 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Steering Graph Neural Networks with Pinning Control
Mar 02, 2023
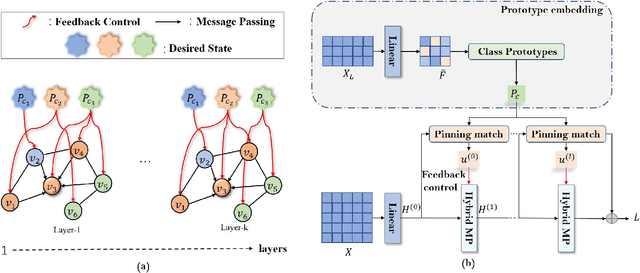
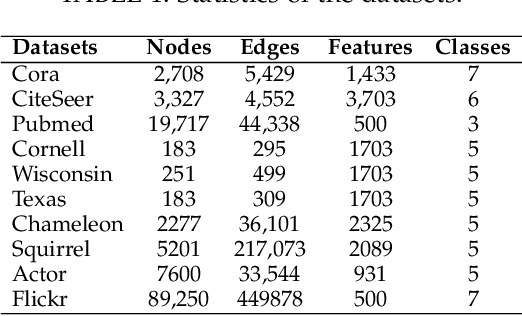
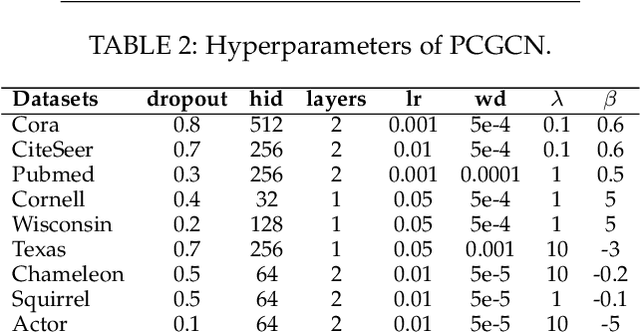
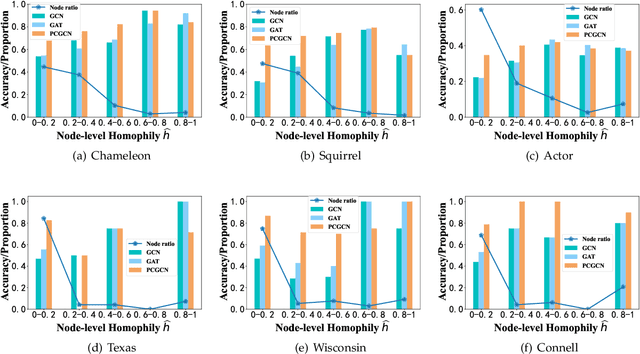
In the semi-supervised setting where labeled data are largely limited, it remains to be a big challenge for message passing based graph neural networks (GNNs) to learn feature representations for the nodes with the same class label that is distributed discontinuously over the graph. To resolve the discontinuous information transmission problem, we propose a control principle to supervise representation learning by leveraging the prototypes (i.e., class centers) of labeled data. Treating graph learning as a discrete dynamic process and the prototypes of labeled data as "desired" class representations, we borrow the pinning control idea from automatic control theory to design learning feedback controllers for the feature learning process, attempting to minimize the differences between message passing derived features and the class prototypes in every round so as to generate class-relevant features. Specifically, we equip every node with an optimal controller in each round through learning the matching relationships between nodes and the class prototypes, enabling nodes to rectify the aggregated information from incompatible neighbors in a graph with strong heterophily. Our experiments demonstrate that the proposed PCGCN model achieves better performances than deep GNNs and other competitive heterophily-oriented methods, especially when the graph has very few labels and strong heterophily.
