 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Do We Really Need Complicated Model Architectures For Temporal Networks?
Feb 22, 2023
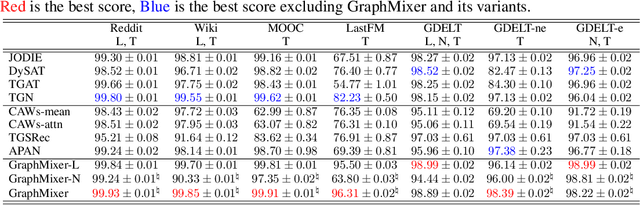
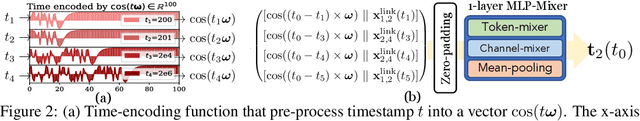

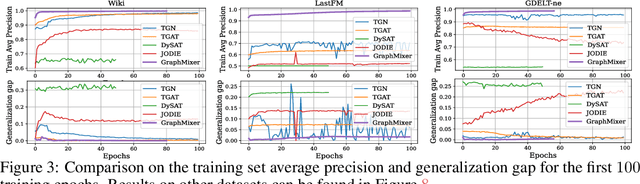
Recurrent neural network (RNN) and self-attention mechanism (SAM) are the de facto methods to extract spatial-temporal information for temporal graph learning. Interestingly, we found that although both RNN and SAM could lead to a good performance, in practice neither of them is always necessary. In this paper, we propose GraphMixer, a conceptually and technically simple architecture that consists of three components: (1) a link-encoder that is only based on multi-layer perceptrons (MLP) to summarize the information from temporal links, (2) a node-encoder that is only based on neighbor mean-pooling to summarize node information, and (3) an MLP-based link classifier that performs link prediction based on the outputs of the encoders. Despite its simplicity, GraphMixer attains an outstanding performance on temporal link prediction benchmarks with faster convergence and better generalization performance. These results motivate us to rethink the importance of simpler model architecture.
Character, Word, or Both? Revisiting the Segmentation Granularity for Chinese Pre-trained Language Models
Mar 20, 2023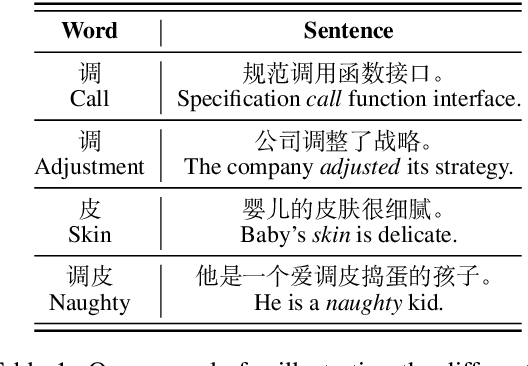
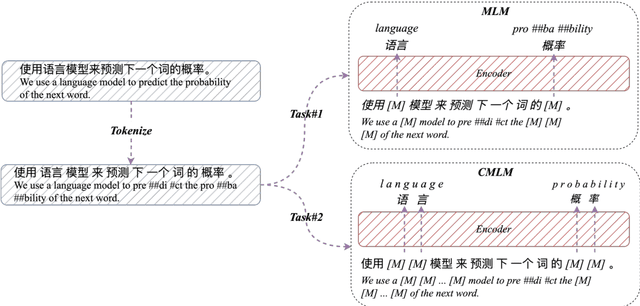

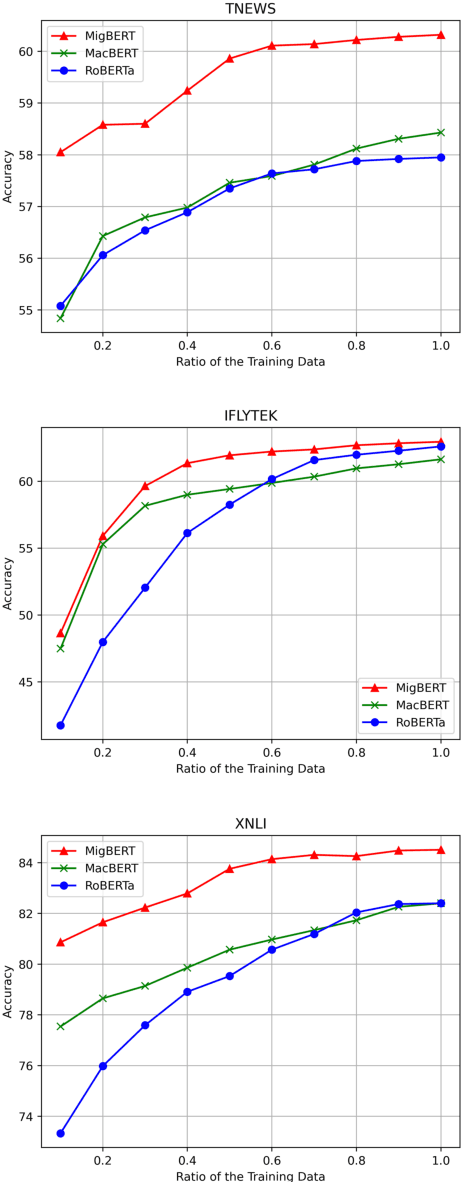
Pretrained language models (PLMs) have shown marvelous improvements across various NLP tasks. Most Chinese PLMs simply treat an input text as a sequence of characters, and completely ignore word information. Although Whole Word Masking can alleviate this, the semantics in words is still not well represented. In this paper, we revisit the segmentation granularity of Chinese PLMs. We propose a mixed-granularity Chinese BERT (MigBERT) by considering both characters and words. To achieve this, we design objective functions for learning both character and word-level representations. We conduct extensive experiments on various Chinese NLP tasks to evaluate existing PLMs as well as the proposed MigBERT. Experimental results show that MigBERT achieves new SOTA performance on all these tasks. Further analysis demonstrates that words are semantically richer than characters. More interestingly, we show that MigBERT also works with Japanese. Our code and model have been released here~\footnote{https://github.com/xnliang98/MigBERT}.
