 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decision-aid or Controller? Steering Human Decision Makers with Algorithms
Mar 23, 2023
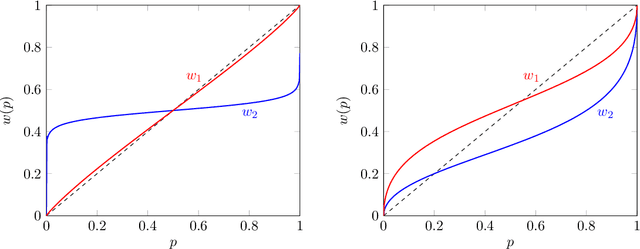
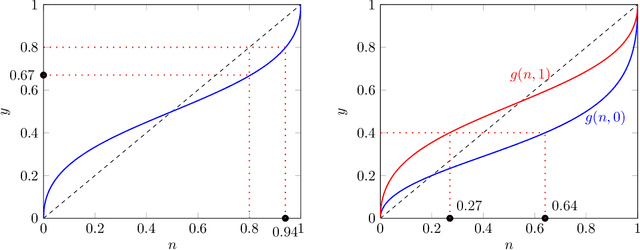
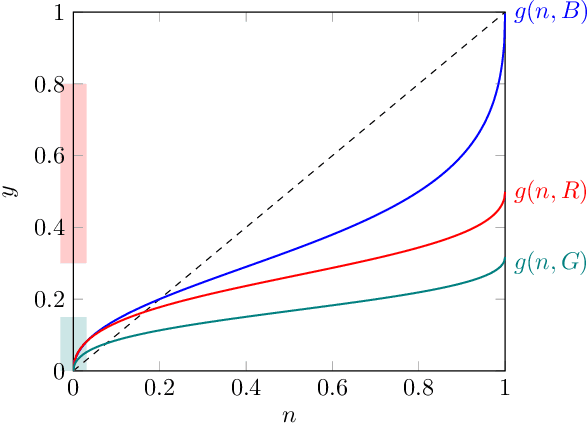
Algorithms are used to aid human decision makers by making predictions and recommending decisions. Currently, these algorithms are trained to optimize prediction accuracy. What if they were optimized to control final decisions? In this paper, we study a decision-aid algorithm that learns about the human decision maker and provides ''personalized recommendations'' to influence final decisions. We first consider fixed human decision functions which map observable features and the algorithm's recommendations to final decisions. We characterize the conditions under which perfect control over final decisions is attainable. Under fairly general assumptions, the parameters of the human decision function can be identified from past interactions between the algorithm and the human decision maker, even when the algorithm was constrained to make truthful recommendations. We then consider a decision maker who is aware of the algorithm's manipulation and responds strategically. By posing the setting as a variation of the cheap talk game [Crawford and Sobel, 1982], we show that all equilibria are partition equilibria where only coarse information is shared: the algorithm recommends an interval containing the ideal decision. We discuss the potential applications of such algorithms and their social implications.