New wrapper method based on normalized mutual information for dimension reduction and classification of hyperspectral images
Oct 25, 2022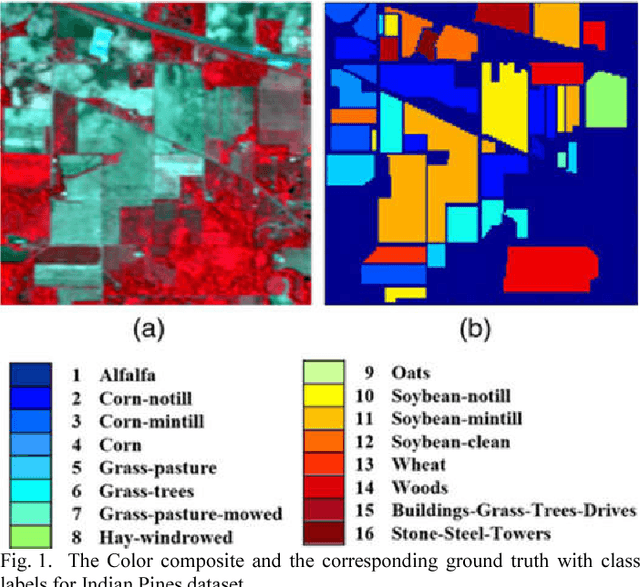
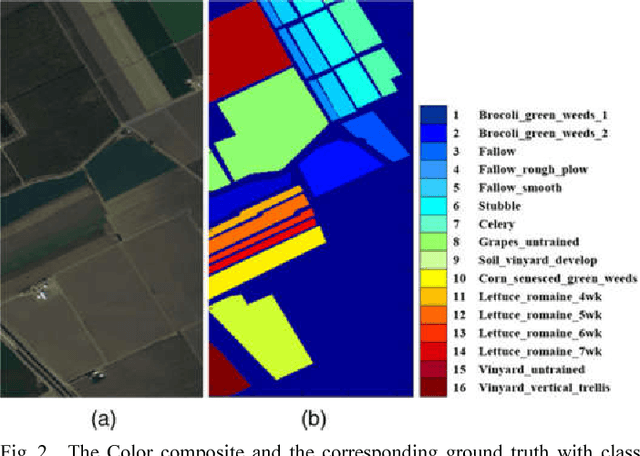
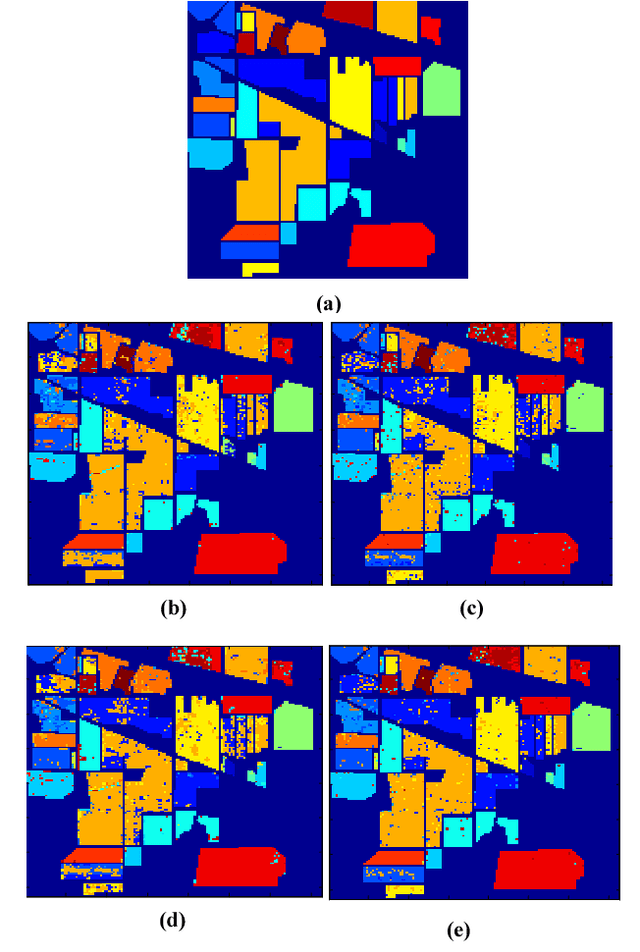
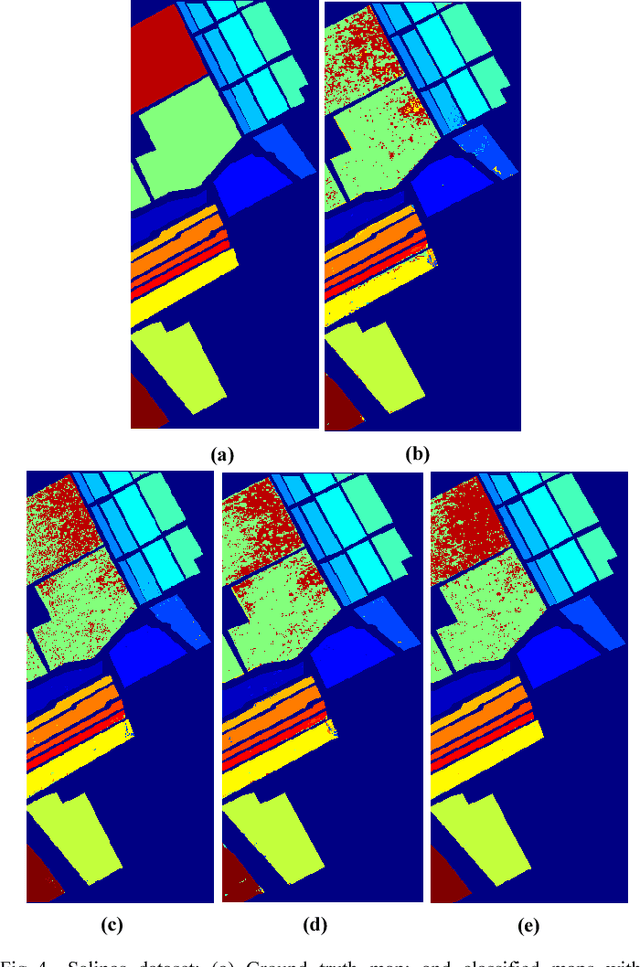
Feature selection is one of the most important problems in hyperspectral images classification. It consists to choose the most informative bands from the entire set of input datasets and discard the noisy, redundant and irrelevant ones. In this context, we propose a new wrapper method based on normalized mutual information (NMI) and error probability (PE) using support vector machine (SVM) to reduce the dimensionality of the used hyperspectral images and increase the classification efficiency. The experiments have been performed on two challenging hyperspectral benchmarks datasets captured by the NASA's Airborne Visible/Infrared Imaging Spectrometer Sensor (AVIRIS). Several metrics had been calculated to evaluate the performance of the proposed algorithm. The obtained results prove that our method can increase the classification performance and provide an accurate thematic map in comparison with other reproduced algorithms. This method may be improved for more classification efficiency. Keywords-Feature selection, hyperspectral images, classification, wrapper, normalized mutual information, support vector machine.
STOA-VLP: Spatial-Temporal Modeling of Object and Action for Video-Language Pre-training