This Was (Not) Intended: How Intent Communication and Biometrics Can Enhance Social Interactions With Robots
Mar 20, 2023Socially Assistive Robots (SARs) are robots that are designed to replicate the role of a caregiver, coach, or teacher, providing emotional, cognitive, and social cues to support a specific group. SARs are becoming increasingly prevalent, especially in elderly care. Effective communication, both explicit and implicit, is a critical aspect of human-robot interaction involving SARs. Intent communication is necessary for SARs to engage in effective communication with humans. Biometrics can provide crucial information about a person's identity or emotions. By linking these biometric signals to the communication of intent, SARs can gain a profound understanding of their users and tailor their interactions accordingly. The development of reliable and robust biometric sensing and analysis systems is critical to the success of SARs. In this work, we focus on four different aspects to evaluate the communication of intent involving SARs, existing works, and our outlook on future works and applications.
Fairness-Aware Graph Filter Design
Mar 20, 2023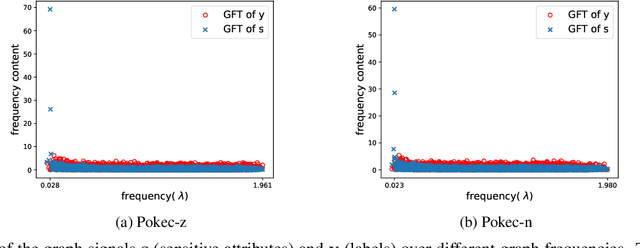
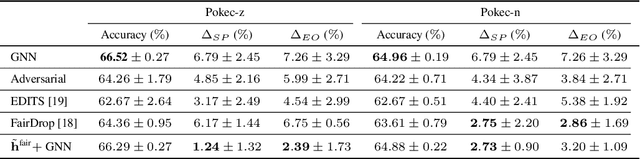

Graphs are mathematical tools that can be used to represent complex real-world systems, such as financial markets and social networks. Hence, machine learning (ML) over graphs has attracted significant attention recently. However, it has been demonstrated that ML over graphs amplifies the already existing bias towards certain under-represented groups in various decision-making problems due to the information aggregation over biased graph structures. Faced with this challenge, in this paper, we design a fair graph filter that can be employed in a versatile manner for graph-based learning tasks. The design of the proposed filter is based on a bias analysis and its optimality in mitigating bias compared to its fairness-agnostic counterpart is established. Experiments on real-world networks for node classification demonstrate the efficacy of the proposed filter design in mitigating bias, while attaining similar utility and better stability compared to baseline algorithms.
