct 02, 2019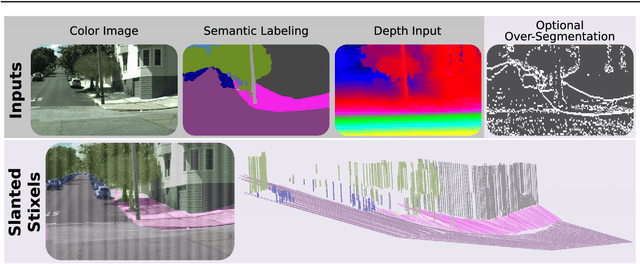
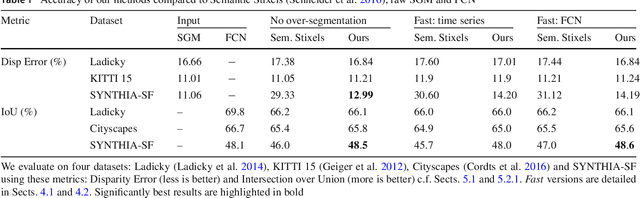

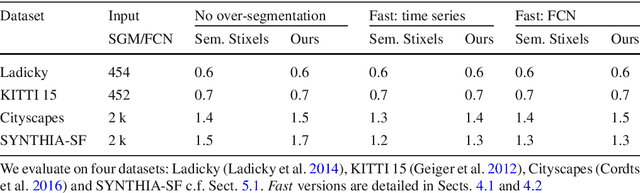
This work presents and evaluates a novel compact scene representation based on Stixels that infers geometric and semantic information. Our approach overcomes the previous rather restrictive geometric assumptions for Stixels by introducing a novel depth model to account for non-flat roads and slanted objects. Both semantic and depth cues are used jointly to infer the scene representation in a sound global energy minimization formulation. Furthermore, a novel approximation scheme is introduced in order to significantly reduce the computational complexity of the Stixel algorithm, and then achieve real-time computation capabilities. The idea is to first perform an over-segmentation of the image, discarding the unlikely Stixel cuts, and apply the algorithm only on the remaining Stixel cuts. This work presents a novel over-segmentation strategy based on a Fully Convolutional Network (FCN), which outperforms an approach based on using local extrema of the disparity map. We evaluate the proposed methods in terms of semantic and geometric accuracy as well as run-time on four publicly available benchmark datasets. Our approach maintains accuracy on flat road scene datasets while improving substantially on a novel non-flat road dataset.
* Journal preprint (published in IJCV 2019: https://link.springer.com/article/10.1007/s11263-019-01226-9). arXiv admin note: text overlap with arXiv:1707.05397
Temporal Coherence for Active Learning in Videos
Aug 30, 2019
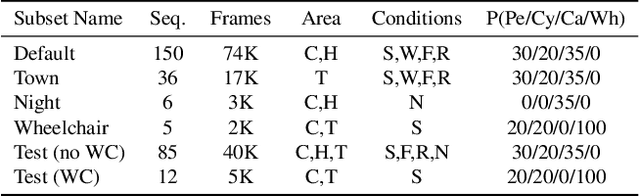
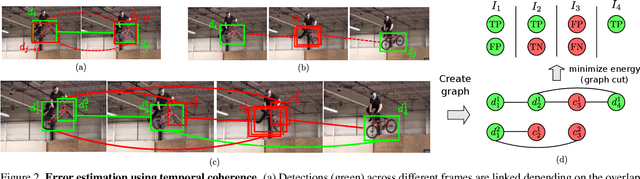
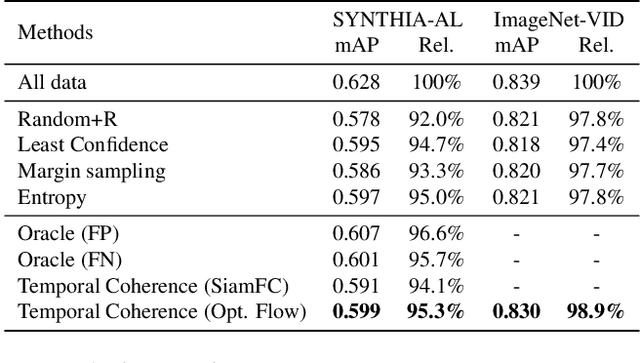
Autonomous driving systems require huge amounts of data to train. Manual annotation of this data is time-consuming and prohibitively expensive since it involves human resources. Therefore, active learning emerged as an alternative to ease this effort and to make data annotation more manageable. In this paper, we introduce a novel active learning approach for object detection in videos by exploiting temporal coherence. Our active learning criterion is based on the estimated number of errors in terms of false positives and false negatives. The detections obtained by the object detector are used to define the nodes of a graph and tracked forward and backward to temporally link the nodes. Minimizing an energy function defined on this graphical model provides estimates of both false positives and false negatives. Additionally, we introduce a synthetic video dataset, called SYNTHIA-AL, specially designed to evaluate active learning for video object detection in road scenes. Finally, we show that our approach outperforms active learning baselines tested on two datasets.