Feb 20, 2023
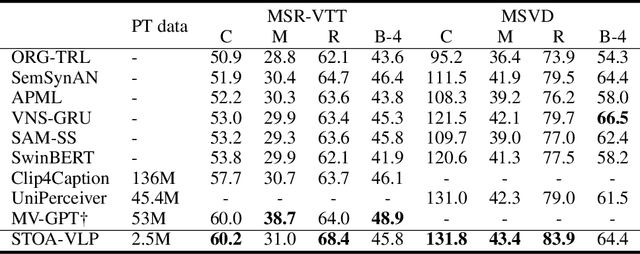
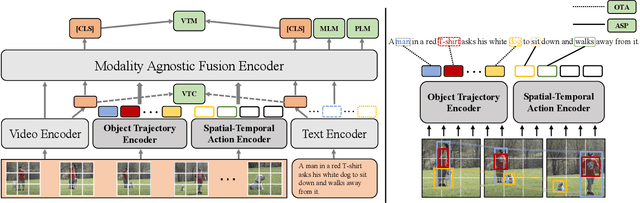
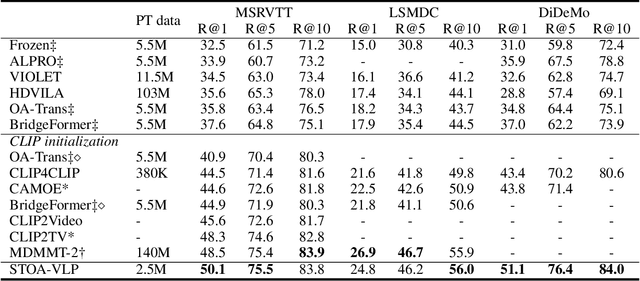
Although large-scale video-language pre-training models, which usually build a global alignment between the video and the text, have achieved remarkable progress on various downstream tasks, the idea of adopting fine-grained information during the pre-training stage is not well explored. In this work, we propose STOA-VLP, a pre-training framework that jointly models object and action information across spatial and temporal dimensions. More specifically, the model regards object trajectories across frames and multiple action features from the video as fine-grained features. Besides, We design two auxiliary tasks to better incorporate both kinds of information into the pre-training process of the video-language model. The first is the dynamic object-text alignment task, which builds a better connection between object trajectories and the relevant noun tokens. The second is the spatial-temporal action set prediction, which guides the model to generate consistent action features by predicting actions found in the text. Extensive experiments on three downstream tasks (video captioning, text-video retrieval, and video question answering) demonstrate the effectiveness of our proposed STOA-VLP (e.g. 3.7 Rouge-L improvements on MSR-VTT video captioning benchmark, 2.9% accuracy improvements on MSVD video question answering benchmark, compared to previous approaches).