Preference-Aware Constrained Multi-Objective Bayesian Optimization
Mar 23, 2023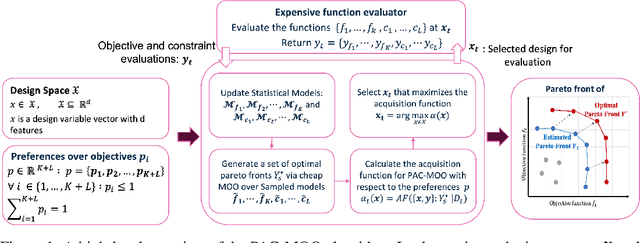
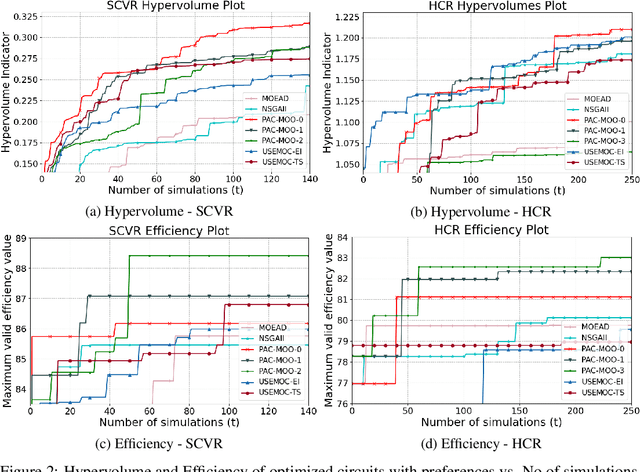
This paper addresses the problem of constrained multi-objective optimization over black-box objective functions with practitioner-specified preferences over the objectives when a large fraction of the input space is infeasible (i.e., violates constraints). This problem arises in many engineering design problems including analog circuits and electric power system design. Our overall goal is to approximate the optimal Pareto set over the small fraction of feasible input designs. The key challenges include the huge size of the design space, multiple objectives and large number of constraints, and the small fraction of feasible input designs which can be identified only after performing expensive simulations. We propose a novel and efficient preference-aware constrained multi-objective Bayesian optimization approach referred to as PAC-MOO to address these challenges. The key idea is to learn surrogate models for both output objectives and constraints, and select the candidate input for evaluation in each iteration that maximizes the information gained about the optimal constrained Pareto front while factoring in the preferences over objectives. Our experiments on two real-world analog circuit design optimization problems demonstrate the efficacy of PAC-MOO over prior methods.
It is all Connected: A New Graph Formulation for Spatio-Temporal Forecasting
Mar 23, 2023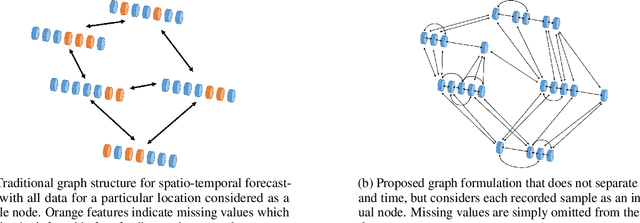

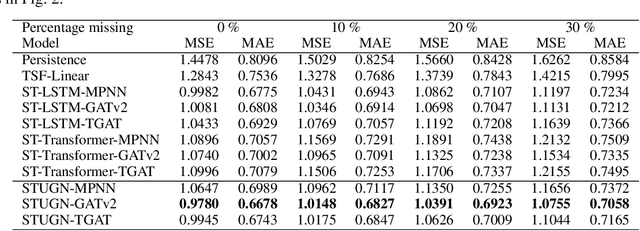
With an ever-increasing number of sensors in modern society, spatio-temporal time series forecasting has become a de facto tool to make informed decisions about the future. Most spatio-temporal forecasting models typically comprise distinct components that learn spatial and temporal dependencies. A common methodology employs some Graph Neural Network (GNN) to capture relations between spatial locations, while another network, such as a recurrent neural network (RNN), learns temporal correlations. By representing every recorded sample as its own node in a graph, rather than all measurements for a particular location as a single node, temporal and spatial information is encoded in a similar manner. In this setting, GNNs can now directly learn both temporal and spatial dependencies, jointly, while also alleviating the need for additional temporal networks. Furthermore, the framework does not require aligned measurements along the temporal dimension, meaning that it also naturally facilitates irregular time series, different sampling frequencies or missing data, without the need for data imputation. To evaluate the proposed methodology, we consider wind speed forecasting as a case study, where our proposed framework outperformed other spatio-temporal models using GNNs with either Transformer or LSTM networks as temporal update functions.
