 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Image as Action Models
Jul 10, 2024



Image-generation diffusion models have been fine-tuned to unlock new capabilities such as image-editing and novel view synthesis. Can we similarly unlock image-generation models for visuomotor control? We present GENIMA, a behavior-cloning agent that fine-tunes Stable Diffusion to 'draw joint-actions' as targets on RGB images. These images are fed into a controller that maps the visual targets into a sequence of joint-positions. We study GENIMA on 25 RLBench and 9 real-world manipulation tasks. We find that, by lifting actions into image-space, internet pre-trained diffusion models can generate policies that outperform state-of-the-art visuomotor approaches, especially in robustness to scene perturbations and generalizing to novel objects. Our method is also competitive with 3D agents, despite lacking priors such as depth, keypoints, or motion-planners.
Improving International Climate Policy via Mutually Conditional Binding Commitments
Jul 26, 2023The Paris Agreement, considered a significant milestone in climate negotiations, has faced challenges in effectively addressing climate change due to the unconditional nature of most Nationally Determined Contributions (NDCs). This has resulted in a prevalence of free-riding behavior among major polluters and a lack of concrete conditionality in NDCs. To address this issue, we propose the implementation of a decentralized, bottom-up approach called the Conditional Commitment Mechanism. This mechanism, inspired by the National Popular Vote Interstate Compact, offers flexibility and incentives for early adopters, aiming to formalize conditional cooperation in international climate policy. In this paper, we provide an overview of the mechanism, its performance in the AI4ClimateCooperation challenge, and discuss potential real-world implementation aspects. Prior knowledge of the climate mitigation collective action problem, basic economic principles, and game theory concepts are assumed.
Learning to Communicate using Contrastive Learning
Jul 03, 2023Communication is a powerful tool for coordination in multi-agent RL. But inducing an effective, common language is a difficult challenge, particularly in the decentralized setting. In this work, we introduce an alternative perspective where communicative messages sent between agents are considered as different incomplete views of the environment state. By examining the relationship between messages sent and received, we propose to learn to communicate using contrastive learning to maximize the mutual information between messages of a given trajectory. In communication-essential environments, our method outperforms previous work in both performance and learning speed. Using qualitative metrics and representation probing, we show that our method induces more symmetric communication and captures global state information from the environment. Overall, we show the power of contrastive learning and the importance of leveraging messages as encodings for effective communication.
Cheap Talk Discovery and Utilization in Multi-Agent Reinforcement Learning
Mar 19, 2023



By enabling agents to communicate, recent cooperative multi-agent reinforcement learning (MARL) methods have demonstrated better task performance and more coordinated behavior. Most existing approaches facilitate inter-agent communication by allowing agents to send messages to each other through free communication channels, i.e., cheap talk channels. Current methods require these channels to be constantly accessible and known to the agents a priori. In this work, we lift these requirements such that the agents must discover the cheap talk channels and learn how to use them. Hence, the problem has two main parts: cheap talk discovery (CTD) and cheap talk utilization (CTU). We introduce a novel conceptual framework for both parts and develop a new algorithm based on mutual information maximization that outperforms existing algorithms in CTD/CTU settings. We also release a novel benchmark suite to stimulate future research in CTD/CTU.