FaceRNET: a Facial Expression Intensity Estimation Network
Mar 02, 2023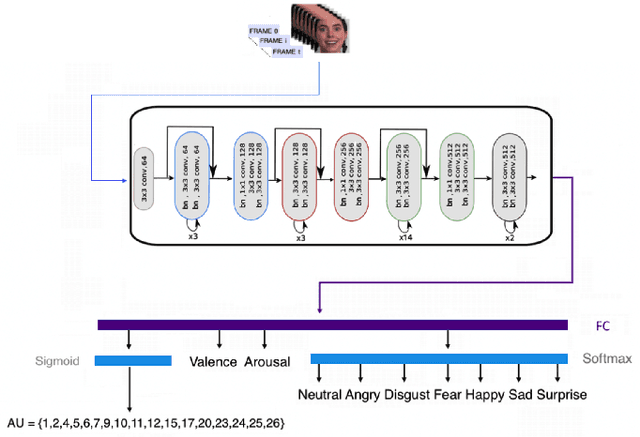

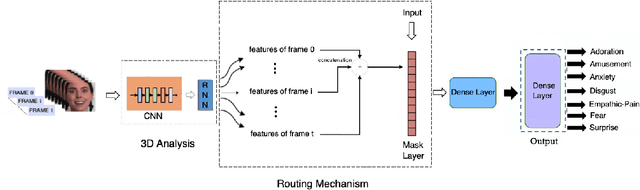

This paper presents our approach for Facial Expression Intensity Estimation from videos. It includes two components: i) a representation extractor network that extracts various emotion descriptors (valence-arousal, action units and basic expressions) from each videoframe; ii) a RNN that captures temporal information in the data, followed by a mask layer which enables handling varying input video lengths through dynamic routing. This approach has been tested on the Hume-Reaction dataset yielding excellent results.
StylerDALLE: Language-Guided Style Transfer Using a Vector-Quantized Tokenizer of a Large-Scale Generative Model
Mar 16, 2023
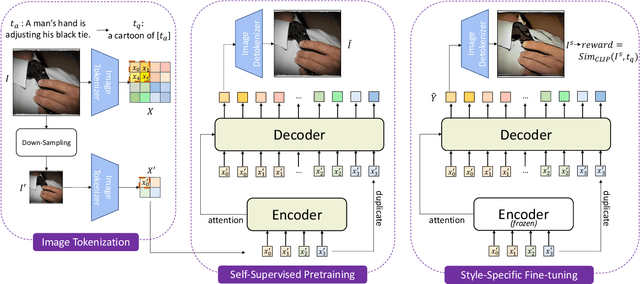


Despite the progress made in the style transfer task, most previous work focus on transferring only relatively simple features like color or texture, while missing more abstract concepts such as overall art expression or painter-specific traits. However, these abstract semantics can be captured by models like DALL-E or CLIP, which have been trained using huge datasets of images and textual documents. In this paper, we propose StylerDALLE, a style transfer method that exploits both of these models and uses natural language to describe abstract art styles. Specifically, we formulate the language-guided style transfer task as a non-autoregressive token sequence translation, i.e., from input content image to output stylized image, in the discrete latent space of a large-scale pretrained vector-quantized tokenizer. To incorporate style information, we propose a Reinforcement Learning strategy with CLIP-based language supervision that ensures stylization and content preservation simultaneously. Experimental results demonstrate the superiority of our method, which can effectively transfer art styles using language instructions at different granularities. Code is available at https://github.com/zipengxuc/StylerDALLE.
KGNv2: Separating Scale and Pose Prediction for Keypoint-based 6-DoF Grasp Synthesis on RGB-D input
Mar 16, 2023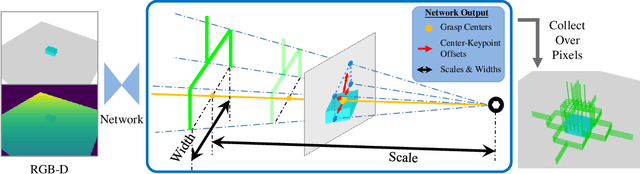
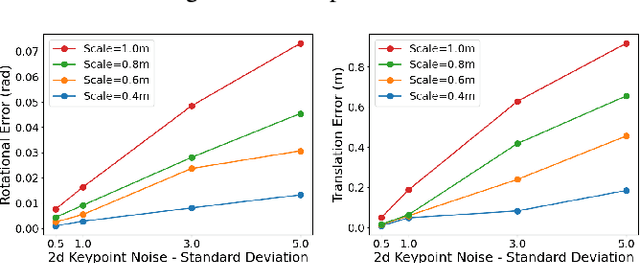
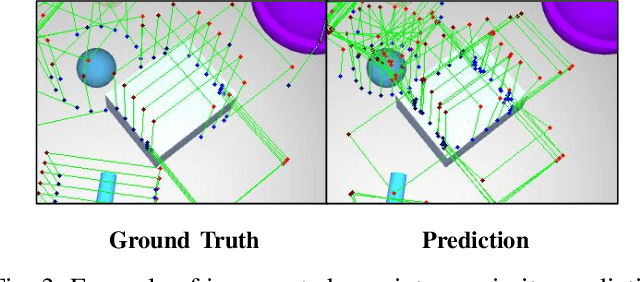

We propose a new 6-DoF grasp pose synthesis approach from 2D/2.5D input based on keypoints. Keypoint-based grasp detector from image input has demonstrated promising results in the previous study, where the additional visual information provided by color images compensates for the noisy depth perception. However, it relies heavily on accurately predicting the location of keypoints in the image space. In this paper, we devise a new grasp generation network that reduces the dependency on precise keypoint estimation. Given an RGB-D input, our network estimates both the grasp pose from keypoint detection as well as scale towards the camera. We further re-design the keypoint output space in order to mitigate the negative impact of keypoint prediction noise to Perspective-n-Point (PnP) algorithm. Experiments show that the proposed method outperforms the baseline by a large margin, validating the efficacy of our approach. Finally, despite trained on simple synthetic objects, our method demonstrate sim-to-real capacity by showing competitive results in real-world robot experiments.