Damage detection of high-speed railway box girder using train-induced dynamic responses
Mar 23, 2023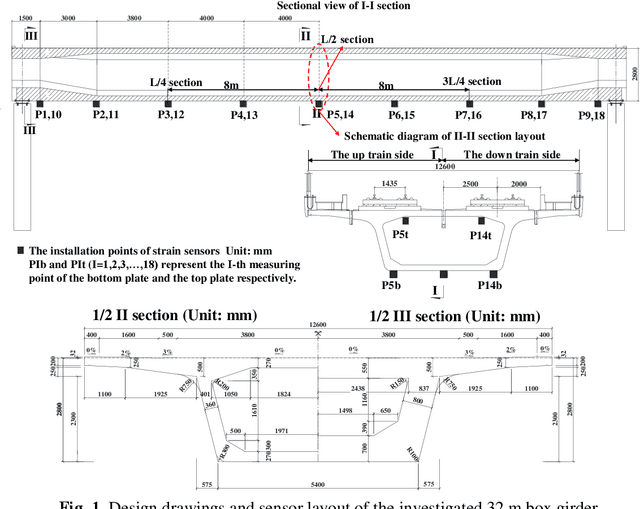
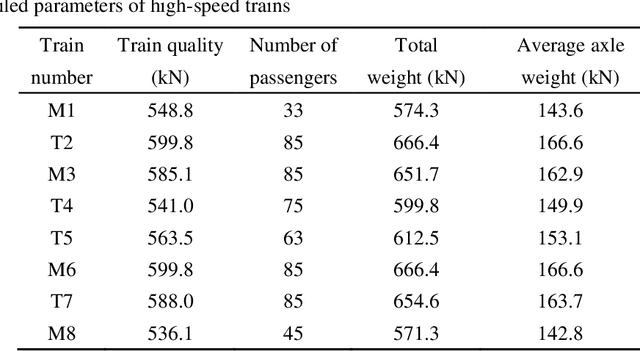
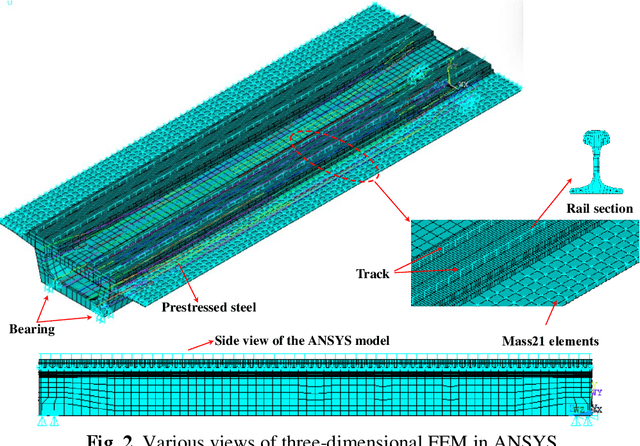

This paper proposes a damage detection method based on the train-induced responses of high-speed railway box girder. Under the coupling effects of bending and torsion, the traditional damage detection method based on the Euler beam theory cannot be applied. In this research, the box girder section is divided into different components based on the plate element analysis method. The strain responses were preprocessed based on Principal Component Analysis (PCA) method to remove the influence of train operation variation. The residual error of autoregressive (AR) model was used as a potential index of damage features. The optimal order of the model was determined based on Bayesian information criterion (BIC) criterion. Finally, the confidence boundary (CB) of damage features (DF) constituting outliers can be estimated by Gaussian inverse cumulative distribution function (ICDF). The numerical simulation results show that the proposed method in this paper can effectively identify, locate and quantify the damage, which verifies the accuracy of the proposed method. The proposed method effectively identifies the early damage of all components on the key section by using four strain sensors, and it is helpful for developing effective maintenance strategies for high-speed railway box girder.