Learning to Ground Decentralized Multi-Agent Communication with Contrastive Learning
Mar 07, 2022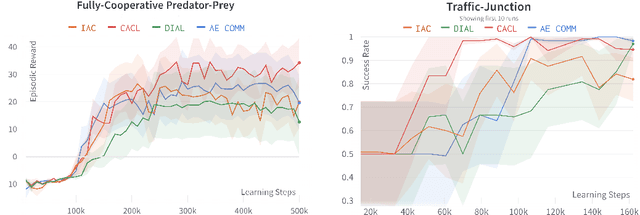
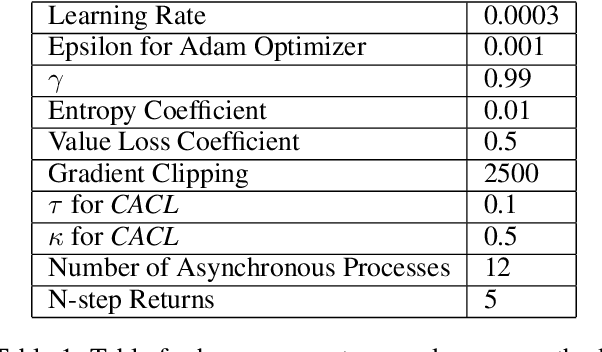
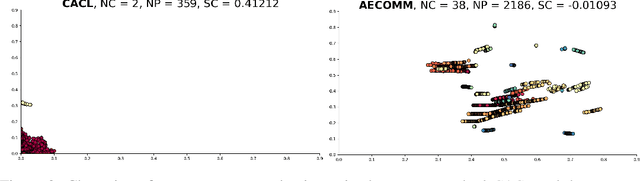
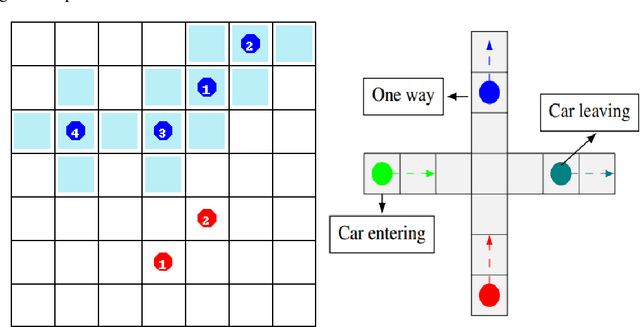
For communication to happen successfully, a common language is required between agents to understand information communicated by one another. Inducing the emergence of a common language has been a difficult challenge to multi-agent learning systems. In this work, we introduce an alternative perspective to the communicative messages sent between agents, considering them as different incomplete views of the environment state. Based on this perspective, we propose a simple approach to induce the emergence of a common language by maximizing the mutual information between messages of a given trajectory in a self-supervised manner. By evaluating our method in communication-essential environments, we empirically show how our method leads to better learning performance and speed, and learns a more consistent common language than existing methods, without introducing additional learning parameters.
Improving Performance in Reinforcement Learning by Breaking Generalization in Neural Networks
Mar 16, 2020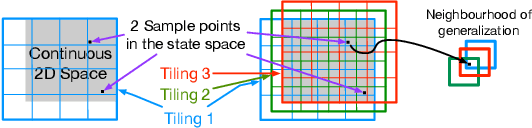
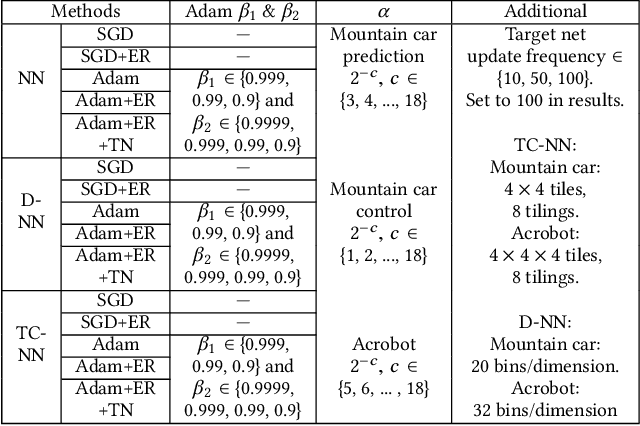
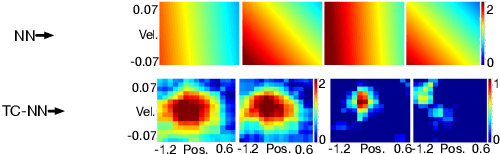

Reinforcement learning systems require good representations to work well. For decades practical success in reinforcement learning was limited to small domains. Deep reinforcement learning systems, on the other hand, are scalable, not dependent on domain specific prior knowledge and have been successfully used to play Atari, in 3D navigation from pixels, and to control high degree of freedom robots. Unfortunately, the performance of deep reinforcement learning systems is sensitive to hyper-parameter settings and architecture choices. Even well tuned systems exhibit significant instability both within a trial and across experiment replications. In practice, significant expertise and trial and error are usually required to achieve good performance. One potential source of the problem is known as catastrophic interference: when later training decreases performance by overriding previous learning. Interestingly, the powerful generalization that makes Neural Networks (NN) so effective in batch supervised learning might explain the challenges when applying them in reinforcement learning tasks. In this paper, we explore how online NN training and interference interact in reinforcement learning. We find that simply re-mapping the input observations to a high-dimensional space improves learning speed and parameter sensitivity. We also show this preprocessing reduces interference in prediction tasks. More practically, we provide a simple approach to NN training that is easy to implement, and requires little additional computation. We demonstrate that our approach improves performance in both prediction and control with an extensive batch of experiments in classic control domains.
