 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can We Use Probing to Better Understand Fine-tuning and Knowledge Distillation of the BERT NLU?
Jan 27, 2023
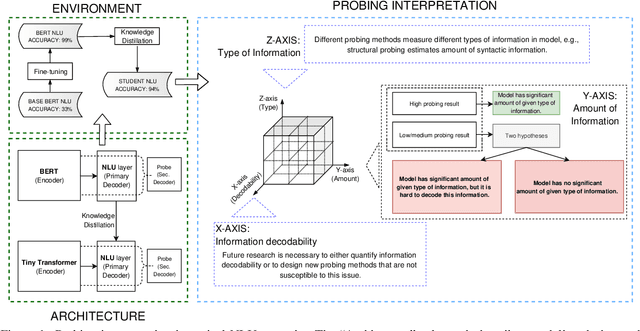
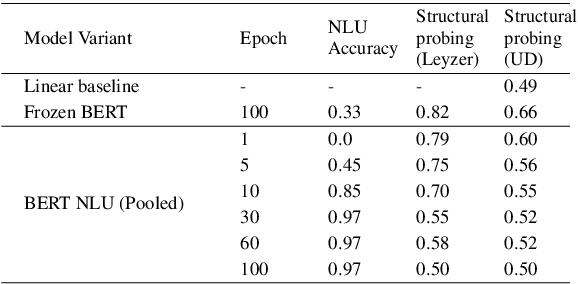
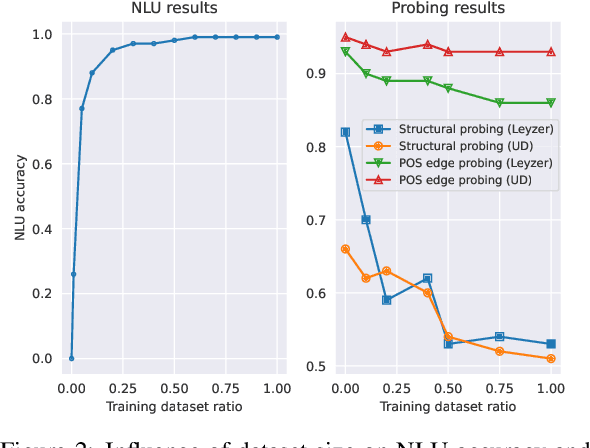
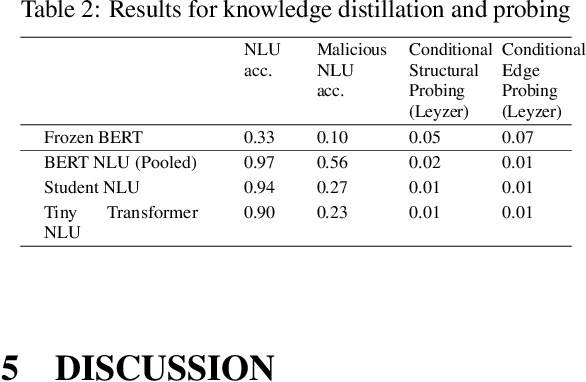
In this article, we use probing to investigate phenomena that occur during fine-tuning and knowledge distillation of a BERT-based natural language understanding (NLU) model. Our ultimate purpose was to use probing to better understand practical production problems and consequently to build better NLU models. We designed experiments to see how fine-tuning changes the linguistic capabilities of BERT, what the optimal size of the fine-tuning dataset is, and what amount of information is contained in a distilled NLU based on a tiny Transformer. The results of the experiments show that the probing paradigm in its current form is not well suited to answer such questions. Structural, Edge and Conditional probes do not take into account how easy it is to decode probed information. Consequently, we conclude that quantification of information decodability is critical for many practical applications of the probing paradigm.