Experience in Engineering Complex Systems: Active Preference Learning with Multiple Outcomes and Certainty Levels
Feb 27, 2023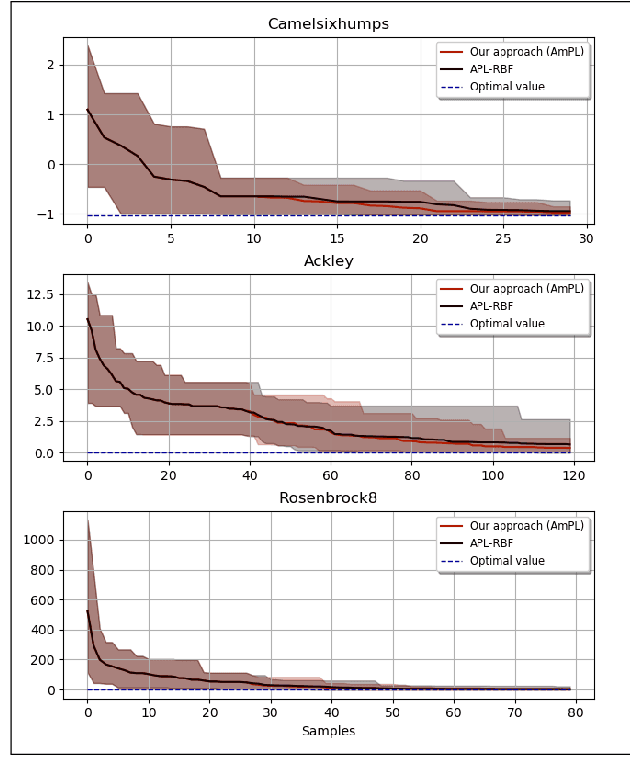
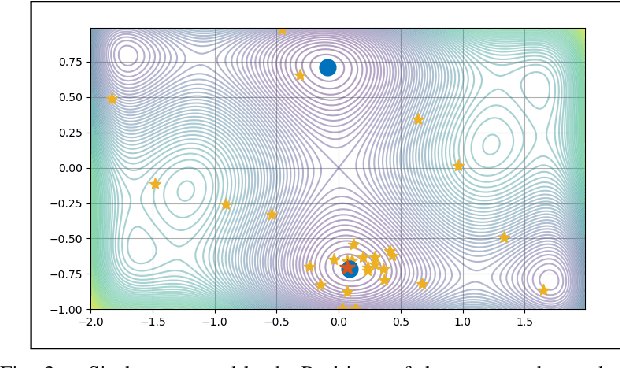
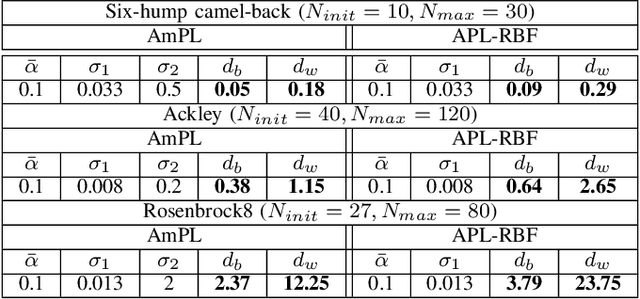
Black-box optimization refers to the optimization problem whose objective function and/or constraint sets are either unknown, inaccessible, or non-existent. In many applications, especially with the involvement of humans, the only way to access the optimization problem is through performing physical experiments with the available outcomes being the preference of one candidate with respect to one or many others. Accordingly, the algorithm so-called Active Preference Learning has been developed to exploit this specific information in constructing a surrogate function based on standard radial basis functions, and then forming an easy-to-solve acquisition function which repetitively suggests new decision vectors to search for the optimal solution. Based on this idea, our approach aims to extend the algorithm in such a way that can exploit further information effectively, which can be obtained in reality such as: 5-point Likert type scale for the outcomes of the preference query (i.e., the preference can be described in not only "this is better than that" but also "this is much better than that" level), or multiple outcomes for a single preference query with possible additive information on how certain the outcomes are. The validation of the proposed algorithm is done through some standard benchmark functions, showing a promising improvement with respect to the state-of-the-art algorithm.