Overcoming Catastrophic Interference in Online Reinforcement Learning with Dynamic Self-Organizing Maps
Oct 29, 2019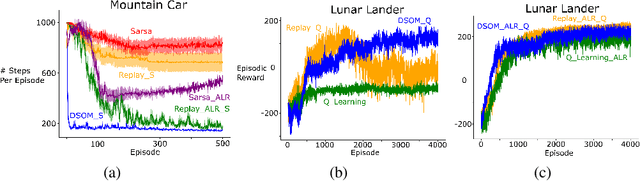
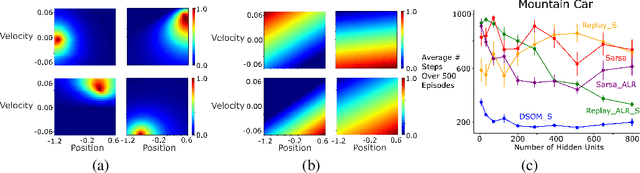
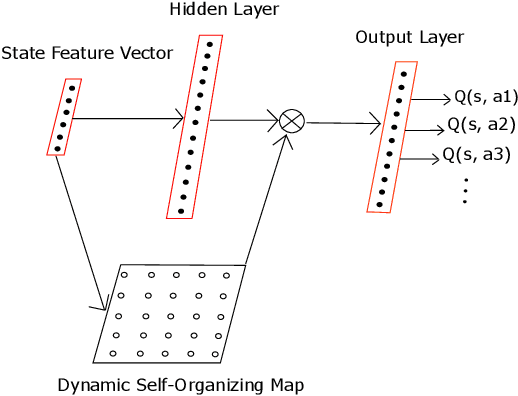
Using neural networks in the reinforcement learning (RL) framework has achieved notable successes. Yet, neural networks tend to forget what they learned in the past, especially when they learn online and fully incrementally, a setting in which the weights are updated after each sample is received and the sample is then discarded. Under this setting, an update can lead to overly global generalization by changing too many weights. The global generalization interferes with what was previously learned and deteriorates performance, a phenomenon known as catastrophic interference. Many previous works use mechanisms such as experience replay (ER) buffers to mitigate interference by performing minibatch updates, ensuring the data distribution is approximately independent-and-identically-distributed (i.i.d.). But using ER would become infeasible in terms of memory as problem complexity increases. Thus, it is crucial to look for more memory-efficient alternatives. Interference can be averted if we replace global updates with more local ones, so only weights responsible for the observed data sample are updated. In this work, we propose the use of dynamic self-organizing map (DSOM) with neural networks to induce such locality in the updates without ER buffers. Our method learns a DSOM to produce a mask to reweigh each hidden unit's output, modulating its degree of use. It prevents interference by replacing global updates with local ones, conditioned on the agent's state. We validate our method on standard RL benchmarks including Mountain Car and Lunar Lander, where existing methods often fail to learn without ER. Empirically, we show that our online and fully incremental method is on par with and in some cases, better than state-of-the-art in terms of final performance and learning speed. We provide visualizations and quantitative measures to show that our method indeed mitigates interference.