Universal resources for quantum computing
Mar 08, 2023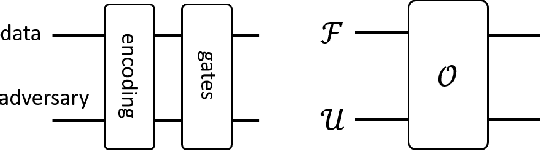
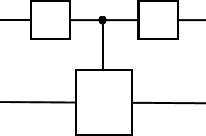
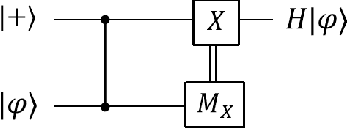
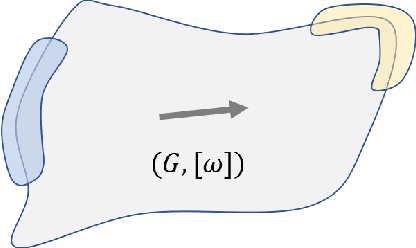
Unravelling the source of quantum computing power has been a major goal in the field of quantum information science. In recent years, the quantum resource theory (QRT) has been established to characterize various quantum resources, yet their roles in quantum computing tasks still require investigation. The so-called universal quantum computing model (UQCM), e.g., the circuit model, has been the main framework to guide the design of quantum algorithms, creation of real quantum computers etc. In this work, we combine the study of UQCM together with QRT. We find on one hand, using QRT can provide a resource-theoretic characterization of a UQCM, the relation among models and inspire new ones, and on the other hand, using UQCM offers a framework to apply resources, study relation among resources and classify them. We develop the theory of universal resources in the setting of UQCM, and find a rich spectrum of UQCMs and the corresponding universal resources. Depending on a hierarchical structure of resource theories, we find models can be classified into families. In this work, we study three natural families of UQCMs in details: the amplitude family, the quasi-probability family, and the Hamiltonian family. They include some well known models, like the measurement-based model and adiabatic model, and also inspire new models such as the contextual model we introduce. Each family contains at least a triplet of models, and such a succinct structure of families of UQCMs offers a unifying picture to investigate resources and design models. It also provides a rigorous framework to resolve puzzles, such as the role of entanglement vs. interference, and unravel resource-theoretic features of quantum algorithms.
Private Status Updating with Erasures: A Case for Retransmission Without Resampling
Feb 23, 2023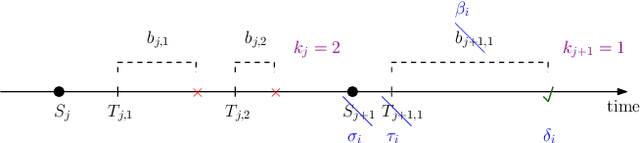
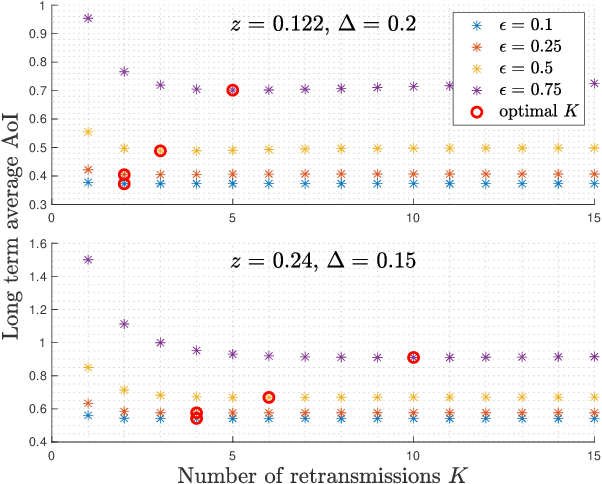
A status updating system is considered in which a source updates a destination over an erasure channel. The utility of the updates is measured through a function of their age-of-information (AoI), which assesses their freshness. Correlated with the status updates is another process that needs to be kept private from the destination. Privacy is measured through a leakage function that depends on the amount and time of the status updates received: stale updates are more private than fresh ones. Different from most of the current AoI literature, a post-sampling waiting time is introduced in order to provide a privacy cover at the expense of AoI. More importantly, it is also shown that, depending on the leakage budget and the channel statistics, it can be useful to retransmit stale status updates following erasure events without resampling fresh ones.