Category-level Shape Estimation for Densely Cluttered Objects
Feb 23, 2023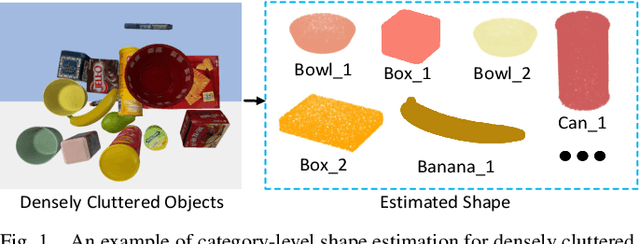
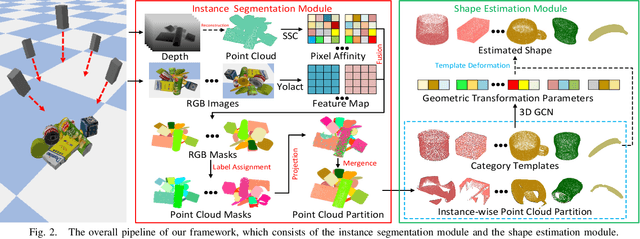
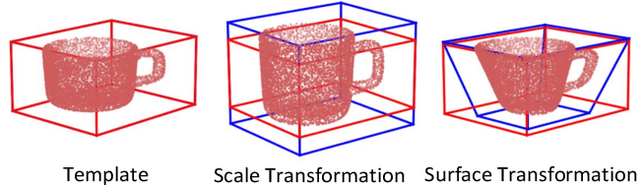
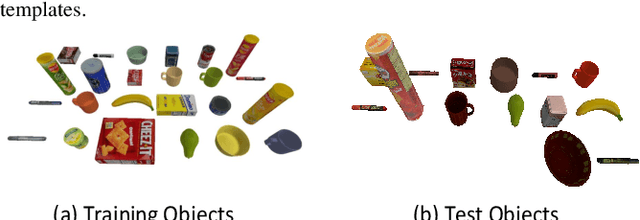
Accurately estimating the shape of objects in dense clutters makes important contribution to robotic packing, because the optimal object arrangement requires the robot planner to acquire shape information of all existed objects. However, the objects for packing are usually piled in dense clutters with severe occlusion, and the object shape varies significantly across different instances for the same category. They respectively cause large object segmentation errors and inaccurate shape recovery on unseen instances, which both degrade the performance of shape estimation during deployment. In this paper, we propose a category-level shape estimation method for densely cluttered objects. Our framework partitions each object in the clutter via the multi-view visual information fusion to achieve high segmentation accuracy, and the instance shape is recovered by deforming the category templates with diverse geometric transformations to obtain strengthened generalization ability. Specifically, we first collect the multi-view RGB-D images of the object clutters for point cloud reconstruction. Then we fuse the feature maps representing the visual information of multi-view RGB images and the pixel affinity learned from the clutter point cloud, where the acquired instance segmentation masks of multi-view RGB images are projected to partition the clutter point cloud. Finally, the instance geometry information is obtained from the partially observed instance point cloud and the corresponding category template, and the deformation parameters regarding the template are predicted for shape estimation. Experiments in the simulated environment and real world show that our method achieves high shape estimation accuracy for densely cluttered everyday objects with various shapes.
Edgeformers: Graph-Empowered Transformers for Representation Learning on Textual-Edge Networks
Feb 21, 2023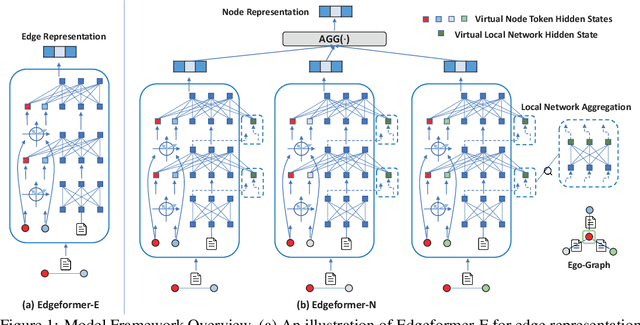

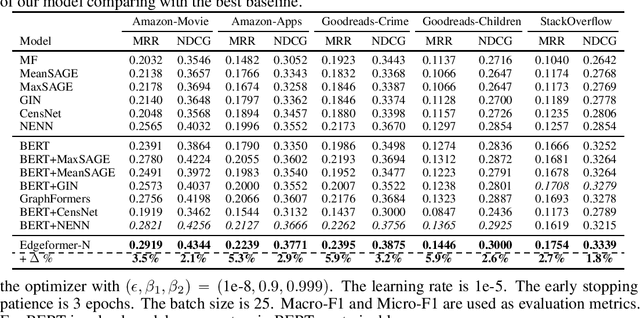
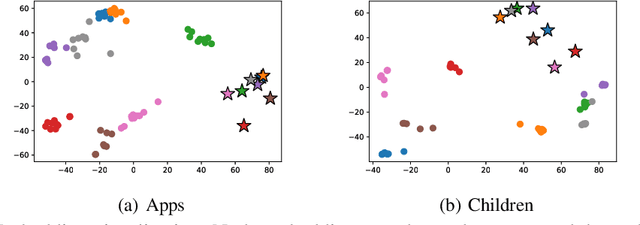