All4One: Symbiotic Neighbour Contrastive Learning via Self-Attention and Redundancy Reduction
Mar 16, 2023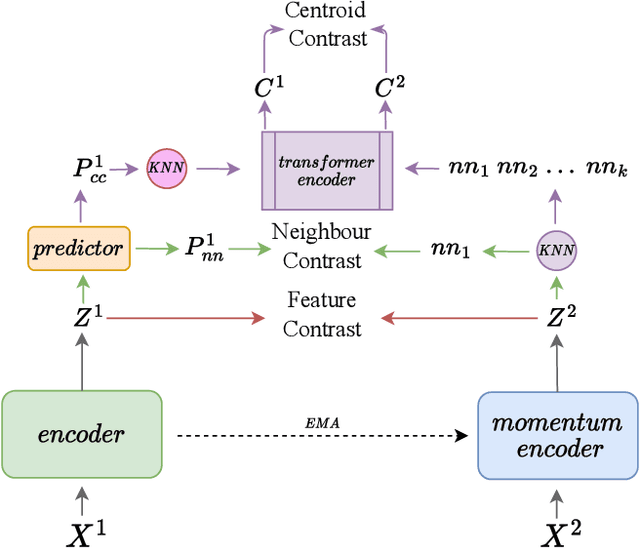
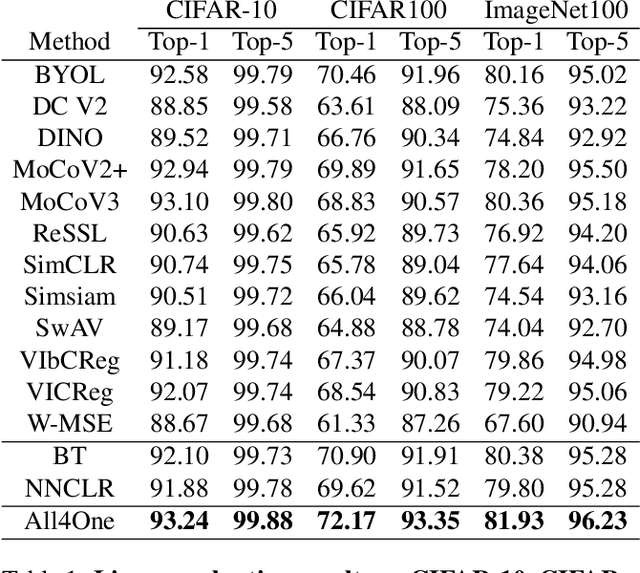
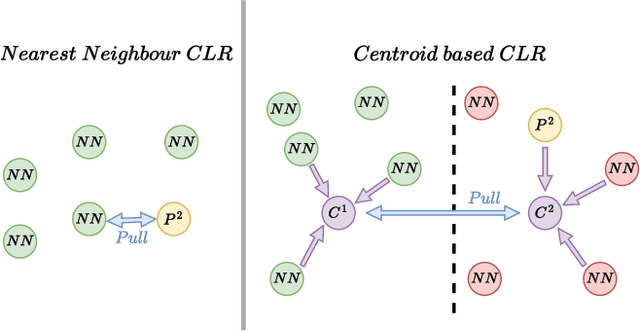

Nearest neighbour based methods have proved to be one of the most successful self-supervised learning (SSL) approaches due to their high generalization capabilities. However, their computational efficiency decreases when more than one neighbour is used. In this paper, we propose a novel contrastive SSL approach, which we call All4One, that reduces the distance between neighbour representations using ''centroids'' created through a self-attention mechanism. We use a Centroid Contrasting objective along with single Neighbour Contrasting and Feature Contrasting objectives. Centroids help in learning contextual information from multiple neighbours whereas the neighbour contrast enables learning representations directly from the neighbours and the feature contrast allows learning representations unique to the features. This combination enables All4One to outperform popular instance discrimination approaches by more than 1% on linear classification evaluation for popular benchmark datasets and obtains state-of-the-art (SoTA) results. Finally, we show that All4One is robust towards embedding dimensionalities and augmentations, surpassing NNCLR and Barlow Twins by more than 5% on low dimensionality and weak augmentation settings. The source code would be made available soon.