Cheap Talk Discovery and Utilization in Multi-Agent Reinforcement Learning
Mar 19, 2023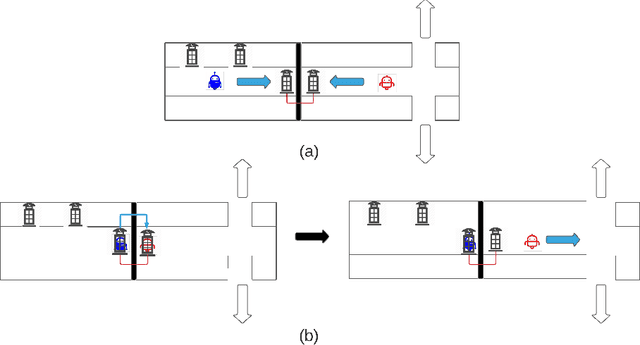
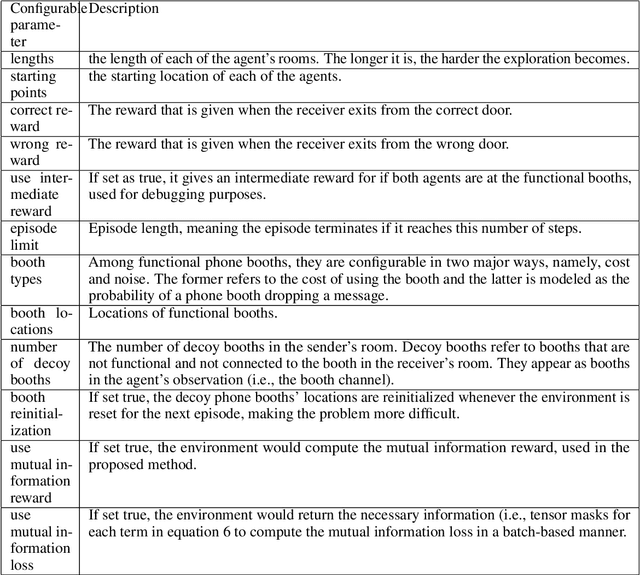
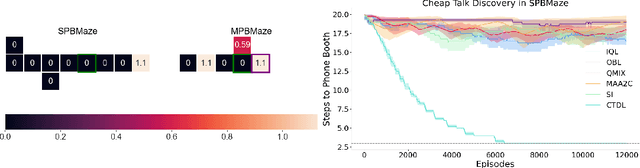
By enabling agents to communicate, recent cooperative multi-agent reinforcement learning (MARL) methods have demonstrated better task performance and more coordinated behavior. Most existing approaches facilitate inter-agent communication by allowing agents to send messages to each other through free communication channels, i.e., cheap talk channels. Current methods require these channels to be constantly accessible and known to the agents a priori. In this work, we lift these requirements such that the agents must discover the cheap talk channels and learn how to use them. Hence, the problem has two main parts: cheap talk discovery (CTD) and cheap talk utilization (CTU). We introduce a novel conceptual framework for both parts and develop a new algorithm based on mutual information maximization that outperforms existing algorithms in CTD/CTU settings. We also release a novel benchmark suite to stimulate future research in CTD/CTU.