Edges in many real-world social/information networks are associated with rich text information (e.g., user-user communications or user-product reviews). However, mainstream network representation learning models focus on propagating and aggregating node attributes, lacking specific designs to utilize text semantics on edges. While there exist edge-aware graph neural networks, they directly initialize edge attributes as a feature vector, which cannot fully capture the contextualized text semantics of edges. In this paper, we propose Edgeformers, a framework built upon graph-enhanced Transformers, to perform edge and node representation learning by modeling texts on edges in a contextualized way. Specifically, in edge representation learning, we inject network information into each Transformer layer when encoding edge texts; in node representation learning, we aggregate edge representations through an attention mechanism within each node's ego-graph. On five public datasets from three different domains, Edgeformers consistently outperform state-of-the-art baselines in edge classification and link prediction, demonstrating the efficacy in learning edge and node representations, respectively.
KG-ECO: Knowledge Graph Enhanced Entity Correction for Query Rewriting
Feb 21, 2023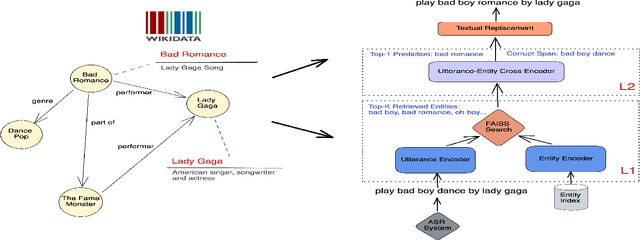

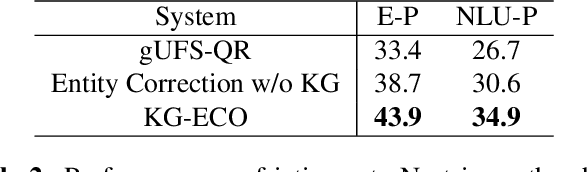
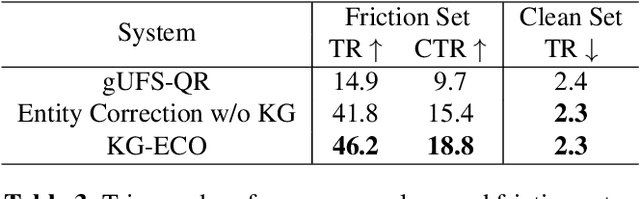
Query Rewriting (QR) plays a critical role in large-scale dialogue systems for reducing frictions. When there is an entity error, it imposes extra challenges for a dialogue system to produce satisfactory responses. In this work, we propose KG-ECO: Knowledge Graph enhanced Entity COrrection for query rewriting, an entity correction system with corrupt entity span detection and entity retrieval/re-ranking functionalities.To boost the model performance, we incorporate Knowledge Graph (KG) to provide entity structural information (neighboring entities encoded by graph neural networks) and textual information (KG entity descriptions encoded by RoBERTa). Experimental results show that our approach yields a clear performance gain over two baselines: utterance level QR and entity correction without utilizing KG information. The proposed system is particularly effective for few-shot learning cases where target entities are rarely seen in training or there is a KG relation between the target entity and other contextual entities in the query.