Sequential Information Design: Learning to Persuade in the Dark
Sep 08, 2022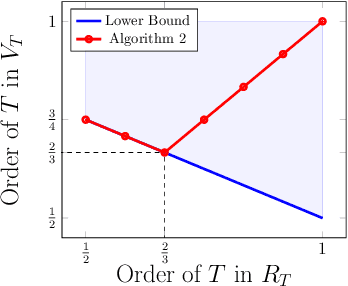
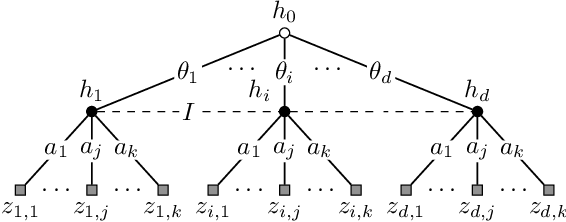
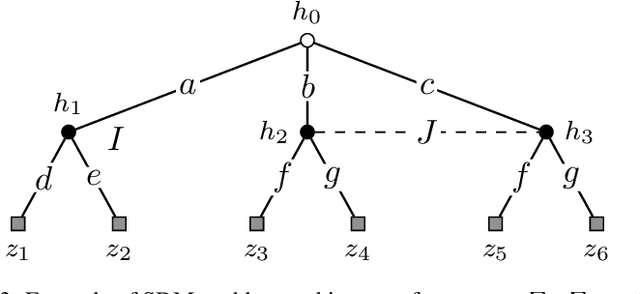
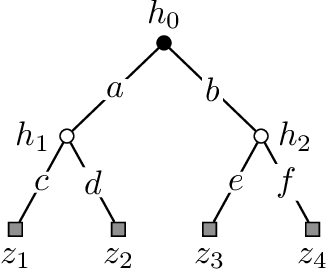
We study a repeated information design problem faced by an informed sender who tries to influence the behavior of a self-interested receiver. We consider settings where the receiver faces a sequential decision making (SDM) problem. At each round, the sender observes the realizations of random events in the SDM problem. This begets the challenge of how to incrementally disclose such information to the receiver to persuade them to follow (desirable) action recommendations. We study the case in which the sender does not know random events probabilities, and, thus, they have to gradually learn them while persuading the receiver. We start by providing a non-trivial polytopal approximation of the set of sender's persuasive information structures. This is crucial to design efficient learning algorithms. Next, we prove a negative result: no learning algorithm can be persuasive. Thus, we relax persuasiveness requirements by focusing on algorithms that guarantee that the receiver's regret in following recommendations grows sub-linearly. In the full-feedback setting -- where the sender observes all random events realizations -- , we provide an algorithm with $\tilde{O}(\sqrt{T})$ regret for both the sender and the receiver. Instead, in the bandit-feedback setting -- where the sender only observes the realizations of random events actually occurring in the SDM problem -- , we design an algorithm that, given an $\alpha \in [1/2, 1]$ as input, ensures $\tilde{O}({T^\alpha})$ and $\tilde{O}( T^{\max \{ \alpha, 1-\frac{\alpha}{2} \} })$ regrets, for the sender and the receiver respectively. This result is complemented by a lower bound showing that such a regrets trade-off is essentially tight.