A novel efficient Multi-view traffic-related object detection framework
Feb 23, 2023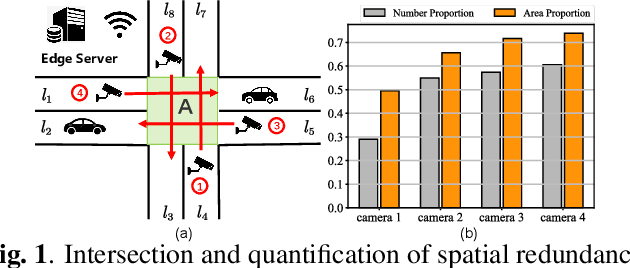
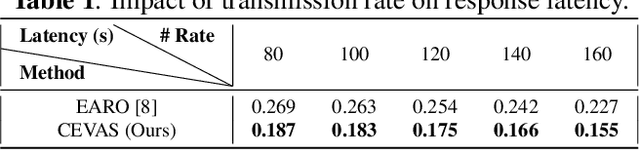

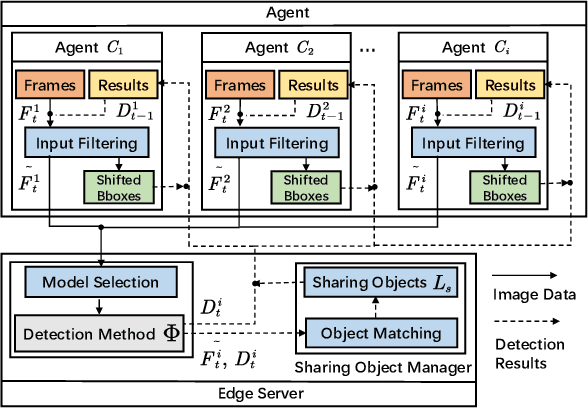
With the rapid development of intelligent transportation system applications, a tremendous amount of multi-view video data has emerged to enhance vehicle perception. However, performing video analytics efficiently by exploiting the spatial-temporal redundancy from video data remains challenging. Accordingly, we propose a novel traffic-related framework named CEVAS to achieve efficient object detection using multi-view video data. Briefly, a fine-grained input filtering policy is introduced to produce a reasonable region of interest from the captured images. Also, we design a sharing object manager to manage the information of objects with spatial redundancy and share their results with other vehicles. We further derive a content-aware model selection policy to select detection methods adaptively. Experimental results show that our framework significantly reduces response latency while achieving the same detection accuracy as the state-of-the-art methods.
Common Vulnerability Scoring System Prediction based on Open Source Intelligence Information Sources
Oct 05, 2022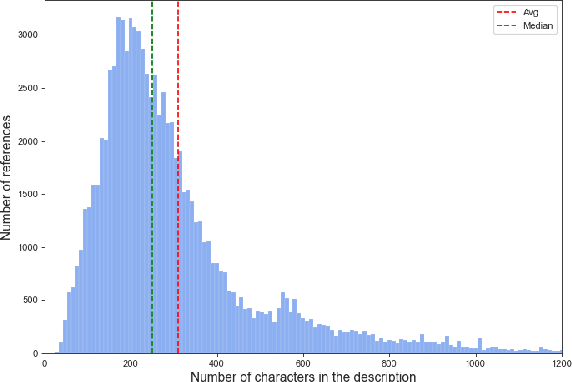
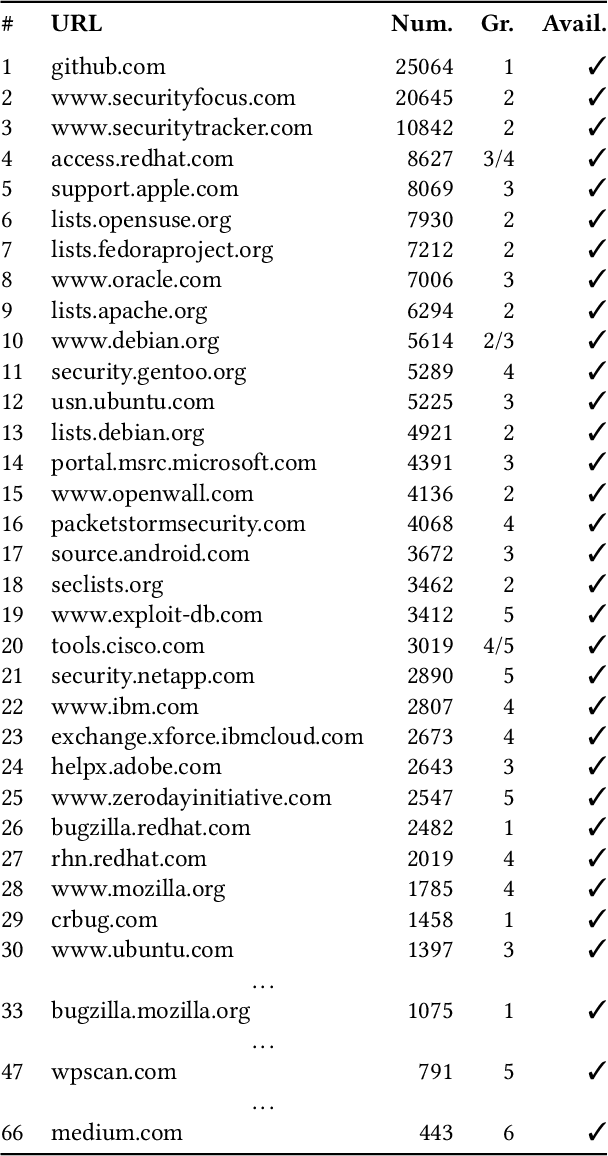
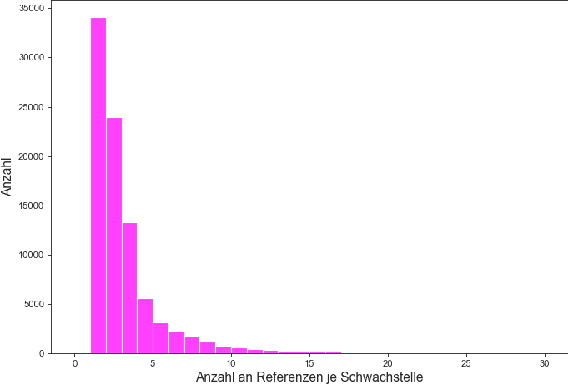
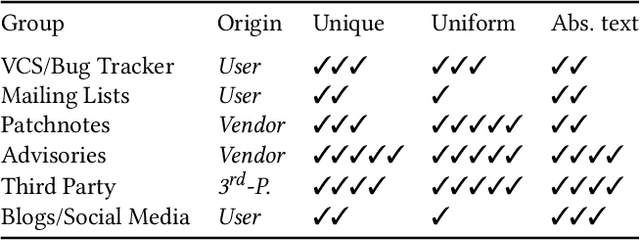