Model-Free Reconstruction of Capacity Degradation Trajectory of Lithium-Ion Batteries Using Early Cycle Data
Mar 31, 2023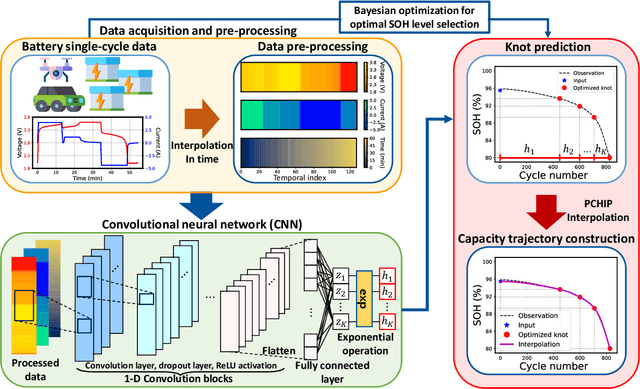
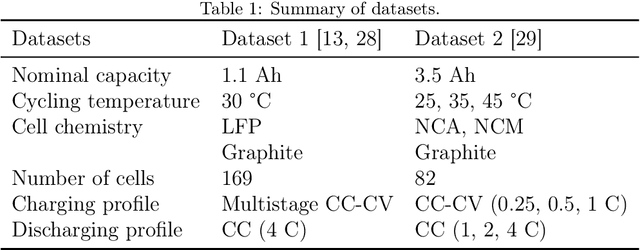
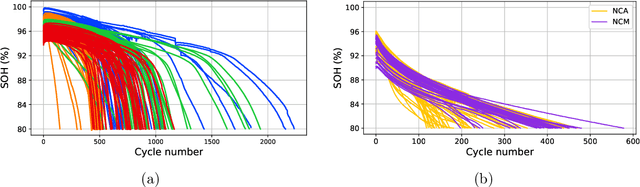
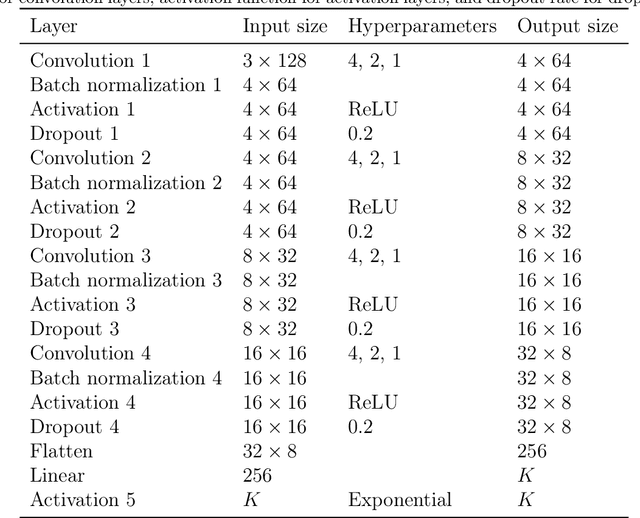
Early degradation prediction of lithium-ion batteries is crucial for ensuring safety and preventing unexpected failure in manufacturing and diagnostic processes. Long-term capacity trajectory predictions can fail due to cumulative errors and noise. To address this issue, this study proposes a data-centric method that uses early single-cycle data to predict the capacity degradation trajectory of lithium-ion cells. The method involves predicting a few knots at specific retention levels using a deep learning-based model and interpolating them to reconstruct the trajectory. Two approaches are used to identify the retention levels of two to four knots: uniformly dividing the retention up to the end of life and finding optimal locations using Bayesian optimization. The proposed model is validated with experimental data from 169 cells using five-fold cross-validation. The results show that mean absolute percentage errors in trajectory prediction are less than 1.60% for all cases of knots. By predicting only the cycle numbers of at least two knots based on early single-cycle charge and discharge data, the model can directly estimate the overall capacity degradation trajectory. Further experiments suggest using three-cycle input data to achieve robust and efficient predictions, even in the presence of noise. The method is then applied to predict various shapes of capacity degradation patterns using additional experimental data from 82 cells. The study demonstrates that collecting only the cycle information of a few knots during model training and a few early cycle data points for predictions is sufficient for predicting capacity degradation. This can help establish appropriate warranties or replacement cycles in battery manufacturing and diagnosis processes.