Task and Motion Planning with Large Language Models for Object Rearrangement
Mar 14, 2023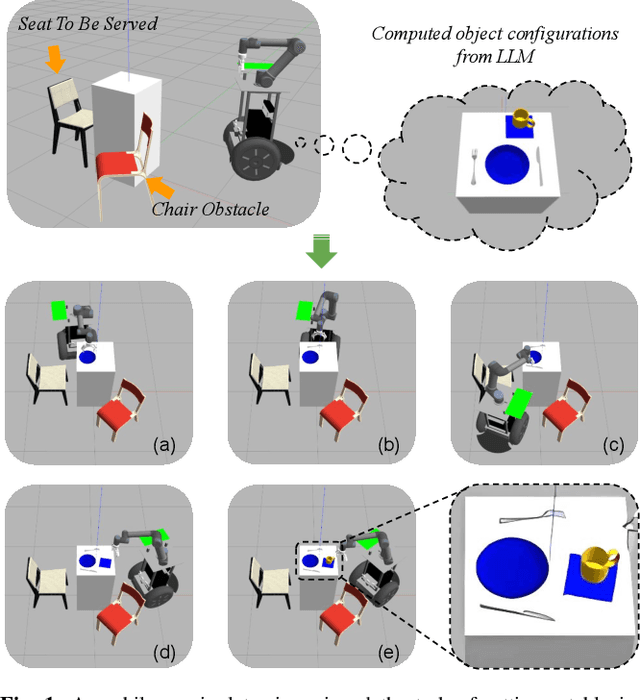
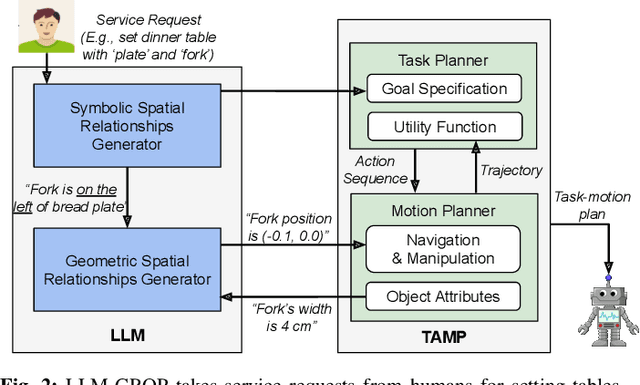
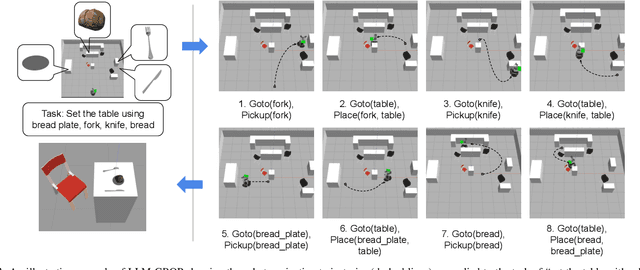
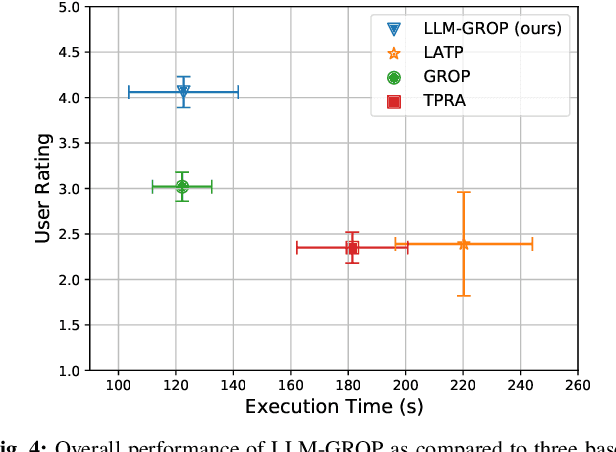
Multi-object rearrangement is a crucial skill for service robots, and commonsense reasoning is frequently needed in this process. However, achieving commonsense arrangements requires knowledge about objects, which is hard to transfer to robots. Large language models (LLMs) are one potential source of this knowledge, but they do not naively capture information about plausible physical arrangements of the world. We propose LLM-GROP, which uses prompting to extract commonsense knowledge about semantically valid object configurations from an LLM and instantiates them with a task and motion planner in order to generalize to varying scene geometry. LLM-GROP allows us to go from natural-language commands to human-aligned object rearrangement in varied environments. Based on human evaluations, our approach achieves the highest rating while outperforming competitive baselines in terms of success rate while maintaining comparable cumulative action costs. Finally, we demonstrate a practical implementation of LLM-GROP on a mobile manipulator in real-world scenarios. Supplementary materials are available at: https://sites.google.com/view/llm-grop