Target-to-User Association in ISAC Systems With Vehicle-Lodged RIS
Mar 14, 2023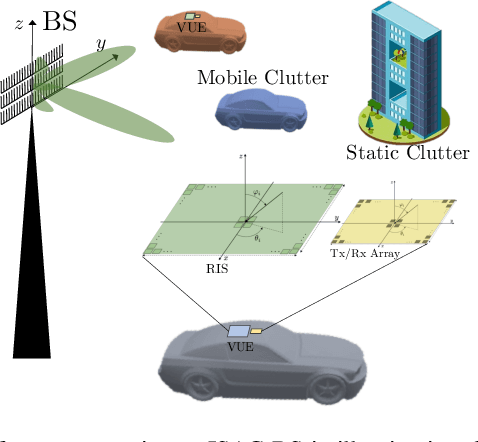
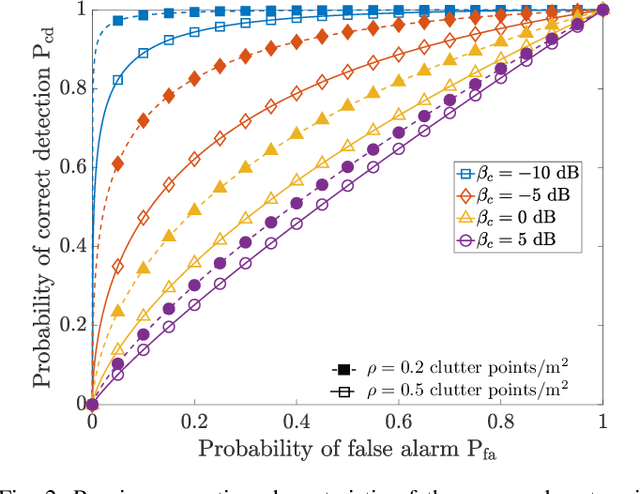
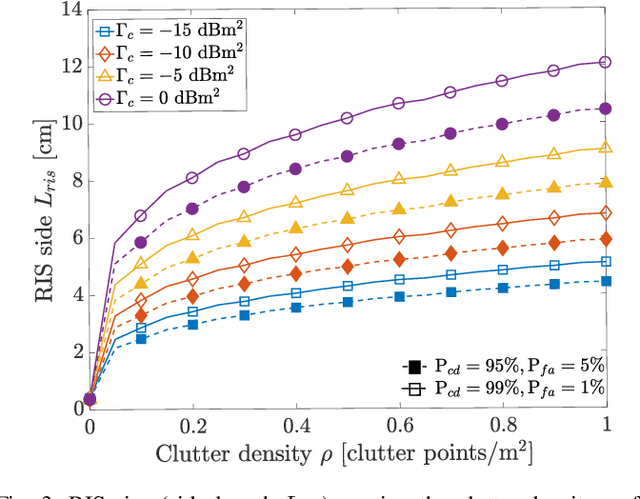
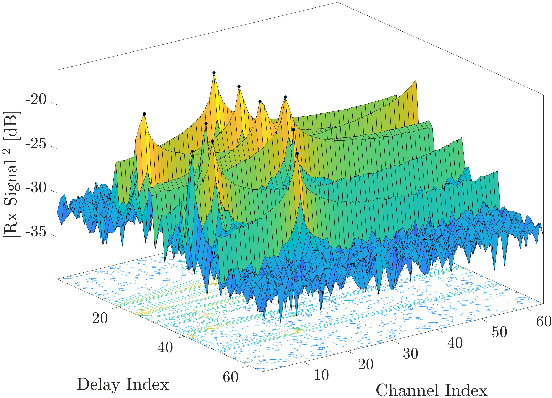
Target-to-user (T2U) association is a prerequisite to fully exploit the potential of the sensing function in communication-centric integrated sensing and communication (ISAC) systems, e.g., for beam and blockage management. This letter proposes to purposely mount a RIS on the roof of the vehicular user equipment (VUE), which can serve as an intentional back-reflector towards the base station. By controlling the reflection pattern over time, it is possible to transmit information to the sensing system, i.e., back-reflection as bit 1, no back-reflection as bit 0. The VUEs are configured to back-reflect a Hadamard code sequence, which enables T2U association. The numerical results confirm the validity of our proposal.