Speaker-Aware Anti-Spoofing
Mar 02, 2023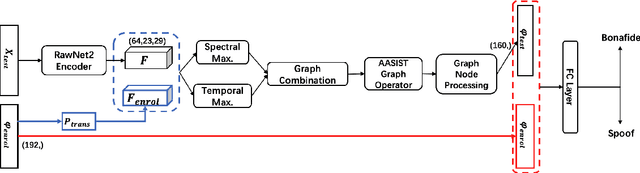
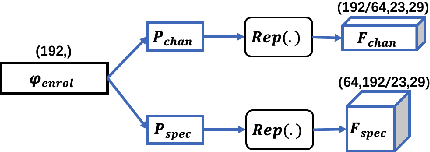
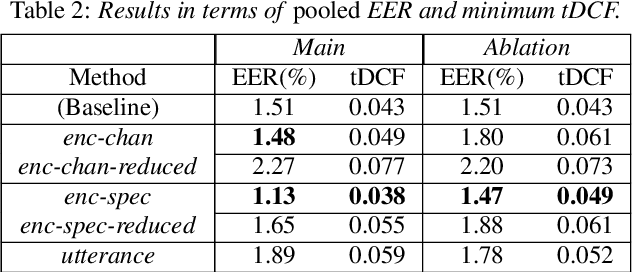
We address speaker-aware anti-spoofing, where prior knowledge of the target speaker is incorporated into a voice spoofing countermeasure (CM). In contrast to the frequently used speaker-independent solutions, we train the CM in a speaker-conditioned way. As a proof of concept, we consider speaker-aware extension to the state-of-the-art AASIST (audio anti-spoofing using integrated spectro-temporal graph attention networks) model. To this end, we consider two alternative strategies to incorporate target speaker information at the frame and utterance levels, respectively. The experimental results on a custom protocol based on ASVspoof 2019 dataset indicates the efficiency of the speaker information via enrollment: we obtain maximum relative improvements of 25.1% and 11.6% in equal error rate (EER) and minimum tandem detection cost function (t-DCF) over a speaker-independent baseline, respectively.
Label Attention Network for sequential multi-label classification
Mar 01, 2023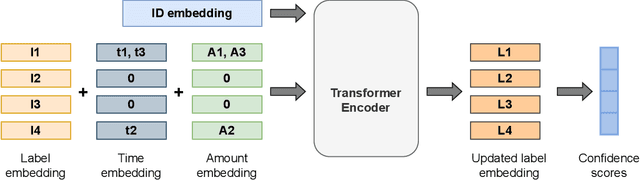
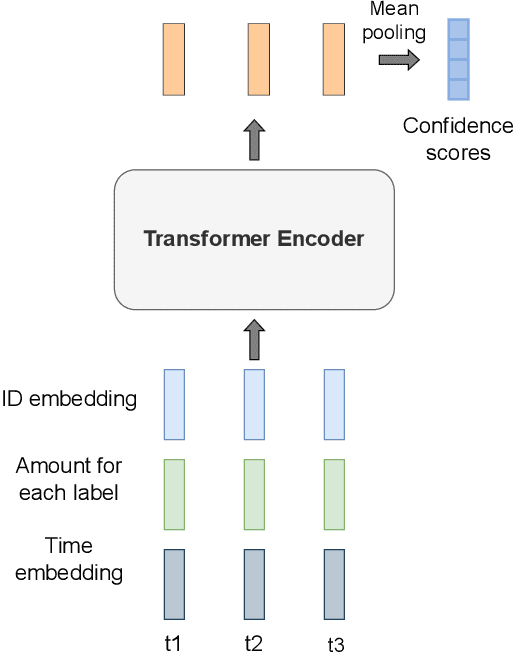
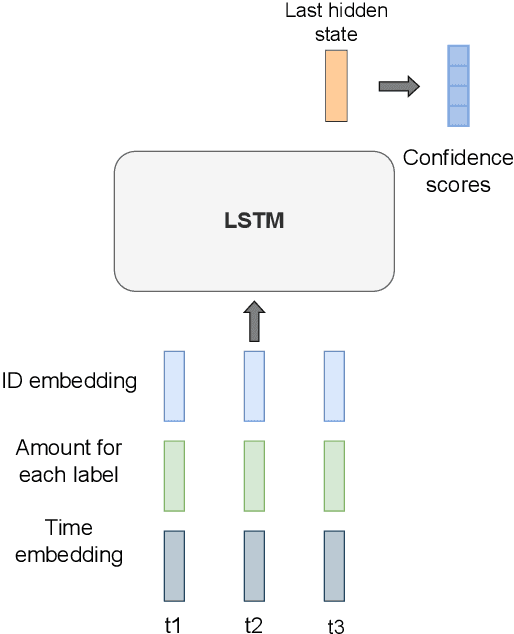
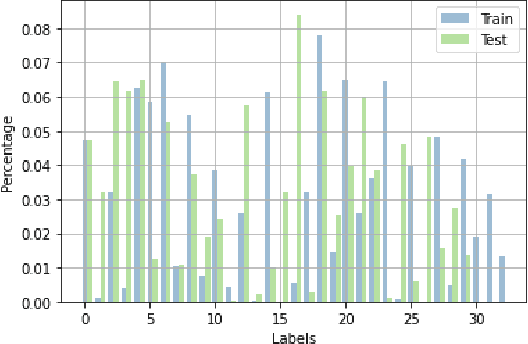
Multi-label classification is a natural problem statement for sequential data. We might be interested in the items of the next order by a customer, or types of financial transactions that will occur tomorrow. Most modern approaches focus on transformer architecture for multi-label classification, introducing self-attention for the elements of a sequence with each element being a multi-label vector and supplementary information. However, in this way we loose local information related to interconnections between particular labels. We propose instead to use a self-attention mechanism over labels preceding the predicted step. Conducted experiments suggest that such architecture improves the model performance and provides meaningful attention between labels. The metric such as micro-AUC of our label attention network is $0.9847$ compared to $0.7390$ for vanilla transformers benchmark.