The number of newly published vulnerabilities is constantly increasing. Until now, the information available when a new vulnerability is published is manually assessed by experts using a Common Vulnerability Scoring System (CVSS) vector and score. This assessment is time consuming and requires expertise. Various works already try to predict CVSS vectors or scores using machine learning based on the textual descriptions of the vulnerability to enable faster assessment. However, for this purpose, previous works only use the texts available in databases such as National Vulnerability Database. With this work, the publicly available web pages referenced in the National Vulnerability Database are analyzed and made available as sources of texts through web scraping. A Deep Learning based method for predicting the CVSS vector is implemented and evaluated. The present work provides a classification of the National Vulnerability Database's reference texts based on the suitability and crawlability of their texts. While we identified the overall influence of the additional texts is negligible, we outperformed the state-of-the-art with our Deep Learning prediction models.
Traffic State Estimation with Anisotropic Gaussian Processes from Vehicle Trajectories
Mar 04, 2023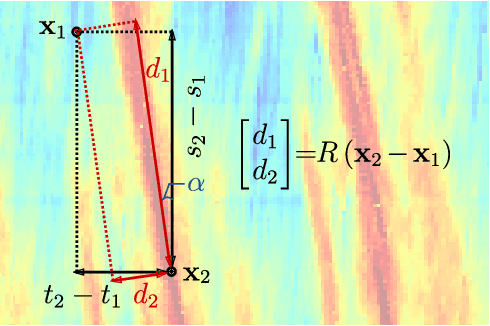
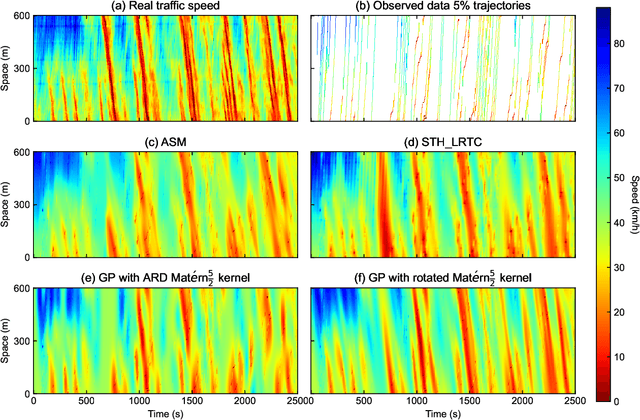
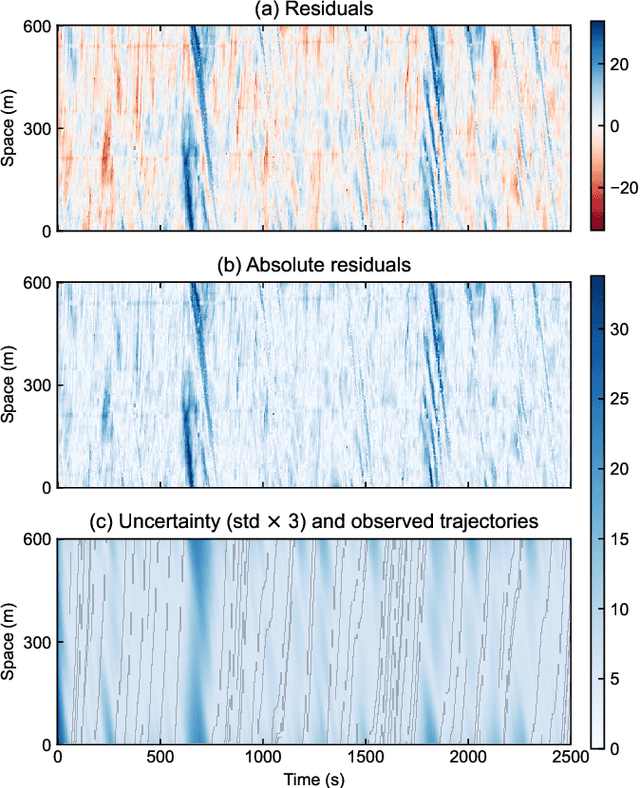
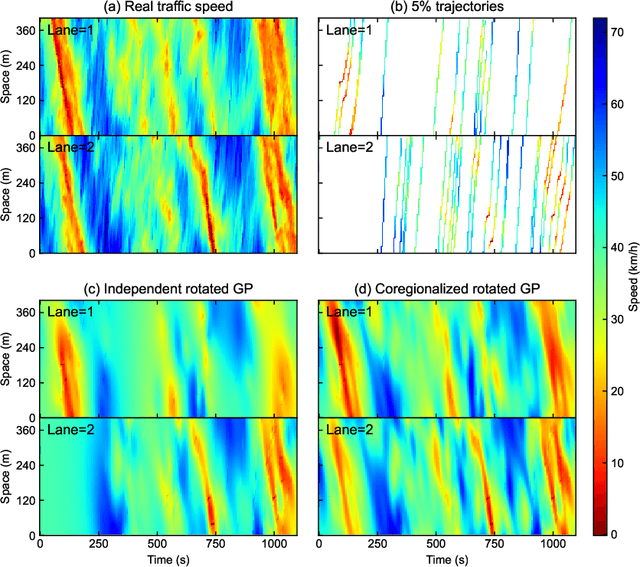
Accurately monitoring road traffic state and speed is crucial for various applications, including travel time prediction, traffic control, and traffic safety. However, the lack of sensors often results in incomplete traffic state data, making it challenging to obtain reliable information for decision-making. This paper proposes a novel method for imputing traffic state data using Gaussian processes (GP) to address this issue. We propose a kernel rotation re-parametrization scheme that transforms a standard isotropic GP kernel into an anisotropic kernel, which can better model the propagation of traffic waves in traffic flow data. This method can be applied to impute traffic state data from fixed sensors or probe vehicles. Moreover, the rotated GP method provides statistical uncertainty quantification for the imputed traffic state, making it more reliable. We also extend our approach to a multi-output GP, which allows for simultaneously estimating the traffic state for multiple lanes. We evaluate our method using real-world traffic data from the Next Generation simulation (NGSIM) and HighD programs. Considering current and future mixed traffic of connected vehicles (CVs) and human-driven vehicles (HVs), we experiment with the traffic state estimation scheme from 5% to 50% available trajectories, mimicking different CV penetration rates in a mixed traffic environment. Results show that our method outperforms state-of-the-art methods in terms of estimation accuracy, efficiency, and robustness.