ForDigitStress: A multi-modal stress dataset employing a digital job interview scenario
Mar 14, 2023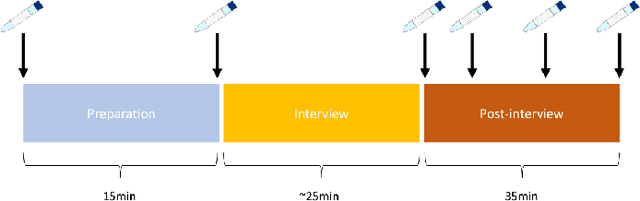
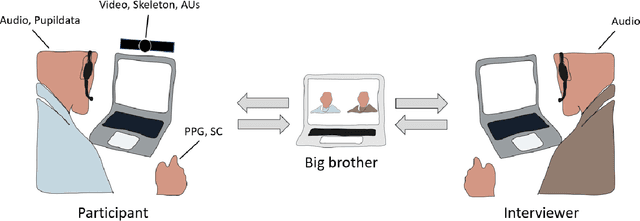
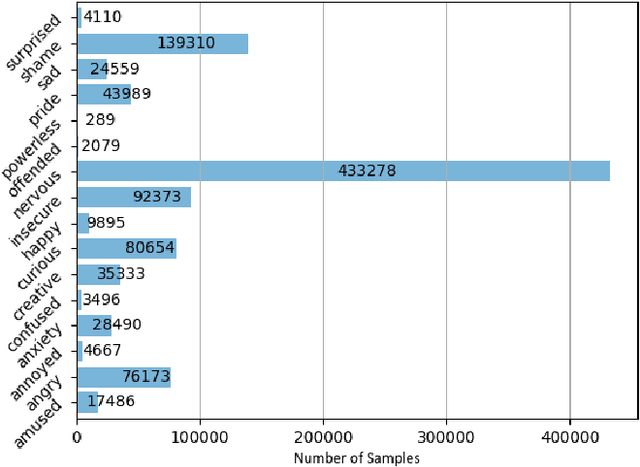
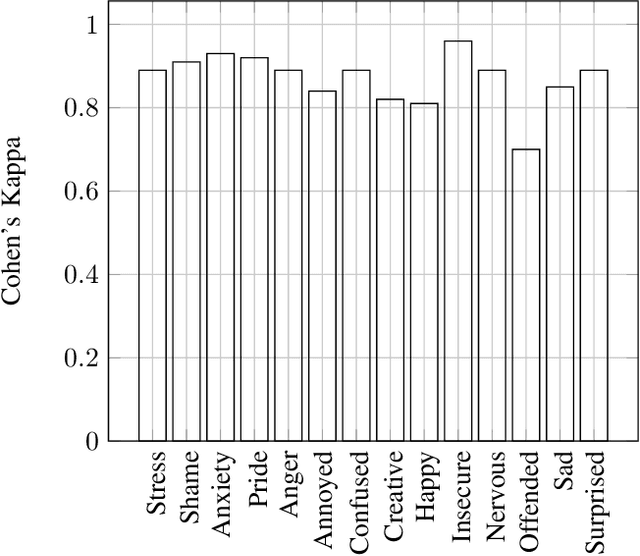
We present a multi-modal stress dataset that uses digital job interviews to induce stress. The dataset provides multi-modal data of 40 participants including audio, video (motion capturing, facial recognition, eye tracking) as well as physiological information (photoplethysmography, electrodermal activity). In addition to that, the dataset contains time-continuous annotations for stress and occurred emotions (e.g. shame, anger, anxiety, surprise). In order to establish a baseline, five different machine learning classifiers (Support Vector Machine, K-Nearest Neighbors, Random Forest, Long-Short-Term Memory Network) have been trained and evaluated on the proposed dataset for a binary stress classification task. The best-performing classifier achieved an accuracy of 88.3% and an F1-score of 87.5%.