CoGANPPIS: Coevolution-enhanced Global Attention Neural Network for Protein-Protein Interaction Site Prediction
Mar 13, 2023
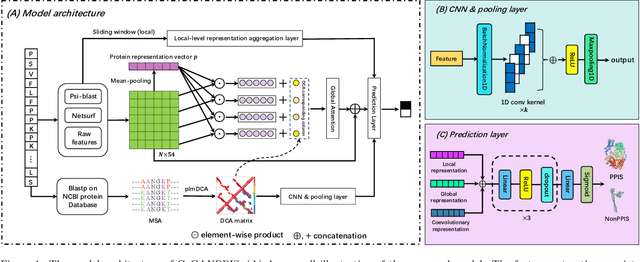
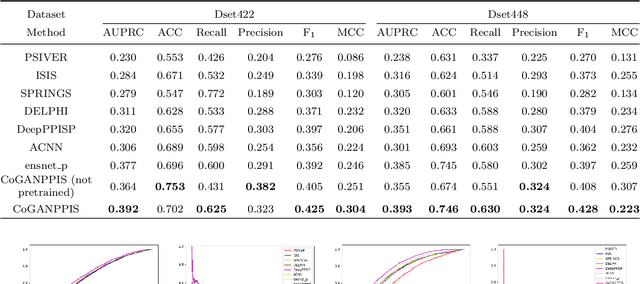
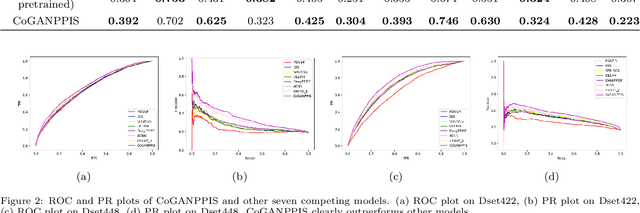
Protein-protein interactions are essential in biochemical processes. Accurate prediction of the protein-protein interaction sites (PPIs) deepens our understanding of biological mechanism and is crucial for new drug design. However, conventional experimental methods for PPIs prediction are costly and time-consuming so that many computational approaches, especially ML-based methods, have been developed recently. Although these approaches have achieved gratifying results, there are still two limitations: (1) Most models have excavated some useful input features, but failed to take coevolutionary features into account, which could provide clues for inter-residue relationships; (2) The attention-based models only allocate attention weights for neighboring residues, instead of doing it globally, neglecting that some residues being far away from the target residues might also matter. We propose a coevolution-enhanced global attention neural network, a sequence-based deep learning model for PPIs prediction, called CoGANPPIS. It utilizes three layers in parallel for feature extraction: (1) Local-level representation aggregation layer, which aggregates the neighboring residues' features; (2) Global-level representation learning layer, which employs a novel coevolution-enhanced global attention mechanism to allocate attention weights to all the residues on the same protein sequences; (3) Coevolutionary information learning layer, which applies CNN & pooling to coevolutionary information to obtain the coevolutionary profile representation. Then, the three outputs are concatenated and passed into several fully connected layers for the final prediction. Application on two benchmark datasets demonstrated a state-of-the-art performance of our model. The source code is publicly available at https://github.com/Slam1423/CoGANPPIS_source_code.