Improving the quality of dental crown using a Transformer-based method
Mar 04, 2023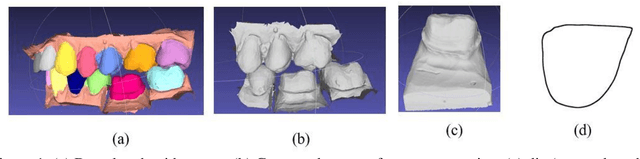
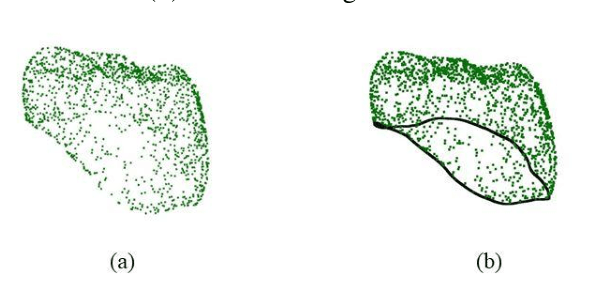

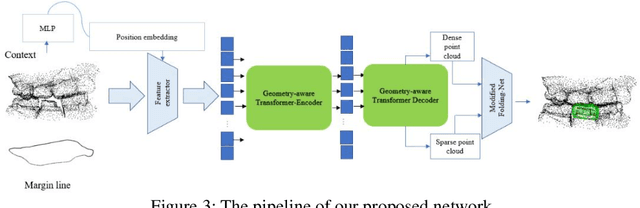
Designing a synthetic crown is a time-consuming, inconsistent, and labor-intensive process. In this work, we present a fully automatic method that not only learns human design dental crowns, but also improves the consistency, functionality, and esthetic of the crowns. Following success in point cloud completion using the transformer-based network, we tackle the problem of the crown generation as a point-cloud completion around a prepared tooth. To this end, we use a geometry-aware transformer to generate dental crowns. Our main contribution is to add a margin line information to the network, as the accuracy of generating a precise margin line directly,determines whether the designed crown and prepared tooth are closely matched to allowappropriateadhesion.Using our ground truth crown, we can extract the margin line as a spline and sample the spline into 1000 points. We feed the obtained margin line along with two neighbor teeth of the prepared tooth and three closest teeth in the opposing jaw. We also add the margin line points to our ground truth crown to increase the resolution at the margin line. Our experimental results show an improvement in the quality of the designed crown when considering the actual context composed of the prepared tooth along with the margin line compared with a crown generated in an empty space as was done by other studies in the literature.
Visualizing Transferred Knowledge: An Interpretive Model of Unsupervised Domain Adaptation
Mar 04, 2023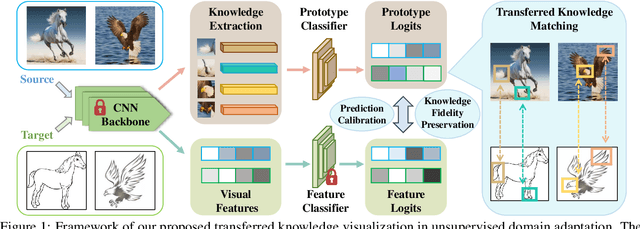
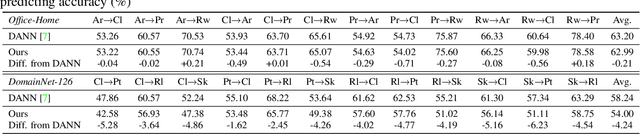
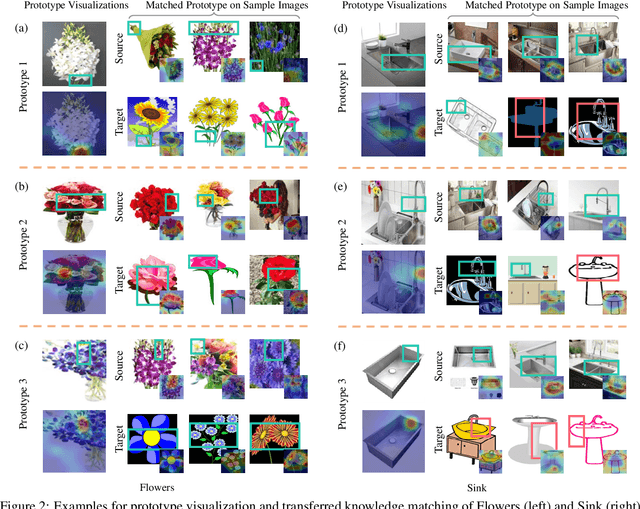
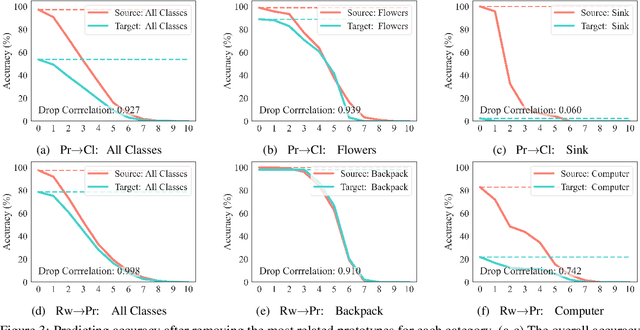
Many research efforts have been committed to unsupervised domain adaptation (DA) problems that transfer knowledge learned from a labeled source domain to an unlabeled target domain. Various DA methods have achieved remarkable results recently in terms of predicting ability, which implies the effectiveness of the aforementioned knowledge transferring. However, state-of-the-art methods rarely probe deeper into the transferred mechanism, leaving the true essence of such knowledge obscure. Recognizing its importance in the adaptation process, we propose an interpretive model of unsupervised domain adaptation, as the first attempt to visually unveil the mystery of transferred knowledge. Adapting the existing concept of the prototype