DasFormer: Deep Alternating Spectrogram Transformer for Multi/Single-Channel Speech Separation
Mar 14, 2023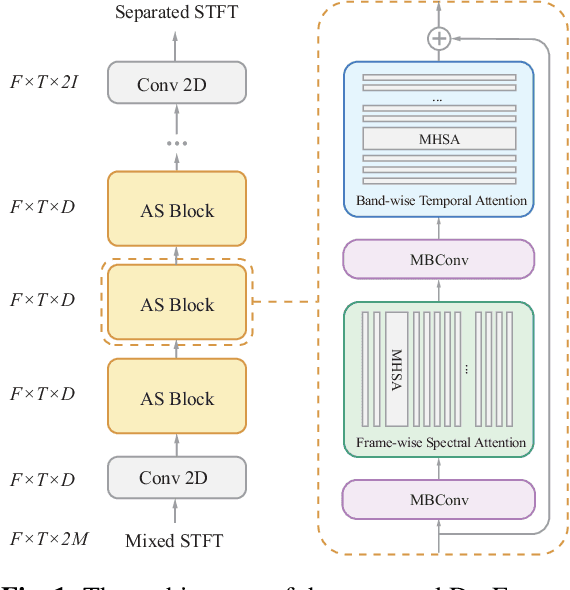
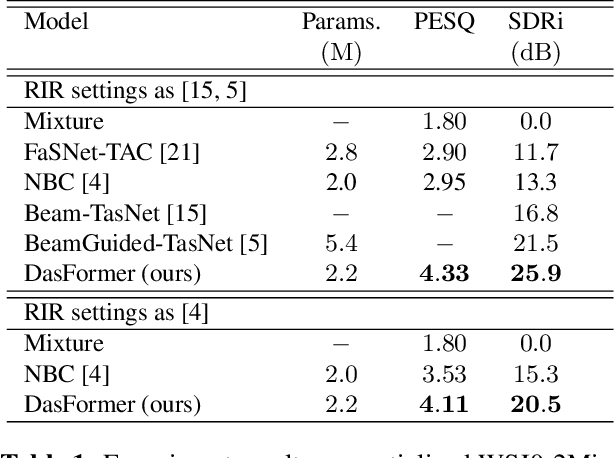
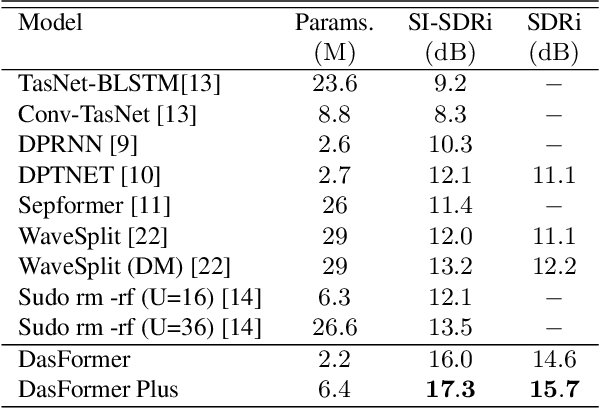
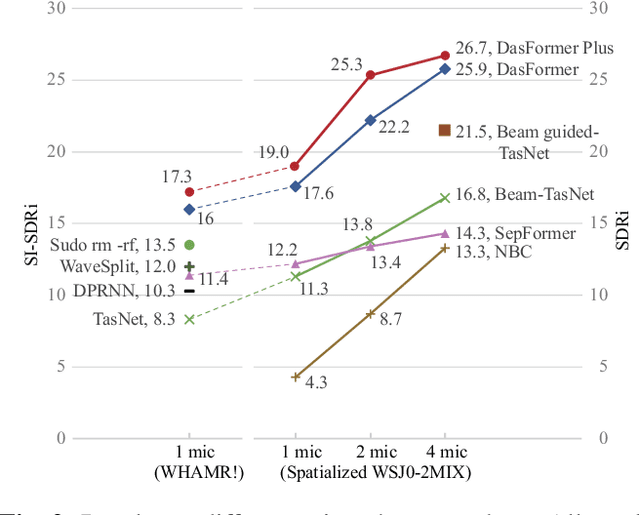
For the task of speech separation, previous study usually treats multi-channel and single-channel scenarios as two research tracks with specialized solutions developed respectively. Instead, we propose a simple and unified architecture - DasFormer (Deep alternating spectrogram transFormer) to handle both of them in the challenging reverberant environments. Unlike frame-wise sequence modeling, each TF-bin in the spectrogram is assigned with an embedding encoding spectral and spatial information. With such input, DasFormer is then formed by multiple repetition of simple blocks each of which integrates 1) two multi-head self-attention (MHSA) modules alternately processing within each frequency bin & temporal frame of the spectrogram 2) MBConv before each MHSA for modeling local features on the spectrogram. Experiments show that DasFormer has a powerful ability to model the time-frequency representation, whose performance far exceeds the current SOTA models in multi-channel speech separation, and also achieves single-channel SOTA in the more challenging yet realistic reverberation scenario.