Multi-modal Multi-kernel Graph Learning for Autism Prediction and Biomarker Discovery
Mar 03, 2023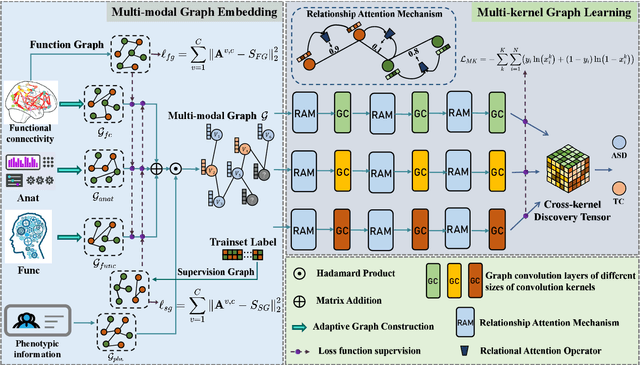
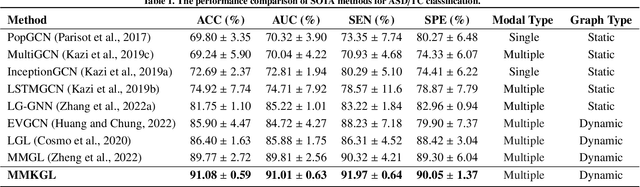
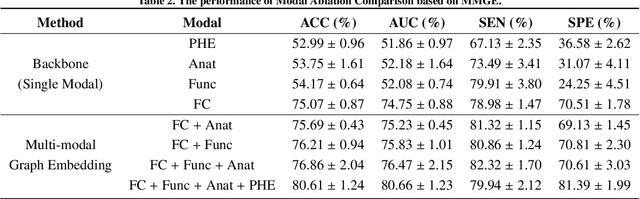
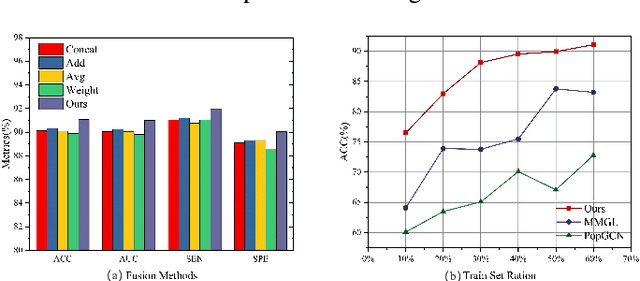
Multi-modal integration and classification based on graph learning is among the most challenging obstacles in disease prediction due to its complexity. Several recent works on the basis of attentional mechanisms have been proposed to disentangle the problem of multi-modal integration. However, there are certain limitations to these techniques. Primarily, these works focus on explicitly integrating at the feature level using weight scores, which cannot effectively address the negative impact between modalities. Next, a majority of them utilize single-sized filters to extract graph features, ignoring the heterogeneous information over graphs. To overcome these drawbacks, we propose MMKGL (Multi-modal Multi-Kernel Graph Learning). For the problem of negative impact between modalities, we use the multi-modal graph embedding module to construct a multi-modal graph. Different from the traditional manual construction of static graphs, a separate graph is generated for each modality by graph adaptive learning, where a function graph and a supervision graph are introduced for optimiztion during the multi-graph fusion embedding process. We then apply the multi-kernel graph learning module to extract heterogeneous information from the multi-modal graph. The information in the multi-modal graph at different levels is aggregated by convolutional kernels with different receptive field sizes, followed by generating a cross-kernel discovery tensor for disease prediction. Our method is evaluated on the benchmark Autism Brain Imaging Data Exchange (ABIDE) dataset and outperforms the state-of-the-art methods. In addition, discriminative brain regions associated with autism are identified by our model, providing guidance for the study of autism pathology.