from visual image interpretation to the DA task, our model similarly extracts shared information from the domain-invariant representations as prototype vectors. Furthermore, we extend the current prototype method with our novel prediction calibration and knowledge fidelity preservation modules, to orientate the learned prototypes to the actual transferred knowledge. By visualizing these prototypes, our method not only provides an intuitive explanation for the base model's predictions but also unveils transfer knowledge by matching the image patches with the same semantics across both source and target domains. Comprehensive experiments and in-depth explorations demonstrate the efficacy of our method in understanding the transferred mechanism and its potential in downstream tasks including model diagnosis.
Exploring The Potential Of GANs In Biological Sequence Analysis
Mar 04, 2023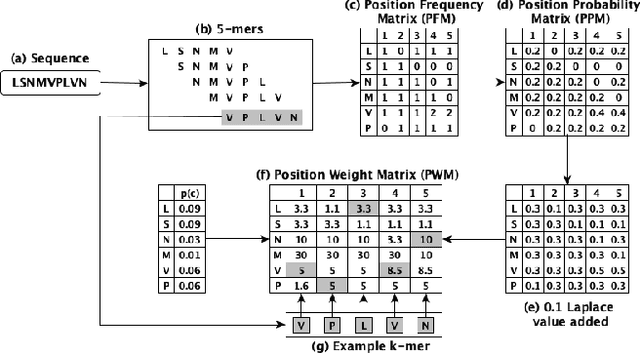
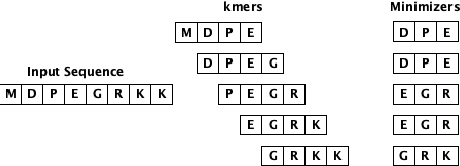
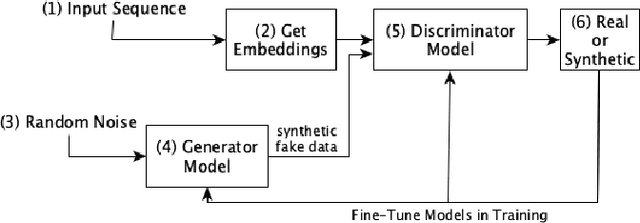
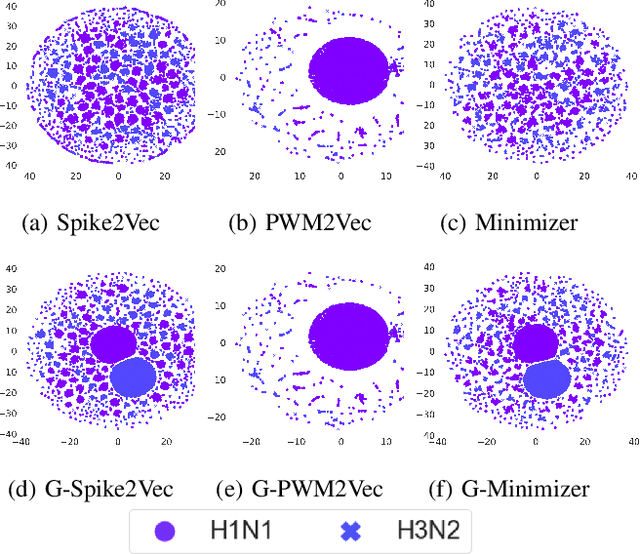
Biological sequence analysis is an essential step toward building a deeper understanding of the underlying functions, structures, and behaviors of the sequences. It can help in identifying the characteristics of the associated organisms, like viruses, etc., and building prevention mechanisms to eradicate their spread and impact, as viruses are known to cause epidemics that can become pandemics globally. New tools for biological sequence analysis are provided by machine learning (ML) technologies to effectively analyze the functions and structures of the sequences. However, these ML-based methods undergo challenges with data imbalance, generally associated with biological sequence datasets, which hinders their performance. Although various strategies are present to address this issue, like the SMOTE algorithm, which creates synthetic data, however, they focus on local information rather than the overall class distribution. In this work, we explore a novel approach to handle the data imbalance issue based on Generative Adversarial Networks (GANs) which use the overall data distribution. GANs are utilized to generate synthetic data that closely resembles the real one, thus this generated data can be employed to enhance the ML models' performance by eradicating the class imbalance problem for biological sequence analysis. We perform 3 distinct classification tasks by using 3 different sequence datasets (Influenza A Virus, PALMdb, VDjDB) and our results illustrate that GANs can improve the overall classification performance.
Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals
Feb 12, 2023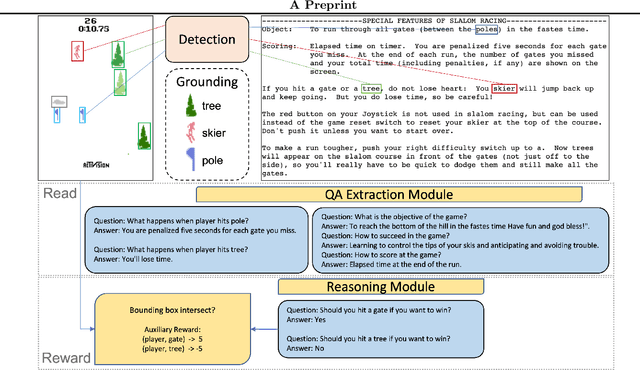
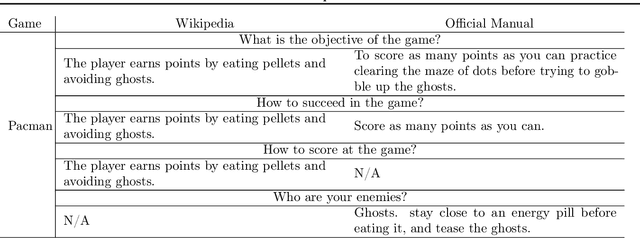
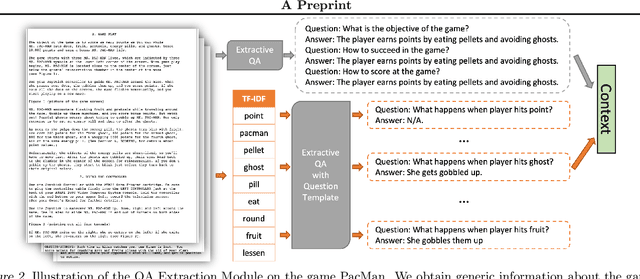
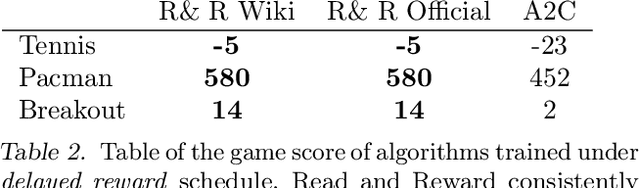
High sample complexity has long been a challenge for RL. On the other hand, humans learn to perform tasks not only from interaction or demonstrations, but also by reading unstructured text documents, e.g., instruction manuals. Instruction manuals and wiki pages are among the most abundant data that could inform agents of valuable features and policies or task-specific environmental dynamics and reward structures. Therefore, we hypothesize that the ability to utilize human-written instruction manuals to assist learning policies for specific tasks should lead to a more efficient and better-performing agent. We propose the Read and Reward framework. Read and Reward speeds up RL algorithms on Atari games by reading manuals released by the Atari game developers. Our framework consists of a QA Extraction module that extracts and summarizes relevant information from the manual and a Reasoning module that evaluates object-agent interactions based on information from the manual. Auxiliary reward is then provided to a standard A2C RL agent, when interaction is detected. When assisted by our design, A2C improves on 4 games in the Atari environment with sparse rewards, and requires 1000x less training frames compared to the previous SOTA Agent 57 on Skiing, the hardest game in Atari.